 夜雨聆风
夜雨聆风
跟 AI 聊到第 8 轮,它突然把你早就否认过的一句话当成"已确认事实"反复引用——越聊越偏。多数人第一反应是换个 200k 大窗口,但窗口越大,错的待得越久。
长上下文事故复盘题 · 翻车 case 篇
"换 200k 大窗口" 最多 50 分,能讲清 4 段记忆管理(分级摘要 + slot + 改口检测 + 任务重置)才拿 90 分。这题考的不是窗口大不大,是有没有人在管记忆。
一、面试现场
面试官提问
"客服 AI 越聊越偏,加大窗口为什么没用?"
阿里长上下文事故复盘面,候选人答"加大上下文窗口,把完整历史塞进去",面试官停了半秒抛出:"信息没丢,但那段错的也一直在——模型怎么知道它是错的?" 候选人卡住——客服 AI 把用户早就否认过的一句话当"已确认事实"反复引用,到第 8 轮就完全跑偏。这题实际在考你能不能区分"换大窗口"和"管记忆"——前者把错误结论留更久,后者主动作废。
二、大多数人怎么答的
典型翻车回答
"用 128k / 200k 大窗口的模型,把完整历史塞下。"
这答案不算错——窗口太小、早期内容被硬截断确实是问题之一,大窗口能缓解"截断成只剩结论"。能拿 50 分。
天花板在两个绕不过去的硬伤上:
① 错误结论不会因为窗口大就消失——它还在历史里,模型有“自洽偏好”,前面说过的后面继续维护。
② lost in the middle:中间段落注意力衰减,关键早期前提反而被淹没,塞得越多越容易丢。
只靠"塞下去"全答不上来。长上下文不等于长期记忆:前者是"能看多少字",后者是"记什么、怎么更新、什么时候忘"。
三、深度解析(4 段管理 + 1 条硬规则)
生产级长会话,至少要 4 段记忆管理。每段挡一种漏,少一段就漏一种污染。把它们当成必选项,看自己的链路对不对得上。
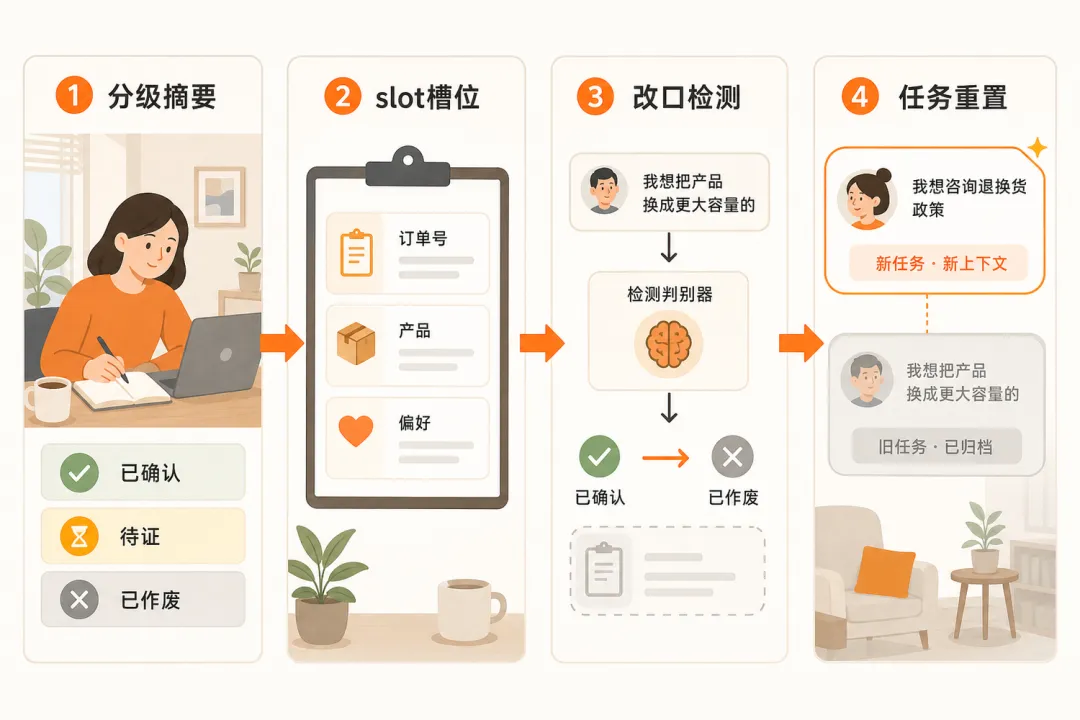
第 1 段:没有摘要分级,所有结论一锅煮、错的当真的
每 N 轮把历史压成 3 档:confirmed_facts(已确认)/ pending_claims(待证)/ retracted(已作废)。错误结论显式移到 retracted,不再喂给模型。不分级的摘要就是把错的当真的。
第 2 段:没有结构化 slot,关键信息靠模型从自由文本回忆
订单号、产品、确认偏好这类关键字段存成 slot,更新就覆盖。不靠模型从历史文本里"回忆"——模型从文本回忆 = 赌运气。slot 是"事实的真相", history 只是"对话的记录"。
第 3 段:没有改口检测,用户更正了模型也不更新
轻量分类器识别"刚才说错了""不是 A 是 B""忽略前面那个",命中就把对应 claim 从 confirmed 移到 retracted。用户改了口,系统得跟着改账本——没有这一步,记忆就是死的。
第 4 段:没有任务重置,新话题被旧上下文带跑
显式信号(用户点新入口、说"换问题")→ 直接重置;自动检测(连续几轮 intent 跳变)→ 软重置:新开任务上下文、旧的降权,重置前给确认话术。该切没切(污染继续)比误切代价大。
我认为:长会话越问越偏的根因不是"窗口不够长",是"没人负责更新和作废记忆"。窗口越大,错误结论待得越久——换大窗口排在最后,前 4 段不到位它救不了你。
四、面试官追问链
追问 1
"摘要 vs 完整历史,什么场景用哪个?"
按会话长度和任务类型分 4 类:
短会话 < 10 轮 + 闲聊——直接喂完整历史,不丢信息
长会话客服 / 助手——摘要式(每 N 轮压一次),代价是摘要有损
任务型对话(下单/配置)——slot 为主,关键字段绝不靠"从文本回忆"
复杂场景——slot 存硬状态 + 摘要存软上下文
"摘要永远更好"是错的——短会话上摘要纯属增加丢信息风险。
追问 2
"用户改口,系统怎么自动识别并清掉旧状态?"
2 步:
① 检测改口意图——轻量分类器识别更正信号,准确率可以做到 90%+
② 定位 + 作废——前提是状态结构化:关键字段在 slot 里就映射 slot 覆盖;自由文本里的 claim 就从 confirmed 移到 retracted,prompt 里显式写"用户已更正:旧值 X 作废"
没有结构化状态,"清掉错误"无从下手——你都不知道要清哪条。
追问 3
"任务切换边界怎么判定?"
显式优先 + 自动兜底:
显式信号(用户点新入口、说"换个问题")→ 直接重置;
无显式信号但意图连续跳变("查物流"→"申请退款")→ 软重置:新开任务上下文、旧的降权。
该切没切(污染继续)比误切(用户重说一遍)代价大,自动检测可以激进点,但重置前给个确认("你是想问退款了吗?")。别承诺"全自动精确判定"——意图边界本身就模糊。
五、落地案例:那次客服事故的改造
把上面 4 段落到出事会话的真实改造——4 步走完。

STEP 1 · 按轮数切片定位污染点
回放历史会话,第 4 轮未证实的猜测在第 6 轮被当事实、第 8 轮进结论。根因:pending 和 confirmed 没分。
↳ 结果:定位 0.5 天,问题归到记忆无分级。
STEP 2 · 引入分级摘要 + slot
每 5 轮摘要一次,产 confirmed/pending/retracted 3 档;订单号、产品、偏好抽进 slot;只把 confirmed + slots + 最近 2 轮原文喂模型。
↳ 结果:2 天上线,prompt 平均缩短 40%。
STEP 3 · 改口检测 + 任务切换
分类器识别"更正/换问题",命中则 retract 对应 claim 或软重置任务线,重置前给确认话术。
↳ 结果:改口识别准确率 93%,误重置率 < 1%。
STEP 4 · 多轮回归集 + 污染告警
40 条"埋错→看引用"长会话 case 进 CI;线上按轮数切片监控答对率斜率,超阈值告警。
↳ 结果:上线 1.5 天,截至 2026-05-27 拦下 2 次摘要回退。
↳ 复盘数据(匿名客服助手)
改造前完整历史策略下,10 轮以上跑偏率约 22%;4 段补齐后 跑偏率降到约 9%,prompt 平均 token 缩短约 40%。残余 9% 主要是摘要丢信息,靠回归集 + 摘要质量监控继续压。
六、本课总结
一句话总结
长会话越问越偏是记忆污染:根因是没人更新/作废记忆,不是窗口不够长。修法 = 分级摘要 + slot + 改口检测 + 任务重置。
面试锦囊
先反问:"您说的'记忆'是指上下文窗口,还是长期状态?"——区分两件事。
再列 4 段:分级摘要(confirmed/pending/retracted)→ slot 存关键字段 → 改口检测 → 任务切换重置。
最后补判断:"该遗忘 vs 该固化的三问——下一轮还成立吗?被否认过吗?属于当前任务吗?任一答否就别带进下一轮。"
下一课预告
用户骂 AI 答错,怎么变成下版本能用的改进?下一课继续往里钻。
留个问题:你那条长会话,4 段里现在只有 1~2 段——你打算先补哪一段?分级摘要、slot 结构化、改口检测,还是任务重置?三选一你站哪边?
