 夜雨聆风
夜雨聆风智能原生软件工程(AiNativeSWE),业界怎么定义和实践,让组织走向AiNativeSWE的可行性路径,让开发人员在此过程里一起成长,敢问路在何方。

缘起性不空
软件工程领域正处于一场基础性的代际跃迁之中。在过去数十年的发展中,软件工程经历了由人类完全主导的传统模式(即软件工程 1.0),并在近年来过渡到了以人工智能为辅助工具的模式(即软件工程 2.0)。在软件工程 2.0 阶段,开发人员仍然是代码的绝对作者,人工智能仅仅作为一种局部的、缺乏上下文的辅助工具存在,例如集成开发环境(IDE)中的自动补全助手或错误日志分析器 。然而,随着前沿大型语言模型(LLM)推理能力的指数级增长,业界与学界正在共同跨越一个关键的阈值,正式迈入“智能原生软件工程”(AI-Native Software Engineering,或称软件工程 3.0)的全新范式 。
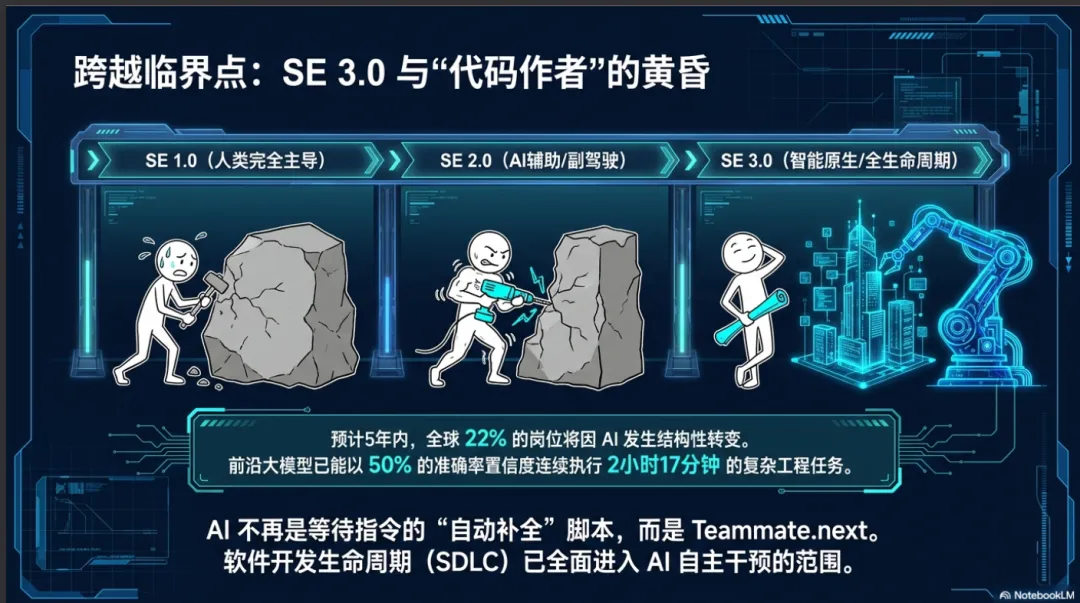
这一转型不仅仅是工具链的升级,更是一场深刻的结构性变革。从宏观经济与劳动力的角度来看,全球约有百分之二十二的工作岗位预计将在未来五年内因人工智能的驱动而发生结构性转变,这一速度远超传统的技能重塑体系 。与此同时,人工智能模型能够维持的连续推理时间正在呈指数级增长;例如,到2025年8月,前沿模型已被证实能够以百分之五十的准确率置信度执行长达两小时十七分钟的连续工作,这意味着整个软件开发生命周期(SDLC)都已进入人工智能自主干预的范围 。在这一背景下,智能原生软件工程不再是一个关于“AI 能否生成更多代码”的问题,而是关于组织如何吸收这些输出、维持系统架构的稳定性,并让开发人员在从“代码作者”向“意图架构师”的身份转变中实现共生增长的系统性工程。
业界与学界对 AI-Native SWE 的多维定义
智能原生软件工程的定义在学术界和工业界之间既有高度的共识,也存在侧重点的差异。学界倾向于从认知架构、语义验证和复用风险的角度进行深刻的理论界定,而业界则更关注交付生态、意图驱动以及商业价值的转化。
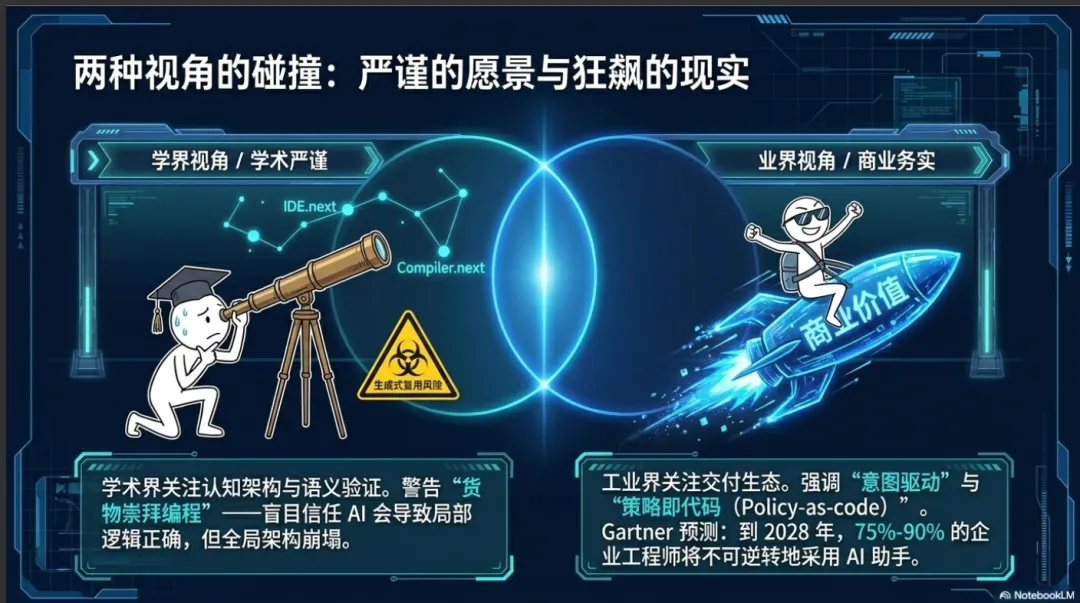
学界愿景:SE 3.0 与生成式复用的双刃剑
学术界将智能原生软件工程(SE 3.0)定义为一种基于人类与人工智能共生关系的全新范式,其核心目标是解决 SE 2.0 阶段由于上下文割裂而带来的认知过载与效率低下问题 。在这一愿景下,研究人员提出了重塑开发环境的三大核心支柱:Teammate.next、IDE.next 以及 Compiler.next 。
人工智能不再被视为一个被动等待指令的辅助脚本,而是作为 Teammate.next(下一代团队成员)深度参与软件设计的全过程。它不仅能够进行代码审查,还能在设计讨论中主动指出架构的潜在扩展性问题或隐蔽的安全漏洞 。为了支撑这一协作模式,IDE.next 将传统的文本编辑器转化为一个多智能体(Multi-Agent)的对话枢纽与编排层。通过模型上下文协议(Model Context Protocol, MCP)等底层技术,开发者可以在一个集成环境中同时启动多个专业化的智能体(如规划智能体、测试智能体和部署智能体)进行并行协作 。更重要的是,Compiler.next 重新定义了编译器的职责。传统的编译器仅负责语法检查和类型安全,而 SE 3.0 中的智能原生编译器则负责执行高级的语义对齐验证。例如,如果需求文档中明确规定了“必须包含双因素认证(2FA)”,但生成的代码逻辑中遗漏了该环节,智能编译器将直接抛出语义级别的警告 。
然而,学术界在描绘这一宏大愿景的同时,也发出了严厉的警告。研究人员深刻指出,高度依赖人工智能生成的代码正在引发一种被称为“生成式软件复用”(Generative Software Reuse)的新形态,这种形态在概念上与危险的“货物崇拜编程”(Cargo Cult Development)极为相似 。货物崇拜编程是指开发者在不理解底层机制的情况下,盲目复制和拼凑代码块的仪式化行为 。由于智能原生系统是基于海量、多样的训练数据集(包括高质量的开源仓库与非正式的技术论坛讨论)学习而来的,其生成的代码往往在局部逻辑上是正确的,但在全局架构层面却可能存在严重的连贯性问题 。如果开发者无条件信任这些输出,不仅会导致系统架构的脆弱性,还可能无意中引入直接或间接的版权侵犯与开源许可证违规风险 。因此,学界对 AI-Native SWE 的定义中,不可剥离的一部分是建立关于责任归属、系统透明度以及如何规避认知退化的研究议程 。
业界共识:从辅助工具到核心基础设施
与学界的严谨审视相呼应,工业界将智能原生软件工程定义为一个以人工智能为核心基础设施的自愈、自治且持续改进的交付生态系统 。根据高德纳(Gartner)的预测,到2028年,将有百分之七十五至百分之九十的企业软件工程师使用基于人工智能的编码助手,这一比例相较于2023年不足百分之十的基数,标志着一种不可逆转的行业化运动 。
业界将这一范式的核心特征总结为一组基础原则。首先是“意图驱动开发”(Intent-driven development),即系统能够将人类的商业目标和战略意图直接转化为机器可解释的指令,确保代码产出与业务需求高度一致 。其次是“嵌入式治理”(Embedded governance),这意味着安全性、合规性和审计可追踪性不再是开发流程末端的附加步骤,而是作为“策略即代码”(Policy-as-code)持续嵌入在智能原生流水线的每一次智能体交互之中 。最终,这种模式促成了“并行化工作流”(Parallelized workflows),使得需求规划、代码构建、自动化测试和安全验证可以在多个智能体的协作下同步进行,从而以机器速度大幅缩短交付周期 。
在这一全新的行业定义下,开发者的角色定位也发生了根本性的转移。业界明确提出,人类在智能原生软件工程中的职责正在从“作者”(Author)转变为“架构师与编辑”(Architect and Editor) 。人类不再专注于逐行编写语法,而是专注于定义意图、做出架构折中决策、设定护栏边界、沉迷于用户体验,并充当质量保障的最后一道防线 。
智能原生实践:重塑软件开发生命周期 (SDLC)
为了将智能原生软件工程的理论愿景转化为实际的生产力,组织必须对其软件开发生命周期(SDLC)进行彻底的解构与重构。传统的瀑布模型或敏捷开发流程都建立在“人类编写代码、人类进行验证”的时间线假设之上。在 AI-Native SWE 时代,实践的核心在于建立一套人机协同的新工作流,并将数据与模型视为一等公民。
“委托、审查与拥有” (Delegate, Review, Own) 核心工作流
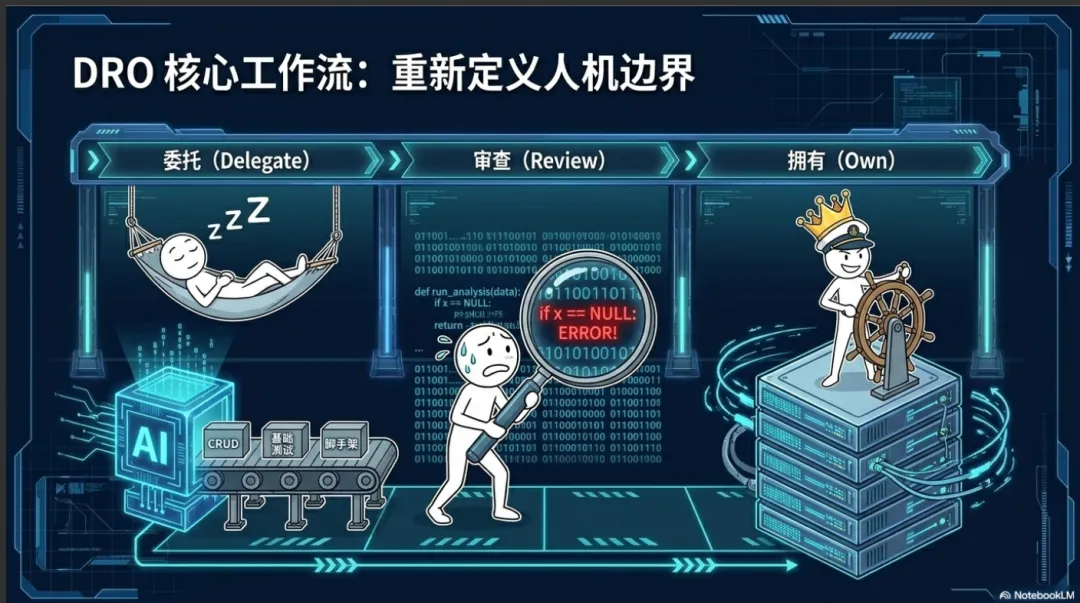
在智能原生的日常实践中,工程领导者需要指导团队将机械的、逐行执行的编码任务剥离,转而采用“委托、审查与拥有”的框架 。这一框架覆盖了从需求规划到构建测试的每一个环节,具体实践机制如下表所示:
SDLC 阶段 | 智能体(AI Agent)的执行域 (Delegate) | 人类开发者的审查域 (Review) | 人类开发者的所有权域 (Own) |
规划与范围界定 (Planning and Scoping) | 智能体通过读取问题跟踪系统中的功能规范,结合对整个代码库的上下文理解,进行初步的可行性分析、依赖关系映射,并标记出需求描述中的模糊地带 。 | 开发者审查智能体生成的依赖映射和任务拆解,验证其准确性和完整性,分配故事点(Story Points),并识别非明显的企业级风险 。 | 人类掌握绝对的战略决策权,包括长期的产品方向、功能优先级的排序、系统演进的顺序以及商业价值的权衡 。 |
系统设计与原型 (Design) | 利用多模态智能体,将自然语言描述或视觉设计草图直接转换为项目脚手架(Scaffolding)、样板代码,并即时应用设计令牌(Design Tokens)和样式指南 。 | 团队评估生成的组件是否符合全局设计约定、可访问性标准,以及是否能够与现有的遗留系统无缝集成 。 | 团队拥有更高维度的设计系统架构设计、用户体验(UX)的整体连贯性把控,以及最终产品交互模式的决策权 。 |
构建与实现 (Build) | 智能体作为首轮实现者,接收 | 开发者对代码进行深度审查,重点关注性能关键路径、潜在的安全漏洞、数据迁移风险以及与领域模型的对齐情况,纠正智能体产生的微妙幻觉 。 | 开发者负责处理需要极深系统直觉的复杂任务,如跨领域架构变更、新抽象的创建以及长期可维护性代价的评估 。 |
通过在每个环节实操这一框架,开发团队能够将系统智能的潜力发挥到极致,同时确保复杂的业务逻辑始终处于人类专家的有效监控之下。
从 VxDD 模型到 SDD (Spec-Driven Development) 的演进
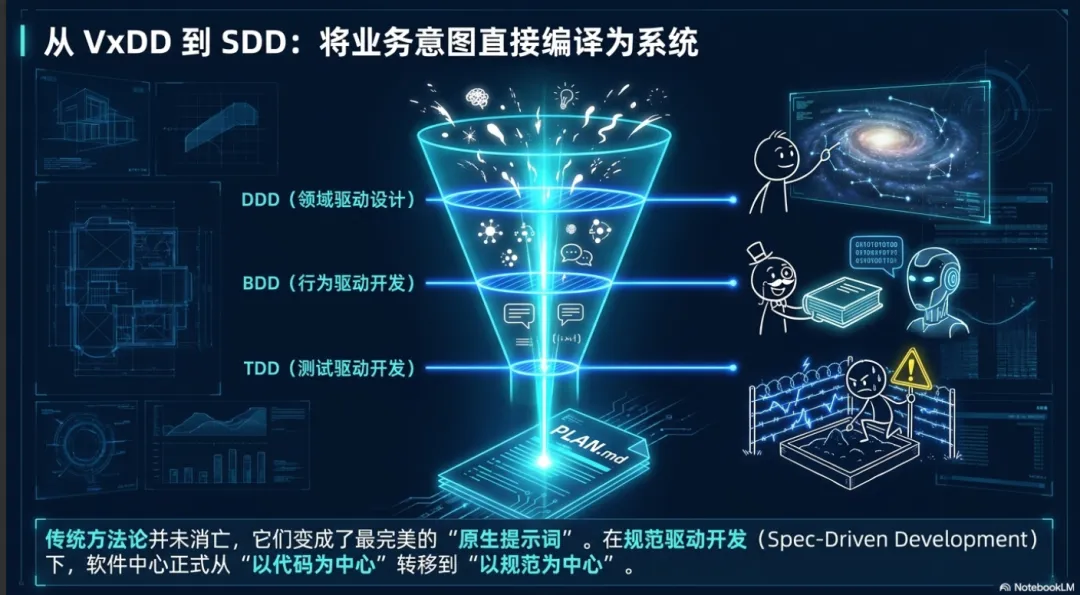
为了让“意图驱动开发”在 AI 时代真正落地,传统的开发方法论必须进行升级。在您定义的 VxDD 模型(即各类型的“X 驱动开发”集合)框架下,经典的 DDD、BDD 和 TDD 并非被 AI 淘汰,而是作为“人机对齐”的核心契约,发挥着比以往更关键的作用,并最终推动工程向 SDD 演化。
DDD(领域驱动设计,Domain-Driven Design):为 AI 提供全局上下文。AI 生成代码最大的风险是“局部正确但全局失调”。DDD 的“统一语言”(Ubiquitous Language)和“限界上下文”(Bounded Context)为多智能体提供了极其精确的领域知识图谱。在实践中,开发者将领域模型转化为 AI 的系统提示词(System Prompts)或上下文规范,确保智能体生成的实体和逻辑与深层的业务架构保持严格一致。
BDD(行为驱动开发,Behavior-Driven Development):连接业务意图与机器执行的桥梁。BDD 强调使用自然语言(如 Gherkin 语法的 Given-When-Then)描述系统行为。这种结构化的自然语言恰好是大型语言模型最完美的“原生提示词”。业务人员和系统架构师编写 BDD 场景,AI 智能体能够将其无缝解析为可执行的系统级测试和代码脚手架。
TDD(测试驱动开发,Test-Driven Development):构筑 AI 幻觉的物理护栏。在 AI 时代,TDD 演变为“AI-TDD”双循环。人类(或规划智能体)首先编写出严格的红灯测试用例,随后编码智能体在沙箱中不断生成、修改代码,直到测试变绿。TDD 将验证的责任前置,是确保“生成式代码”质量不退化的终极底线。
向 SDD(规范驱动开发,Spec-Driven Development)的终极演化
随着前沿大模型能力的提升,VxDD 正在向更高维度的 SDD(规范驱动开发) 演进。业界专家指出,在人工智能强大生成能力的催化下,软件开发的核心正在经历从“以代码为中心”(Code-centric)向“以规范为中心”(Spec-centric)的根本性转移。
SDD 被广泛视为 BDD 的 2.0 版本。在 SDD 范式中,开发人员不再纠结于具体的语法实现,而是使用清晰的自然语言和结构化文本(如 PLAN.md 或 AGENTS.md)来描述新功能、设定系统边界与内置的安全护栏。这些规范(Spec)既是人类可读的需求文档,也是机器可执行的生成指令。AI 智能体读取这些带有护栏的规范后,默认能够生成更安全、更高质量的基础代码。这意味着,开发者通过精心设计的 VxDD 模型与实践,最终实现了将高维度的“业务意图(Spec)”直接编译为底层软件系统的巨大跨越。
智能原生 CI/CD 与持续智能部署
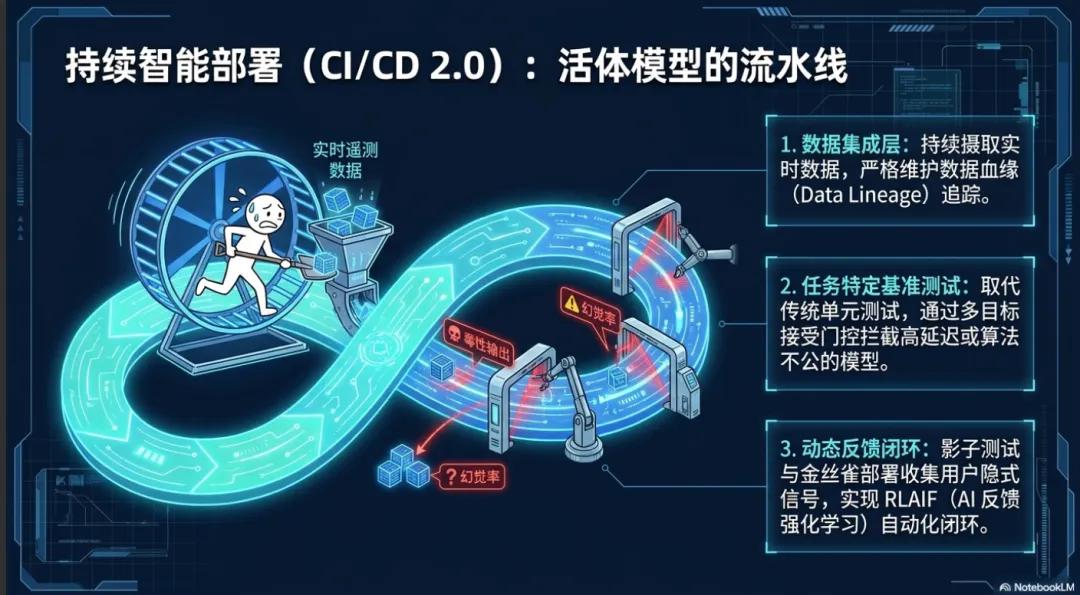
软件构建完成后的测试与部署阶段,同样经历了智能化重塑。传统的持续集成与持续部署(CI/CD)流水线主要处理静态的二进制文件和配置。然而,在 AI-Native SWE 中,不仅软件本身是由人工智能生成的,软件系统内部往往也嵌入了动态的人工智能模型(如大语言模型或分类器)。这要求流水线演进为“持续智能部署”(Continuous Intelligence Deployment)生态系统 。
智能原生 CI/CD 流水线在架构设计上引入了多个全新的层级。首先是数据集成层(Data Integration Layer)。由于人工智能模型的性能极度依赖于新鲜的数据输入,该层需要持续摄取流式训练数据(如实时遥测数据和用户交互日志),并严格维护数据血缘(Data Lineage)追踪,确保每一个部署的模型版本都能安全地追溯到其特定的数据集快照 。
其次,模型验证与测试机制发生了质变。传统的单元测试和集成测试被任务特定的基准测试(Task-Specific Benchmarks)所取代或扩充。例如,对于语言模型,流水线必须自动评估其幻觉率、毒性输出以及高并发下的推理延迟 。这种验证必须是多目标的,因为一个模型可能在准确率上有所提升,但却在算法公平性或推理成本上出现倒退。因此,流水线会强制执行多目标接受门控(Multi-Objective Acceptance Gates)以拦截不合格的部署 。
最后,反馈循环(Feedback Loops)成为了流水线的核心机制。通过金丝雀部署(Canary Deployments)和影子测试(Shadow Testing),新生成的模型和代码在不影响核心用户的情况下处理真实的生产流量。系统自动捕捉遥测数据和用户隐式信号(如放弃点击、重新提示),并将这些信号反馈到训练阶段,实现人类反馈强化学习(RLHF)和人工智能反馈强化学习(RLAIF)的自动化闭环 。这种全链路的持续学习能力,是 AI-Native SWE区别于传统自动化工具的最显著标志。
垂直领域深潜:智能原生在嵌入式系统中的实践
尽管智能原生软件工程在通用软件和网络服务开发中进展迅速,但在嵌入式软件和安全关键(Safety-Critical)领域,其应用面临着独特的挑战。嵌入式领域受限于严格的硬件资源限制、苛刻的实时性要求、复杂的交叉编译工具链以及行业合规性标准(如汽车行业的 ISO 26262 或航空业的 DO-178C)。为了克服这些物理与合规障碍,业界正在通过专用的智能体流水线、硬件在环整合以及编译范式的激进创新,重塑嵌入式开发。
1. 嵌入式特有的智能体流水线 (Agentic Pipelines)
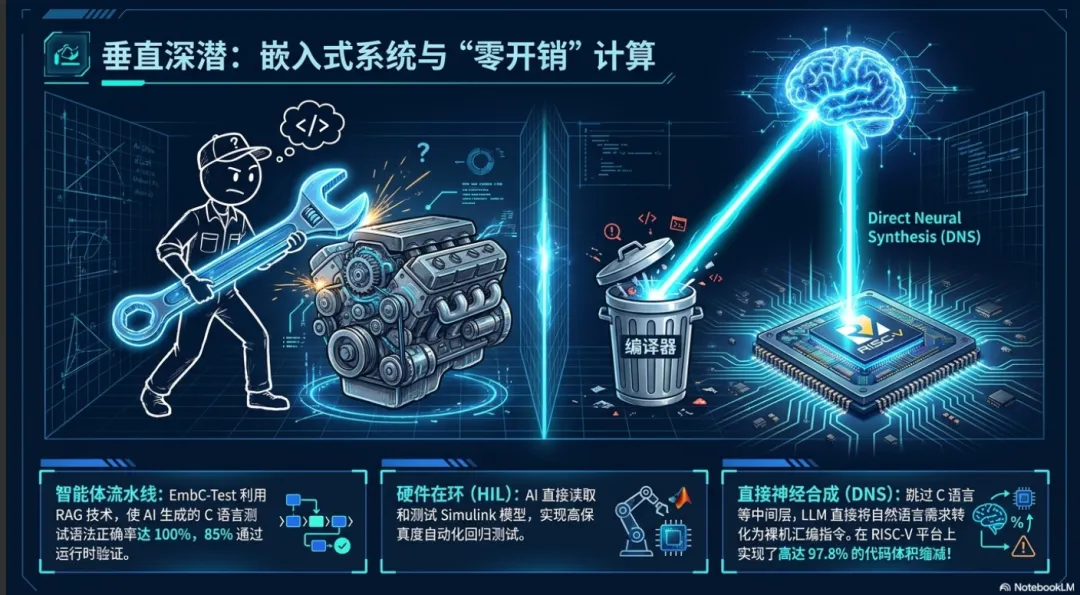
在嵌入式领域,持续集成(CI)阶段经常因为软硬件协同进化、底层依赖项错配或复杂的工具链配置而遭遇编译失败 。为了解决这一问题,业界提出了诸如 PhantomRun 等自动化修复框架。该框架无需人类干预,利用大语言模型与编译器反馈循环(Compiler-in-the-Loop),自动定位并修复开源嵌入式项目中的编译错误,极大保障了 CI 流水线的顺畅运行 。
此外,嵌入式 C 语言软件的自动化单元测试编写向来极其耗时,且由于缺乏上下文,“零样本(Zero-shot)”的 LLM 生成极易产生危险的幻觉(如捏造不存在的硬件寄存器或内部 API)。为此,业界开发了基于检索增强生成(RAG)的测试流水线(如 EmbC-Test)。通过将模型强制锚定在特定的项目硬件手册和代码工件上,这种 AI 辅助生成的测试用例语法正确率可达 100%,其中 85% 能够成功通过运行时验证,在大幅减少验证环节瓶颈的同时确保了测试质量。
2. 硬件在环 (HIL) 测试与模型驱动的智能协同
传统的硬件在环(Hardware-in-the-Loop, HIL)测试由于测试台昂贵且稀缺,通常排队时间长且自动化程度低。在智能原生范式下,AI 智能体被赋予了直接操作复杂工程仿真环境的能力。例如,MATLAB/Simulink 的智能体工具包(Simulink Agentic Toolkit)通过模型上下文协议(MCP),允许 AI 智能体运用基于模型的设计(Model-Based Design)最佳实践,直接读取、编辑、查询和测试 Simulink 模型。
在这种混合工作流中,AI 智能体可以自主执行参数扫描、管理硬件配置并在虚拟测试架构中验证控制算法,工程师则只需在关键的决策点(Human-in-the-Loop)介入评估架构与折中方案。随着 AI 与 HIL 基础设施的深度结合,自动驾驶 ECU 和航空电子设备等嵌入式系统得以实现高保真度、持续的自动化回归测试与漂移监控。
3. 激进创新:从意图到芯片的直接神经合成 (DNS)
为了彻底弥合由于传统编译器、链接器和通用启动代码引入的“语义到硅片(Semantic-to-Silicon)”鸿沟,学术界提出了一种激进的无编译器范式——直接神经合成(Direct Neural Synthesis, DNS)。
该方法将指令集架构(ISA,如 RISC-V)直接视为一种模型可理解的原生语言。开发者只需以自然语言定义硬件需求文档(HRD),LLM 就能跨过 C 语言等中间抽象层,直接生成裸机汇编指令。在基于 RISC-V 平台的实验中,相比于经过极度优化的 GCC 编译二进制文件,DNS 能够实现高达 97.8% 的控制任务代码体积缩减。它实现了真正的“零开销(Zero-Overhead)”计算,能够自主管理动态栈初始化等底层资源。在这种架构下,嵌入式工程师的重点将不再是钻研晦涩的编译器标志,而是纯粹的系统架构与机器意图定义。
4. 功能安全与合规治理 (ISO 26262 / HARA)
将生成式 AI 引入自动驾驶等安全关键系统时,由于其概率性输出与黑盒属性,直接违背了功能安全标准(如 ISO 26262)对强确定性、可追溯性和故障隔离的要求。为此,业界在推进智能原生嵌入式开发时,正在采用一套严格的协同工程框架。
在进行危害分析和风险评估(HARA)时,类似 LASAR(LLM-Augmented Situation Space Analysis for Risk Assessment)的方法通过人类与 AI 的协作,利用 LLM 的海量知识域帮助工程师识别在高度复杂的运行设计域(ODD)中容易被忽略的边界风险。同时,在代码与模型合规层面,为了解决“AI 生成工件的认证鸿沟(Certification Gap)”,企业正在将可解释 AI(XAI)、形式化验证以及严格的提示词与模型版本控制纳入流水线。这确保了在长达十数年的汽车或工业产品生命周期中,由 AI 辅助生成的每一行代码及其原始意图,都能满足审计(Auditability)要求的完整追溯性。
组织走向 AI-Native SWE 的可行性路径
尽管智能原生软件工程展现出了极高的生产力前景,但组织层面的广泛采用却面临着巨大的阻力。宏观研究数据揭示了一个严峻的现实:尽管全球范围内对生成式人工智能的投资高达数百亿美元,但目前仍有高达百分之九十五的组织无法从其生成式人工智能投资中获得实质性回报,仅有约百分之八的企业成功地在企业级规模上部署了人工智能以最大化商业价值 。
导致这一失败的核心原因并非技术本身的缺陷,而是期望错位、应用场景失准以及缺乏严谨的执行标准 。许多组织陷入了“炒作驱动的实验”(Hype-driven experimentation),而忽视了基础能力的构建。为了帮助组织跨越这一鸿沟,业界与学界联合推出了成熟度模型与效能度量新范式,为走向 AI-Native 铺平了道路。
跨越炒作周期:SEI/Accenture AI 采用成熟度模型
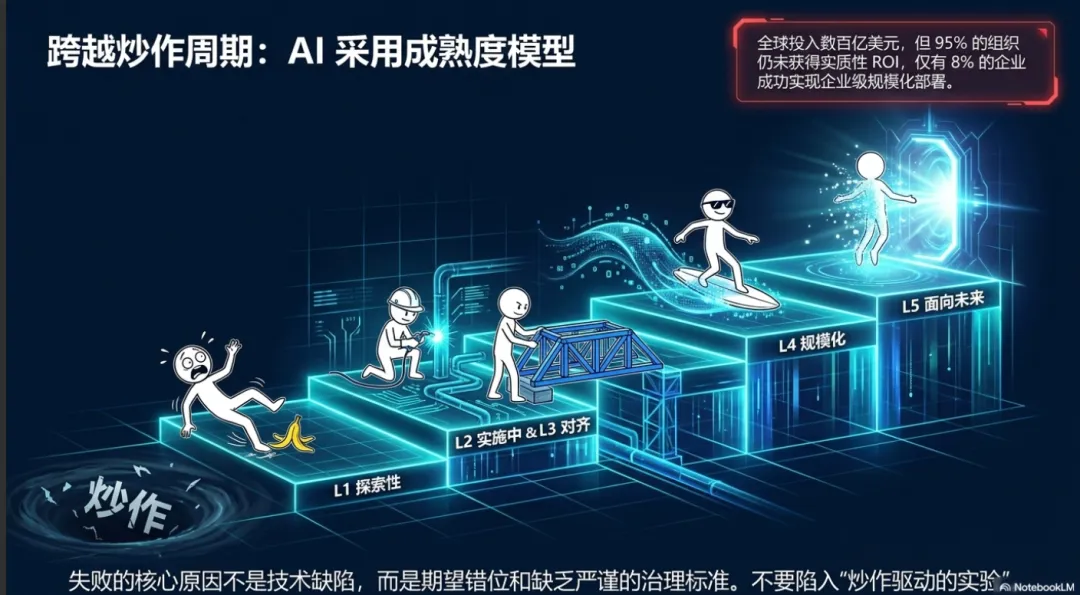
卡内基梅隆大学软件工程研究所(CMU SEI)联合埃森哲(Accenture)共同开发了“人工智能采用成熟度模型”(AI Adoption Maturity Model)。该模型旨在为组织提供一个可预测的、严格的路线图,帮助其从混乱的技术实验走向系统化的价值创造。模型在设计上吸取了传统 CMMI(能力成熟度模型集成)和 CERT-RMM(韧性成熟度模型)的深厚经验,将人工智能能力划分为八个核心维度:组织战略、劳动力与文化、工作流重构、风险与治理、数据、工程、运营与维持,以及生态系统管理 。
组织在这八个维度上的综合表现,将其划分为五个渐进的成熟度等级,为领导层提供了清晰的演进路径:
实施成熟度等级 | 组织特征与状态描述 | 核心挑战与突破口 |
Level 1: 探索性 AI (Exploratory AI) | 组织处于转型的起点,AI 的采用通常以孤立的、临时性的实验为主,缺乏统一的战略指导和工具链标准 。 | 需要克服对技术失败的恐惧,开始识别真正具有商业价值的用例,而非盲目追逐技术热点。 |
Level 2: 实施中的 AI (Implemented AI) | 组织或特定业务单元已经正式走上实施路径,开始在某些非核心流程中部署 AI 工具,并初步建立培训机制 。 | 突破口在于将成功的孤岛项目经验转化为可复用的内部标准,开始重视数据质量与治理。 |
Level 3: 对齐的 AI (Aligned AI) | 人工智能工作流在组织内部得到一致的管理。跨团队的协作开始形成标准,风险与安全治理机制初步嵌入 SDLC 。 | 此时面临的主要挑战是打破部门壁垒,实现 AI 基础设施的集中化管理和成本优化。 |
Level 4: 规模化 AI (Scaled AI) | AI 已在企业级规模上成功部署,能够产生可重复、可预测的积极结果。工具链高度整合,持续部署与影子测试成为常态 。 | 组织需要关注模型的持续漂移(Model Drift)以及全链路的系统可观测性。 |
Level 5: 面向未来的 AI (Future-Ready AI) | 组织拥有持续成功并利用 AI 推动增量与突破性创新的记录。AI 代理不仅是辅助,更是自我治理和自我优化的核心基础设施 。 | 维持这一状态需要极高的文化敏捷性,确保员工具备快速适应下一代前沿模型的能力。 |
效能度量的坍塌与重建:超越 DORA 指标
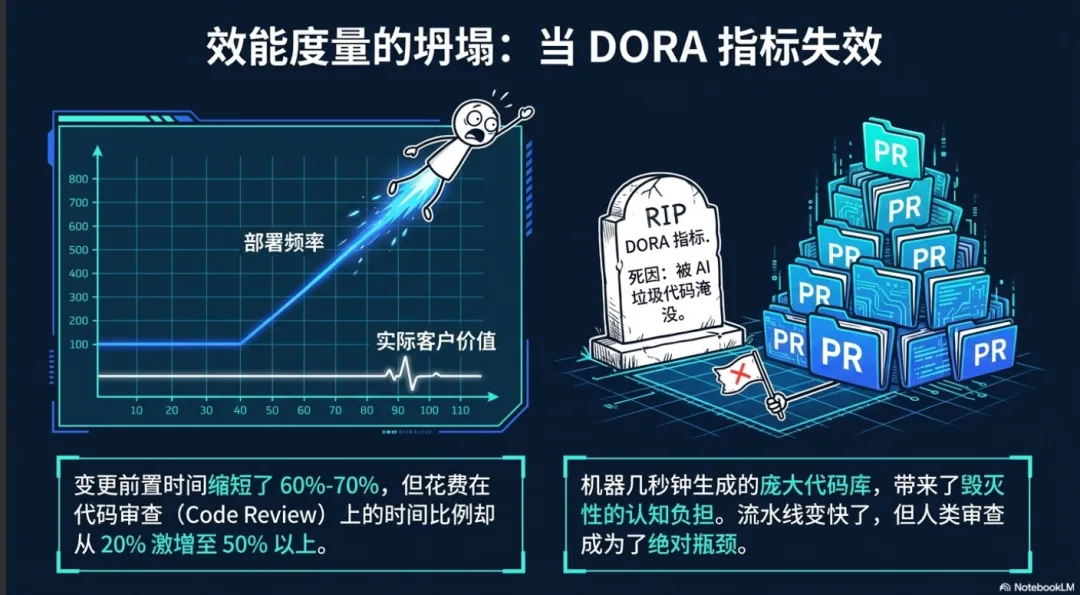
当组织沿着成熟度模型向上攀登时,工程领导者会遭遇一个意想不到的系统性故障:传统的研发效能度量指标在人工智能时代完全失效 。在过去十余年中,业界广泛采用 DORA(DevOps 研究与评估)指标来衡量团队效能,其核心指标包括部署频率(Deployment Frequency)、变更前置时间(Lead Time for Changes)、平均恢复时间(MTTR)以及变更失败率(Change Failure Rate)。
DORA 指标的根本假设是:代码完全由人类编写,且工程效率的最大瓶颈在于如何将代码安全地推送至生产环境 。然而,在 AI-Native 环境下,人工智能能够毫不费力地生成海量的样板代码、配置文件和测试脚手架。这导致组织的“部署频率”在纸面上呈指数级暴涨,使得团队看起来已经达到了“精英”级别,但实际上并未交付任何有实质意义的客户价值 。
更严重的是,“变更前置时间”这一指标掩盖了流程瓶颈的转移。研究表明,在采用人工智能后,代码从提交到生产的总体前置时间可能缩短了百分之六十到百分之七十,但在这段缩短的时间内,花费在“代码审查”(Code Review)上的时间比例却从百分之二十激增至百分之五十以上 。由于机器可以在几秒钟内生成数百行代码,审查这些庞大且不包含人类默会知识(Tacit Knowledge)的代码库,给人类审查者带来了极大的认知负担。流水线的整体速度变快了,但人类在代码审查环节的瓶颈却比以往任何时候都更加集中 。
为了真实反映组织的工程能力,业界提出了“开发者人工智能影响框架”(Developer AI Impact Framework),建议用具备人工智能感知能力的扩展指标来替代或补充 DORA 指标 :
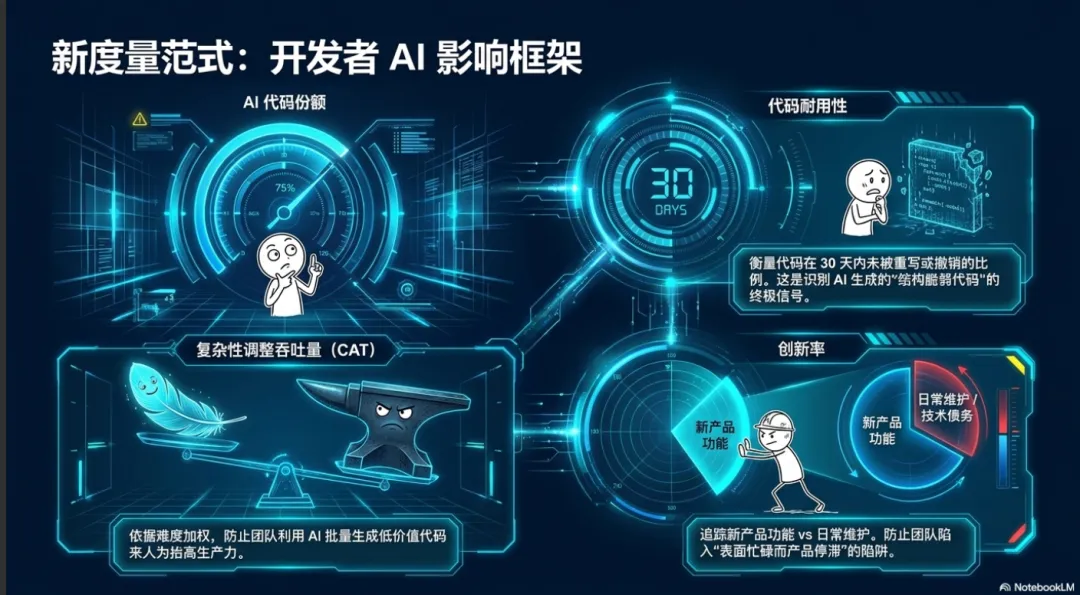
AI 代码份额 (AI Code Share):衡量提交的代码中人工智能生成代码与人类编写代码的比例。这是解读所有其他指标的上下文基础,一个具有百分之七十 AI 代码份额的团队与只有百分之二十的团队具有完全不同的运作逻辑 。
代码周转率/耐用性 (Code Turnover Rate / Durability):衡量有多少代码在提交后的十四到三十天内没有被撤销、重写或大幅修改。由于 AI 善于编写能通过自动化测试但结构脆弱的代码,变更失败率无法捕捉这种低质量的“代码搅动”(Code Churn)。代码耐用性才是衡量 AI 生成代码真实质量的终极信号 。
复杂性调整吞吐量 (Complexity-Adjusted Throughput, CAT):根据任务的难度和复杂性对吞吐量进行加权。这一指标取代了单纯的部署频率,防止团队利用 AI 批量生成低价值的简单代码来人为抬高生产力指标 。
创新率 (Innovation Rate):部署的新产品功能与用于日常维护(如依赖项更新)的部署之比。由于 AI 极度擅长处理日常维护工作,如果不追踪创新率,团队可能会在表面上显得异常忙碌和高产,而实际的产品功能却陷入停滞 。
开发者在此过程中的蜕变与成长
智能原生软件工程的核心不仅在于组织架构和工具链的变革,更在于处于这一生态中心的“人”的演进。人工智能技术引发了深层次的心理和职业挑战,促使开发人员重新思考:在机器能够承担大部分编码工作的情况下,这项职业中还有哪些部分值得保留? 这种转型不仅仅是技能的更新,更是个人身份认同的重构。
身份重构:从“代码作者”到“意图架构师”
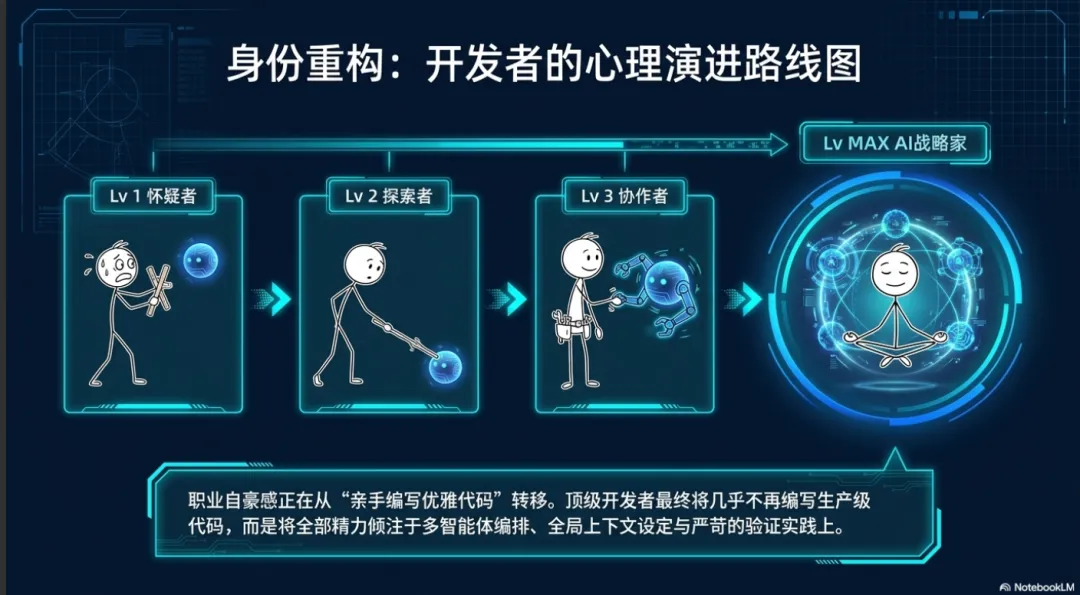
在传统模式中,程序员的职业自豪感往往来源于亲手编写出优雅、高效的代码。然而,在 AI-Native 时代,这种身份逐渐消解。为了适应深度的智能协同,开发者的心理认知通常会经历四个发展阶段 :
首先是怀疑者(The Skeptic)阶段。面对 AI 早期可能给出的低劣建议,开发者感到原有工作流被打断,他们倾向于将 AI 的错误视为其技术不成熟的证据,并试图坚守手动编码的习惯 。随着市场压力的增加,他们进入探索者(The Explorer)阶段。在这一阶段,AI 偶尔展现出的强大能力(如解释晦涩的遗留代码库)打破了他们的怀疑。他们开始在日常工作中进行提示词工程的实验,逐渐建立起对工具边界的信任 。
随后,开发者演进为协作者(The Collaborator)。他们不再等到遇到难题时才求助于 AI,而是从解决问题的第一步起就将 AI 视为思考伙伴。他们接受 AI 在第一遍输出时可能会犯错,并将迭代与反复的对话完善作为主要的创造方法 。最终,极少数开发者会达到AI 战略家(The AI Strategist)的境界。在这个阶段,开发者几乎不编写任何代码。他们乐于看到 AI 完成百分之九十甚至百分之百的生产级代码。他们的全部精力都倾注于多智能体的编排、全局上下文的设定以及极其严苛的验证实践上 。
智能原生时代的核心能力模型
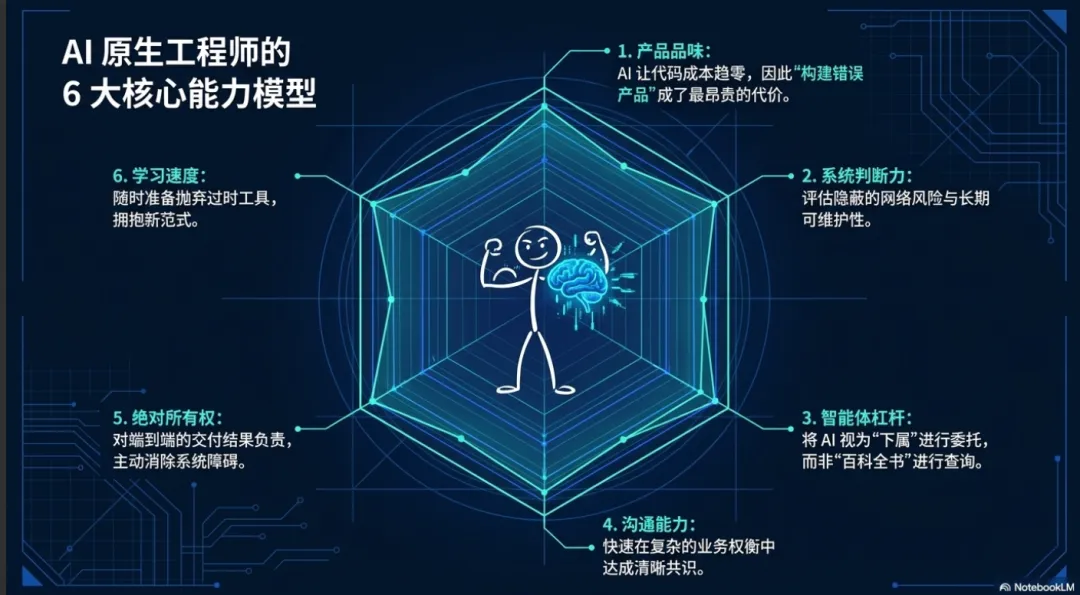
为了在这种高阶状态下胜任工作,业界重新定义了 AI-Native 工程师的招聘与评估标准。未来的开发人员不再以熟悉多少种编程语言的语法为荣,而是需要掌握以下六项核心能力 :
核心能力维度 | 评估问题与内涵解析 |
产品与结果品味 (Product & Outcome Taste) | 我们在构建正确的东西吗? 既然 AI 让生成代码的成本趋近于零,那么组织能犯的最昂贵错误就是“构建了错误的产品”。高杠杆的工程师必须具备敏锐的产品嗅觉,能够在编写任何代码前穿透模糊性,清晰定义业务期望的最终结果 。 |
系统与架构判断力 (System & Architectural Judgment) | 这能在生产环境中存活吗? AI 可以轻松让一段代码在本地运行,但却很难评估其在庞大系统中的架构合理性。工程师需要深刻的判断力来理解长期的可维护性折中、操作现实以及大规模并发下的隐藏网络风险 。 |
智能体杠杆运用 (Agent Leverage) | 你能将 AI 转化为实际的工程吞吐量吗? 优秀的工程师将 AI 视为下属进行“委托”,而不是作为维基百科进行“查询”。他们善于将复杂问题结构化,以便智能体能够高效执行,并在智能体偏离方向时进行干预纠正 。 |
沟通与协作 (Communication & Collaboration) | 你能清晰传达意图吗? 随着代码实现速度的加快,工程工作的主要瓶颈变成了明确问题和统一意见。最敏捷的团队不是代码写得最快的团队,而是最快在复杂业务权衡中达成清晰共识的团队 。 |
所有权与领导力 (Ownership & Leadership) | 你对结果负责,还是只对任务负责? 卓越的工程师对整个交付结果负有端到端的责任。如果陈旧的构建流水线或模糊的需求文档阻碍了 AI 智能体的发挥,他们会主动越出自己的职责边界去消除这些系统性障碍 。 |
学习速度与实验心态 (Learning Velocity) | 你能跟上工具进化的速度吗? 今天的工具和工作流可能在几个月后就会被完全淘汰。工程师必须将实验作为日常工作的一部分,随时准备抛弃过时的方法论,拥抱更高级的智能范式 。 |
哲学分歧:氛围编程 (Vibe Coding) 与智能体工程 (Agentic Engineering)
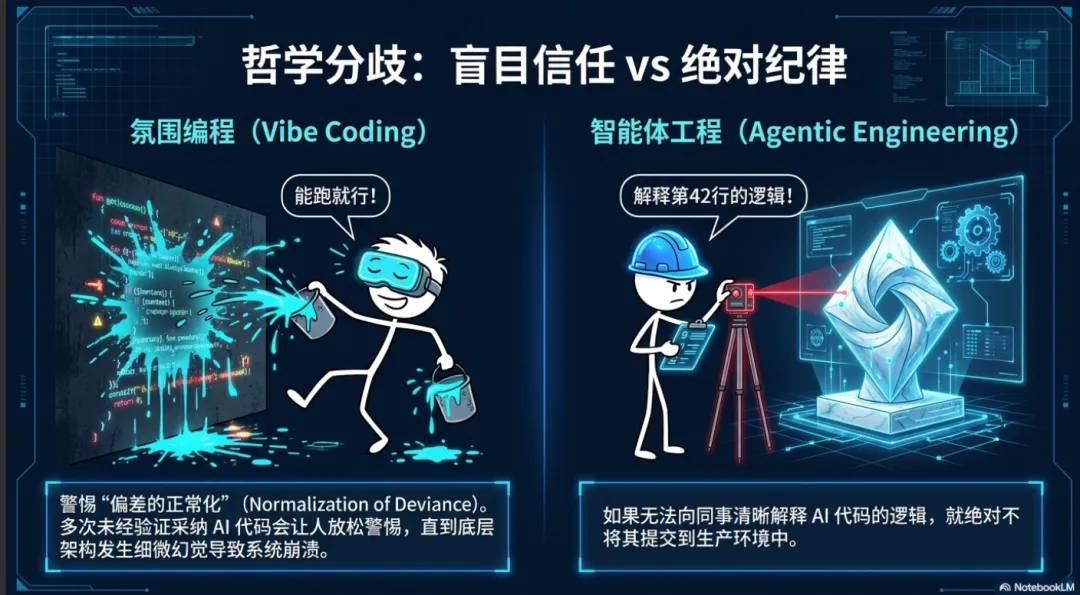
随着人工智能能力的爆发,开发者社区内部出现了一种值得警惕的哲学分歧,集中体现在“氛围编程”(Vibe Coding)与“智能体工程”(Agentic Engineering)的对立上 。
“氛围编程”由业界首次提出,描述了一种完全放弃代码审查的开发模式。在这种模式下,用户可能完全不懂编程,他们向 AI 描述需求,如果生成的工具能够运行,他们就直接使用;如果报错,他们将错误信息原封不动地复制给 AI,祈祷下一次修复能够成功。在此过程中,他们从不阅读代码差异(Diff),也不关心系统性能或安全约束 。行业专家认为,这种依赖“感觉”的编程方式对于个人构建一次性工具或快速原型极为有效,且大大降低了技术的准入门槛;但如果将其用于构建面向公众的、涉及敏感数据或金融交易的生产级软件,则是极度不负责任的 。
与之相对的是“智能体工程”。这是一种由资深专业软件工程师主导的、高度负责的开发实践。从业者利用他们多年积累的关于安全性、性能优化和可维护性的专业知识,来严格约束和引导 AI 工具 。他们的核心原则是:如果无法向另一位同事清晰地解释这段 AI 生成的代码究竟做了什么,就绝对不会将其提交到生产仓库中 。
然而,随着前沿模型通过海量的虚拟环境强化学习变得越来越可靠,这两种截然不同的实践正在出现令人不安的融合趋势 。专家指出,由于 AI 代理在大多数情况下的正确率极高,许多经验丰富的工程师也开始产生疲劳,逐渐减少了对代码的逐行审查,将 AI 系统视为一个“黑盒”依赖项 。这种对手中工具的盲目信任引发了“偏差的正常化”(Normalization of Deviance)。当工程师多次未经验证地采纳 AI 代码而没有引发灾难时,他们会在未来更加放松警惕;一旦 AI 在底层的关键架构处产生一次细微的逻辑幻觉,系统将面临无法挽回的崩溃。因此,在 AI 时代,开发者最难能可贵的品质恰恰是抵抗自动化的诱惑,保持不妥协的验证纪律 。
破除“技能退化”悖论:下一代工程师的导师机制
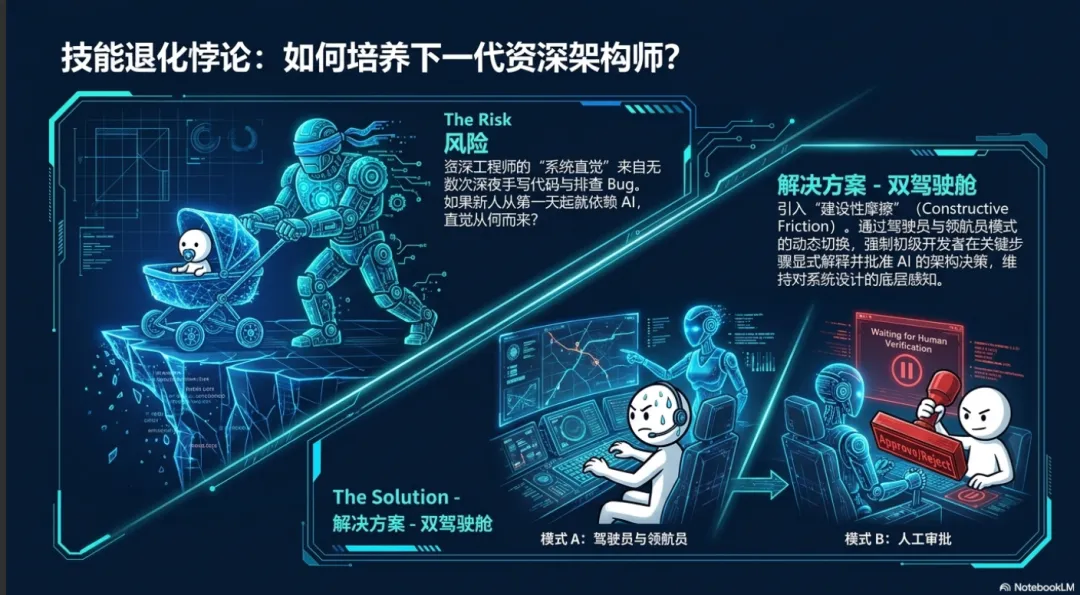
在这种高度自动化的环境中,组织与开发者必须共同面对一个可能危及行业未来的严峻挑战——初级开发人员的“技能退化”悖论(Deskilling Paradox)。资深工程师之所以能够有效地审查 AI 生成的架构,发现那些会悄悄吞噬异常错误或在负载下崩溃的微妙问题,是因为他们拥有丰富的系统直觉 。而这些直觉,是他们过去在无数个深夜中通过手动编写代码、排查 Bug 和痛苦重构积累而来的 。
如果刚步入职场的年轻开发者从第一天起就将所有的实现细节委托给 AI 智能体,他们将失去在实践中磨砺底层认知和构建系统直觉的机会 。他们可能会永远依赖于这些自动化工具,停留在“氛围编程”的浅层阶段,最终无法成长为具备深度判断力的“意图架构师”。
为了打破这一悖论,让开发人员在 AI 时代获得真正成长,组织正在探索全新的导师机制与工具交互范式,例如“驾驶员与领航员”模式(Driver vs. Navigator Mode)。在这种机制下,资深工程师或系统本身会有意识地引入“建设性摩擦”(Constructive Friction)。在“领航员模式”下,AI 仅仅提供高层次的架构指导和逻辑检查,强制初级开发者手动编写关键业务代码以建立肌肉记忆;而在“驾驶员模式”下,即使 AI 负责生成所有代码,系统的工作流也会强制初级开发者在每个执行步骤前显式地解释并批准 AI 的架构决策,确保他们充分理解背后的系统取舍 。通过这种人机角色的动态互换,组织可以在维持高生产力的同时,确保下一代开发者依然能够接触到系统设计的本质,从而建立起驾驭高级人工智能所必需的技术底蕴。
结论

智能原生软件工程(AI-Native SWE)不仅标志着代码编写方式的转变,更代表着软件价值创造体系的彻底重构。从学界对 Teammate.next 的探索和对“生成式复用”风险的警示,到业界对意图驱动交付流水线的全面拥抱,这场变革正在以不可阻挡的势头重塑整个行业。
对于组织而言,迈向 AI-Native 并非简单的采购和部署 AI 工具。它要求组织跨越盲目的炒作周期,参考成熟度模型在战略、文化和治理上进行全方位建设,并在面临嵌入式硬件或功能安全约束时制定专门的智能管治策略。同时,必须废弃那些鼓励盲目堆砌代码量的工业时代效能指标,转而采用关注代码耐用性和复杂性价值的智能时代度量体系,重构以持续反馈和多维验证为核心的 CI/CD 生态系统。
对于开发人员而言,这是一个解除繁文缛节束缚、向更高维度认知跃升的历史机遇。通过完成从“语法编写者”向“意图架构师”的身份演变,开发者将不再被束缚于重复的机械逻辑中。只要坚守住系统架构的判断力,抵御住“氛围编程”带来的盲目信任诱惑,并通过科学的协同机制解决技能退化问题,人类开发者与人工智能就能在这一全新范式中实现真正的共生与共同进化,共同定义软件工程的未来。
—— by 术子米德@2026年5月27日
特别提醒:文章的思路和结构,都来自我(EnigmaWU),内容的检索和组织,包括插图,肯定不来自我的键盘和鼠标。
