 夜雨聆风
夜雨聆风同事用10分钟把100页PDF变成了精排文档,我研究了半天发现她偷偷用了微软这个免费工具
上周开会,同事小张甩出来一份整理好的会议纪要。
格式整齐,层级清晰,连表格都对齐了。
我问她:你搞了多久?
她说:10分钟。
我当时就坐不住了。
因为那份会议纪要的原始材料,是3个PDF文件加上2个Word文档,加起来快100页。
正常整理这些内容,光复制粘贴排版就得半天。

她怎么做到的?
答案是一个微软开源的Python工具——MarkItDown。
今天我就把这套方法完整拆给你看,包括我加的一个小技巧:怎么把AI生成的内容去掉那股"AI味"。
学会了,以后处理文档的效率直接翻倍。
你需要准备什么?
先别怕,这个不需要你是程序员。
只要你会打开命令行(就是那个黑色窗口),照着敲就行。
需要准备的东西就两样:
第一样:Python环境。Mac电脑自带,Windows去python.org下个安装包装上就行。
第二样:一个终端工具。Mac用自带的Terminal,Windows用PowerShell。
没了。真的就这些。
对了,如果你想处理图片里的文字(OCR),还需要装一个叫Tesseract的东西。但这个不是必须的,先跳过也行。
第一步:安装MarkItDown
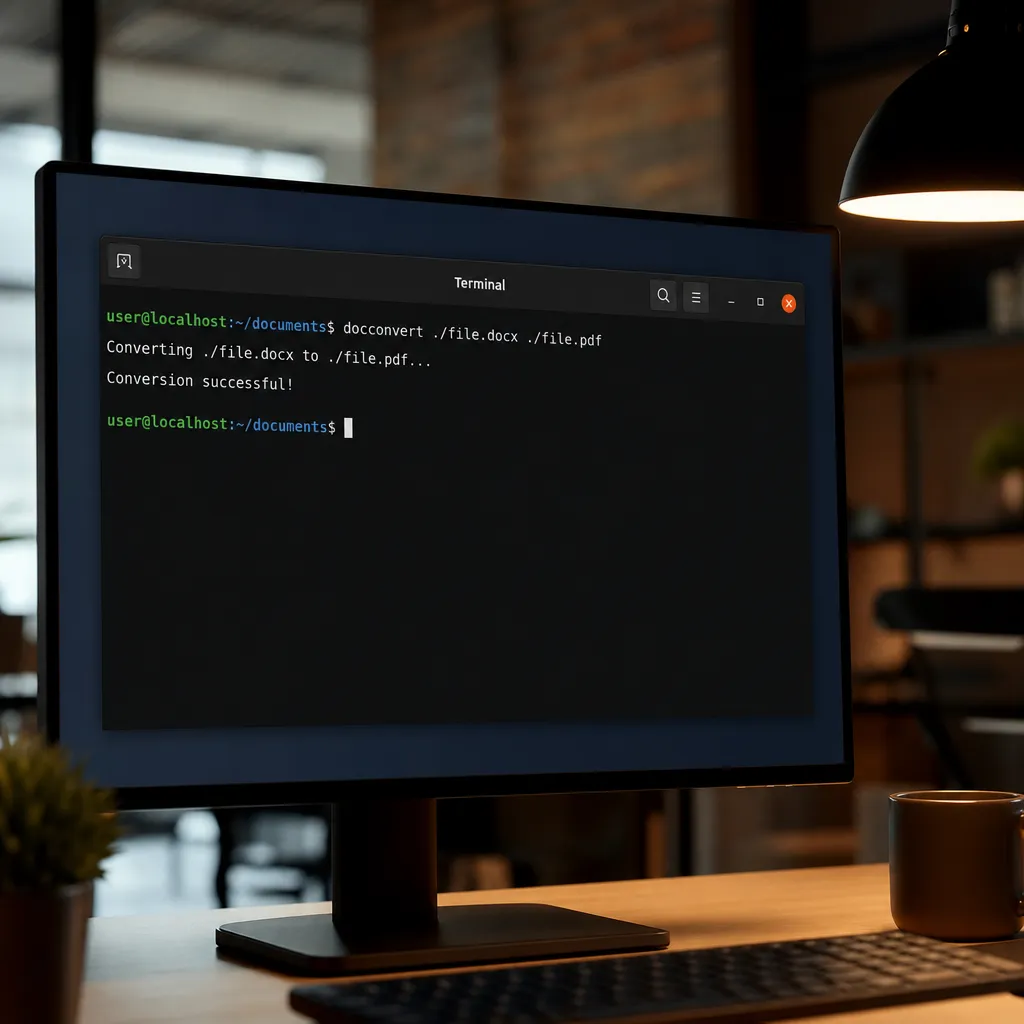
打开你的终端,输入下面这行命令:
pip install markitdown
回车,等它跑完。
如果没有报错,恭喜你,安装完成了。
就这么简单。
微软做的开源项目,安装包管理做得还不错,基本上不会出什么幺蛾子。
如果报错了,大概率是网络问题——你懂的,某些地区访问Python官方源比较慢。
换成国内镜像源就行,这个百度一下"pip换源",30秒搞定。
第二步:转换你的第一个文件
假设你桌面上有一个叫"报告.docx"的Word文档。
在终端里输入:
markitdown 报告.docx > 报告.md
回车,一秒钟就完事了。
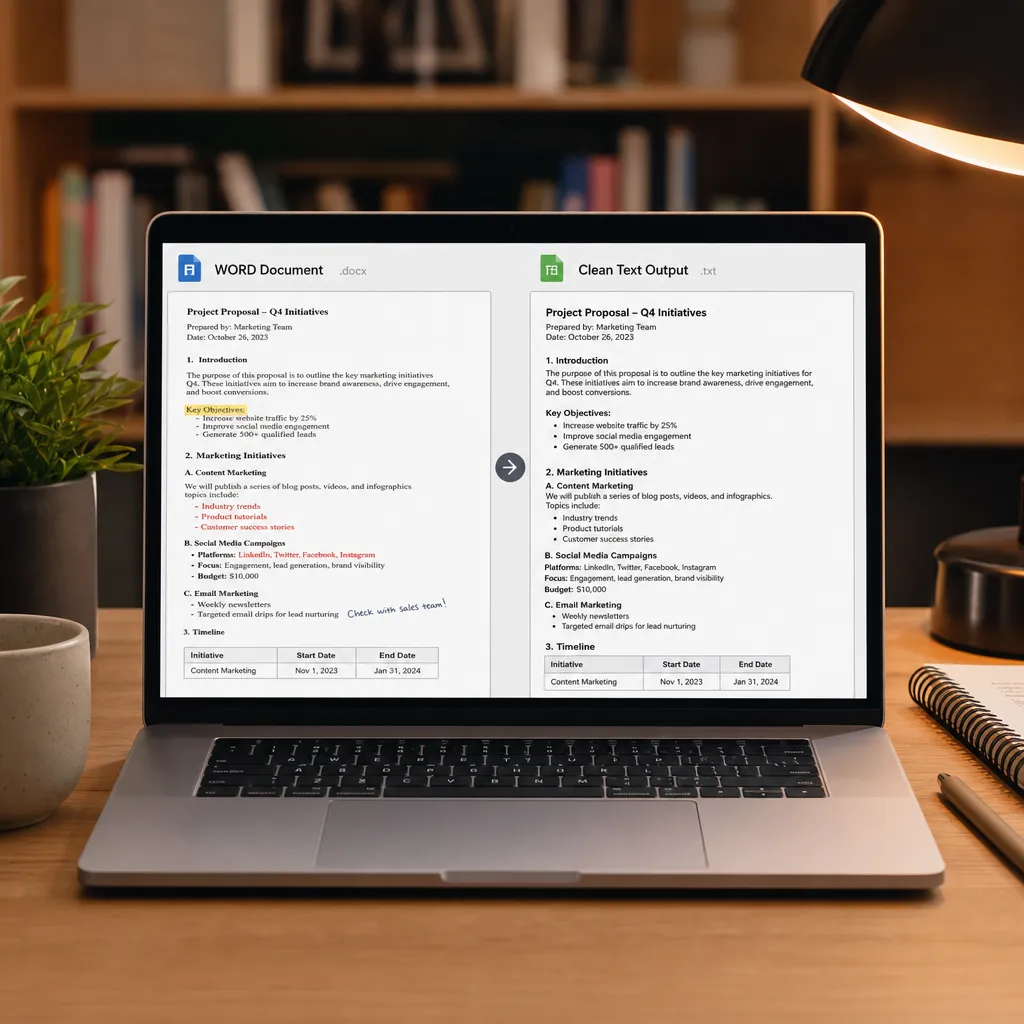
然后你会发现桌面上多了一个"报告.md"文件,打开一看——
Word里的标题变成了Markdown的#标题,
表格变成了Markdown表格,
图片的位置也标记出来了。
就这么简单?对,就这么简单。
我第一次用的时候也觉得离谱。
以前要把Word转成格式化的文本,要么手动复制粘贴,要么花钱买转换工具。
现在一行命令搞定,还是微软官方出的。
第三步:支持哪些文件格式?
这才是重点——MarkItDown不只是转Word。
它支持一大堆格式:
Word文档(.docx)——完美支持,标题、表格、列表都能转。
PDF文件(.pdf)——支持,但扫描版的PDF效果一般,文字版PDF效果很好。
Excel表格(.xlsx)——能转成Markdown表格,数据一个不丢。
PPT演示(.pptx)——每页幻灯片都能转出来,文字和排版都保留。
HTML网页——直接把网页内容提取成干净的Markdown。
纯文本和CSV——自然支持,不需要额外处理。
甚至还能处理Outlook邮件(.msg)和图片(.jpg/.png,需要配合Tesseract做OCR)。
基本上你在办公室能遇到的文件格式,它都能吃。
这覆盖率,够用了吧?
第四步:批量转换才是杀手锏
一个一个转太麻烦?
写个简单的脚本,批量处理整个文件夹。
在终端里输入:
for f in *.docx; do markitdown "$f" > "${f%.docx}.md"; done
这行命令的意思是:把当前文件夹里所有Word文档都转成Markdown。
我上周末试了一下,把公司共享盘里87个会议纪要全转了。
耗时:不到2分钟。
如果手动复制粘贴?我算了一下,一个文档平均5分钟,87个就是7个多小时。
2分钟对7小时,你自己算这个效率提升。
而且转出来的Markdown格式非常统一,不会有手动操作时"这个忘了加粗""那个表格歪了"的问题。
第五步:把AI味去掉
转出来的Markdown,如果还需要用AI进一步处理(比如总结、改写),就会遇到一个问题。
AI改写出来的文字,总有一股"AI味"。
什么"值得注意的是""让我们来看看""总而言之"——一看就是AI写的。
GitHub上最近有个项目叫stop-slop,专门解决这个问题的。
它的原理很简单:给AI一个"品味指南",告诉它什么该写、什么不该写。
比如禁止使用那些AI常说的套话,要求用更口语化、更有个人风格的表达。
安装也很简单,但这个需要配合你用的AI工具(比如Claude、ChatGPT)。
核心思路是:在给AI的指令里加上约束——
"不要用'值得注意的是''让我们''总而言之'这些词。"
"用朋友聊天的语气写,不要用书面语。"
"可以偶尔吐槽,不要太正经。"
就这么几个简单的约束,AI输出的内容质量立刻不一样了。
我从"一看就是AI写的"变成了"哎,这个写得还行嘛"。
这个小技巧,是我最近用得最多的。
效果对比
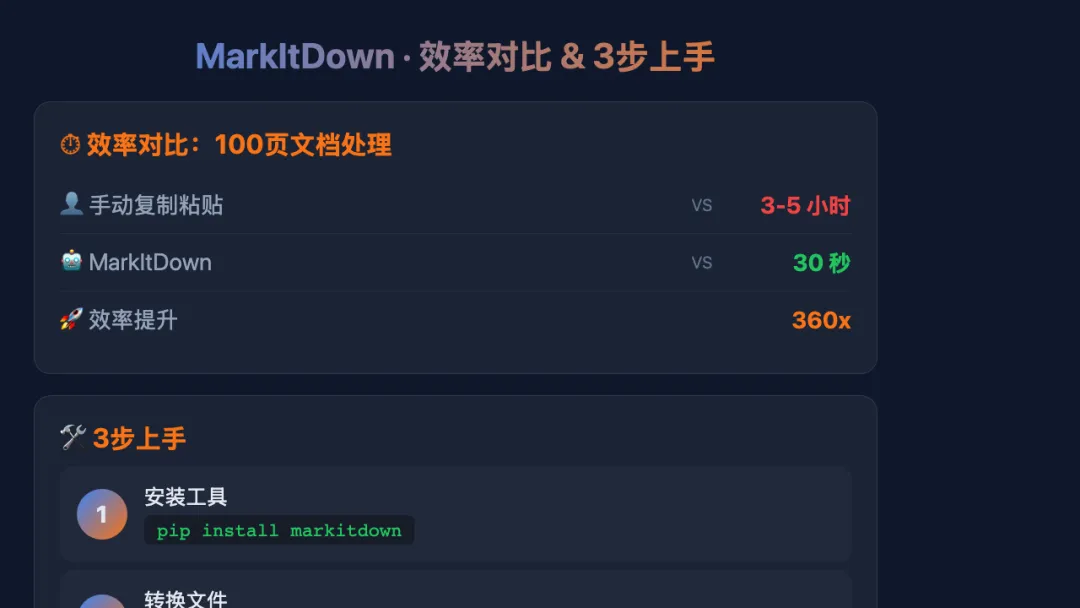
| 维度 | 手动处理 | MarkItDown |
|---|---|---|
| 100页PDF转换时间 | 3-5小时 | 30秒 |
| 格式一致性 | 看手速,容易出错 | 统一标准,零失误 |
| 批量处理 | 重复劳动,容易崩溃 | 一行命令搞定 |
| 学习成本 | 零门槛 | 需要会敲命令行 |
| 价格 | 免费(但费命) | 免费 |
进阶技巧
基础用法会了,再教你几个隐藏玩法。
技巧1:配合AI做文档摘要。
先用MarkItDown把文档转成Markdown,然后把Markdown扔给ChatGPT或者Claude,让它帮你做摘要。
这比直接把PDF扔给AI效果好得多——因为Markdown格式AI理解起来更准确。
技巧2:写自动化流水线。
如果你经常需要处理同类文档(比如每周的会议纪要),可以写个脚本自动跑。
设置一个定时任务,新文件放进来就自动转换,转完自动发到你的邮箱或者飞书。
当然,这个需要一点编程基础。
不会写代码也没关系,可以让AI帮你写——你只需要描述清楚需求就行。
技巧3:搭建成知识库。
把转换出来的Markdown文件放到一个统一的文件夹里。
然后用Obsidian或者Notion之类的工具打开——瞬间就有了一个可搜索的文档知识库。
以后找资料不用翻半天文件夹了,直接搜索关键词。
这招是我自己用得最多的,强烈推荐。

泼冷水
说了这么多好处,该说说不好的地方了。
第一,扫描版PDF效果差。
如果你的PDF是扫描件(就是那种用扫描仪扫出来的图片型PDF),MarkItDown转换出来基本是空的。
因为它不能直接识别图片中的文字,需要配合OCR工具。
而OCR的准确率取决于扫描质量,手写的、模糊的基本没戏。
第二,复杂排版会丢失。
多栏排版、嵌套表格、图文混排这些复杂格式,转换后会有信息丢失。
Markdown本身就是一种简洁格式,它不是用来还原复杂排版的。
如果你的文档有很多特殊格式,转换完记得检查一遍。
第三,需要命令行基础。
这可能是最大的门槛了。
虽然只有一行命令,但对完全没用过终端的人来说,打开那个黑色窗口就已经紧张了。
不过说真的,这个门槛真的很低——你会用手机就行。
命令行就是用文字代替手指点屏幕,本质上没什么区别。
第四,不处理图片内容。
文档里的图片,MarkItDown会标记出位置,但不会帮你识别图片里的内容。
如果你的文档里有很多图表和数据可视化,这些信息转换后会丢失。
需要手动处理或者配合其他OCR工具。
值不值得学?
如果你日常工作涉及大量文档处理——每周要整理会议纪要、要转换各种格式的文件、要做资料汇总。
那花30分钟学会这个工具,后面能帮你省几百个小时。
如果你很少处理文档——那看看就行,不需要专门学。
工具这东西,不用的技能就是废技能。
但如果你有哪怕一点点需求,我建议你试试。
因为一旦你体会到"一行命令解决半天工作量"的感觉,你会打开一个新世界。
这不是夸张,是过来人的经验。
好了,今天就到这里。
我是小王,一个帮普通人筛AI工具的安全从业者。
你平时处理文档最头疼的是什么?评论区说说,说不定我能帮你找到更合适的工具。
