 夜雨聆风
夜雨聆风数据量在增长,业务在跑起来,ClickHouse 集群迟早要扩容。那什么时候该加服务器?加了服务器怎么加才不花冤枉钱?
一、扩容之前,先搞清楚瓶颈在哪
加服务器之前,有一件事值得花一周做:搞清楚你的集群到底卡在哪。
有团队一上来就加分片,结果瓶颈其实在读取端,加了等于白加;也见过有团队先加了三台副本,读性能立刻翻倍,问题解决了。区别就在于——扩容之前有没有搞清楚瓶颈是读、写还是存。
具体怎么做?答案是:先花一周做基线校准——把读写分开、打开批量写入、换对表引擎、装上监控。这四件事不花买服务器的钱,但能让现有的服务器发挥出最大实力。第四节会详细说明每一步怎么做。
做完基线校准后,跑 1-2 周监控,就能看清瓶颈在哪——是 CPU 打满了(写入瓶颈)、是查询慢但副本很闲(读取瓶颈)、还是硬盘快满了(存储瓶颈)。不同的瓶颈对应不同的扩容策略,下一节的大厂案例和后面的路线图会一一说明。
二、看看大厂们怎么配服务器?——5 家公司的真实案例
Cloudflare:全球顶尖水平
• 用了快 10 年 ClickHouse,最大集群 超过 100 台服务器 • 每秒钟处理 数亿条事件数据 • 设计理念:每台服务器都能独立干活,尽量减少"中央指挥" • 2026 年刚修复了一个查询调度 bug,在特定查询场景下显著降低了延迟
小白解读:这是一家做网络安全的公司,每天要分析全球海量访问日志。他们的配置就是"大力出奇迹"——服务器多、数据量大,但管理得很聪明。
字节跳动:自己改装发动机
• 自己研发了改进版的数据引擎,还用上了另一种成熟的数据库技术做辅助 • 效果惊人:服务器坏了恢复时间从 1-2 小时缩短到 3 分钟 • 开源了自研的 ByConity 架构,存储和读取速度均有显著提升
小白解读:就像普通车改装成赛车,字节对 ClickHouse 做了深度改造。一般团队学不来,但说明这条路的上限很高。
携程:10 台服务器扛 700 亿行数据
• 只用 10 台物理机,撑起了 700 亿行 数据 • 自己在应用层做"交通指挥",不用 ClickHouse 自带的分布式引擎 • 60% 的查询能直接命中缓存,不用每次都翻硬盘
小白解读:这是最值得中小团队学的案例。携程没有狂堆服务器,而是把每台服务器的潜力榨干——就像装修房子,不是买更大的房,而是把现有空间利用到极致。
滴滴:走"非主流"路线的日志系统
• 300 多台服务器,但只用单份数据(不设副本) • 用压缩技术 + 另一个存储系统做长期归档 • 接受"偶尔丢一点数据没关系"——因为只是日志,不是订单
小白解读:这是一个"反常识"的案例。通常我们都觉得数据要有备份,但滴滴算了一笔账:日志数据量太大,做备份太贵;丢一点不影响业务,不如把钱省下来。这叫"用业务特点决定技术方案"。
京东(京喜达):中等规模的"标准答案"(据公开技术分享)
• 6 组分片 × 2 份副本 = 12 台服务器,每台 32 核 128G 内存 • 据分享数据,每天新增约 3000 万条数据,双 11 高峰每秒处理 93 个查询,CPU 占用 60%
小白解读:如果你的公司是个中等规模的 SaaS 企业,这个配置差不多就是"毕业配置"——不是最小起步,也不是顶级豪华,而是"够用且有余量"。
5 家配置一览表
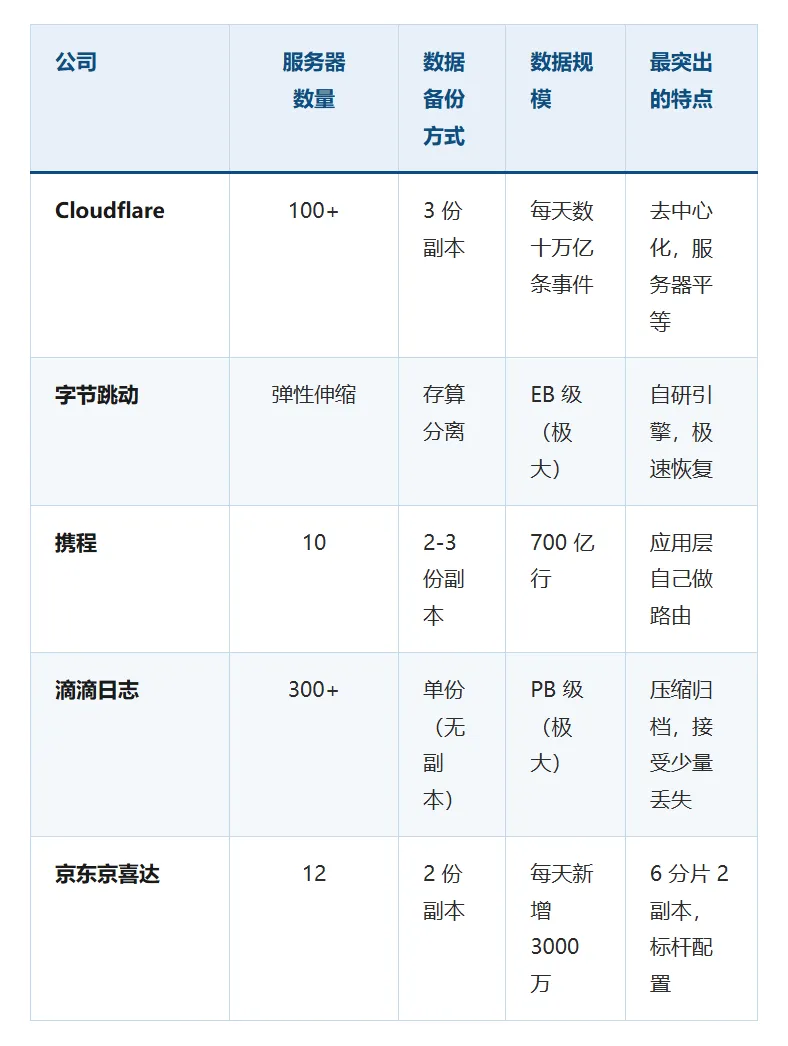
一个关键洞察:服务器数量不重要,"分片数"才是命门
对比这 5 家公司,我发现一个常被忽略的真相:
• 携程只有 10 台服务器,但"分片"分得够细,所以能扛 700 亿行 • 滴滴 300 多台服务器,全用单副本意味着 300 个分片都能存数据,存的数据量远超同等服务器做 3 份备份(只能有 100 个分片),代价是牺牲了冗余 • 京东 12 台服务器,关键是分成了 6 个分片——意味着写入时可以 6 路并行,速度是单分片的 6 倍
服务器数量是"看起来多壮观",分片数才是"实际能扛多少活"。 这个区别在你跟老板申请预算时非常重要——花钱要买"分片能力",不是买"服务器数量"。
一句话总结:ClickHouse 的扩容没有标准答案,但有适合你的答案。携程 10 台扛 700 亿行,靠的是分片分得精;滴滴 300 台敢用单副本,靠的是业务允许取舍。关键不是抄谁的作业,是搞清楚自己的业务需要什么。
三、用云厂商还是自己搭?这笔账怎么算
看完大厂的案例,回到一个接地气的问题:用云厂商的托管服务(比如华为云 MRS),还是自己下载开源 ClickHouse 自己搭?
3.1 云厂商到底"包"了什么
以华为云 MRS 为例,它对开源 ClickHouse 做了 13 项增强。最值钱的 5 个:
1. 自动路由层:帮你做好了"流量往哪台服务器导",开源版你得自己搭 2. 可视化运维面板:70 多个监控指标,点鼠标就能看,不用写脚本 3. 数据迁移工具:扩容要搬数据时,不用手写迁移脚本,拖拖拽拽就能做 4. 多租户管理:不同业务可以设不同的"内存使用上限",热修改不用重启 5. 滚动升级:一台一台升级,业务不中断
云厂商把 ClickHouse 从"手动挡老吉普"改成了"自动挡 SUV"。你不需要会修车,踩油门就能走。
3.2 但有个坑:底层用的还是"老技术"
这是云厂商暂时解决不了的:
• MRS 目前(截至文章撰写时)底层协调器还是用 ZooKeeper • 开源社区主流已经换成了 ClickHouse 自研的 Keeper,内存占用最多能少 46 倍 • 有公司换了之后,CPU 和内存开销直接省了 75% 以上
云厂商为了稳定性,更新会慢一拍。如果你追求最新技术红利,云厂商可能给不了。
3.3 钱到底怎么算
云厂商总费用 = 服务费(含在 License 里)+ 服务器费(另算)
很多公司说"我们已经买了 License",但要搞清楚:
• License 通常只覆盖服务费 • 服务器、硬盘、带宽 都是另外按小时或包年付费的 • 中等规模(6-12 台服务器),服务器、硬盘、带宽的硬件费用往往远超 License 本身
自己搭开源版的账:
• 同等服务器数的纯租用费:省下云厂商的服务费 • 但需要 0.5-1 个专职运维(月薪约 2 万元) • 结论:中小规模自己搭反而更贵——除非这个运维能同时管多个系统,摊薄成本
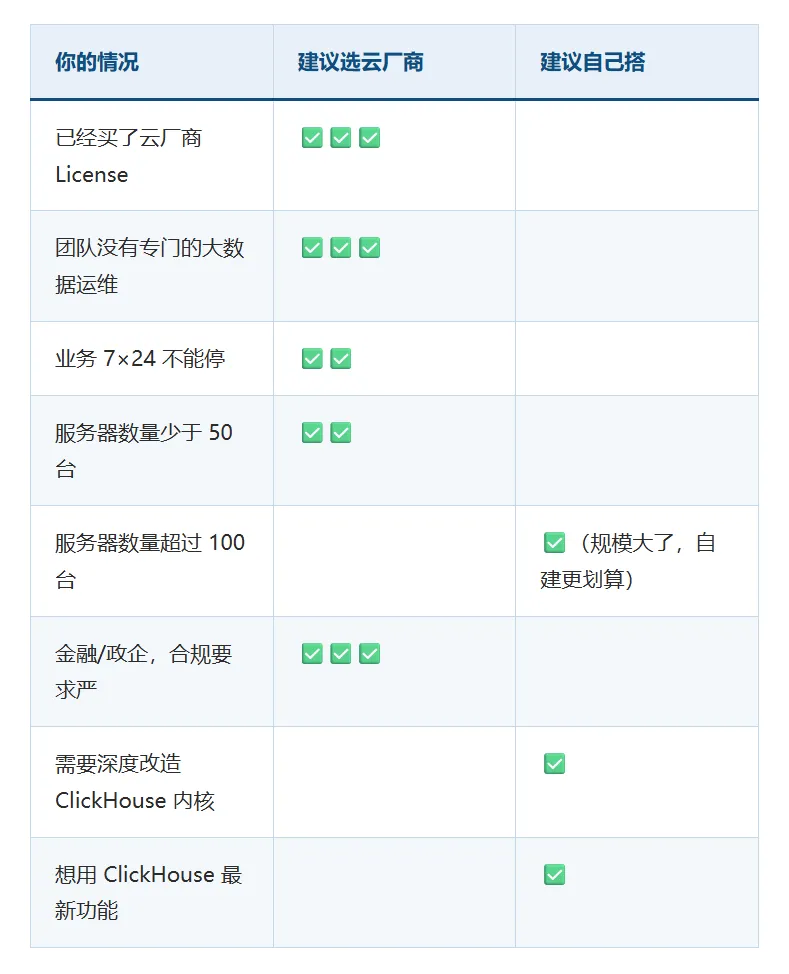
3.4 决策对照表
以下仅供参考,实际决策还需结合团队运维能力、数据敏感性、SLA 要求等因素综合判断。
3.5 第三条路:混合架构
很多中型公司其实是"脚踩两只船":
• 核心生产业务用云厂商(吃满 License、要稳定性保障) • 测试和开发环境用开源自建(接触前沿、省钱) • 长期看存算分离方案(弹性伸缩,用多少付多少)
一句话总结:"已经买了 License"是沉没成本——重点不是"该不该用满",而是"用满之后还差什么,差的这部分有没有更便宜的替代方案"。
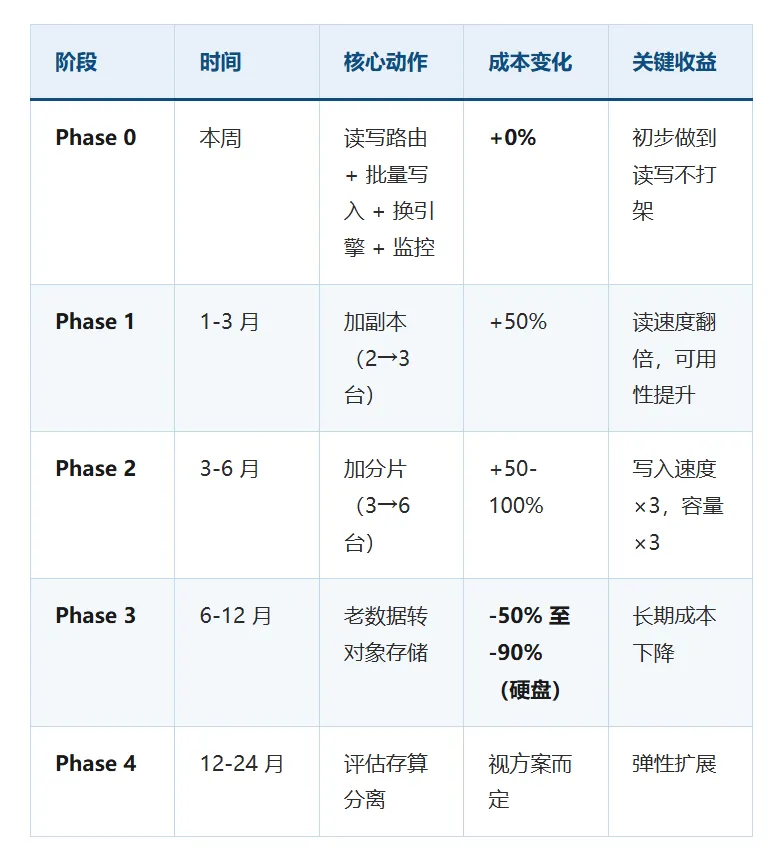
四、扩容路线模型:五个阶段,循序渐进
Phase 0:扩容前的基线校准
这一步不是"劝你不加服务器",而是"加服务器之前先把基线拉齐"。就像盖楼之前要打地基——地基不牢,后面盖得越高越容易歪。做好这一步,你后续每一台新加的服务器都能发挥最大价值。
具体动作和收益:
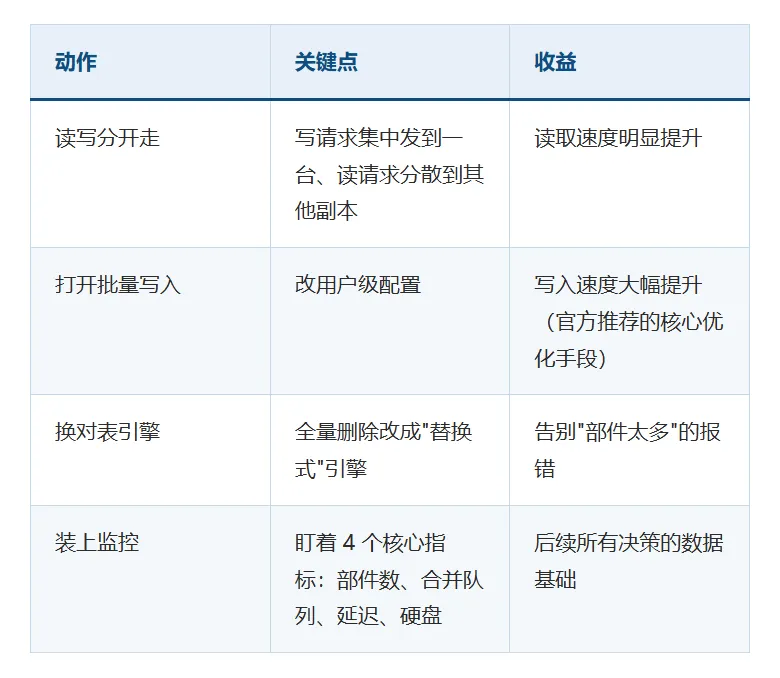
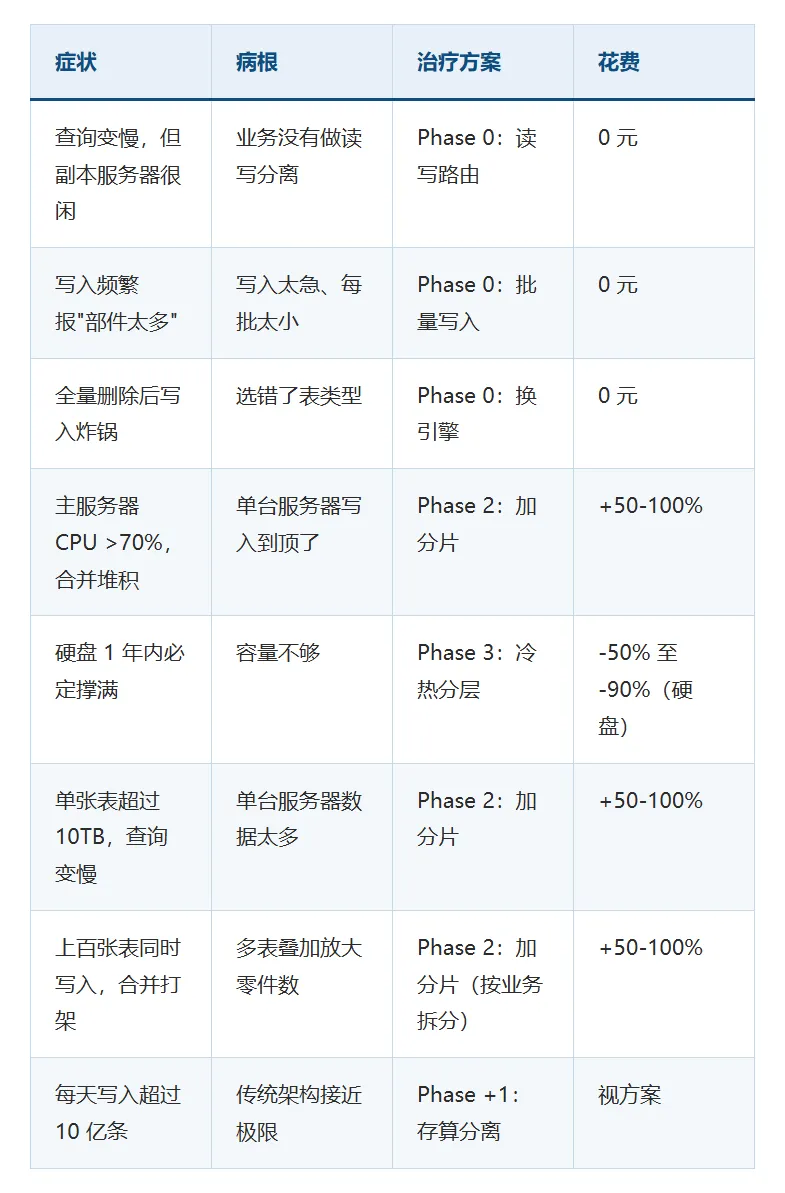
什么时候进入下一阶段:跑 1-2 周监控后,如果主服务器 CPU 还是长期超过 70%、硬盘剩余不到 40%,说明软件红利吃完了,该加服务器了。
Phase 1:加副本(1-3 个月,成本增加约 50%)
目标:从 2 个副本升级到 3 个副本,提高读取能力和数据安全性。
适合什么情况:写入指标正常(CPU 没打满、合并队列正常、硬盘充足),但查询偏慢或需要高可用保障——说明瓶颈在读端,加副本能分担读压力。
收益:配合读负载均衡,读的速度可以翻倍,同时系统从"能用"变成"一台坏了另一台还能顶上"。
Phase 2:加分片(3-6 个月,成本增加 50%-100%)
目标:从"一个小组干活"变成"多个小组并行干活",写入速度和存储容量同时翻倍。
关键问题:什么时候必须从"加副本"转向"加分片"?
出现以下任何一个信号,说明"加副本"已经救不了你了:
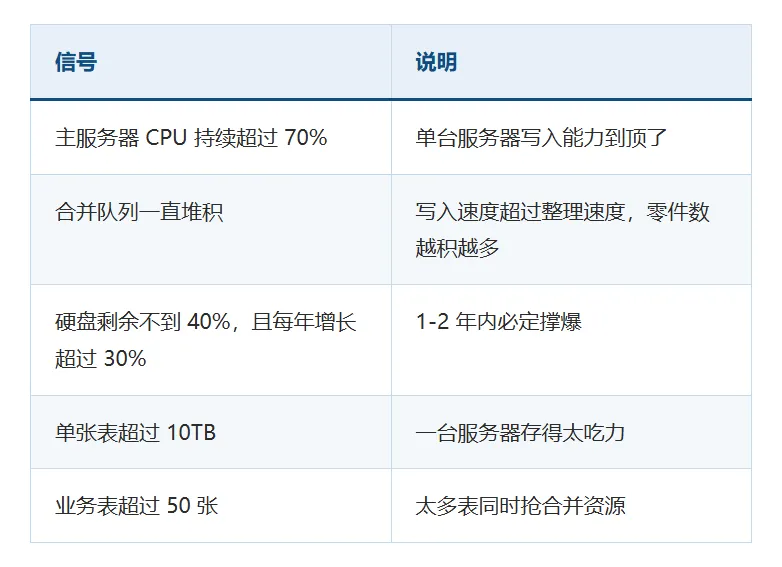
难度提醒:加分片比加副本难得多——数据要重新分布,可能需要停服或接受一段时间的写入降级。就像装修要把家具全部搬出去,工程量大。
Phase 3:冷热分层(6-12 个月,硬盘成本降低 50%-90%)
目标:把"老数据"搬到便宜的对象存储里,本地硬盘只留最近 30 天的热数据。
具体做法:给数据表设置"生命周期规则"——比如 30 天前的数据自动转到对象存储,1 年前的数据直接删除。
经济性对比:
• 本地高速硬盘:约 0.7-2 元/GB/月 • 对象存储(华为云 OBS / 阿里云 OSS / AWS S3):约 0.15 元/GB/月,远低于本地硬盘——实际案例中,小红书存储成本降低 58%,部分场景降幅可达 90%
像你家衣柜,常穿的衣服挂在外面,换季的衣服收进床底储物箱。ClickHouse 也能这样——最近常用的数据放"贵但快"的本地硬盘,老数据放"便宜但慢"的对象存储。查询老数据会慢一点,但成本大幅下降。
Phase 4:评估存算分离(12-24 个月)
触发条件:每天写入超过 10 亿条,或者单张表超过 100TB,或者数据量每年涨 50% 以上。
• 轻量方案:开源 ClickHouse + 对象存储做磁盘 + 多个读集群 • 中量方案:开源的 ByConity 架构,适合 K8s 环境 • 重量方案:ClickHouse 官方云服务,完全托管,不用自己运维
"存算分离"就是把"存数据的仓库"和"算数据的工人"分开。工人(计算资源)可以按需增减,仓库(存储资源)一直放在那儿。高峰期多招几个工人,低谷期减少工人,弹性更强。
路线图总览
一张"病症诊断表"
一句话总结:扩容不是一锤子买卖,是循序渐进的过程。每个阶段解决一类问题,花钱有节奏、风险可控。
五、写在最后:扩容不可怕,怕的是加错了
回头看这五个阶段,你会发现一条清晰的逻辑线:
• 瓶颈在读 → 加副本,读负载一分就通 • 瓶颈在写 → 加分片,写入能力线性增长 • 瓶颈在存 → 冷热分层,老数据搬到便宜的地方 • 瓶颈在弹性 → 存算分离,要多少算力开多少
每种瓶颈对应一种扩容策略,不存在万能解。携程 10 台服务器扛 700 亿行,靠的是分片分得巧;滴滴 300 台敢用单副本,靠的是业务允许丢日志;京东 12 台刚好够用,靠的是配置调到 60% 不浪费也不紧张。
扩容最大的敌人不是预算,是盲目。见过最多的失败模式是:团队跳过基线校准,一上来就加分片,结果数据迁移停服三天,上线发现瓶颈在查询端。也见过最聪明的做法:先花一周做好监控和读写路由,看清楚瓶颈在写入,然后精准加了两组分片,当天搞定。
ClickHouse 的扩容说到底就一句话——加对地方比加得多更重要。先看清瓶颈,再选对阶段,逐步推进。每次扩容都让系统上一个台阶,而不是把同样的钱花两遍。
参考资料
大厂实战博客
• Cloudflare uses ClickHouse to scale analytics at quadrillion-row scale[1] • Cloudflare: ClickHouse query plan contention bug fix (2026/03)[2] • 字节跳动 ByteHouse 云原生之路[3] • 万字长文:ClickHouse 在京喜达实时数据的探索与实践[4]
ClickHouse Keeper
• Why is ClickHouse Keeper recommended over ZooKeeper[5] • Bonree replaces ZooKeeper with ClickHouse Keeper[6]
华为云 MRS 文档
• 华为云 FusionInsight MRS ClickHouse 增强特性介绍[7] • 集群内 ClickHouseServer 节点间数据迁移[8] • 华为云 MRS 定价说明[9]
存算分离方案
• Introducing Warehouses: Compute-compute separation[10] • ByConity GitHub[11]
引用链接
[1] Cloudflare uses ClickHouse to scale analytics at quadrillion-row scale: https://clickhouse.com/blog/cloudflare[2] Cloudflare: ClickHouse query plan contention bug fix (2026/03): https://blog.cloudflare.com/clickhouse-query-plan-contention/[3] 字节跳动 ByteHouse 云原生之路: https://aws.amazon.com/cn/blogs/china/bytehouse-road-to-cloud-native-separation-of-computing-and-storage-and-performance-optimization/[4] 万字长文:ClickHouse 在京喜达实时数据的探索与实践: https://testerhome.com/topics/36578[5] Why is ClickHouse Keeper recommended over ZooKeeper: https://clickhouse.com/docs/knowledgebase/why_recommend_clickhouse_keeper_over_zookeeper[6] Bonree replaces ZooKeeper with ClickHouse Keeper: https://clickhouse.com/blog/bonree-replaces-zookeeper-with-clickhouse-keeper-for-drastically-improved-performance-and-reduced-costs[7] 华为云 FusionInsight MRS ClickHouse 增强特性介绍: https://www.cnblogs.com/huaweicloud/p/16037987.html[8] 集群内 ClickHouseServer 节点间数据迁移: https://support.huaweicloud.com/cmpntguide-mrs/mrs_01_24198.html[9] 华为云 MRS 定价说明: https://www.huaweicloud.com/zhishi/price-mrs.html[10] Introducing Warehouses: Compute-compute separation: https://clickhouse.com/blog/introducing-warehouses-compute-compute-separation-in-clickhouse-cloud[11] ByConity GitHub: https://github.com/ByConity/ByConity
