 夜雨聆风
夜雨聆风在上一个版本中我们做到了“一句话搞定数据处理”。
但很多用户问:万一AI理解错了呢?能不能让我先看看再执行?跑完了能不能看到每一步的进度和结果?今天,πFlow AI 0.6正式开源发布。
我们把“规划”和“执行”拆成了两阶段——AI负责出方案,你负责拍板,执行引擎负责跑。

你对AI说:
“帮我清洗这个文件夹里的CSV,去掉空行,按时间排序。”
0.5版本(旧):
AI直接开始跑,跑完给你结果。如果它把“去掉空行”理解成了“去掉所有带空值的行”,你只能重来。
0.6版本(新):
AI先理解意图,如果需求模糊(比如你没说按哪个时间字段排序),它会追问:
l “请确认排序依据的字段名,是timestamp还是date?”
你回答后,AI生成一个可执行的DAG流程图(JSON格式),然后给你三个按钮:
l【一键运行】:确认无误,交给执行引擎执行
l【打开画板编辑】:手动调整节点或参数
l【导出JSON】:保存流程,以后复用
执行过程中,你可以实时查看节点进度、中间结果、输出文件。跑完了,所有记录都在运行历史里,随时回溯。
一句话总结:0.5是AI说了算,0.6是你说了算。
上一个版本中,大模型同时承担了意图理解、算子匹配、DAG生成和执行调度四个职责。这在简单场景下够用,但在复杂科研任务中暴露几个问题:
1. 不可控:AI生成流程后直接执行,用户无法中间干预
2. 难调试:执行过程黑盒,节点进度和中间输出不可见
3. 不灵活:用户无法手动调整AI生成的DAG
4.长时任务不可靠:大模型推理上下文有超时限制,当数据处理任务需要数小时时,大模型会中断连接,无法继续监控或恢复
这次我们将规划与执行拆分为两个阶段:
l规划阶段:大模型负责意图澄清、算子筛选、生成DAG JSON
l执行阶段:独立的πFlow执行引擎负责解析JSON、调度节点、返回结果
执行引擎接手后,任务独立异步运行,即使处理数小时也不会因大模型会话超时而中断。你可以随时关闭页面,稍后从运行历史中查看完整结果。
用户站在中间,拥有审核、编辑、导出、触发运行的完全控制权。为了让πFlow AI更可靠、更开放,我们重写了执行引擎:
l Python原生,轻量级,便于集成
l 兼容原有πFlow DAG模型,方便老用户替换
l 支持skill.json:每个算子都有独立的脚本、参数、执行指令,执行引擎可快速调用
l 两套JSON体系:
✦DAG JSON:精简结构,专供大模型生成(降低AI出错率)
✦DSL JSON:保留画板细节,用于编辑、存储、还原
简单说:AI做它擅长的事(生成流程),引擎做它擅长的事(高效执行),你做最擅长的事(判断和决策)。
目前平台已积累120个科研算子,覆盖数据清洗、校验、转换、增强等场景。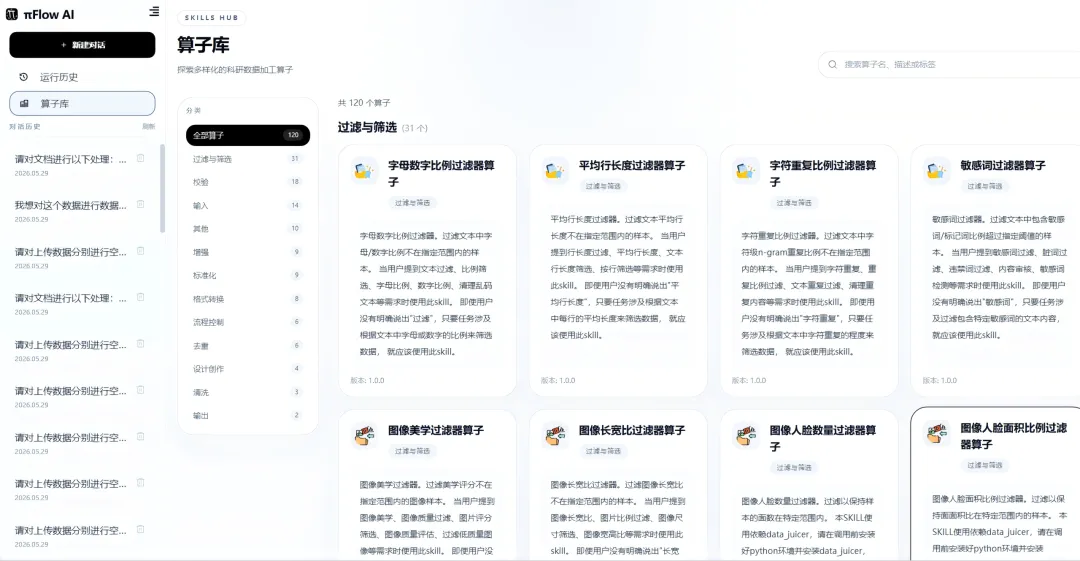
用户: “帮我处理这批实验数据,去重,然后把结果存成Excel。”
Agent:“请问去重的依据是哪个字段?是否需要保留第一条还是最后一条记录?”
用户: “按样品ID去重,保留第一条。”
Agent:
“已为您编排好流程:读取CSV → 按样品ID去重(保留首行)→ 保存为Excel。您可以直接「一键运行」,或「打开画板编辑」,也可以继续告诉我您的调整需求。”
用户点击【一键运行】
执行引擎开始工作,界面实时显示进度条和节点状态。运行结束,输出文件自动出现在工作区。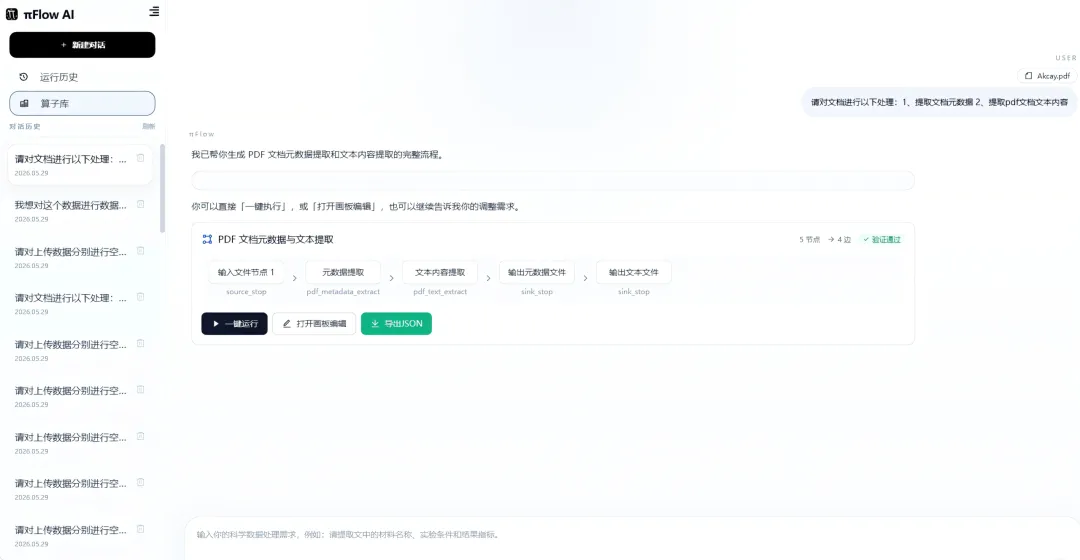
πFlow AI 将持续建设。接下来,团队会重点推进以下工作:
l 扩充科研算子库(目前已积累120个算子,覆盖更多科研场景)
l AI自动生成算子:支持用户用自然语言描述新功能,依托大模型代码生成能力自动编写并调试算子,用户确认后可入库沉淀复用
l 支持更多数据源:接入多种类型的数据来源,满足不同科研需求
l 执行引擎集成大模型算子:在DAG中增加大模型类型的节点(如语义化算子),拓展智能处理能力
l 分布式调度:让执行引擎支持多机协同,提升大规模数据处理效率
l 执行失败智能纠错:当任务失败时,大模型自动分析日志,给出修复建议并自动修改DAG
... ...
欢迎开发者贡献算子、提交PR,或在评论区反馈需求。
让我们一起,打造真正懂科研的智能数据工作台。
项目地址:https://github.com/cas-bigdatalab/PiFlowAI

