 夜雨聆风
夜雨聆风本月某个周日,我在家改学生们的课程作业,改到十点半的时候突然想到一个问题——我对学生们的课程作业的修改多次用了deepseek最新的V4专家版,每次提问prompt大概耗电多少?我当时没想这个问题,就跟往常一样用了。但那天晚上不知道为什么突然想到了,然后就睡不着了。第二天一早我就开始查资料,一查查了三天,越查越心里不安。我发现这个问题比我想的大得多。而且最让我不安的不是排放量本身,是几乎没人在管这个事。
一、先说几个数,你心里有个底
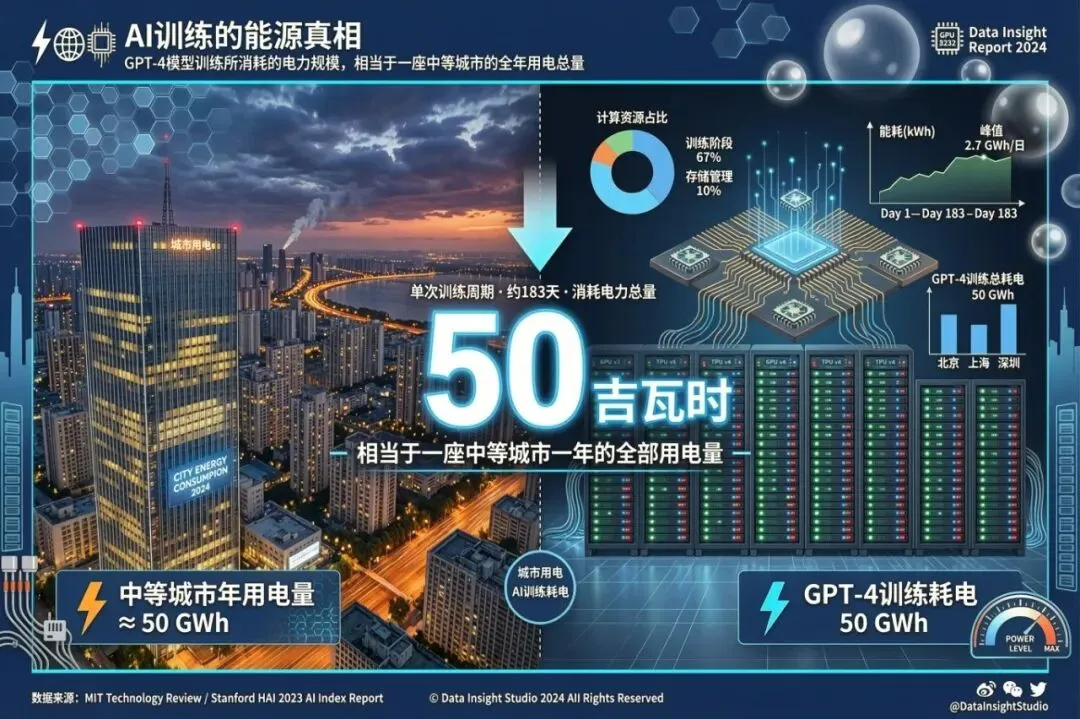
最先说训练。MIT今年发了一篇解释性文章,里面提到了一个数字:训练GPT-4大概耗电50吉瓦时,花了超过1亿美元。五十吉瓦时是什么概念?相当于一个中等城市一年的用电量。就为了训一个模型。而且这只是训练阶段,不包括推理。
再说推理。推理才是大头。你每次向豆包、深度求索、千问等提问,它背后的服务器就在跑,跑就耗电,耗电就排碳。北京大学的一项研究分析了全球369个大语言模型,发现当前全球大语言模型的年耗电量达到24.97到41.1太瓦时。这是什么概念?相当于三峡工程年发电量的40%。三峡啊。三峡是全球最大的水电站,一个三峡就够让很多人想象了,40%的三峡只是为了让大模型跑起来。
由此产生的二氧化碳排放量是1067万到1861万吨。这是华北电力大学丁肇豪教授课题组的研究结果。千万吨级别。什么概念?相当于北京市全年碳排放的十分之一左右。就是说,光是让全球的大模型跑一年,排的碳就跟北京一个超大城市差不多了。
GPT-3单次训练耗电1287兆瓦时,这是斯坦福AI研究所的数据。1287兆瓦时什么概念?相当于3000辆特斯拉各行驶20万公里。就为了训练一个模型。而且GPT-3已经过时了,GPT-4的训练能耗是GPT-3的好几十倍。那GPT-5呢?GPT-6呢?没人知道,因为OpenAI不公布这些数据。你连它排了多少碳都不知道,你怎么管?
我知道有人会说,这点碳跟全球总排放比起来不算什么。对,现在确实不算什么。但问题是它在飞速增长。

二、增长速度才是真正的问题
说几个让我吃惊的数。埃森哲今年发了一份报告,说AI数据中心的碳排放到2030年可能激增11倍。十一倍。你想想这个数字。如果现在是一个北京,到2030年就是十一个北京。康奈尔大学的一个研究团队也算了一笔账,说到2030年,当前速度的AI增长每年会往大气里排入2400万到4400万吨二氧化碳。
还有一个数据让我很意外。Meta的数据中心排放自2019年以来涨了223%。两百二十三个百分点。这家公司可是签了承诺要做碳中和的。签了承诺,排放反而涨了223%。为什么?因为AI。他们在狂建数据中心,狂买GPU,狂训模型。承诺是承诺,业务是业务。当业务和承诺冲突的时候,承诺先放一边。
这不是Meta一家的问题。谷歌也一样。微软也一样。所有在AI上发力的大厂都一样。他们都签了碳中和承诺,然后全部在延迟。为什么延迟?因为没有人逼他们。没有法律说你必须在某个日期前完成碳中和,没有罚则说你完不成就得赔钱。承诺就是一句话的事。
三、水也是一笔大账
现在考察各大公司的ESG报告。谷歌2024年的范围二排放涨了将近50%,微软也差不多。两家都把原因归结为AI数据中心的扩张。但他们的措辞很有意思,说的是“暂时性增长”,意思是以后会降下来的。以后是什么时候?没说。我有个在投行做ESG分析的朋友跟我说了句大实话:“他们说的以后会降,就跟我说以后会减肥一样,你信吗?”
说到AI的环境成本,大多数人只想到电和碳。但水也是一笔大账。数据中心要冷却,冷却要用水。一个中等规模的数据中心每年耗水可以达到1.1亿加伦,相当于一个中等城市的年用水量。而且这还是中等规模的。现在那些专门为AI建的超大数据中心,耗水量只会更多。
有一个研究说,全球AI数据中心的耗水量预计将达到丹麦全国年用水量的6倍。六倍。丹麦虽然小,但也是一个国家的用水量的6倍啊。而且这些水很多是在缺水地区耗的。你知道很多数据中心建在哪里吗?美国的很多数据中心建在俄勒冈州和亚利桑那州,那些地方本身就缺水。中国的很多数据中心建在内蒙古和宁夏,也是缺水地区。为什么建在缺水地区?因为电价便宜,地价便宜,风能太阳能丰富。但水呢?没人想。
我前两天看到一个新闻,说智利的某个县为了引进数据中心,把当地居民的农业用水给切了。当地农民意见很大,但数据中心已经建好了,拆不了。这种事以后会越来越多。因为数据中心建了就是建了,它不会自己搬走,而它每天都要喝水。
有些数据中心为了省水,改用空气冷却。空气冷却不用水,但耗电更多。耗电更多就排碳更多。你省了水,但多排了碳。你省了碳,但多用了水。这两个目标之间是矛盾的,而目前没有任何政策工具来平衡这个矛盾。你到底该省水还是省碳?没人告诉你。

四、谁在埋单?现在的答案是:没人
中国2024年数据中心的用电量大概是166太瓦时,占全社会用电量的1.68%。1.68%听着不多,但增速吓人。而且这还只是2024年的数据,2025年2026年只会更多。如果AI应用真的爆发了,这个比例翻几倍都有可能。到那时候,数据中心用电可能占到全社会的5%甚至10%。这意味着什么?意味着为了跑AI,我们可能得建更多的电厂。建什么电厂?如果是煤电,那AI就是在用碳换智能。如果是绿电,那绿电本来可以用来替代煤电的,现在被AI抢走了,煤电还是得跑。怎么算都不划算。
这让我想到一个更大的问题:我们现在的环境治理体系是分头管理的。碳归生态环境部管,水归水利部管,电归能源局管。但AI的环境影响是整体的,它同时耗电、耗水、排碳、占地。你分头管,每个部门只看自己那一块,就会出这种按下葫芦浮起瓢的事。得有人统筹。但目前没有这样的统筹机制。
AI的碳足迹谁来埋单?现在的答案是没人。或者说,是所有人在埋单,但没人知道自己在埋。
你每次用豆包或千问等的时候,你付了钱吗?如果你用的是免费版,你没付钱。那谁付了?豆包或千问付了电费,付了水费,付了服务器的钱。但它们的的钱从哪来?从投资人那里来。投资人的钱从哪来?从其他业务的利润里来。其他业务的利润从哪来?从消费者那里来。所以绕一圈,还是所有人在埋单。但这个埋单是隐性的,没人知道自己付了多少。
更重要的是,谁承担了环境成本?是数据中心所在地的居民。他们的电被用了,他们的水被用了,他们的空气被污染了。但他们得到了什么?一些就业岗位?一点税收?还是什么都没有?这就是典型的负外部性问题。经济学上说的负外部性,就是有人得了好处不付钱,有人承担了成本不得利。AI的碳足迹就是一个巨大的负外部性。
我在《管理经济学》课上跟学生讨论这个问题的时候,有个学生说了句让我想了很久的话。他说:“老师,我们用AI的时候付的是货币,但地球付的是碳。这两种货币之间没有汇率。”说得太好了。货币和碳之间没有汇率,意思是你花了钱不等于你付了碳的成本。钱进了科技公司的口袋,碳留在了大气里。
五、碳交易能解决吗?不能
有人会说,碳交易不就行了吗?你排了碳,你买碳配额,买了就抵消了。听着很美。
但我觉得碳交易解决不了AI的碳问题。原因有三个。
第一,碳配额本身就是一笔糊涂账。你买的碳配额真的能抵消你排的碳吗?很多碳配额项目根本就不靠谱。种树的说能吸收多少碳,实际上树死了就放出来了。可再生能源的说能替代多少煤电,实际上很多时候煤电还在跑。碳配额很多时候就是一种“赎罪券”,让你觉得自己排的碳被抵消了,其实没有。
第二,数据中心的碳排放还没被纳入全国碳市场。我国的全国碳排放权交易市场目前主要覆盖的是电力、钢铁、建材等行业。数据中心呢?还没被明确纳入。也就是说,数据中心排的碳在现有体系里是“无主”的。没人对它负责,没人为它买单。生态环境部2025年发了一个通知,说要做好2025年全国碳市场的工作,但里面没提数据中心。
第三,即便纳入了,碳价太低也没用。现在全国碳市场的碳价大概几十块钱一吨。几十块钱。对一家年收入几百亿的科技公司来说,这点钱跟没有一样。你让他买碳配额,他买就买了,然后继续排。因为排碳的收益远大于买碳的成本。这就是经济学说的“边际减排成本太低”。你得把碳价提到足够高,高到让他们觉得排碳比减排更贵,他们才会真的去减。但现在的碳价远远不够。
六、三个判断
第一,必须把数据中心纳入碳市场。这是最基本的。你连市场都不让它进,它永远不会有减排的动力。但光纳入不够,碳价得提上去。我的看法是,数据中心的碳价应该比普通行业高,因为它的排放增长速度比普通行业快得多。你排得快,你就得付得多。这才公平。
第二,必须强制披露AI的碳足迹。现在很多公司不披露他们的AI业务排了多少碳。他们披露的是全公司的碳排放,但不单独披露AI部分。你不知道AI排了多少,你就没法监督。这就像你让一个企业披露环保数据,但不让它披露最污染的那条生产线的数据。披露了等于没披露。欧盟在这方面走得前一点,CSRD要求企业披露更详细的环境信息,但专门针对AI碳足迹的披露要求还是没有。
第三,必须有“绿色AI”的标准和认证。现在有机食认证、绿色建筑认证,但没有绿色AI认证。你不知道你用的模型训练时排了多少碳,你不知道它是用煤电训练的还是用绿电训练的。这个信息应该像食品包装上的营养成分表一样,明明白白地写在每个模型的介绍里。这样用户才能做出选择。你可能会说,用户会在乎吗?我觉得会。不是所有人会在乎,但总有人会。而且当越来越多人在乎的时候,市场就会变。
七、一个很不安的预测
有机食品刚出来的时候也很贵,没几个人买。但随着越来越多的人在乎,市场规模越来越大,成本反而降下来了。绿色AI也可以走这条路。当用户开始在乎模型的碳排放,公司就有动力去优化。优化了成本就降了,降了就有更多人用,更多人用就进一步降成本。这是一个正循环。但前提是得有人迈出第一步,而这个第一步得是政策推的。
中国的一项研究说,中国AI碳足迹的碳达峰时间可能推迟至2038年。这意味着什么?意味着因为AI的快速增长,我们原本预计的碳达峰时间被推迟了。国家说的2030年碳达峰,但AI可能让这个目标实现不了。这不是小事。
这个问题跟气候变化本身的问题很像——都是“公地悲剧”。每个人都在用AI,每个人都在排碳,但没人觉得自己的使用会造成问题。因为一个人的使用确实不会造成问题。但几十亿个人的使用叠加在一起,就是火山。而没人为这座火山买单。
八、最后
我有时候想,也许我们得接受一个现实:AI的环境成本问题不会自己解决,它只会越来越严重。除非有人为它设定边界。就像当年治理空气污染一样,不是企业自己想减排的,是法律逼的。AI的碳排放也一样,光靠企业自觉是不够的,得有规则。没有规则的市场就是公地,公地的结局就是悲剧。经济学上叫“公地悲剧”,每个人都在最大化自己的利益,最后所有人的利益都受损。AI的碳足迹就是数字时代的公地。
从数据安全到AI安全,我们已经讨论了很多。但AI的环境安全,几乎没人谈。这才是最大的治理盲区。我们关注AI会不会伤害人,会不会侵犯隐私,会不会失业,但很少有人关注AI会不会让地球变得更热。而这个问题,跟所有人都有关。
参考文献
[1] MIT News (2025). Explained: Generative AI’s Environmental Impact.
[2] 北京大学大数据分析中心 (2025). 当AI学会“创造”,地球却在“碳息”?——全球生成式人工智能的环境成本研究.
[3] 华北电力大学丁肇豪教授课题组 (2025). 大语言模型碳足迹量化研究.
[4] Fortune (2025). AI Data Centers’ Carbon Emissions Could Surge 11-Fold by 2030.
[5] Cornell University (2025). Roadmap Shows the Environmental Impact of AI Data Center Boom.
[6] As You Sow (2025). Meta Platforms Inc: Disclose Climate Transition Plan for Data Centers.
[7] ESG Dive (2025). How Meta is Ramping Up Cleantech Investments Amid the AI Boom.
[8] 生态环境部 (2025). 关于做好2025年全国碳排放权交易市场有关工作的通知.
[9] MIT Technology Review (2025). We Did the Math on AI’s Energy Footprint.
[10] Frontiers in Sustainability (2024). Forecasting US Data Center CO2 Emissions Using AI Models.
[11] 《低碳AI:大模型的绿色训练与推理优化方法研究》,信息通信技术与政策 (2025)
