 夜雨聆风
夜雨聆风你有没有被一份 PDF 折磨到怀疑人生?
周五下午 5 点,老板甩来一份 50 页的年度报告 PDF,让你「下班前喂给 AI 做个摘要」。
你信心满满地打开文件,复制文字粘贴到 ChatGPT——结果表格全散架,标题混成一坨,图表变成乱码。你试着用在线转换工具,免费版只能转 3 页。你咬牙花 29 块开了会员,转出来的 Markdown 还是惨不忍睹。
最后你只能手动一行行敲,敲到晚上 10 点,腰也酸了眼也花了,老板已经回家了。
如果你经历过这种痛苦,今天这把「瑞士军刀」你一定要认识一下。
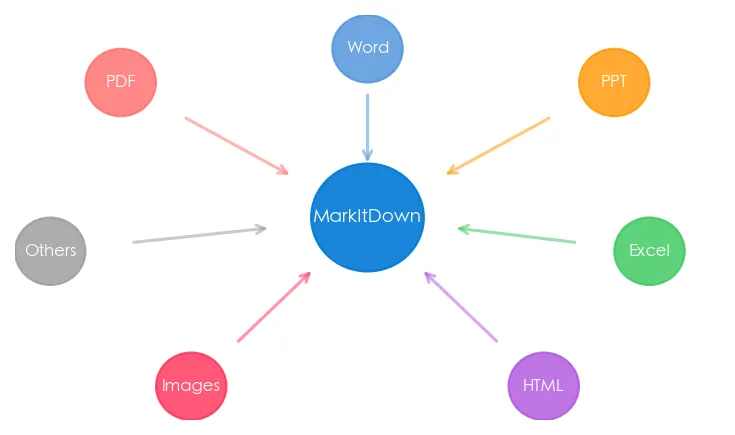
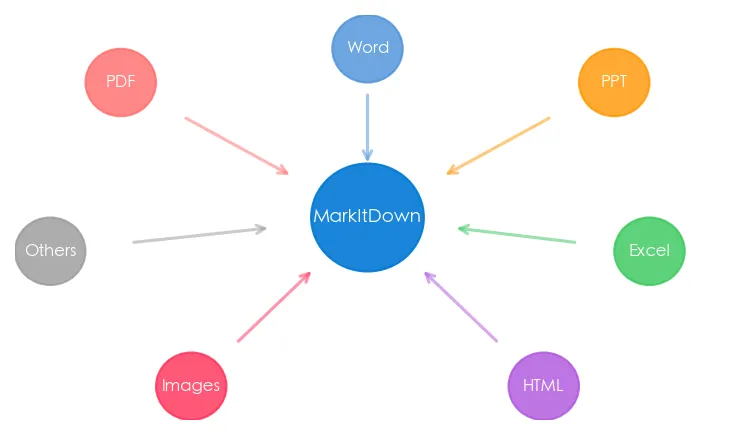
MarkItDown:微软出品的「文档翻译官」
MarkItDown 是微软开源的一个 Python 工具,专门把各种文件转成 Markdown。
听起来很普通对吧?但它在 GitHub 上已经拿了 131K+ Stars,今天 Trending 日增 1,873 颗星。这热度,相当于开源界的顶流了。
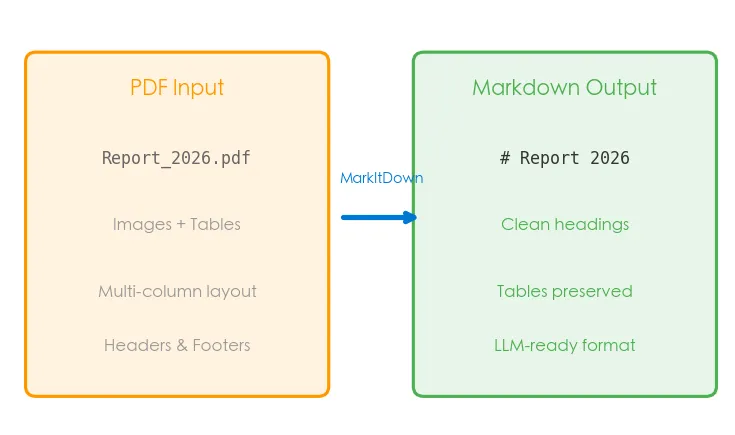
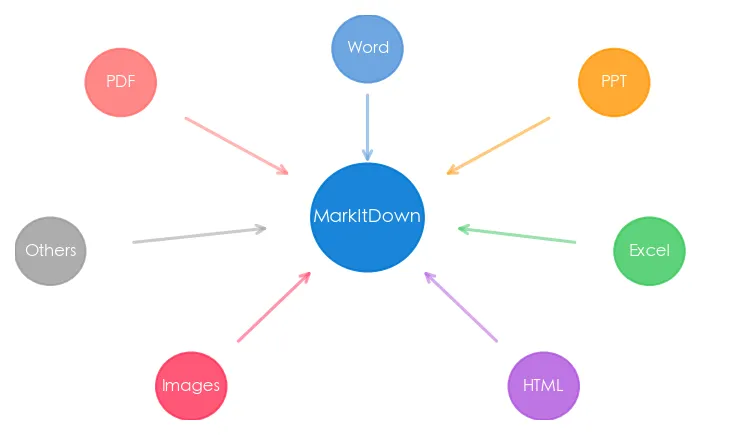
它能把 PDF、Word、PPT、Excel、HTML、图片(OCR)、甚至音频和 YouTube 视频都转成干净的 Markdown。重点是——一行命令就能搞定。
为什么转 Markdown 这么重要?因为 Markdown 是大语言模型最爱吃的格式。它接近纯文本,几乎没有多余的格式噪音,但又能保留标题、列表、表格这些关键结构。GPT、Claude 都「原生说 Markdown」,喂它们 Markdown,效果最好、token 最省。
安装:比泡面还快
确保你的 Python 版本是 3.10 或更高,然后一行搞定:
pip install 'markitdown[all]'`[all]` 会安装所有可选依赖,支持全部格式。如果你只需要部分格式,也可以按需安装:
# 只装 PDF、Word、PPT 支持
pip install 'markitdown[pdf, docx, pptx]'可用的可选依赖标签一览:
- 基础安装:`pip install markitdown`(只含核心功能)
- PDF 支持:`pip install "markitdown[pdf]"`(推荐,PDF 是最高频需求)
- 完整安装:`pip install "markitdown[all]"`(包含所有格式支持)
- 开发版:`pip install "markitdown[dev]"`(含测试和开发工具)
- Azure 集成:`pip install "markitdown[azure]"`(配合 Azure AI 服务)
命令行用法:一行搞定一切
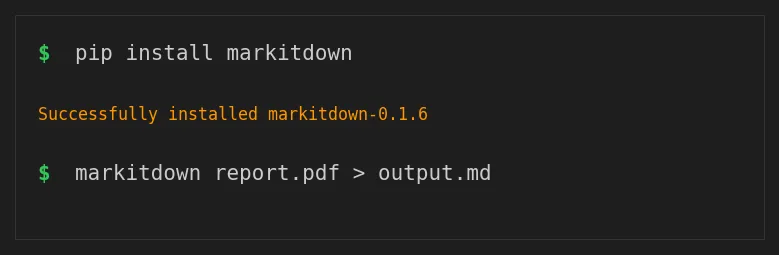
最简单的用法,直接在终端跑:
# 转换 PDF 并输出到文件
markitdown report.pdf -o report.md
# 也可以用管道
cat report.pdf | markitdown > report.md就这么简单。没有配置文件,没有复杂参数,文件路径一扔就出结果。
Python API 用法:三行代码集成到你的项目
命令行够用,但如果你想在自己的项目里用,Python API 同样简单:
from markitdown import MarkItDown
md = MarkItDown()
result = md.convert("report.pdf")
print(result.text_content)三行代码,完成转换。`result.text_content` 就是转换后的 Markdown 文本。
这就是它 131K Stars 的底气——简单到令人发指。
实战一:PDF 转换(含表格提取)
PDF 是最让人头疼的格式,没有之一。尤其是里面带表格的 PDF,传统工具转出来惨不忍睹。
MarkItDown 对 PDF 的处理相当能打,特别是表格。3 个月前他们刚合入了 PR #1552,专门增强了宽表格的支持。
from markitdown import MarkItDown
md = MarkItDown()
result = md.convert("annual_report.pdf")
print(result.text_content)转换后的表格会保留为 Markdown 表格格式,标题变成 `#`、`##`,列表变成 `-` 或 `1.`,基本可以直接喂给 LLM 使用。
实战二:Word 文档(.docx)
Word 转 Markdown 是个高频需求。客户发来合同、产品经理发来 PRD,你都想快速转成文本让 AI 帮你分析。
from markitdown import MarkItDown
md = MarkItDown()
result = md.convert("contract.docx")
print(result.text_content)标题层级、粗体斜体、列表缩进都能保留。比你自己手动复制粘贴强一万倍。
实战三:PowerPoint(.pptx)
这个场景太实用了。老板让你「把这份 PPT 总结一下」,以前你得一页页截图发给 AI,现在直接转:
from markitdown import MarkItDown
md = MarkItDown()
result = md.convert("quarterly_review.pptx")
print(result.text_content)每页幻灯片的内容会被依次提取,标题作为标题,正文作为正文,连备注都能拿到。
实战四:Excel(.xlsx)
Excel 转 Markdown 表格,做数据分析的人一定懂这个痛。
from markitdown import MarkItDown
md = MarkItDown()
result = md.convert("sales_data.xlsx")
print(result.text_content)转换后每个 Sheet 的数据会变成 Markdown 表格,列对齐,数据完整。拿去喂 AI 做数据分析,比直接上传 Excel 文件靠谱得多。
实战五:HTML 网页
爬下来的网页想转成干净的文本?MarkItDown 也行:
from markitdown import MarkItDown
md = MarkItDown()
result = md.convert("page.html")
print(result.text_content)它会去掉 HTML 标签,保留有意义的结构。比起 BeautifulSoup 手写解析逻辑,省太多心了。
实战六:图片 OCR
是的,图片也能转。它会提取 EXIF 元数据,并通过 OCR 识别图片中的文字:
from markitdown import MarkItDown
md = MarkItDown()
result = md.convert("screenshot.png")
print(result.text_content)如果你还想让 AI 描述图片内容(不只是 OCR),可以接入大模型:
from markitdown import MarkItDown
from openai import OpenAI
client = OpenAI()
md = MarkItDown(llm_client=client, llm_model="gpt-4o")
result = md.convert("chart.jpg")
print(result.text_content)这样图片里的图表、流程图都能被 AI 理解并描述出来。
进阶一:批量处理整个文件夹
一个一个文件转?太慢了。用 Python 写个批量脚本:
import glob
from markitdown import MarkItDown
md = MarkItDown()
# 批量转换某个文件夹下所有 PDF
for file_path in glob.glob("./documents/**/*.pdf", recursive=True):
result = md.convert(file_path)
output_path = file_path.rsplit(".", 1)[0] + ".md"
with open(output_path, "w", encoding="utf-8") as f:
f.write(result.text_content)
print(f"✅ {file_path} → {output_path}")跑一遍,整个文件夹的文档全部变成 Markdown。爽不爽?
进阶二:接入 RAG Pipeline
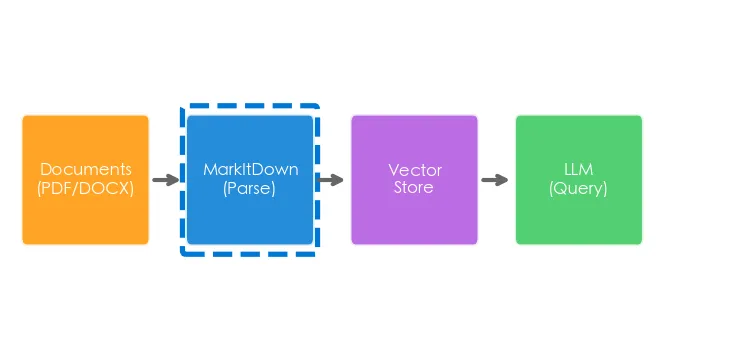
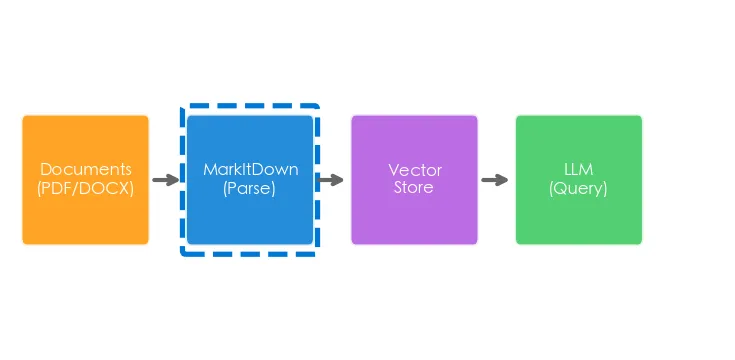
这才是 MarkItDown 的核心价值——它是 RAG(检索增强生成)系统的「入口关卡」。
文档解析是 RAG 的第一步,解析质量直接决定后续检索和生成的效果。MarkItDown 把各种格式的文档统一转成 Markdown,然后你就可以用 LlamaIndex 或 LangChain 切分、向量化、检索了。
一个简单的 LlamaIndex 集成示例:
from markitdown import MarkItDown
from llama_index.core import Document, VectorStoreIndex
# 第一步:用 MarkItDown 把文件转成 Markdown
md = MarkItDown()
result = md.convert("knowledge_base.pdf")
# 第二步:构建 LlamaIndex 文档对象
doc = Document(text=result.text_content, metadata={
"file_name": "knowledge_base.pdf"
})
# 第三步:构建索引并查询
index = VectorStoreIndex.from_documents([doc])
query_engine = index.as_query_engine()
response = query_engine.query("这份报告的核心结论是什么?")
print(response)整个流程跑通,从原始文档到 AI 回答,不到 20 行代码。
进阶三:Docker 方式运行
不想装 Python 环境?Docker 一把梭:
# 构建镜像
docker build -t markitdown:latest .
# 转换文件
docker run --rm -i markitdown:latest < ~/report.pdf > output.mdCI/CD 流水线里用特别方便,环境隔离、版本可控。
横向对比:MarkItDown vs 竞品们
市面上文档解析工具不少,MarkItDown 凭什么拿 131K Stars?来个简单对比:
MarkItDown vs 竞品对比:
- Stars:MarkItDown 131K+ | LiteParse 较新 | unstructured 10K+ | pandoc 35K+
- 定位:MarkItDown 转 Markdown | LiteParse 轻量解析 | unstructured 全功能 | pandoc 通用格式转换
- PDF 表格:MarkItDown 原生支持 | LiteParse 基础 | unstructured 强 | pandoc 弱
- 速度:MarkItDown 快 | LiteParse 最快 | unstructured 慢(依赖重) | pandoc 快
- AI/RAG 友好:MarkItDown 原生 Markdown | LiteParse JSON 输出 | unstructured 多格式 | pandoc 需后处理
- 开箱即用:MarkItDown 一行装 | LiteParse 一行装 | unstructured 配置多 | pandoc 系统级安装
- 扩展性:MarkItDown 插件体系 | LiteParse LlamaIndex 集成 | unstructured API 服务 | pandoc 过滤器
简单总结:
- pandoc 是格式转换的经典老炮,但它不是为 AI 场景设计的,输出格式偏「给人看」
- unstructured.io 功能最全但比较重,适合企业级场景
- LiteParse 是 LlamaIndex 出的新品,日增 701 Stars,值得关注
- MarkItDown 胜在「简单好用 + 微软背书 + 社区活跃」,131K Stars 不是白来的
踩坑指南:这些场景要当心
工具再好也有局限,这几个坑我替你踩过了:
1. 扫描件 PDF 效果有限
如果 PDF 是纯扫描的图片(不是文字型 PDF),MarkItDown 的内置 OCR 能力有限。建议搭配 `markitdown-ocr` 插件,用 GPT-4o 做 OCR:
from markitdown import MarkItDown
from openai import OpenAI
md = MarkItDown(
enable_plugins=True,
llm_client=OpenAI(),
llm_model="gpt-4o",
)
result = md.convert("scanned_doc.pdf")2. 超复杂表格可能对不齐
虽然 PR #1552 增强了宽表格支持,但那种多层嵌套表头、合并单元格花式乱用的 Excel,转出来还是可能变形。简单表格完全没问题。
3. 中英文混排偶尔丢格式
中文 PDF 中的英文部分(比如专业术语、代码片段)偶尔会丢掉格式标记。这个目前是已知的 Issue,社区在持续改进。
4. 注意安全
MarkItDown 会以当前进程的权限访问文件。如果在服务端用,务必做好输入校验,优先用 `convert_local()` 或 `convert_stream()` 这些更窄的 API,别直接把用户上传的路径扔给 `convert()`。
💡 打工人的碎碎念
说实话,第一次看到 MarkItDown 的时候我内心是拒绝的——又是一个「万能工具」的饼?
但用完之后我服了。它做的事很简单:把乱七八糟的文件变成 AI 能读懂的文本。但就是这件简单的事,以前要花我 hours 去搞定。
现在我的工作流变了:收到任何文档,第一件事就是 `markitdown` 过一遍,然后再喂给 AI。整个人的效率直接拉满。
131K Stars 说明了一切——这个工具解决了真实存在的痛点。不是那种看起来很炫但用不上的玩具,而是你今天装上、今天就能用上的生产力工具。
唯一的小遗憾是目前版本号才 v0.1.6,API 可能还会变。不过微软 AutoGen 团队在维护,309 个 commits 的活跃度,更新频率还是很稳的。
总结
MarkItDown 的核心价值就四个字:简单好用。
- 一行命令安装,三行代码使用
- 覆盖 PDF/Word/PPT/Excel/HTML/图片 六大核心格式
- 天然适合 RAG pipeline 集成
- 微软出品,131K Stars,社区活跃
如果你的日常工作涉及文档处理和 AI,这把瑞士军刀值得放进你的工具箱。
GitHub 地址:https://github.com/microsoft/markitdown
装上试试,你的周末可能就因此多出几个小时。
