 夜雨聆风
夜雨聆风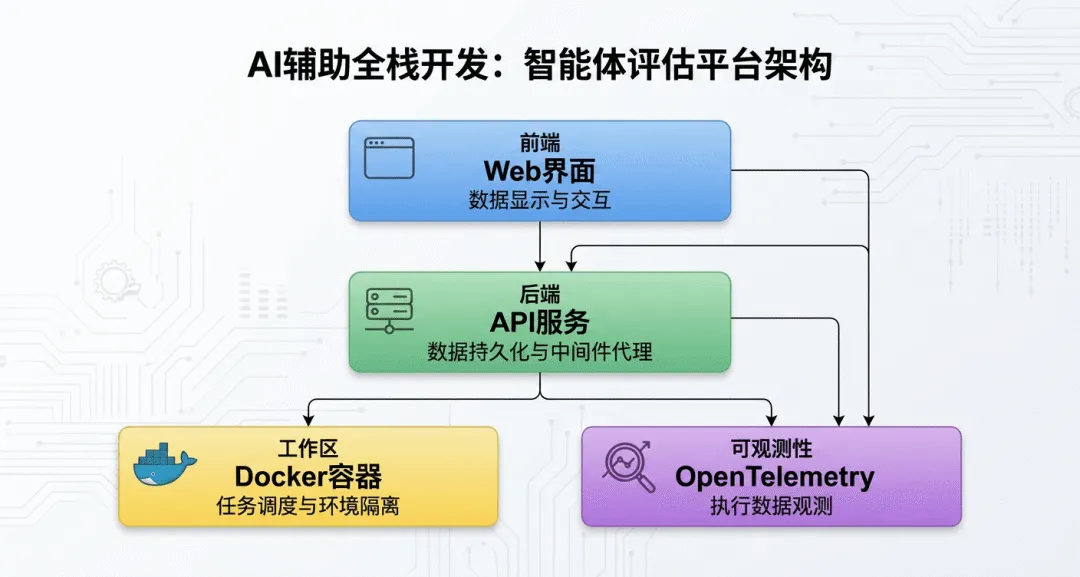
本文完整记录了使用 AI 编程助手(Claude)从零开发一套 Agent 评测平台的全过程,涵盖数据库设计、前后端开发、Jenkins 集成到联调自测的每一个环节。希望通过这次实战经验,帮助大家掌握 AI 辅助开发的正确姿势,避免踩坑。
一、实操技巧:让 AI 写出能用的代码
很多人用 AI 写代码的体验是"生成一堆,能用的没几行"。核心原因不是 AI 能力不够,而是提示词的工程化程度不够。以下是总结的 5 条关键技巧:
1.1 模块切片:一次只做一件事
反面案例:把整个平台的需求一股脑丢给 AI,结果生成的代码结构混乱、模块耦合严重。
正确做法:每次只让 AI 完成一个模块。比如先做项目管理接口,确认没问题后,再做数据集管理接口。
1.2 带上上下文:AI 没有记忆
配置项目级的CLAUDE.md,告诉模型当前的项目代码架构,在架构出现调整的时候及时更新。 主要包含以下内容:
1.整体架构图: 展示前端、后端、评测框架运行端三个核心端的架构关系2.数据流: 展示前端、后端、评测框架之间的数据交互流程3.项目约束: 如schema.prisma生成的文件不能直接修改
1.3 指定文件结构:约束 AI 的自由发挥
明确告诉 AI 要生成哪些文件、放在什么目录。
否则 AI 会按自己的理解组织代码,和现有工程风格不统一。
1.4 给出已有代码:让 AI 复用而非重造
如果项目中已有公共组件、工具函数、统一响应格式,直接粘贴给 AI 让它参照复用。这比事后手动改造效率高得多。
1.5 分层提问:先设计后实现
不要一上来就让 AI 写代码。正确的节奏是:
第一轮:问接口设计 → 确认 API 定义合理第二轮:问数据库设计 → 确认表结构完整第三轮:问具体实现 → 基于前两轮的确认结果编码
总结一句话:先做整体规划,再逐步分解细化,用最小实现打样验证,没问题了再铺开。
二、开发顺序:按依赖关系分五个阶段推进
一个好的开发顺序能避免大量返工。我们按依赖关系和价值交付两个维度,将整个平台拆分为 5 个阶段:
第一阶段:工程基础(2 天)
地基不牢,地动山摇。后面所有开发都依赖这一步。
第二阶段:核心 CRUD(3)
不涉及 Jenkins,前后端可并行开发,效率最高的阶段。
后端优先完成接口,前端用 Mock 同步开发。
开发顺序:
1.项目管理 API — 最顶层,其他模块都依赖 project_id2.环境参数配置 API — repos / dependencies / agent / shell_command3.评估器配置 API — grader + scoring strategy4.数据集 API — 先做元数据 CRUD,OSS 上传放第三阶段
前端同步开发对应的列表页和配置表单。
提示:环境配置表单字段最多最复杂(repos / mcp / agents / shell_command 都是动态列表),放在这个阶段早开发,避免后期成为瓶颈。
第三阶段:任务执行链路(3天)
核心主流程,必须端到端联调,有严格的先后依赖。
YAML Assembler → Jenkins Callback API → 任务触发 API → SSE 状态推送 → 前端任务模块 → 端到端联调每个环节的输出是下一个环节的输入,不能跳步。
第四阶段:报告与大盘(1 天)
依赖第三阶段产生的真实执行数据,包括:
•测评报告页(成功率、平均 Token、评估器得分分布、Case 明细)•数据大盘(Token 消耗趋势、任务次数趋势、项目分布)
第五阶段:完善体验(3天)
锦上添花,不影响主流程:
•OSS 直传(替换临时方案)•数据集预览与单条编辑•Token 额度管理•API Key 加密存储与掩码展示
三、数据库设计:用 Prisma Schema 一步到位
数据库是整个平台的骨架。我们使用 Prisma ORM,在开发初期一次性定义好所有核心表,避免后期频繁 migrate 带来的联调成本。
3.1 核心实体关系
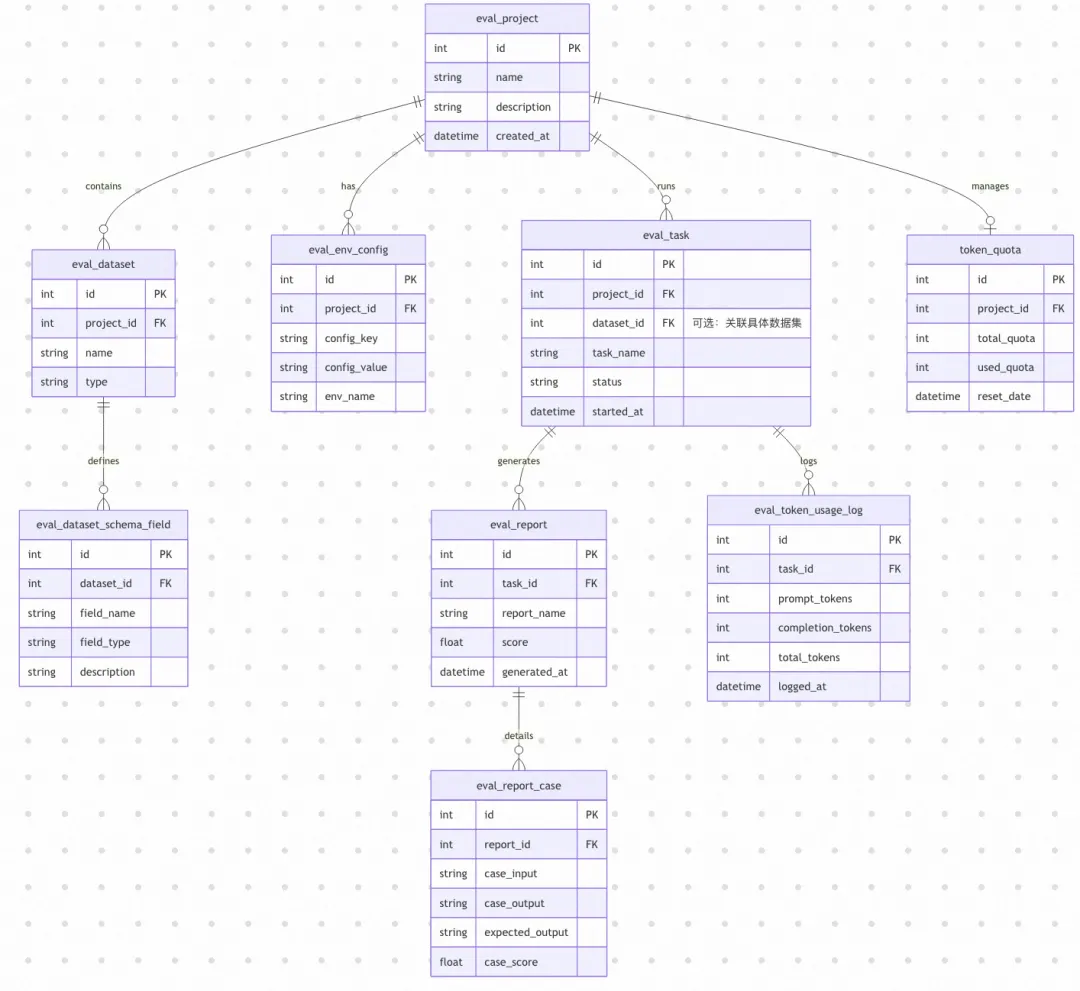
3.2 设计要点
项目表(eval_project):顶层实体,所有资源都通过 project_id 关联。token_quota 和 token_used 直接放在项目表上,避免额外的聚合查询。
数据集表(eval_dataset):元数据与文件分离设计。元数据存 DB,原始文件存 OSS。parse_status 字段跟踪文件解析状态(PENDING / DONE / FAILED)。
任务表(eval_task):状态机设计——PENDING → RUNNING → SUCCESS / FAILED / CANCELLED。jenkins_build_number 字段关联 Jenkins 构建,支持取消操作。
报告表(eval_report + eval_report_case):一对多关系。汇总数据存 report 表用于列表展示,明细数据存 case 表用于下钻分析。
AI 辅助技巧:将完整的 Prisma Schema 文件粘贴给 AI,让它基于表结构生成对应的 CRUD 代码,准确率远高于口头描述。
四、前端开发:从路由设计到页面实现
4.1 路由与导航设计
平台以项目为核心维度组织。侧边导航采用两级结构:
Agent 评测├── 项目管理 ← 项目列表总览├── 通用项目│ ├── 任务管理│ ├── 数据集管理│ ├── 环境参数配置│ └── 测评报告├── BizProject│ ├── 任务管理│ ├── ...└── CustomProject├── 任务管理├── ...
每个项目下的四个子模块功能完全相同,仅 project_id 参数不同,实现一套组件、路由传参复用。
给 AI 的提示词示例:
参考 path: 'BizRouter',新增一个 AgentEval path,children 有三个项目:通用项目、BizProject、CustomProject,每个项目 children 下有 4 个子页面:任务管理、数据集管理、环境参数配置、测评报告,功能一样只是 project_id 不同。
4.2 项目管理页面
项目列表是只读的卡片式展示,核心数据来自两个接口:
GET /ws/agent_eval/projects | |
GET /ws/agent_eval/projects/:id |
关键业务逻辑:
•token_remaining 由后端计算(token_quota - token_used),quota = 0 表示不限制,remaining 返回 -1•stats 聚合字段(数据集数、配置数、任务成功/失败数)实时计算
给 AI 的提示词要点:明确指出复用现有依赖(React + Ant Design),给出完整的接口定义和响应示例,指定参考已有页面的实现风格。
4.3 数据集管理页面
数据集模块是前端最复杂的页面之一,涉及文件上传、Schema 定义、数据预览三个核心功能。
上传流程:前端直传 OSS → 拿到 URL → 提交元数据到后端
用户选择文件 → 前端上传至 OSS → 获取 sourcePath→ POST /ws/agent_eval/projects/:pid/datasets (带 sourcePath)→ 后端创建元数据记录(parse_status: PENDING)→ 后端异步解析文件
关键接口:
POST /projects/:pid/datasets | |
POST /datasets/:id/import | |
PUT /datasets/:id/schema | |
GET /datasets/:id/preview |
校验规则:同项目内 name + version 唯一,冲突返回 40901。
五、后端开发:分层架构 + AI 生成
5.1 后端RESTful API 接口设计
使用实体关系表,去生成最小实现涉及的所有API清单,再通过API清单去实现每个具体的接口设计。
# 项目管理GET /api/projects # 项目列表GET /api/projects/:id # 项目详情(含job信息/token额度)# 数据集管理GET /api/projects/:pid/datasets # 数据集列表POST /api/projects/:pid/datasets # 创建数据集POST /api/datasets/:id/import # 导入数据(xlsx/json)PUT /api/datasets/:id/schema # 更新Schema定义GET /api/datasets/:id/preview # 预览数据(分页)# 环境参数配置GET /api/projects/:pid/env-configs # 环境配置列表POST /api/projects/:pid/env-configs # 创建环境配置PUT /api/env-configs/:id # 更新环境配置# 任务管理GET /api/projects/:pid/tasks # 任务列表POST /api/projects/:pid/tasks # 创建并触发任务DELETE /api/tasks/:id # 取消任务(Jenkins停止)GET /api/tasks/:id/yaml-preview # 预览将要生成的YAML# 测评报告GET /api/tasks/:id/report # 任务报告详情GET /api/projects/:pid/reports # 项目报告列表# Jenkins Callback(内部接口,Jenkins调用)POST /internal/jenkins/callback # 任务结束回调,提交报告数据
5.2 后端开发提示词模板
经过多次迭代,总结出一套高效的后端开发提示词结构:
你是一个资深后端工程师,使用 TypeScript 基于 Node 开发,请实现 Agent 评测平台的 [模块名] 模块。## 相关 Prisma Schema[粘贴对应的 model 定义]## API 文档[粘贴接口定义、请求/响应示例]## 业务逻辑[列出计算规则、校验规则、边界条件]## 参考接口实现接口定义:[已有接口路径]涉及代码:[controller / service 文件路径]请参考已有接口实现,复用已有的库和代码实现风格,包括项目分层结构、统一响应格式等,逐文件输出完整代码。
核心要素:Schema + API 文档 + 业务逻辑 + 参考实现,四者缺一不可。
5.3 项目接口实现
以项目列表接口为例,生成的代码遵循三层架构:
src/controller/agent_eval/project.ts ← 路由定义、参数校验src/service/agent_eval/project.ts ← 业务逻辑、数据聚合
核心业务逻辑:
•项目列表支持分页和状态过滤•token_remaining 后端实时计算•项目详情附带 stats 聚合数据,使用 Prisma 的 _count 一次查询完成
验证接口响应符合预期:
{"code": "1","message": "success","data": {"list": [{"id": 3,"name": "BizProject","token_quota": 20000000,"token_used": 0,"token_remaining": 20000000,"status": "active"}],"total": 3,"page": 1,"page_size": 20}}
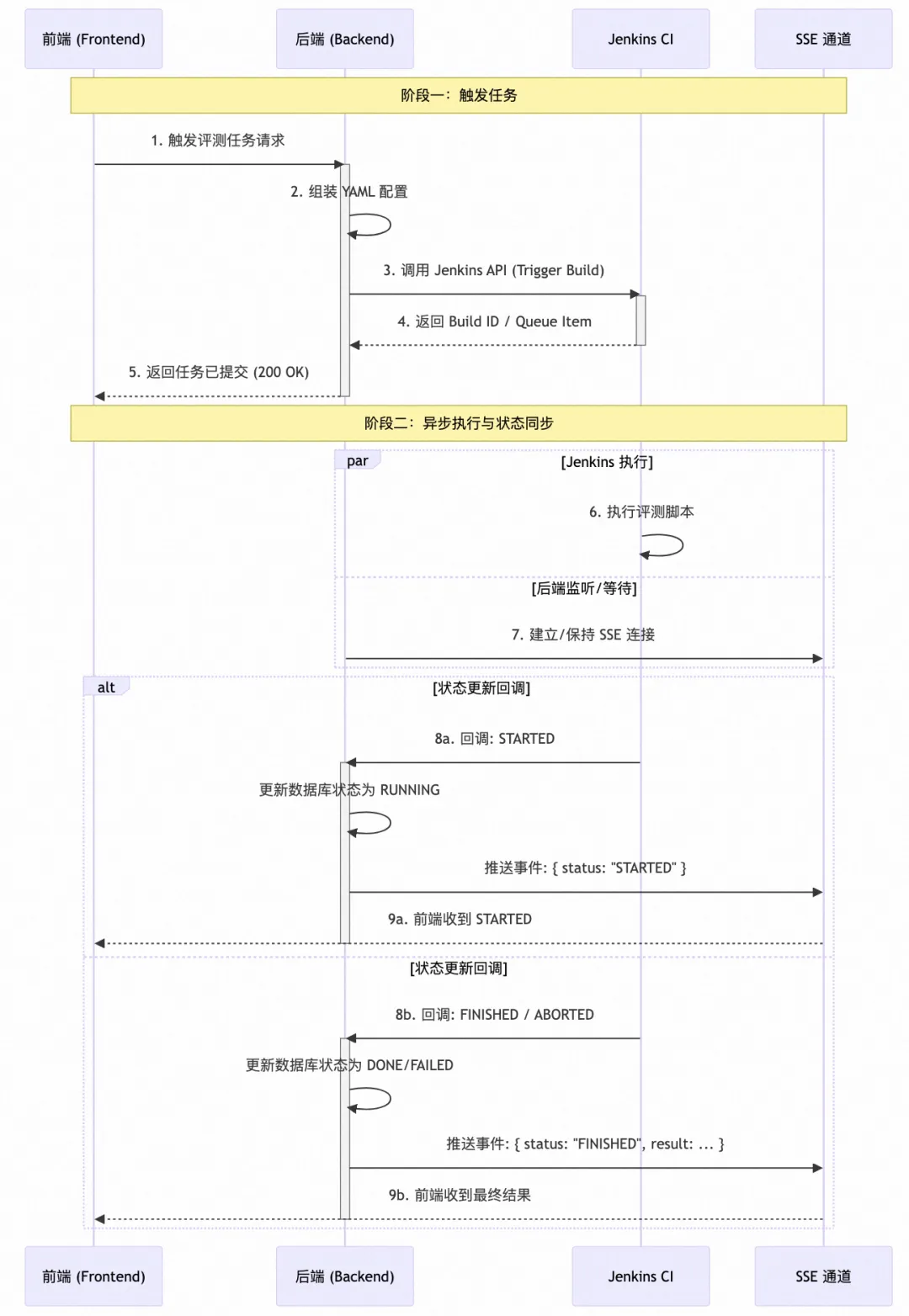
六、运行端开发:Jenkins 集成与回调机制
运行端是连接前后端与实际评测执行的桥梁,核心是 Jenkins 的集成与回调。
6.1 任务执行流程
七、联调自测:让 AI 设计测试用例
联调阶段最容易出问题的,往往不是代码逻辑错误,而是各环节对接时的边界情况。我们的做法是:让 AI 先理解设计架构和工作原理,再让它设计测试用例。
7.1 功能验证:以 Git Diff 模块为例
这个模块需要在包含多个子 Git 仓库的工作区中,统一收集所有文件变更。我们设计了一个分步验证流程:
Step 1:调用 create_git_baseline 创建基线Step 2:修改一个已有文件(新增一行 "test modify")Step 3:删除一个子仓库中的文件Step 4:在另一个子仓库中新增两个文件Step 5:调用 generate_workspace_diff 生成 diff 报告
预期的 diff 输出应包含:
root_git_project/├── [EDIT] file1├── child_git_project1/│ └── [DELETE] file2└── child_git_project2/└── [ADD] file3
7.2 问题定位与修复
首次运行结果不符合预期——只检测到 1 个修改文件,新增和删除的文件都丢失了。
根本原因:代码只扫描了根仓库的变更,没有递归扫描子 Git 仓库。
修复提示词的关键在于描述清楚实际的仓库结构和期望结果:
实现不符合预期。已有的真实 git 仓库下验证,根目录是一个 git 仓库,根目录下还有多个子 git 仓库。当存在多个文件变更时,都应统一获取到。实际结果:Added 0, Deleted 0, Modified 1期望结果:Added 1, Deleted 1, Modified 1
这比笼统地说"有 bug,请修复"有效得多。
7.3 联调自测的核心原则
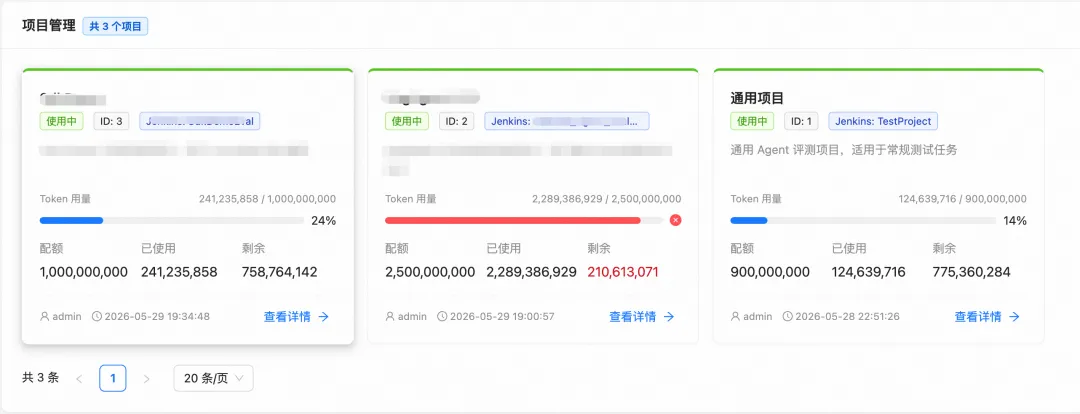
八、实现效果
经过五个阶段的迭代开发,最终交付了一套完整的 Agent 评测平台,核心能力包括:支持多运行器(OpenCode、QoderCli)、多模型(claude、glm、qwen、kimi等)、可选Skill插件的端到端评测平台。
实现完整流程:① 创建项目 → ② 导入数据集 → ③ 配置环境 → ④ 创建评分器 → ⑤ 配置评分策略 → ⑥ 创建并执行任务 → ⑦ 查看报告
写在最后
回顾整个开发过程,AI 辅助开发不是"把需求丢给 AI 就完事",它更像是和一个能力很强但没有上下文的新同事协作。你需要:
1.做好规划:AI 擅长执行,不做约束容易失控。整体架构和开发顺序需要你来定。2.提供上下文:每次对话都带上表结构、接口文档、已有代码风格,AI 的输出质量直接和输入质量成正比。3.分步验证:不要等所有代码都生成完再验证。每个模块生成后立即验证,发现问题及时纠正。4.精确描述问题:当结果不符合预期时,描述"期望什么、实际什么、差距在哪",远比"有 bug 请修复"有效。
AI 辅助开发的本质是把人的时间从编码搬运转移到设计思考和质量把控上。用好了,开发效率可以提升数倍;用不好,可能还不如自己写。
希望这篇实战记录对你有帮助。如果你也在探索 AI 辅助开发,欢迎交流。
