 夜雨聆风
夜雨聆风上一篇聊完“AI 时代,大模型真的能做好一款产品的设计吗?”之后,其实还会自然引出另一个更大的问题:
如果从更长的周期看,未来 AI 产品化到底会走向哪里?
这件事现在很容易被讨论散。
有人盯着个人助理,有人盯着数字员工,有人盯着 SaaS Agent 化,有人盯着语义层,有人盯着 Manus 这一类通用 Agent,也有人觉得应用层没什么机会了,最后都会被基模厂商吃掉。
我先说我的判断。
未来 AI 产品化的分化主轴,大概率会围绕三件事展开:谁拥有上下文,谁拿得到执行权限,谁承担结果责任。
模型能力当然重要,但模型能力会越来越像电力、算力、云资源一样,变成所有产品都能调用的基础能力。
真正决定 AI 产品能不能长期成立的,往往要看它站在哪个位置:
• 它能不能拿到用户或组织的真实上下文; • 它有没有权限进入系统、调用工具、操作流程; • 它输出的结果有没有人验收、追责、复盘和持续改进; • 它有没有入口和分发能力; • 它会不会在半年到一年内,被模型厂商或平台厂商顺手覆盖。
所以我更倾向于把未来 AI 产品化理解成一场产品位置竞争,而不只是“谁的 Agent 更聪明”。
更现实的问题是:谁能把 AI 放进一个有上下文、有权限、有责任边界的生产位置。
这个角度下看,未来比较清晰的路径至少有八条。
一、个人 PC/Phone 超级助理:争夺个人上下文和设备权限
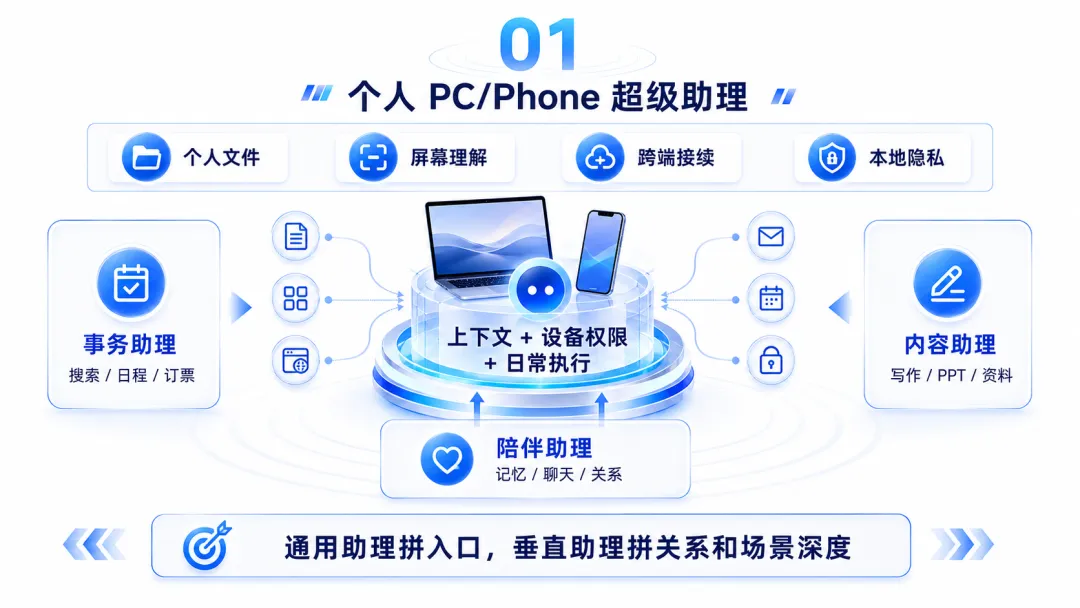
第一条路,是个人 PC/Phone 超级助理。
这类产品的代表,可以看 OpenClaw、Hermes、Marvis、豆包 OS 这一类方向。
名字可以换,形态也会继续变,但产品核心非常清楚:
它们想成为个人设备上的任务入口。
过去的个人 AI 助手,很多还停在聊天、搜索、写作、问答上。现在这一类产品开始向更深的位置走:
• 读取本地文件、图片、网页、应用状态; • 理解屏幕内容; • 控制浏览器或桌面应用; • 跨 PC、Phone、微信、浏览器接续任务; • 在本地模式和云端模式之间切换; • 帮用户处理日程、搜索、总结、提醒、订票、填表、轻办公。
Marvis 官网直接把自己描述成“操作系统层级 AI 助手”,强调本地文档和图片搜索、跨 PC/手机/微信多端在线、自然语言控制电脑设置、本地模式和敏感文件不上云。
豆包相关隐私政策里,也能看到“任务模式”调用浏览器、执行点击和输入、对页面截屏后做屏幕内容理解、用户可随时接管等描述。
这些信息放在一起看,信号已经很明确:
个人 AI 助手的竞争,开始从对话框推进到屏幕、权限和任务执行。
这类产品的增长空间很大。
因为个人生活里有大量碎片任务:查资料、找文件、订行程、改设置、整理照片、回复消息、总结会议、做简单表格、准备材料、陪伴聊天。
更重要的是,个人用户的很多需求并不需要复杂组织协同。一个人授权,一个人验收,一个人承担风险,产品闭环相对短。
所以个人超级助理会天然覆盖三个方向:
• 事务助理:搜索、整理、提醒、日程、订票、填表; • 内容助理:写作、图片、视频、PPT、资料汇总; • 陪伴助理:聊天、情绪支持、长期记忆、个人关系陪伴。
但这条路也有非常硬的门槛。
普通创业公司很难靠一个 App 直接吃下这个市场。
核心门槛在入口和权限。
手机厂、操作系统厂、超级 App、浏览器、模型厂商,会天然占据更强的位置。它们能拿到设备权限、应用入口、账号体系和用户习惯。普通创业公司如果切个人助理,最好避开“大而全的入口争夺”,去做更垂直、更有情绪价值或更专业的场景。
比如特定人群的陪伴、特定职业的个人工作台、特定设备上的智能助手、特定内容资产的长期管理。
通用个人助理拼的是入口,垂直个人助理拼的是关系、记忆和场景深度。
这里还会长期存在几个风险:
• 隐私数据如何处理; • 本地模式和云端模式如何取舍; • 自动操作出错怎么处理; • 长期记忆如何可控、可删、可解释; • 陪伴产品如何避免过度依赖和伦理问题。
所以这条路会很热,也会很难。
它的终局更像个人设备上的一层智能操作界面,单个孤立 App 很难承载这个位置。
二、组织/企业工作助理:企业会买单,但买的是稳定干活
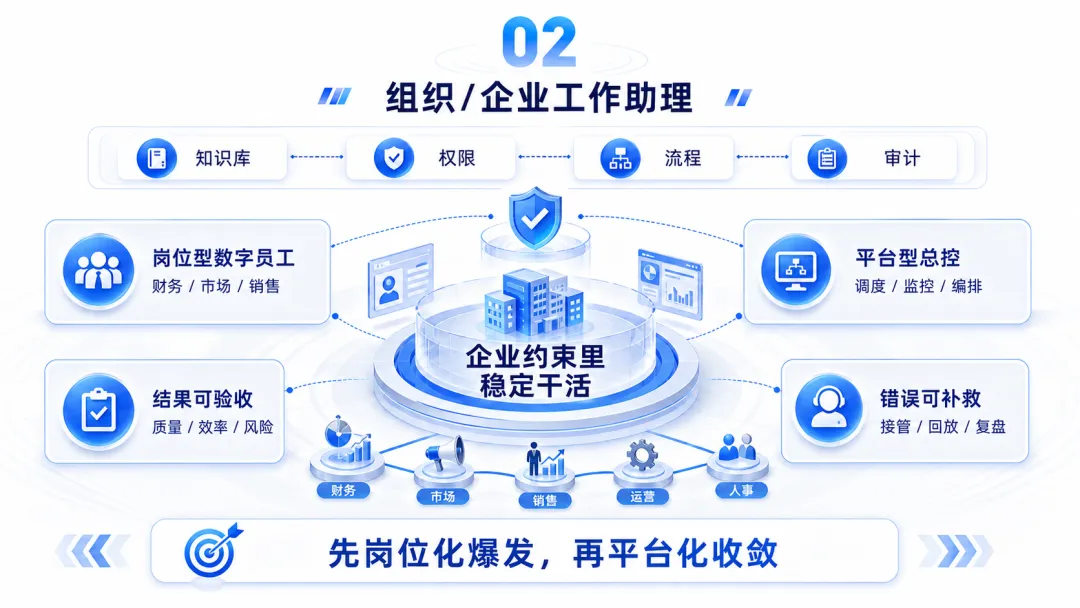
第二条路,是组织和企业工作助理。
这一类可以看云商封装的 OpenClaw,也可以看 OPCS 这类组织协同系统。更广义地说,未来企业里会出现大量数字员工:
• 超级搜索助理; • PPT 助理; • Excel 助理; • 财务数字员工; • 市场数字员工; • 销售运营助理; • 招投标助理; • 法务初审助理; • 客服质检助理; • 数据分析助理。
这类产品和个人助理看起来相似,底层差异很大。
个人助理主要服务一个人,企业助理要进入组织。
组织意味着什么?
意味着权限、流程、审计、知识库、业务系统、部门协同、岗位责任、数据安全。
一个个人助理帮我订错一张票,我自己承担后果。一个财务数字员工算错应收账款、一个市场数字员工错误投放、一个法务助理漏掉关键条款,企业不能用“模型偶尔会错”来搪塞。
企业买单的理由,核心在于 AI 能不能在企业约束里稳定完成一类工作;会聊天只是入口。
所以企业工作助理要越过内容生成,继续解决这些生产问题:
• 能不能连接企业知识; • 能不能识别权限边界; • 能不能调用业务系统; • 能不能保留操作日志; • 能不能交给人审核; • 能不能出错后回放; • 能不能持续优化一类任务; • 能不能在组织里被管理。
这条路的机会非常大。
因为企业里长期存在大量“流程里的知识劳动”。这些工作没有复杂到必须由专家从头判断,也没有简单到可以完全规则化。过去靠人、模板、Excel、邮件、IM、审批流硬撑,效率低,质量也不稳定。
AI 的进入,会先改造这些岗位中相对标准的部分。
比如市场数字员工不一定能替代市场负责人,但可以先做竞品监测、素材整理、活动复盘、公众号初稿、线索清洗、销售话术整理。
财务数字员工不一定能替代财务总监,但可以先做凭证归类、异常提醒、回款跟踪、经营报表解释、预算偏差分析。
销售运营助理不一定能替代销售管理者,但可以先做客户信息补全、商机推进提醒、会议纪要抽取、报价材料生成、合同条款检查。
组织工作助理最好的切入点,往往是边界清晰、结果可验收、错误可补救的知识劳动。
这类产品未来会出现两种形态。
一种是平台型。
企业买一个总控平台,把知识库、流程、权限、系统连接器、数字员工编排、审计和监控统一管起来。OPCS 这类系统就更接近这个方向。
另一种是岗位型。
厂商直接做某个岗位的 AI 产品,比如财务 AI、HR AI、销售运营 AI、市场 AI、采购 AI。这类产品更容易售卖,也更容易讲清 ROI,但长期会面临平台整合问题。
我更倾向于认为,企业市场里会先岗位化爆发,再平台化收敛。
因为企业采购往往从一个明确痛点开始,不会一上来就为“未来组织智能操作系统”买一个大平台。
但当数字员工越来越多,统一权限、统一审计、统一知识、统一调度就会变得非常必要。
三、语义层和数据基建:企业 Agent 想稳定,迟早要补业务世界模型
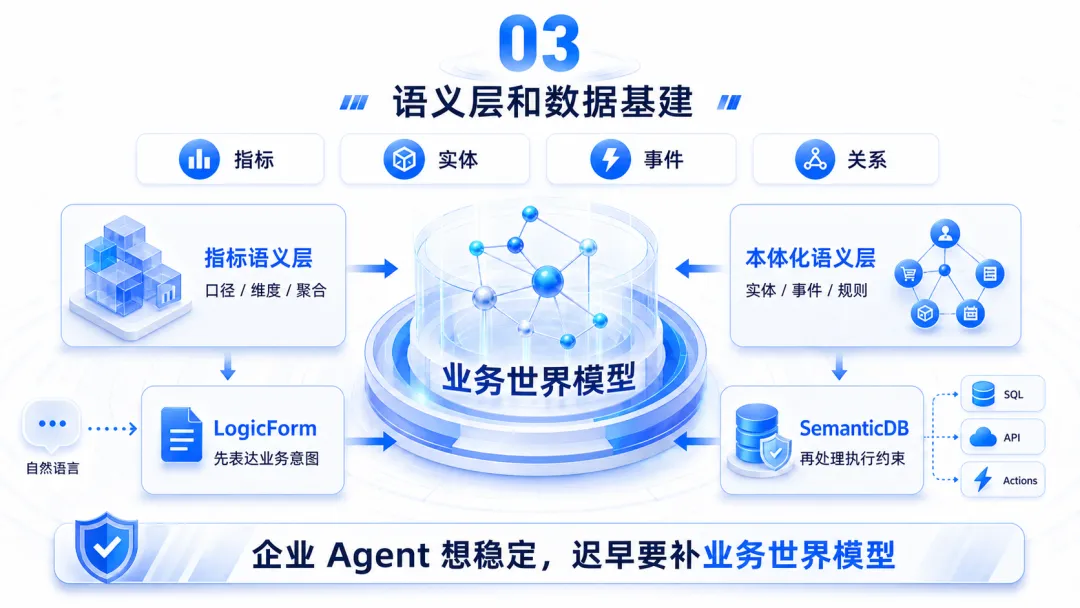
第三条路,是以语义层为锚点的数据基建路线。
现在很多人一讲企业 Agent,就会把重点放在模型、工作流、RAG、MCP、工具调用上。这些当然重要,但在经营分析、财务分析、销售分析、供应链分析、数据问答这些场景里,还有一个更底层的问题:
AI 到底怎么理解企业业务世界?
企业里的数据远比一堆表复杂。
同一个“客户”,可能在 CRM、订单、合同、发票、售后系统里都有不同字段。
同一个“收入”,可能涉及确认口径、时间口径、退货规则、渠道拆分、权限规则。
同一个“转化率”,可能在市场、销售、运营团队里含义不同。
同一个“下滑原因”,可能要串起客户、区域、商品、价格、库存、活动、竞品、渠道、销售动作。
如果这些业务语义没有被稳定建模,Agent 就只能在 prompt 里临场猜。
这就是很多企业 AI 数据应用演示很好看、生产一落地就开始抖的原因。
企业 Agent 想进入核心业务,迟早要补一层“业务世界模型”。没有语义层,Agent 的聪明会停在演示里。
海外主流厂商已经在用不同语言往这个方向走。
dbt Semantic Layer 强调一致、可靠的数据指标;Cube 的数据模型把业务实体、度量、维度、实体关系和 knowledge graph 串在一起;Palantir Foundry Ontology 长期围绕对象、关系、动作来组织业务系统。
这些路线不完全一样,但背后有一个共同趋势:
企业 AI 如果只靠模型读库表,稳定性很难进入生产级。
它需要一层稳定的业务表达。
这里要把两件事讲清楚。
指标语义层依然很有价值。
它解决的是指标、维度、聚合口径、时间粒度、权限和消费一致性。对于 BI、自助分析、经营看板、标准化报表,它仍然是非常重要的基础设施。
但 Data Agent 要解决的问题更宽。
它要回答的问题更宽:
• 这个业务对象是谁; • 它处在什么状态; • 发生了什么事件; • 事件之间有什么关系; • 变化从哪里开始; • 应该沿着什么路径继续分析; • 哪些动作可以被执行。
这就需要本体化语义层。
更准确的表达是:本体更适合作为语义层内部更高阶的建模方式。相对于指标语义层,本体化语义层抽象更高、表达范围更广、对 Agent 更友好。
很多系统是在教 AI 认指标,下一阶段更关键的是教 AI 认业务世界。
这也是为什么我一直认为,语义层会成为基建厂商和部分咨询厂商面向未来的一条重要路径。
数据基建厂商有数据入口、查询引擎、数据治理和企业客户基础。
咨询厂商有业务流程理解、行业模型、组织变革经验。
如果两类能力能结合起来,就会形成面向企业 Agent 的“业务语义基础设施”。
它的价值会越过 NL2SQL 准确率本身。
更核心的是把自然语言先转成业务意图表达,再由语义基础设施处理指标、实体、事件、关系、权限、时间和执行路径。
直接让模型写 SQL,是把业务理解和物理执行压在一次生成里;LogicForm 之类的路线把业务意图和执行细节拆开,系统稳定性会高很多。
这条路短期看不如个人助理热闹,长期看更接近企业 AI 的地基。
四、SaaS 超级 App Agent 化:存量入口的生死战
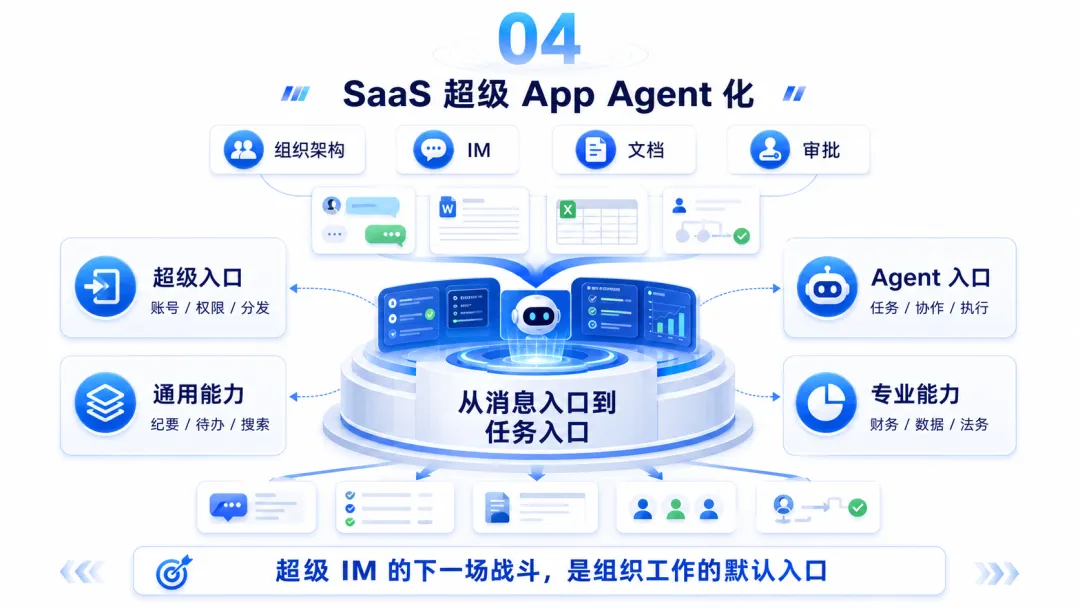
第四条路,是 SaaS 超级 App 的 Agent 化。
钉钉、飞书、企业微信、Slack、Microsoft 365、Google Workspace 这一类产品,本来就占着企业协同入口。
它们有几个天然优势:
• 组织架构在里面; • 消息和会议在里面; • 文档和审批在里面; • 项目和任务在里面; • 权限和账号体系在里面; • 用户每天都打开。
所以它们拥抱 Agent,是非常自然的事情。
钉钉官网现在已经把自己放在“AI 时代工作方式”的表述里,页面里也出现了 Agent OS 执行终端、AI 随身助理等产品信号。
飞书 / Lark 的公开页面,也把自己定位为包含聊天、文档、会议、工作流自动化和 AI 的 productivity superapp。
这些动作背后的逻辑很清楚:
IM 只是消息入口,Agent 会变成任务入口。
过去用户在群里讨论、发文档、开会、审批。以后很多工作会变成:
“帮我把这个会议结论转成任务。”
“把这个客户的历史记录、合同、工单和销售纪要整理成一页简报。”
“根据这个项目进度,提醒相关负责人补齐风险项。”
“从这些群消息里抽出本周需要我处理的事项。”
这时候,协同软件如果还只停在聊天、文档和审批,很容易从企业操作入口退化成消息管道。
超级 IM 的下一场战斗,会从“多一个 AI 按钮”,转向“能不能把 Agent 变成组织工作的默认入口”。
这条路会带来两个结果。
第一,很多轻量 AI 应用会被协同平台吸收。
比如会议纪要、文档总结、待办提取、简单流程自动化、群聊问答、知识库搜索。这些能力一旦成为协同平台内置功能,独立产品的生存空间会明显变窄。
第二,协同平台也会遇到专业深度不够的问题。
它可以做通用入口,但未必能深入财务、供应链、数据分析、研发管理、法务审查这些专业场景。
所以 SaaS 超级 App Agent 化之后,市场不会只剩平台厂商。更可能出现一种关系:
• 超级 App 提供入口、账号、组织和分发; • 专业 Agent 提供行业能力和业务深度; • 数据语义层提供可信业务理解; • 连接器和权限层负责接入企业系统。
谁能在这个体系里占到关键位置,谁就有机会留下来。
五、应用层 AI:最容易热闹,也最容易被压缩
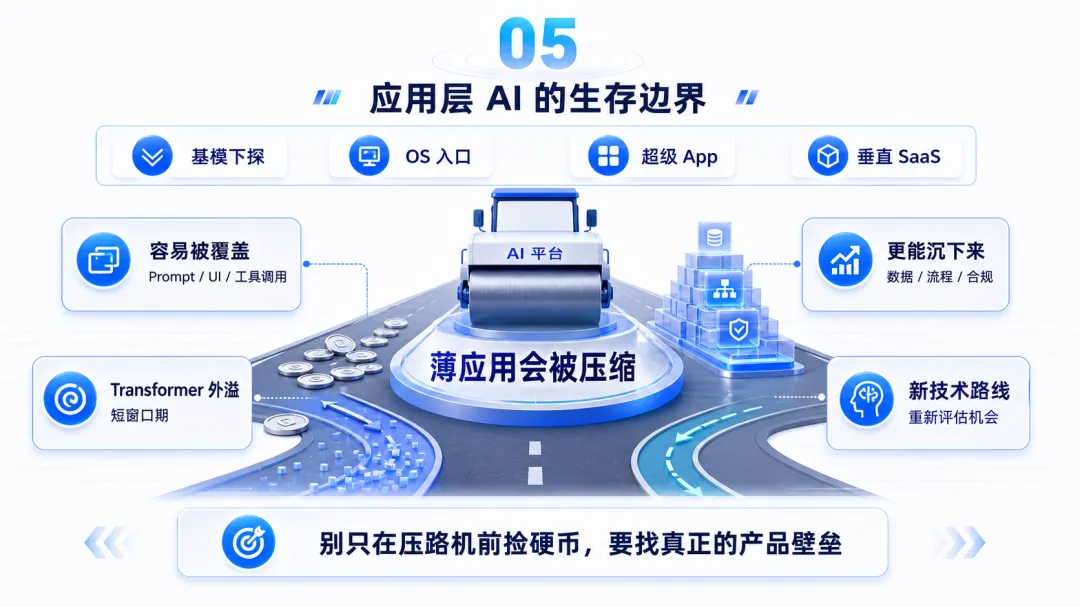
第五条路,是各种应用层 AI。
这一块会非常热闹,也会非常残酷。
过去两年,市面上出现了大量 AI 应用:
• AI 写作; • AI PPT; • AI 表格; • AI 设计; • AI 数据分析; • AI 搜索; • AI 浏览器; • AI 销售助理; • AI 客服; • AI 法务; • AI 招聘; • AI 通用任务 Agent。
这里当然会跑出公司,但也会死掉很多项目。
原因很直接:基模厂商、OS 厂商、云厂商、超级 App、垂直 SaaS 都在往下吃。
如果一个应用的核心能力只是“调用模型 + 写一段 prompt + 做一个 UI + 调几个工具”,它很容易被平台迭代覆盖。
这就是那句很形象的话:
很多应用层 AI,像是在压路机前捡硬币。硬币是真的,风险也是真的。
Manus 这一类通用任务 Agent 给市场的启发也在这里。
通用 Agent 当然有价值。它让大家看见了“模型 + 浏览器 + 工具 + 任务规划”的组合能力。
但如果壁垒主要来自通用执行链路,窗口期就会非常短。模型厂商、浏览器厂商、OS 厂商、云厂商,都有动机把这件事做成基础能力。
这里有一个值得单独拎出来的例外。
如果一个产品底层押注的路线跳出了当前主流 Transformer 框架,它面对的竞争逻辑会不一样。
比如未来如果出现更适合长时序推理、低成本端侧运行、连续世界建模、动作规划、具身智能或强记忆系统的新架构路线,应用层厂商就可能从“调用基模做包装”,切换到在新一代能力曲线上抢早期位置。
这类机会当然存在,但门槛也会高很多。
它考验的是团队有没有模型、算法、系统工程和场景闭环能力,而不只是产品经理会不会包装一个 Agent。状态空间模型、类 RWKV 路线、世界模型、神经符号混合、专用小模型集群,未来都有可能在某些场景里切出新空间。
所以“压路机前捡硬币”这句话,主要针对沿着 Transformer 基模能力外溢做薄应用的项目。
如果真正在底层技术路线上另起一条能力曲线,风险和机会都要重新评估。
所以应用层 AI 想长期成立,最好至少抓住一个硬东西:
• 专有数据; • 专业工作流; • 强交付结果; • 行业合规; • 系统集成; • 客户渠道; • 长期使用形成的组织记忆; • 复杂场景里的责任闭环。
越靠近通用对话和通用任务,越容易被基模和入口挤压;越靠近行业责任、业务流程和私有上下文,越有机会沉下来。
这也是我判断一个 AI 产品能不能做时,最常问的问题:
半年后,GPT、Claude、Gemini、豆包、通义、DeepSeek、手机厂、钉钉、飞书,会不会顺手把它做掉?
如果答案很可能是会,那就要继续追问:
你凭什么还能活?
靠品牌?
靠渠道?
靠行业经验?
靠客户数据?
靠系统集成?
靠交付能力?
靠合规门槛?
靠用户每天离不开的工作流?
如果这些都没有,这件事就要谨慎。
六、开发者和创作者工作台:真正的机会在 Harness

第六条路,开发者和创作者工作台。
这包括 AI Coding、AI 设计、AI 视频、AI PPT、AI 文档、AI 数据分析、AI 研究工作台等。
它们和普通办公助理不同。
这些产品服务的是专业生产者。用户说“帮我聊两句”时,背后真正要的是一个可交付的作品:
• 一段能跑的代码; • 一个能发布的页面; • 一份能对外讲的 PPT; • 一篇能发的文章; • 一个可复用的设计系统; • 一个能验证的数据分析结论; • 一个可以继续迭代的项目资产。
所以这类产品真正值钱的地方,生成能力只是起点。
专业工作台的核心在 Harness:需求澄清、版本控制、资产管理、审查、测试、回滚、协作和交付。
AI Coding 就是最典型的例子。
如果只是让模型写代码,初期很惊艳,复杂项目很快会失控。
真正接近工程级的做法,一定会把开发拆成:
• 需求澄清; • 原型和设计; • 功能矩阵; • 技术方案; • 开发台账; • 测试; • Code Review; • 回归; • 真实浏览器验证; • Git 提交; • 文档沉淀。
AI 设计、AI PPT、AI 写作也是一样。
越专业的工作,越需要上下文管理、资产复用、质量审查和交付标准。
OpenAI 的 Computer-Using Agent、Apps SDK,Anthropic 的 computer use 方向,都说明一个趋势:模型正在获得操作软件、调用工具、进入应用生态的能力。
当这些底层能力逐渐平台化,专业工具厂商真正要做的,就是把它们组织成可控工作流。
所以我对“一个输入框生成一切”的专业工具叙事比较谨慎。
它适合演示,不适合长期生产。
真正有机会的专业工作台,会越来越像一个带 AI 的控制台:
• 有任务; • 有资产; • 有版本; • 有审查; • 有权限; • 有评估; • 有交付物; • 有团队协作。
七、AgentOps、安全治理和权限审计:不性感,但会越来越刚需

第七条路,是 AgentOps。
这条路现在不如个人助理和数字员工热闹,但企业一旦真的让 Agent 干活,它就绕不开。
只要 Agent 开始调用工具、访问系统、操作数据、代表员工执行任务,就会出现一串问题:
• 它看了什么数据; • 它为什么调用这个工具; • 它有没有越权; • 它有没有被提示注入攻击; • 它有没有泄露敏感信息; • 它执行了哪些动作; • 它的结果谁审核; • 它出错后如何回放; • 它的成本怎么控制; • 它的效果如何评估。
这些问题不解决,企业 Agent 就很难从试点走向生产。
企业不会长期接受一个“黑箱员工”。AI 越像员工,审计、权限和治理就越重要。
这条路很像云计算时代的 DevOps、FinOps、安全合规。
一开始大家觉得它是配套能力,后来会发现它本身就是基础设施。
未来企业里很可能会出现专门的 Agent 管理层:
• 管 Agent 身份; • 管工具权限; • 管任务日志; • 管提示词和策略; • 管成本; • 管效果; • 管异常; • 管审计; • 管合规。
这类产品未必适合做爆款,但非常适合做企业级基础设施。
尤其在金融、医疗、政企、制造、能源、零售这些强合规行业,AgentOps 会越来越重要。
因为这些行业不缺 AI 试点,缺的是把 AI 放进生产系统之后还能被管理。
八、连接器、MCP、RPA 和执行层:让 Agent 真正进系统
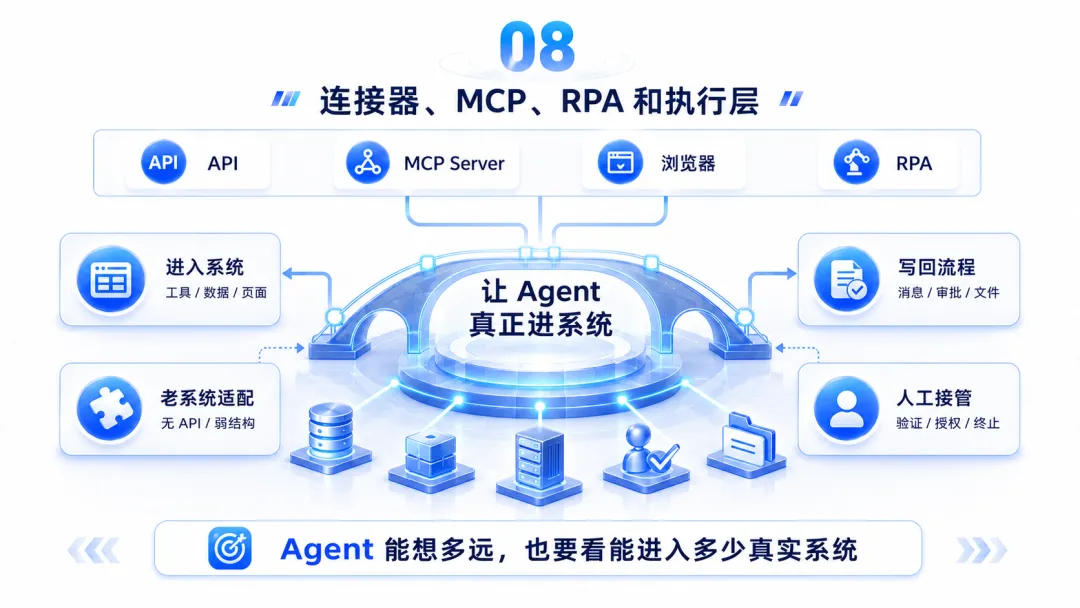
第八条路,是连接器和执行层。
很多 Agent 产品会卡在一个很尴尬的位置:
它知道该做什么,但进不了系统。
它能写出步骤,但没有 API。
它能理解页面,但不能稳定操作。
它能生成内容,但不能把内容放回业务流程。
这时候,连接器、MCP、RPA、浏览器自动化、API 编排、企业应用适配层,就会变得非常关键。
OpenAI Apps SDK 基于 MCP 连接外部工具和数据,已经说明了这个方向的重要性。
MCP 的意义超出了技术协议本身,它把“模型如何进入外部世界”这件事标准化了一部分。
但企业里会同时存在 MCP 之外的多种接入方式。
大量老系统没有标准 API,大量页面没有良好结构,大量权限体系分散在不同应用里,大量流程仍然靠 Excel、邮件、IM 和人工操作拼起来。
所以执行层会同时包含几种能力:
• API 连接; • MCP Server; • 浏览器操作; • RPA; • 文件读写; • 数据库访问; • 消息系统接入; • 审批流接入; • 权限映射; • 人工接管。
Agent 的价值同时取决于两件事:它能想多远,以及它能进入多少真实系统。
这条路会诞生很多看起来很“脏”的产品。
它们不一定炫酷,但很值钱。
因为企业落地里,最麻烦的部分经常绕过了模型本身,落在怎么把模型接进已有系统、已有流程和已有权限上。
谁能把这层做扎实,谁就有机会成为企业 Agent 的水电煤。
九、做 AI 产品前,先问自己七个问题
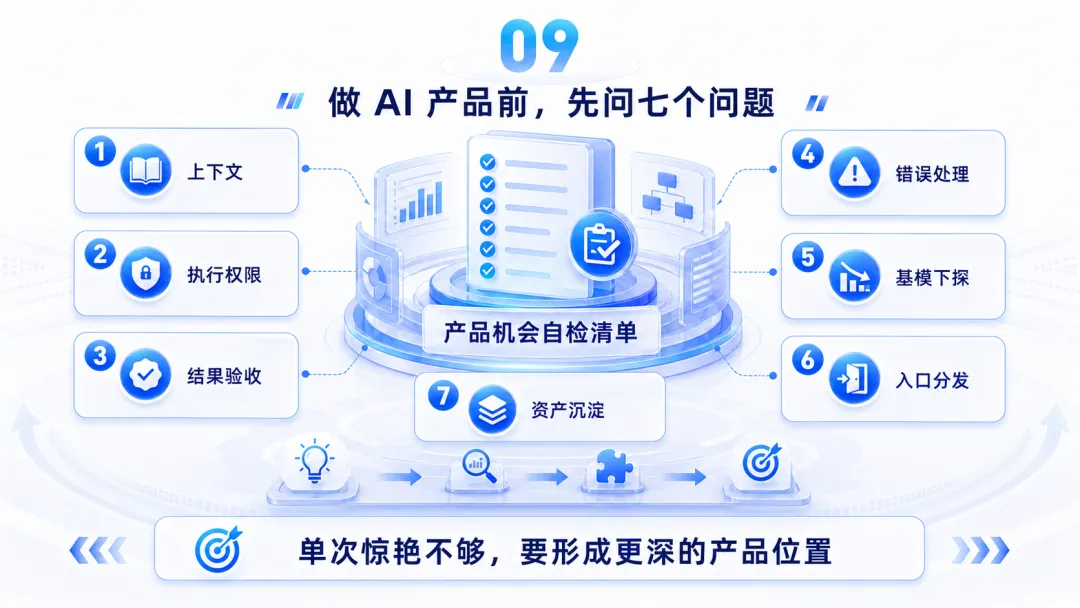
如果把上面八条路收起来,我觉得未来判断 AI 产品机会,可以先问七个问题。
第一,你拿得到什么上下文?
个人上下文、企业知识、业务数据、行业语料、历史操作记录、协作关系,这些东西决定了 AI 能不能比通用模型更懂场景。
第二,你有没有执行权限?
只能回答问题,价值会被压缩。能调用工具、操作系统、进入流程、写回结果,产品位置会高很多。
第三,结果由谁验收?
一个 AI 产品如果没有明确验收标准,就很容易停在“感觉还行”。企业愿意长期付费的产品,通常要能证明效率、质量、风险或收入上的改善。
第四,错误如何处理?
越接近生产,准确率越只是起点。审核、回滚、接管、日志、异常处理和责任边界,都会变成产品的一部分。
第五,半年到一年内,基模厂商会不会做?
这个问题很残酷,但必须问。
如果你的产品能力很通用,且没有专有数据、专有流程、渠道、合规或系统集成壁垒,那就很危险。
还有一个更底层的追问:你的产品是否仍然沿着 Transformer 主流能力外溢在做应用?
如果答案是肯定的,就要假设基模厂商半年到一年内会继续下探。只有当你押注的是新架构、新推理方式、新端侧成本结构、新交互范式,或者某个现有基模很难自然覆盖的专业系统,才有资格把这件事从“应用包装”重新评估成“技术路线机会”。
第六,你占不占入口?
入口决定分发成本。个人入口在 OS、手机、浏览器、超级 App;企业入口在 IM、文档、流程、数据平台、业务系统。
第七,你有没有越用越深的资产沉淀?
比如知识库、语义层、工作流、版本记录、审计日志、行业模型、客户配置、团队协作关系。没有沉淀,产品很容易被替代。
单次生成的惊艳感撑不起 AI 产品化的长期周期。产品要在上下文、权限、责任和资产沉淀上,形成越来越深的位置。
写在最后
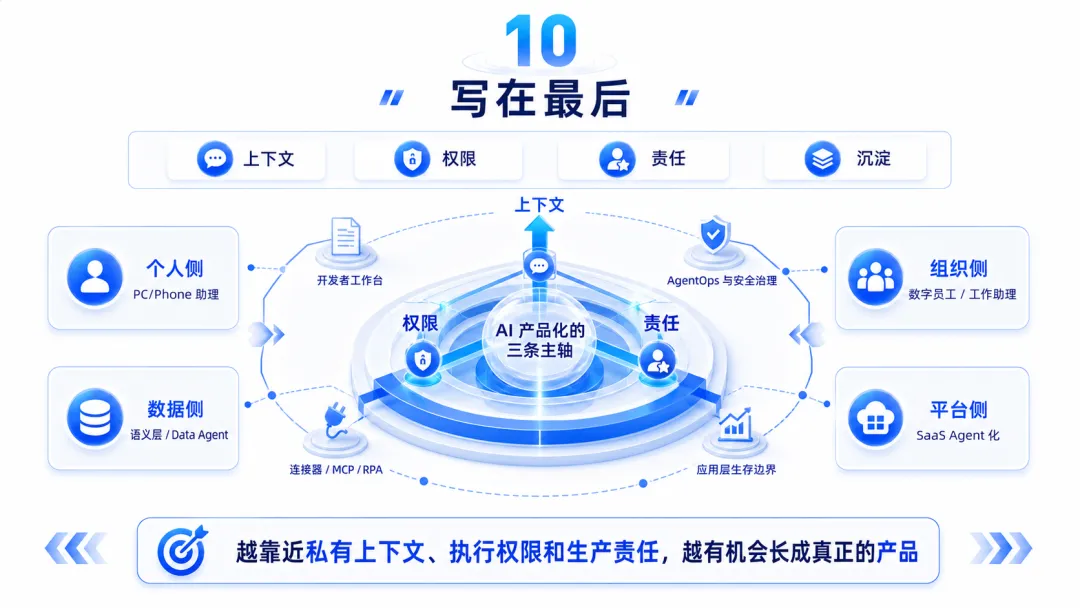
未来 AI 产品化会有多条主线。
个人侧会有 PC/Phone 超级助理和陪伴产品。
组织侧会有数字员工和企业工作助理。
数据侧会有语义层、本体化语义层和 Data Agent。
平台侧会有钉钉、飞书、Microsoft 365、Google Workspace 这类超级入口的 Agent 化。
应用侧会继续出现大量垂直 AI 产品。
底层还会长出 AgentOps、MCP、连接器、RPA、权限审计、专业工作台这些基础设施。
但如果非要压成一句话,我会这么判断:
越靠近通用对话,越容易被入口和基模挤压;越靠近私有上下文、执行权限和生产责任,越有机会长成真正的产品。
这也是我现在看 AI 产品机会时,越来越重视的一点。
模型能力会继续变强。
但产品化竞争的核心,会从模型能力继续向外延展。
真正能沉下来的产品,往往要回答一个更朴素的问题:
它到底进入了谁的工作,拿到了什么上下文,拥有多少执行权限,最后又对什么结果负责?
能回答清楚这个问题,才有资格谈未来。
后续 AI 产品和应用相关的落地方案以及实操就更新到这个公众号了,欢迎大家转发推荐给更多小伙伴,一起来唠 AI 技术嗑。
同时正式做一个活跃的 AI 技术讨论社群,主要关注 OPC、语义层、本体论、数字员工、AI Coding 实践与优化等方向,扫码入群昨天一下午满了,加我微信拉群:fl_manyi
看到这里了,来个 “点赞” 、“关注” 和 “在看” 吧,这是更新最大动力了~
我们下篇见~
