 夜雨聆风
夜雨聆风这篇文章学kube-scheduler,不废话直接发车。
1.1、 kube-scheduler的启动流程
// C:\git\kubernetes-1.22.3\cmd\kube-scheduler\scheduler.gofunc main() { rand.Seed(time.Now().UnixNano()) pflag.CommandLine.SetNormalizeFunc(cliflag.WordSepNormalizeFunc) command := app.NewSchedulerCommand() logs.InitLogs()defer logs.FlushLogs()if err := command.Execute(); err != nil { os.Exit(1) }}追踪app.NewSchedulerCommand,kube-scheduler启动还是通过cobra.Command实现的。追踪cobra.Command.Run中的runCommand。
// C:\git\kubernetes-1.22.3\cmd\kube-scheduler\app\server.go// runCommand runs the scheduler.func runCommand(cmd *cobra.Command, opts *options.Options, registryOptions ...Option)error { verflag.PrintAndExitIfRequested() cliflag.PrintFlags(cmd.Flags()) ctx, cancel := context.WithCancel(context.Background())defer cancel()go func() { stopCh := server.SetupSignalHandler() <-stopCh cancel() }()/* func Setup(ctx, opts, outOfTreeRegistryOptions) (*schedulerserverconfig.CompletedConfig, *scheduler.Scheduler, error) setup返回一个完整的配置和scheduler对象 */ cc, sched, err := Setup(ctx, opts, registryOptions...)if err != nil {return err }return Run(ctx, cc, sched)}追踪Setup
func Setup(ctx context.Context, opts *options.Options, outOfTreeRegistryOptions ...Option) (*schedulerserverconfig.CompletedConfig, *scheduler.Scheduler, error) { c, err := opts.Config()}追踪opts.Config
// C:\git\kubernetes-1.22.3\cmd\kube-scheduler\app\options\options.go// Config return a scheduler config objectfunc (o *Options) Config() (*schedulerappconfig.Config, error) {// 新建一个空的调度器配置对象 c := &schedulerappconfig.Config{}// ApplyTo 把 Options 里的所有参数(端口、日志、调度策略、客户端配置等)填充到配置对象中if err := o.ApplyTo(c); err != nil {return nil, err }return c, nil// 使用 --kubeconfig传入的配置初始化kube config kubeConfig, err := createKubeConfig(c.ComponentConfig.ClientConnection, o.Master)if err != nil {return nil, err }// 使用kube-config 创建client-set对象 client, eventClient, err := createClients(kubeConfig)if err != nil {return nil, err } c.EventBroadcaster = events.NewEventBroadcasterAdapter(eventClient)}继续追踪Options.Config,接下来是初始化事件广播器,这里后面会详细讨论。
// C:\git\kubernetes-1.22.3\cmd\kube-scheduler\app\options\options.go// Config return a scheduler config objectfunc (o *Options) Config() (*schedulerappconfig.Config, error) {/* EventBroadcaster:事件广播器 统一管理调度器产生的所有事件(如调度成功、调度失败、节点不可用) 依赖 eventClient 将事件发送到 APIServer */ c.EventBroadcaster = events.NewEventBroadcasterAdapter(eventClient)}继续追踪Options.Config,接下来是开启选举主的锁配置,默认scheduler 启动的时候 带上参数 --leader-elect=true,代表先选主再进行主流程,为了高可用部署,这里后面会详细讨论。
// C:\git\kubernetes-1.22.3\cmd\kube-scheduler\app\options\options.go// Config return a scheduler config objectfunc (o *Options) Config() (*schedulerappconfig.Config, error) {// Set up leader election if enabled.var leaderElectionConfig *leaderelection.LeaderElectionConfigif c.ComponentConfig.LeaderElection.LeaderElect {// Use the scheduler name in the first profile to record leader election. schedulerName := corev1.DefaultSchedulerNameif len(c.ComponentConfig.Profiles) != 0 { schedulerName = c.ComponentConfig.Profiles[0].SchedulerName } coreRecorder := c.EventBroadcaster.DeprecatedNewLegacyRecorder(schedulerName) leaderElectionConfig, err = makeLeaderElectionConfig(c.ComponentConfig.LeaderElection, kubeConfig, coreRecorder)if err != nil {return nil, err } }return c, nil}这样schedulerappconfig.Config对象完成了初始化,回到Setup函数 scheduler.New,创建一个scheduler对象。
// C:\git\kubernetes-1.22.3\cmd\kube-scheduler\app\server.go// Setup creates a completed config and a scheduler based on the command args and optionsfunc Setup(ctx context.Context, opts *options.Options, outOfTreeRegistryOptions ...Option) (*schedulerserverconfig.CompletedConfig, *scheduler.Scheduler, error) { c, err := opts.Config()if err != nil {return nil, nil, err } sched, err := scheduler.New(cc.Client, cc.InformerFactory, recorderFactory, ctx.Done(), scheduler.WithComponentConfigVersion(cc.ComponentConfig.TypeMeta.APIVersion), scheduler.WithKubeConfig(cc.KubeConfig), scheduler.WithProfiles(cc.ComponentConfig.Profiles...), scheduler.WithLegacyPolicySource(cc.LegacyPolicySource), scheduler.WithPercentageOfNodesToScore(cc.ComponentConfig.PercentageOfNodesToScore), scheduler.WithFrameworkOutOfTreeRegistry(outOfTreeRegistry), scheduler.WithPodMaxBackoffSeconds(cc.ComponentConfig.PodMaxBackoffSeconds), scheduler.WithPodInitialBackoffSeconds(cc.ComponentConfig.PodInitialBackoffSeconds), scheduler.WithExtenders(cc.ComponentConfig.Extenders...), scheduler.WithParallelism(cc.ComponentConfig.Parallelism), scheduler.WithBuildFrameworkCapturer(func(profile kubeschedulerconfig.KubeSchedulerProfile) {// Profiles are processed during Framework instantiation to set default plugins and configurations. Capturing them for logging completedProfiles = append(completedProfiles, profile) }), )return &cc, sched, nil}到这里完成了Schedulerserverconfig.CompletedConfig和scheduler.Scheduler
的生成。回到runCommand.Run开始kube-scheduler的运行。
// C:\git\kubernetes-1.22.3\cmd\kube-scheduler\app\server.go// runCommand runs the scheduler.func runCommand(cmd *cobra.Command, opts *options.Options, registryOptions ...Option)error { cc, sched, err := Setup(ctx, opts, registryOptions...)return Run(ctx, cc, sched)}追踪Run方法
// C:\git\kubernetes-1.22.3\cmd\kube-scheduler\app\server.gofunc Run(ctx context.Context, cc *schedulerserverconfig.CompletedConfig, sched *scheduler.Scheduler)error {/* 注册/configz的路由,可以通过这个路由获取到kube-scheduler配置信息 curl -s -k https://localhost:10259/configz --header "Authorization: Bearer $TOKEN" |python -m json.tool */if cz, err := configz.New("componentconfig"); err == nil { cz.Set(cc.ComponentConfig) } else {return fmt.Errorf("unable to register configz: %s", err) }// 启动事件广播管理器 cc.EventBroadcaster.StartRecordingToSink(ctx.Done())// 初始化健康检查var checks []healthz.HealthCheckerif cc.ComponentConfig.LeaderElection.LeaderElect { checks = append(checks, cc.LeaderElection.WatchDog) }}继续追踪Run
// C:\git\kubernetes-1.22.3\cmd\kube-scheduler\app\server.gofunc Run(ctx context.Context, cc *schedulerserverconfig.CompletedConfig, sched *scheduler.Scheduler)error {/* channel 打开 → 还没选主 / 我不是主 channel 关闭 → 我已经成为主! */ waitingForLeader := make(chan struct{})/* isLeader() 函数给健康检查使用: 没成为主isLeader返回false,成为主isLeader返回true。 */ isLeader := func()bool {select {case _, ok := <-waitingForLeader:// if channel is closed, we are leadingreturn !okdefault:// channel is open, we are waiting for a leaderreturn false } }if cc.InsecureMetricsServing != nil {/* handler := buildHandlerChain(newMetricsHandler(&cc.ComponentConfig, cc.InformerFactory, isLeader), nil, nil) */var metricsHandler http.Handler = newMetricsHandler(&cc.ComponentConfig, cc.InformerFactory, isLeader) handler := buildHandlerChain(metricsHandler, nil, nil) if err := cc.InsecureMetricsServing.Serve(handler, 0, ctx.Done()); err != nil {return fmt.Errorf("failed to start metrics server: %v", err) } }}追踪isLeader,可以看到isLeader会决定某些功能是否开启。例如深入newMetricsHandler,其中的installMetricHandler,注册 /metrics 指标接口,并且只有主节点(Leader)才暴露资源使用指标,从节点不暴露。
// C:\git\kubernetes-1.22.3\cmd\kube-scheduler\app\server.gofunc installMetricHandler(pathRecorderMux *mux.PathRecorderMux, informers informers.SharedInformerFactory, isLeader func()bool) { configz.InstallHandler(pathRecorderMux) pathRecorderMux.Handle("/metrics", legacyregistry.HandlerWithReset()) resourceMetricsHandler := resources.Handler(informers.Core().V1().Pods().Lister()) pathRecorderMux.HandleFunc("/metrics/resources", func(w http.ResponseWriter, req *http.Request) {if !isLeader() {return } resourceMetricsHandler.ServeHTTP(w, req) })}继续追踪buildHandlerChain
// C:\git\kubernetes-1.22.3\cmd\kube-scheduler\app\server.go// buildHandlerChain 用标准过滤器包装传入的 handler,形成一条完整的 HTTP 请求处理链func buildHandlerChain(handler http.Handler, authn authenticator.Request, authz authorizer.Authorizer) http.Handler {// 创建请求信息解析器,用来解析 HTTP 请求里的 API 信息(如:访问哪个资源、什么操作) requestInfoResolver := &apirequest.RequestInfoFactory{}// 创建认证失败时的默认处理器:当用户认证不通过时,返回 401 Unauthorized failedHandler := genericapifilters.Unauthorized(scheme.Codecs)// 第 1 层:授权检查 → 验证当前用户是否有权限访问这个接口(RBAC 权限判断) handler = genericapifilters.WithAuthorization(handler, authz, scheme.Codecs)// 第 2 层:认证检查 → 验证用户是谁(Token、证书等),失败则走 failedHandler handler = genericapifilters.WithAuthentication(handler, authn, failedHandler, nil)// 第 3 层:解析请求信息 → 从 HTTP 请求中提取 API 资源、动词、命名空间等信息 handler = genericapifilters.WithRequestInfo(handler, requestInfoResolver)// 第 4 层:设置缓存控制 → 告诉客户端不要缓存健康检查/metrics 接口 handler = genericapifilters.WithCacheControl(handler)// 第 5 层:HTTP 请求日志 → 记录请求的路径、响应码、耗时等 handler = genericfilters.WithHTTPLogging(handler)// 第 6 层:Panic 恢复 → 处理接口内部崩溃,避免进程直接挂掉,返回 500 错误 handler = genericfilters.WithPanicRecovery(handler, requestInfoResolver)// 返回包装完成的完整处理链return handler}继续回到Run
// C:\git\kubernetes-1.22.3\cmd\kube-scheduler\app\server.go// Run executes the scheduler based on the given configuration. It only returns on error or when context is done.func Run(ctx context.Context, cc *schedulerserverconfig.CompletedConfig, sched *scheduler.Scheduler)error {// 启动所有informer cc.InformerFactory.Start(ctx.Done())// 执行调度前,先把通过informer把资源缓存到本地 cc.InformerFactory.WaitForCacheSync(ctx.Done())}开启LeaderElection选主的流程,如果被选为主的话则执行sched.Run
// C:\git\kubernetes-1.22.3\cmd\kube-scheduler\app\server.go// Run executes the scheduler based on the given configuration. It only returns on error or when context is done.func Run(ctx context.Context, cc *schedulerserverconfig.CompletedConfig, sched *scheduler.Scheduler)error {// If leader election is enabled, runCommand via LeaderElector until done and exit.if cc.LeaderElection != nil { cc.LeaderElection.Callbacks = leaderelection.LeaderCallbacks{ OnStartedLeading: func(ctx context.Context) {close(waitingForLeader) sched.Run(ctx) }, OnStoppedLeading: func() {select {case <-ctx.Done():// We were asked to terminate. Exit 0. klog.Info("Requested to terminate. Exiting.") os.Exit(0)default:// We lost the lock. klog.Exitf("leaderelection lost") } }, } leaderElector, err := leaderelection.NewLeaderElector(*cc.LeaderElection)if err != nil {return fmt.Errorf("couldn't create leader elector: %v", err) } leaderElector.Run(ctx)return fmt.Errorf("lost lease") }// Leader election is disabled, so runCommand inline until done.close(waitingForLeader) sched.Run(ctx)return fmt.Errorf("finished without leader elect")}至此,kube-scheduler启动完成
1.2 、kube-scheduler中的leader election选主机制
kube-scheduler与kube-controller-manager常以多副本部署实现高可用,依靠leaderelection机制完成选主。该机制借助 K8s API 操作原子性构建分布式锁,实例间相互竞争,同一时段仅有leader实例执行业务。原有leader故障后,集群会重新推选新leader,保障组件持续稳定运行,这类设计在 K8s 中普遍应用。
// C:\git\kubernetes-1.22.3\cmd\kube-scheduler\app\options\options.go// Complete completes the remaining instantiation of the options obj.// In particular, it injects the latest internal versioned ComponentConfig.func (o *Options) Complete(nfs *cliflag.NamedFlagSets) error {// 根据--leader-elect=true 配置开启选主抢锁 leaderelection := nfs.FlagSet("leader election")if leaderelection.Changed("leader-elect") { cfg.LeaderElection.LeaderElect = o.ComponentConfig.LeaderElection.LeaderElect }}// Config return a scheduler config objectfunc (o *Options) Config() (*schedulerappconfig.Config, error) {// Set up leader election if enabled.var leaderElectionConfig *leaderelection.LeaderElectionConfigif c.ComponentConfig.LeaderElection.LeaderElect {// Use the scheduler name in the first profile to record leader election. schedulerName := corev1.DefaultSchedulerNameif len(c.ComponentConfig.Profiles) != 0 { schedulerName = c.ComponentConfig.Profiles[0].SchedulerName } coreRecorder := c.EventBroadcaster.DeprecatedNewLegacyRecorder(schedulerName) leaderElectionConfig, err = makeLeaderElectionConfig(c.ComponentConfig.LeaderElection, kubeConfig, coreRecorder)if err != nil {return nil, err } }}追踪makeLeaderElectionConfig,makeLeaderElectionConfig 用于创建选主抢锁配置:
以主机名拼接
uuid作为实例唯一标识依托
resourcelock资源锁实现竞争选主锁相关默认配置可通过
/configz接口查询# curl -s -k https://localhost:10259/configz --header "Authorization: Bearer $TOKEN" |python -m json.tool{ "LeaderElection": { "LeaderElect": true, "LeaseDuration": "15s", "RenewDeadline": "10s", "ResourceLock": "leases", "ResourceName": "kube-scheduler", "ResourceNamespace": "kube-system", "RetryPeriod": "2s" }}
// C:\git\kubernetes-1.22.3\cmd\kube-scheduler\app\options\options.go// makeLeaderElectionConfig 根据参数创建一个选主配置,用于抢分布式锁func makeLeaderElectionConfig( config componentbaseconfig.LeaderElectionConfiguration, kubeConfig *restclient.Config, recorder record.EventRecorder) (*leaderelection.LeaderElectionConfig, error) {// 获取当前机器的主机名,用于标识当前实例 hostname, err := os.Hostname()if err != nil {return nil, fmt.Errorf("unable to get hostname: %v", err) }// 给当前实例生成一个全局唯一ID:主机名 + UUID// 目的:防止同一台机器上的两个进程冲突 id := hostname + "_" + string(uuid.NewUUID())// ====================== 核心:创建分布式锁 ======================// 创建资源锁(基于 Lease/ConfigMap/Endpoint 实现)// 所有 scheduler 抢的就是这把锁 rl, err := resourcelock.NewFromKubeconfig( config.ResourceLock, // 锁类型:Lease/ConfigMap config.ResourceNamespace, // 锁所在命名空间:kube-system config.ResourceName, // 锁名称:kube-scheduler resourcelock.ResourceLockConfig{ Identity: id, // 当前实例唯一ID EventRecorder: recorder, // 事件记录器 }, kubeConfig, // 连接 APIServer 的配置 config.RenewDeadline.Duration, )if err != nil {return nil, fmt.Errorf("couldn't create resource lock: %v", err) }// 返回最终的选主配置return &leaderelection.LeaderElectionConfig{ Lock: rl, // 分布式锁(所有实例抢这把锁) LeaseDuration: config.LeaseDuration.Duration, // 锁租期:15s RenewDeadline: config.RenewDeadline.Duration, // 续租超时:10s RetryPeriod: config.RetryPeriod.Duration, // 抢锁重试间隔:2s WatchDog: leaderelection.NewLeaderHealthzAdaptor(time.Second * 20), // 健康检查 Name: "kube-scheduler", // 选主组件名称 ReleaseOnCancel: true, // 停止时主动释放锁 }, nil}追踪resourcelock.NewFromKubeconfig,观察resourcelock资源锁的初始化
// C:\git\kubernetes-1.22.3\vendor\k8s.io\client-go\tools\leaderelection\resourcelock\interface.go// NewFromKubeconfig will create a lock of a given type according to the input parameters.// Timeout set for a client used to contact to Kubernetes should be lower than// RenewDeadline to keep a single hung request from forcing a leader loss.// Setting it to max(time.Second, RenewDeadline/2) as a reasonable heuristic.func NewFromKubeconfig(lockType string, ns string, name string, rlc ResourceLockConfig, kubeconfig *restclient.Config, renewDeadline time.Duration) (Interface, error) {// shallow copy, do not modify the kubeconfig config := *kubeconfig timeout := renewDeadline / 2if timeout < time.Second { timeout = time.Second } config.Timeout = timeout leaderElectionClient := clientset.NewForConfigOrDie(restclient.AddUserAgent(&config, "leader-election"))return New(lockType, ns, name, leaderElectionClient.CoreV1(), leaderElectionClient.CoordinationV1(), rlc)}其中的New方法用来创建资源锁,可以看到支持多种锁类型:Lease、ConfigMap、Endpoints 等
// C:\git\kubernetes-1.22.3\vendor\k8s.io\client-go\tools\leaderelection\resourcelock\interface.go// Manufacture will create a lock of a given type according to the input parameters// New 根据传入的参数,创建指定类型的资源锁(真正干活的锁)func New( lockType string, // 锁类型:Lease、ConfigMap、Endpoints 等 ns string, // 命名空间(一般是 kube-system) name string, // 锁名字(如 kube-scheduler) coreClient corev1.CoreV1Interface, // 核心API客户端 coordinationClient coordinationv1.CoordinationV1Interface, // Lease 专用客户端 rlc ResourceLockConfig)// 锁配置(唯一标识、事件记录器)(Interface, error) {// 1. 创建 Endpoints 锁(老式锁) endpointsLock := &EndpointsLock{ EndpointsMeta: metav1.ObjectMeta{ Namespace: ns, Name: name, }, Client: coreClient, LockConfig: rlc, }// 2. 创建 ConfigMap 锁(老式锁) configmapLock := &ConfigMapLock{ ConfigMapMeta: metav1.ObjectMeta{ Namespace: ns, Name: name, }, Client: coreClient, LockConfig: rlc, }// 3. 创建 Lease 锁(新式、推荐、高性能锁) leaseLock := &LeaseLock{ LeaseMeta: metav1.ObjectMeta{ Namespace: ns, Name: name, }, Client: coordinationClient, LockConfig: rlc, }// ====================== 核心:根据类型返回对应锁 ======================switch lockType {case EndpointsResourceLock:return endpointsLock, nil// 只用 Endpoints 锁case ConfigMapsResourceLock:return configmapLock, nil// 只用 ConfigMap 锁case LeasesResourceLock:return leaseLock, nil// 只用 Lease 锁(K8s 现在默认用这个)case EndpointsLeasesResourceLock:return &MultiLock{ // 双锁:主锁 Endpoints + 备锁 Lease Primary: endpointsLock, Secondary: leaseLock, }, nilcase ConfigMapsLeasesResourceLock:return &MultiLock{ // 双锁:主锁 ConfigMap + 备锁 Lease Primary: configmapLock, Secondary: leaseLock, }, nildefault:return nil, fmt.Errorf("Invalid lock-type %s", lockType) }}回到kube-schedule的server的Run方法,查看scheduler中抢锁的运行
// C:\git\kubernetes-1.22.3\cmd\kube-scheduler\app\server.go// Run executes the scheduler based on the given configuration. It only returns on error or when context is done.func Run(ctx context.Context, cc *schedulerserverconfig.CompletedConfig, sched *scheduler.Scheduler)error {// If leader election is enabled, runCommand via LeaderElector until done and exit.// 如果开启了 --leader-elect=trueif cc.LeaderElection != nil {// 设置选主回调 cc.LeaderElection.Callbacks = leaderelection.LeaderCallbacks{// 成功抢到锁,成为 Leader OnStartedLeading: func(ctx context.Context) {// 标记自己是主close(waitingForLeader)// 真正开始调度Pod sched.Run(ctx) },// 锁丢了(主节点挂了/网络断了) OnStoppedLeading: func() {select {case <-ctx.Done():// We were asked to terminate. Exit 0. klog.Info("Requested to terminate. Exiting.") os.Exit(0)default:// We lost the lock.// 直接退出 klog.Exitf("leaderelection lost") } }, }// 创建选主器 leaderElector, err := leaderelection.NewLeaderElector(*cc.LeaderElection)if err != nil {return fmt.Errorf("couldn't create leader elector: %v", err) }// 开始抢锁、续租、监听锁变化 leaderElector.Run(ctx)return fmt.Errorf("lost lease") }// 没有开启选主(--leader-elect=false)// Leader election is disabled, so runCommand inline until done.// 不抢主close(waitingForLeader)// 直接开始调度 sched.Run(ctx)return fmt.Errorf("finished without leader elect")}追踪过leaderElector.Run开始执行抢锁选主
// C:\git\kubernetes-1.22.3\vendor\k8s.io\client-go\tools\leaderelection\leaderelection.go// Run starts the leader election loop. Run will not return// before leader election loop is stopped by ctx or it has// stopped holding the leader lease// Run 启动 leader 选举循环。// Run 函数会一直阻塞,直到:// 上下文 ctx 被取消,或者失去了 leader 锁(lease) 除此之外它永远不会返回func (le *LeaderElector) Run(ctx context.Context) {defer runtime.HandleCrash()/* 无论什么原因退出这个函数,一定会执行:宣布停止成为 leader cc.LeaderElection.Callbacks = leaderelection.LeaderCallbacks{ OnStartedLeading: func(ctx context.Context) { }, OnStoppedLeading: func() { }, } */defer func() {// 这里的OnStoppedLeading,就是前面Run函数中注册的 le.config.Callbacks.OnStoppedLeading() }()// 第一步:抢锁(阻塞直到抢到锁 或者 ctx 取消)// 如果抢锁失败(比如被人取消了),直接 returnif !le.acquire(ctx) {return }// 抢到锁了!创建一个子 context,用于停止 leader 任务 ctx, cancel := context.WithCancel(ctx)defer cancel()/* 开启协程,执行用户的业务逻辑(比如 kube-scheduler 开始调度) cc.LeaderElection.Callbacks = leaderelection.LeaderCallbacks{ OnStartedLeading: func(ctx context.Context) { }, OnStoppedLeading: func() { }, } */go le.config.Callbacks.OnStartedLeading(ctx)// 【关键】死循环:不断续租锁,保证一直是 leader// 一旦续租失败(丢锁),这个函数就会返回 le.renew(ctx)}追踪le.acquire分析抢锁
// C:\git\kubernetes-1.22.3\vendor\k8s.io\client-go\tools\leaderelection\leaderelection.go// acquire 循环调用 tryAcquireOrRenew 尝试抢锁// 一旦抢锁成功,立刻返回 true// 如果 ctx 被取消(进程停止),返回 falsefunc (le *LeaderElector) acquire(ctx context.Context) bool {// 创建一个可取消的 context,用来在抢到锁后停止循环 ctx, cancel := context.WithCancel(ctx)defer cancel()// 标记:是否成功抢到锁 succeeded := false// 锁的描述信息(如:kube-system/kube-scheduler) desc := le.config.Lock.Describe()// ====================== 核心循环 ======================// wait.JitterUntil = 定时、带随机抖动的循环执行函数// 每隔 RetryPeriod(默认2秒)执行一次// ===================================================== wait.JitterUntil(func() {// 尝试抢锁 或 续租锁(真正执行抢锁逻辑) succeeded = le.tryAcquireOrRenew(ctx)// 更新状态:是否从"从节点"变成"主节点" le.maybeReportTransition()// 如果没抢到锁 → 打印日志,继续下一轮循环if !succeeded { klog.V(4).Infof("failed to acquire lease %v", desc)return }// ============= 抢锁成功!=============// 记录事件:变成 leader le.config.Lock.RecordEvent("became leader")// 监控指标:标记成为主节点 le.metrics.leaderOn(le.config.Name)// 取消循环,停止继续抢锁 cancel() }, le.config.RetryPeriod, JitterFactor, true, ctx.Done())// 返回最终是否抢到锁return succeeded}追踪tryAcquireOrRenew,流程如下:
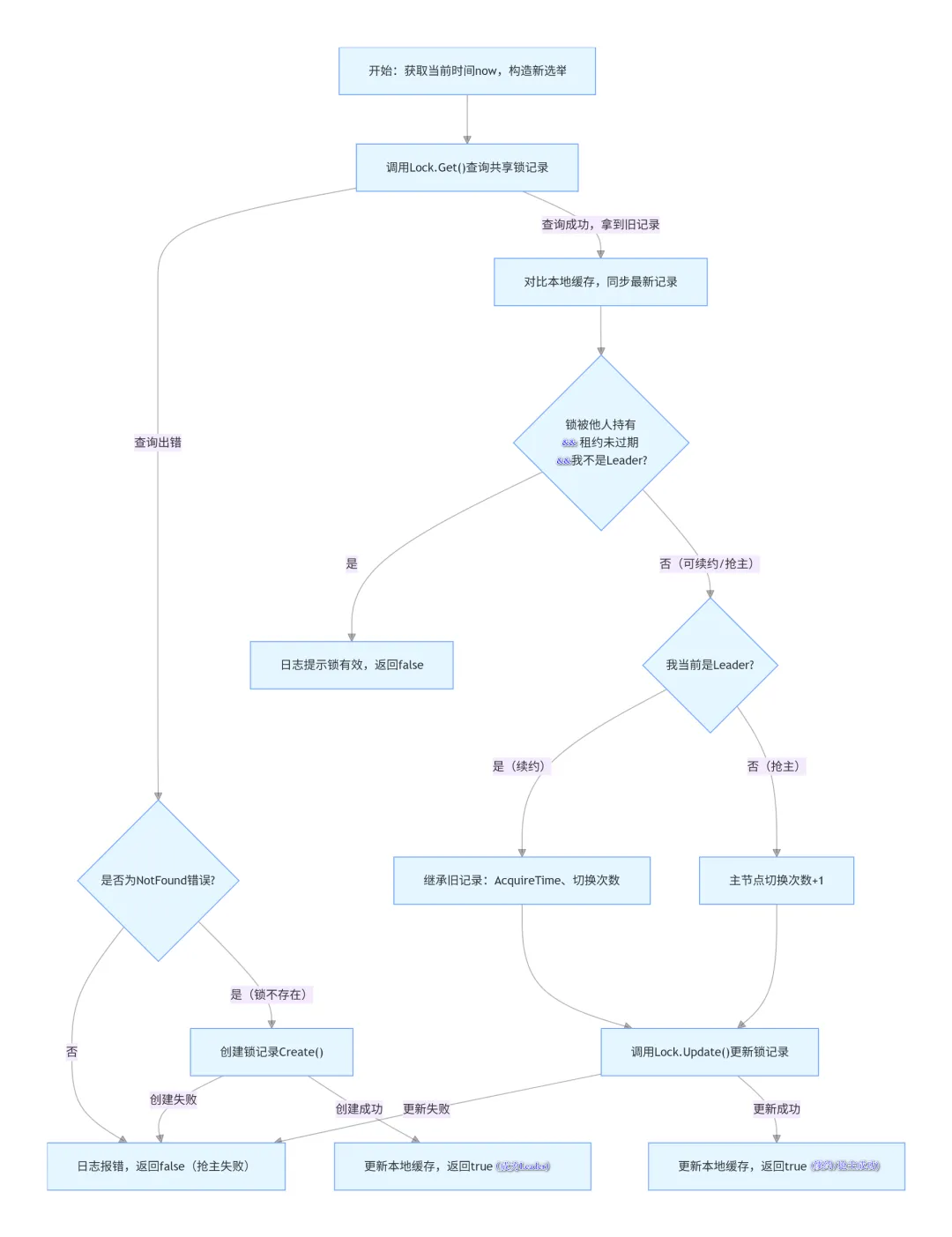
// tryAcquireOrRenew 尝试获取 Leader 租约(如果还没获得),// 或者尝试续约租约(如果已经获得)。成功返回 true,失败返回 false。func (le *LeaderElector) tryAcquireOrRenew(ctx context.Context) bool {// 获取当前时间 now := metav1.Now()// 构造一个新的 Leader 选举记录(默认值,后续会根据场景修改) leaderElectionRecord := rl.LeaderElectionRecord{ HolderIdentity: le.config.Lock.Identity(), // 当前节点的唯一标识 LeaseDurationSeconds: int(le.config.LeaseDuration / time.Second), // 租约有效期(秒) RenewTime: now, // 本次续约/获取时间 AcquireTime: now, // 首次成为 Leader 的时间 }// 步骤 1:尝试从共享存储中获取现有的锁记录// Get 从 K8s 资源(Lease/ConfigMap/Endpoint)中读取旧的选举记录 oldLeaderElectionRecord, oldLeaderElectionRawRecord, err := le.config.Lock.Get(ctx)if err != nil {// 如果获取失败,且错误不是「记录不存在」,则直接返回失败if !errors.IsNotFound(err) { klog.Errorf("error retrieving resource lock %v: %v", le.config.Lock.Describe(), err)return false }// 场景 A:锁记录不存在,第一次抢主,直接创建锁// 创建锁记录,写入当前节点信息if err = le.config.Lock.Create(ctx, leaderElectionRecord); err != nil { klog.Errorf("error initially creating leader election record: %v", err)return false }// 缓存最新记录,标记自己成为 Leader le.setObservedRecord(&leaderElectionRecord)return true }// 步骤 2:已获取到旧记录,更新本地缓存并校验合法性// 如果远程记录和本地缓存不一致,更新本地缓存(避免重复解析)if !bytes.Equal(le.observedRawRecord, oldLeaderElectionRawRecord) { le.setObservedRecord(oldLeaderElectionRecord) le.observedRawRecord = oldLeaderElectionRawRecord }// 核心判断:// 1. 锁有持有者// 2. 租约未过期(上次观察时间 + 租约时长 > 当前时间)// 3. 本节点不是 Leader// 满足全部条件 → 锁被别人持有且有效,本节点不能抢主,直接返回 falseif len(oldLeaderElectionRecord.HolderIdentity) > 0 && le.observedTime.Add(le.config.LeaseDuration).After(now.Time) && !le.IsLeader() { klog.V(4).Infof("lock is held by %v and has not yet expired", oldLeaderElectionRecord.HolderIdentity)return false }// 步骤 3:准备更新锁记录(抢主 或 续约)// 如果本节点已经是 Leader → 执行【续约】操作if le.IsLeader() {// 续约时保持:首次获取时间不变、主节点切换次数不变 leaderElectionRecord.AcquireTime = oldLeaderElectionRecord.AcquireTime leaderElectionRecord.LeaderTransitions = oldLeaderElectionRecord.LeaderTransitions } else {// 如果本节点不是 Leader → 执行【抢主】操作// 抢主成功,主节点切换次数 +1 leaderElectionRecord.LeaderTransitions = oldLeaderElectionRecord.LeaderTransitions + 1 }// 步骤 4:原子更新共享锁,完成抢主/续约// 将新记录更新到 K8s 共享存储if err = le.config.Lock.Update(ctx, leaderElectionRecord); err != nil { klog.Errorf("Failed to update lock: %v", err)return false }// 更新本地缓存的最新记录 le.setObservedRecord(&leaderElectionRecord)// 抢主/续约成功return true}当多个le.config.Lock.Update调用的时候,会有并发问题,通过resourceVersion字段可以解决这个问题。每个锁(Lease)都有一个版本号resourceVersion,只要有人更新锁,版本号就会自动加1,版本号是唯一、连续、不可重复的。每个Update只认自己拿到的那个版本号,版本号不对,就不允许更新!
[root]# kubectl get lease -n kube-systemNAME HOLDER AGEkube-controller-manager k8s-master01_def02570-9146-54c1-b700-66dd407ff612 221dkube-scheduler k8s-master01_29da2906-4a43-4db1-36f9-4bf8919b4cda 221d如上,kube‑scheduler 和 kube‑controller‑manager 均基于Lease 资源实现选主抢锁,锁资源统一创建在 kube‑system 命名空间下。其中 holder 字段标识当前锁的持有者,取值格式为节点机器名 + UUID,用于区分不同实例。
1.3、k8s Event
之前在看到kube‑scheduler的启动流程中, 提到k8s的Event那么。接下来就来研究一下Event。接下来就沿着kube‑scheduler代码,分析一下K8s事件源码。
提到k8s的Event就要祭出这张图
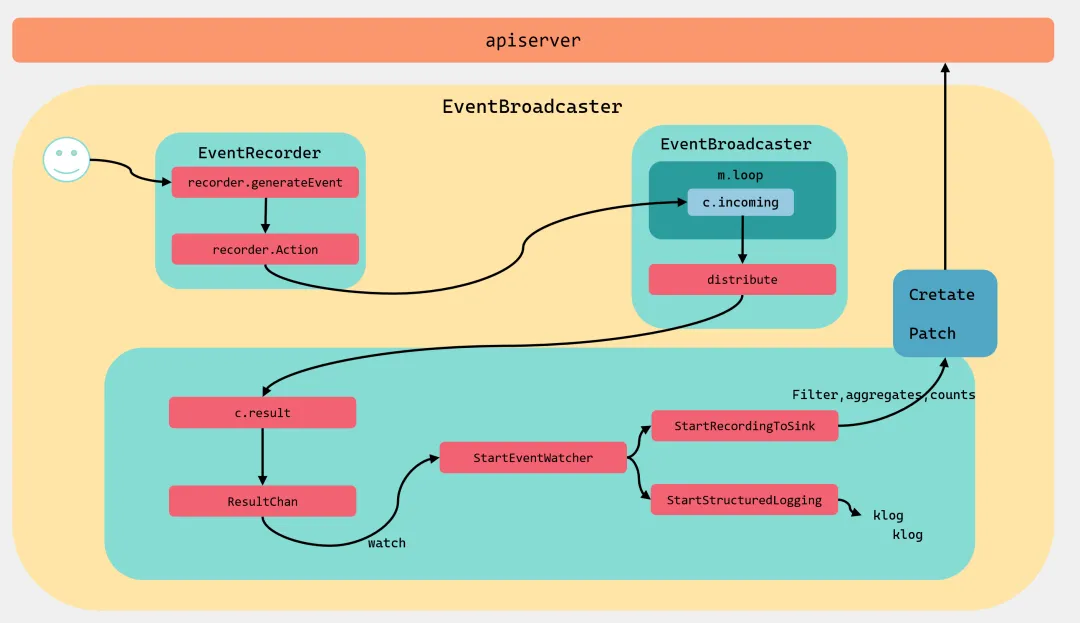
EventRecorder:是事件生成者,k8s组件通过调用它的方法来生成事件;EventBroadcaster:事件广播器,负责消费EventRecorder产生的事件,然后分发给broadcasterWatcher;broadcasterWatcher:用于定义事件的处理方式,如上报apiserver;
这张图完整展示了 Kubernetes 事件从产生、广播、聚合过滤到最终上报 APIServer 的全链路,逐环节拆解如下:
一、整体分层
上层: apiserver:事件最终存储入口中层: EventBroadcaster:事件广播核心组件左侧: EventRecorder:业务组件(调度器、控制器等)的事件生成器下方:事件消费、聚合、上报、日志落盘模块
二、逐流程环节解析
1. 事件产生(业务侧)
用户 / 组件触发业务逻辑(如 Pod调度失败)EventRecorder.generateEvent:构造events.k8s.io/v1.Event事件对象recorder.Action:将事件发送到EventBroadcaster广播器
2. 事件广播分发
EventBroadcaster.m.loop:内部循环接收流入事件(c.incoming)distribute:将事件分发给所有订阅者(事件上报、日志组件)c.result+ResultChan:通过通道将事件下发给下游消费模块
3. 下游双消费分支
3.1、分支 A:结构化日志落盘
StartStructuredLogging:将事件输出到 klog,用于本地日志记录,不上报 apiserver。
3.2、分支 B:事件聚合 + 上报 APIServer(核心链路)
StartEventWatcher:监听事件通道,接收分发后的事件StartRecordingToSink:启动两个后台协程:定时保活重复事件( refreshExistingEventSeries)定时清理过期事件( finishSeries)内部完成 Filter(过滤)、aggregates(聚合)、counts(计数),即你之前学的recordToSink聚合逻辑Create/Patch:调用recordEvent,新事件走Create、重复聚合事件走Patch,最终发送到apiserver存储。
三、核心对应源码映射
generateEventAction | recordSchedulingFailureEventf 事件生成逻辑 |
distribute | |
StartRecordingToSink | StartRecordingToSink |
Filter,aggregates,counts | recordToSink |
Create/Patch | recordEvent |
c.incoming | |
c.result |
四、关键设计亮点
异步解耦:事件生成与上报分离,通过广播 + 通道异步处理,不阻塞业务主流程; 事件聚合:相同事件只计数、不重复上报,大幅减轻 apiserver/etcd压力;双输出:同时支持 apiserver存储 + 本地klog日志,兼顾集群查询与问题排查;生命周期管理:通过定时保活、过期清理,保证事件有效性与内存稳定。
接下来开始追踪代码
1.3.1、EventBroadcaster的初始化
// C:\git\kubernetes-1.22.3\cmd\kube-scheduler\app\options\options.gofunc (o *Options) Config() (*schedulerappconfig.Config, error) { c := &schedulerappconfig.Config{}if err := o.ApplyTo(c); err != nil {return nil, err }// Prepare kube config. kubeConfig, err := createKubeConfig(c.ComponentConfig.ClientConnection, o.Master)if err != nil {return nil, err }// Prepare kube clients. client, eventClient, err := createClients(kubeConfig)if err != nil {return nil, err } c.EventBroadcaster = events.NewEventBroadcasterAdapter(eventClient)}追踪events.NewEventBroadcasterAdapter
// C:\git\kubernetes-1.22.3\vendor\k8s.io\client-go\tools\events\event_broadcaster.go// NewEventBroadcasterAdapter 创建一个事件广播器适配器// 用于简化组件从旧事件API迁移到新事件API的过程func NewEventBroadcasterAdapter(client clientset.Interface) EventBroadcasterAdapter {// 创建适配器实例 eventClient := &eventBroadcasterAdapterImpl{}/* 第一步:检测集群是否支持 【新事件API】 events.k8s.io/v1 GroupName is the group name use in this package const GroupName = "events.k8s.io" // SchemeGroupVersion is group version used to register these objects var SchemeGroupVersion = schema.GroupVersion{Group: GroupName, Version: "v1"} */if _, err := client.Discovery().ServerResourcesForGroupVersion(eventsv1.SchemeGroupVersion.String()); err == nil {// 如果支持新API → 初始化新API的客户端和广播器// 新事件API客户端 eventClient.eventsv1Client = client.EventsV1()// 新事件广播器 eventClient.eventsv1Broadcaster = NewBroadcaster(&EventSinkImpl{Interface: eventClient.eventsv1Client}) }// 第二步:无条件创建 【旧事件API】 core/v1.Event// 虽然新API慢慢普及,但旧的开销很小,所以统一都创建 eventClient.coreClient = client.CoreV1() // 旧API客户端 eventClient.coreBroadcaster = record.NewBroadcaster() // 旧事件广播器// 返回适配器(上层组件用它发事件,不用管新旧版本)return eventClient}两个NewBroadcaster的底层实现都是eventBroadcasterImpl
// C:\git\kubernetes-1.22.3\vendor\k8s.io\client-go\tools\record\event.go// Creates a new event broadcaster.func NewBroadcaster() EventBroadcaster {return &eventBroadcasterImpl{ Broadcaster: watch.NewLongQueueBroadcaster(maxQueuedEvents, watch.DropIfChannelFull), sleepDuration: defaultSleepDuration, }}type eventBroadcasterImpl struct { *watch.Broadcaster sleepDuration time.Duration options CorrelatorOptions}// C:\git\kubernetes-1.22.3\vendor\k8s.io\client-go\tools\events\event_broadcaster.go// NewBroadcaster Creates a new event broadcaster.func NewBroadcaster(sink EventSink) EventBroadcaster {return newBroadcaster(sink, defaultSleepDuration, map[eventKey]*eventsv1.Event{})}// NewBroadcasterForTest Creates a new event broadcaster for test purposes.func newBroadcaster(sink EventSink, sleepDuration time.Duration, eventCache map[eventKey]*eventsv1.Event) EventBroadcaster {return &eventBroadcasterImpl{ Broadcaster: watch.NewBroadcaster(maxQueuedEvents, watch.DropIfChannelFull), eventCache: eventCache, sleepDuration: sleepDuration, sink: sink, }}type eventBroadcasterImpl struct { *watch.Broadcaster mu sync.Mutex eventCache map[eventKey]*eventsv1.Event sleepDuration time.Duration sink EventSink}1.3.2、eventRecorder初始化
// C:\git\kubernetes-1.22.3\cmd\kube-scheduler\app\server.go// Setup creates a completed config and a scheduler based on the command args and optionsfunc Setup(ctx context.Context, opts *options.Options, outOfTreeRegistryOptions ...Option) (*schedulerserverconfig.CompletedConfig, *scheduler.Scheduler, error) {if errs := opts.Validate(); len(errs) > 0 {return nil, nil, utilerrors.NewAggregate(errs) } c, err := opts.Config()if err != nil {return nil, nil, err }// Get the completed config cc := c.Complete() outOfTreeRegistry := make(runtime.Registry)for _, option := range outOfTreeRegistryOptions {if err := option(outOfTreeRegistry); err != nil {return nil, nil, err } }// recorderFactory代表生成eventRecorder的工厂函数 recorderFactory := getRecorderFactory(&cc)}追踪getRecorderFactory
// C:\git\kubernetes-1.22.3\cmd\kube-scheduler\app\server.gofunc getRecorderFactory(cc *schedulerserverconfig.CompletedConfig) profile.RecorderFactory {return func(name string) events.EventRecorder {return cc.EventBroadcaster.NewRecorder(name) }}追踪NewRecorder
// C:\git\kubernetes-1.22.3\vendor\k8s.io\client-go\tools\events\event_broadcaster.go// NewRecorder returns an EventRecorder that records events with the given event source.func (e *eventBroadcasterImpl) NewRecorder(scheme *runtime.Scheme, reportingController string) EventRecorder { hostname, _ := os.Hostname() reportingInstance := reportingController + "-" + hostnamereturn &recorderImpl{scheme, reportingController, reportingInstance, e.Broadcaster, clock.RealClock{}}}1.3.3、开启event事件广播器
// C:\git\kubernetes-1.22.3\vendor\k8s.io\client-go\tools\events\event_broadcaster.go// Run executes the scheduler based on the given configuration. It only returns on error or when context is done.func Run(ctx context.Context, cc *schedulerserverconfig.CompletedConfig, sched *scheduler.Scheduler)error {if cz, err := configz.New("componentconfig"); err == nil { cz.Set(cc.ComponentConfig) } else {return fmt.Errorf("unable to register configz: %s", err) }// 开启`event`事件广播器 cc.EventBroadcaster.StartRecordingToSink(ctx.Done())}追踪StartRecordingToSink
// C:\git\kubernetes-1.22.3\vendor\k8s.io\client-go\tools\events\event_broadcaster.go// StartRecordingToSink starts sending events received from the specified eventBroadcaster to the given sink.func (e *eventBroadcasterImpl) StartRecordingToSink(stopCh <-chan struct{}) {go wait.Until(e.refreshExistingEventSeries, refreshTime, stopCh)go wait.Until(e.finishSeries, finishTime, stopCh) e.startRecordingEvents(stopCh)}追踪refreshExistingEventSeries,它的作用是给重复事件续期,让它一直显示在 kubectl describe 里
// C:\git\kubernetes-1.22.3\vendor\k8s.io\client-go\tools\events\event_broadcaster.go// refreshExistingEventSeries 刷新事件系列的TTL,给事件“续期”func (e *eventBroadcasterImpl) refreshExistingEventSeries() {// 加锁,保证并发安全(操作eventCache) e.mu.Lock()defer e.mu.Unlock()// 遍历所有缓存的事件for isomorphicKey, event := range e.eventCache {// 只处理【有系列信息】的重复事件(重复发生的同类型事件)if event.Series != nil {// 发送事件到 APIServer(更新计数、刷新最后观察时间)if recordedEvent, retry := recordEvent(e.sink, event); !retry {// 更新成功,把最新的事件存回缓存if recordedEvent != nil { e.eventCache[isomorphicKey] = recordedEvent } } } }}追踪finishSeries,它的作用是事件太久没发生,那么清理掉释放内存
// C:\git\kubernetes-1.22.3\vendor\k8s.io\client-go\tools\events\event_broadcaster.go// finishSeries 检查事件是否已经长期不发生// 1. 有系列的事件:写入最终计数后删除// 2. 普通事件:直接删除func (e *eventBroadcasterImpl) finishSeries() {// 加锁保护缓存 e.mu.Lock()defer e.mu.Unlock()// 遍历缓存中的所有事件for isomorphicKey, event := range e.eventCache { eventSerie := event.Seriesif eventSerie != nil {// 如果【系列事件】最后一次发生已经超过了 finishTimeif eventSerie.LastObservedTime.Time.Before(time.Now().Add(-finishTime)) {// 最后上报一次最终状态(总发生次数)if _, retry := recordEvent(e.sink, event); !retry {// 上报成功 → 从缓存删除delete(e.eventCache, isomorphicKey) } } } else {// 如果是【普通单件事件】,且已过期if event.EventTime.Time.Before(time.Now().Add(-finishTime)) {// 直接从缓存删除delete(e.eventCache, isomorphicKey) } } }}其中EventSeries是用来事件聚合使用的
// C:\git\kubernetes-1.22.3\vendor\k8s.io\api\events\v1\types.gotype Event struct {// series is data about the Event series this event represents or nil if it's a singleton Event.// +optional/* 作用:事件聚合(系列)信息 存放重复事件的:计数、最后观察时间 比如 “镜像拉取失败” 发生 100 次,只存一条事件,用 Series 记录次数。 */ Series *EventSeries `json:"series,omitempty" protobuf:"bytes,3,opt,name=series"`}type EventSeries struct {// count is the number of occurrences in this series up to the last heartbeat time. Count int32 `json:"count" protobuf:"varint,1,opt,name=count"`// lastObservedTime is the time when last Event from the series was seen before last heartbeat. LastObservedTime metav1.MicroTime `json:"lastObservedTime" protobuf:"bytes,2,opt,name=lastObservedTime"`}继续追踪startRecordingEvents
// C:\git\kubernetes-1.22.3\vendor\k8s.io\client-go\tools\events\event_broadcaster.gofunc (e *eventBroadcasterImpl) startRecordingEvents(stopCh <-chan struct{}) { eventHandler := func(obj runtime.Object) { event, ok := obj.(*eventsv1.Event)if !ok { klog.Errorf("unexpected type, expected eventsv1.Event")return } e.recordToSink(event, clock.RealClock{}) } stopWatcher := e.StartEventWatcher(eventHandler)go func() { <-stopCh stopWatcher() }()}其中需要关注两个函数StartEventWatcher和recordToSink,先追踪StartEventWatcher
// C:\git\kubernetes-1.22.3\vendor\k8s.io\client-go\tools\events\event_broadcaster.go// StartEventWatcher starts sending events received from this EventBroadcaster to the given event handler function.// The return value is used to stop recordingfunc (e *eventBroadcasterImpl) StartEventWatcher(eventHandler func(event runtime.Object)) func() { watcher := e.Watch()go func() {defer utilruntime.HandleCrash()for { watchEvent, ok := <-watcher.ResultChan()if !ok {return } eventHandler(watchEvent.Object) } }()return watcher.Stop}也就是说从broadcasterWatcher.result这个事件的Eventchan中读取Event,然后调用eventHandler处理事件,内部也就是调用recordToSink处理事件
// C:\git\kubernetes-1.22.3\vendor\k8s.io\apimachinery\pkg\watch\mux.go// Watch adds a new watcher to the list and returns an Interface for it.// Note: new watchers will only receive new events. They won't get an entire history// of previous events. It will block until the watcher is actually added to the// broadcaster.func (m *Broadcaster) Watch() Interface {var w *broadcasterWatcher m.blockQueue(func() { id := m.nextWatcher m.nextWatcher++ w = &broadcasterWatcher{ result: make(chan Event, m.watchQueueLength), stopped: make(chan struct{}), id: id, m: m, } m.watchers[id] = w })if w == nil {// The panic here is to be consistent with the previous interface behavior// we are willing to re-evaluate in the future.panic("broadcaster already stopped") }return w}追踪recordToSink
// C:\git\kubernetes-1.22.3\vendor\k8s.io\client-go\tools\events\event_broadcaster.go// recordToSink 事件聚合 + 上报入口// 核心作用:相同事件合并计数,不同事件才发送到 APIServerfunc (e *eventBroadcasterImpl) recordToSink(event *eventsv1.Event, clock clock.Clock) {// 深拷贝事件,防止多协程并发修改(安全) eventCopy := event.DeepCopy()// 启动协程异步处理,不阻塞主线程go func() {// 第一步:加锁检查缓存,做【事件聚合】 evToRecord := func() *eventsv1.Event { e.mu.Lock()defer e.mu.Unlock()// 生成事件唯一 Key(相同事件会生成同一个key) eventKey := getKey(eventCopy)// 从缓存中查找是否已经存在【相同事件】 isomorphicEvent, isIsomorphic := e.eventCache[eventKey]if isIsomorphic {// 【情况1】缓存里已有相同事件,那么聚合,只更新计数和时间if isomorphicEvent.Series != nil {// 已有系列信息,那么次数+1,更新最后时间 isomorphicEvent.Series.Count++ isomorphicEvent.Series.LastObservedTime = metav1.MicroTime{Time: clock.Now()}// 返回 nil,那么代表【只聚合,不上报】return nil }// 第一次聚合:给事件加上 Series 信息 isomorphicEvent.Series = &eventsv1.EventSeries{ Count: 1, LastObservedTime: metav1.MicroTime{Time: clock.Now()}, }// 返回事件,那么代表【需要上报】return isomorphicEvent }// 【情况2】缓存里没有,那么新事件,加入缓存 e.eventCache[eventKey] = eventCopy// 返回事件,那么代表【需要上报】return eventCopy }()// 第二步:如果需要上报(不是纯聚合),就发送到 APIServerif evToRecord != nil {// 真正执行上报(调用 recordEvent → Patch/Create) recordedEvent := e.attemptRecording(evToRecord)// 上报成功,用 APIServer 返回的最新事件更新缓存if recordedEvent != nil { recordedEventKey := getKey(recordedEvent) e.mu.Lock()defer e.mu.Unlock() e.eventCache[recordedEventKey] = recordedEvent } } }()}追踪getKey
// C:\git\kubernetes-1.22.3\vendor\k8s.io\client-go\tools\events\event_broadcaster.gofunc getKey(event *eventsv1.Event) eventKey { key := eventKey{ action: event.Action, reason: event.Reason, reportingController: event.ReportingController, regarding: event.Regarding, }if event.Related != nil { key.related = *event.Related }return key}type eventKey struct { action string reason string reportingController string regarding corev1.ObjectReference related corev1.ObjectReference}其中各个字段含义如下
Action | string | ||
Reason | string | ||
ReportingController | string | ||
Regarding | corev1.ObjectReference | Pod/Node 等),确保只聚合同一资源的事件 | |
Related | corev1.ObjectReference |
继续追踪attemptRecording
// C:\git\kubernetes-1.22.3\vendor\k8s.io\client-go\tools\events\event_broadcaster.gofunc (e *eventBroadcasterImpl) attemptRecording(event *eventsv1.Event) *eventsv1.Event { tries := 0for {if recordedEvent, retry := recordEvent(e.sink, event); !retry {return recordedEvent } tries++if tries >= maxTriesPerEvent { klog.Errorf("Unable to write event '%#v' (retry limit exceeded!)", event)return nil }// Randomize sleep so that various clients won't all be// synced up if the master goes down. time.Sleep(wait.Jitter(e.sleepDuration, 0.25)) }}继续追踪recordEvent,调用的就是EventSink.Patch
// C:\git\kubernetes-1.22.3\vendor\k8s.io\client-go\tools\events\event_broadcaster.gofunc recordEvent(sink EventSink, event *eventsv1.Event) (*eventsv1.Event, bool) {if isEventSeries { newEvent, err = sink.Patch(event, patch) }}// EventSink knows how to store events (client-go implements it.)// EventSink must respect the namespace that will be embedded in 'event'.// It is assumed that EventSink will return the same sorts of errors as// client-go's REST client.type EventSink interface { Create(event *eventsv1.Event) (*eventsv1.Event, error) Update(event *eventsv1.Event) (*eventsv1.Event, error) Patch(oldEvent *eventsv1.Event, data []byte) (*eventsv1.Event, error)}1.3.4、调用 eventRecorder产生的事件
// recordSchedulingFailure 记录 Pod 调度失败事件// 作用:Pod 调度失败 → 发送事件、更新 Pod 状态、设置 nominatedNode(候选节点)func (sched *Scheduler) recordSchedulingFailure( fwk framework.Framework, podInfo *framework.QueuedPodInfo, err error, reason string, nominatedNode string,) {// 1. 把调度错误记录到调度器内部日志(错误计数、监控指标) sched.Error(podInfo, err)// 2. 设置 nominatedNode(推荐下次优先尝试调度的节点)// 把 Pod 标记为“推荐在某个节点重试调度”,避免并发竞争if sched.SchedulingQueue != nil { sched.SchedulingQueue.AddNominatedPod(podInfo.PodInfo, nominatedNode) } pod := podInfo.Pod// 截断错误信息,避免太长 msg := truncateMessage(err.Error())// 3. 发送【调度失败】事件到 Kubernetes Event 系统// Type: Warning// Reason: FailedScheduling// 消息:为什么调度失败(如:节点资源不足、节点亲和性不匹配) fwk.EventRecorder().Eventf( pod,nil, v1.EventTypeWarning,"FailedScheduling","Scheduling", msg, )// 4. 更新 Pod 状态:// 设置 Pod 条件 PodScheduled = False// 标记调度失败原因 + 消息if err := updatePod( sched.client, pod, &v1.PodCondition{ Type: v1.PodScheduled, Status: v1.ConditionFalse, Reason: reason, Message: err.Error(), }, nominatedNode, // 同时写入推荐节点 ); err != nil { klog.ErrorS(err, "Error updating pod", "pod", klog.KObj(pod)) }}其中EventRecorder就是一个初始化之后的eventRecorder
// C:\git\kubernetes-1.22.3\vendor\k8s.io\client-go\tools\events\interfaces.go// EventRecorder returns an event recorder.func (f *frameworkImpl) EventRecorder() events.EventRecorder {return f.eventRecorder}1.4、k8s的informer机制
在开始研究 kube-scheduler内对pod的调度机制之前,需要研究informer的原理作为铺垫。
说到informer就必须要祭出这张图
1.4.1、Informer 机制核心作用
保证消息实时性、可靠性、顺序性
不依赖中间件,通过
ListWatch长连接监听资源变更。大幅降低
APIServer / Etcd压力使用本地缓存
Indexer,避免组件频繁直接请求集群。统一资源监听能力
让
K8s组件、自定义控制器、Operator快速获取资源实时状态。
1.4.2、Informer 核心组件
Reflector | APIServer 建立长连接,通过 ListWatch 监听资源变化 |
DeltaFIFO | Added/Updated/Deleted) |
Informer | |
Indexer | 本地缓存APIServer |
1.4.3、Informer 完整工作流程
Reflector监听APIServer资源变化变更事件写入 DeltaFIFOInformer消费队列,更新Indexer本地缓存Informer抛出事件回调标准生产流程:事件 → Key→WorkQueue→ 从Indexer取最新对象 → 执行业务
1.4.4、Indexer 本地缓存
Indexer 是Informer 内置的线程安全本地存储,作用:
存储资源最新完整对象 支持按 Key/ 标签索引查询纯本地读取,零 APIServer压力与集群状态保持最终一致
Indexer 常用操作
// 按 key 查询对象obj, exists, err := indexer.GetByKey(key)// 列出所有缓存对象list := indexer.List()// 按索引查询objs, err := indexer.ByIndex("indexKey", "indexValue")1.4.5、生产级标准流程:事件 → Key → 队列 → 取最新对象 → 处理
这是 K8s 官方推荐的控制器标准模型,解决:
事件阻塞 重复处理 高并发削峰 失败自动重试 永远使用最新状态
流程说明
事件:资源新增 / 更新 / 删除触发回调 Key:将对象转为唯一标识(namespace/name或自定义)队列: Key入队,解耦事件与业务取最新对象:从 Indexer本地缓存获取最新状态处理:执行业务调谐逻辑( Reconcile)
1.4.6、标准流程Demo
package mainimport ("context""flag""fmt""log""path/filepath""time"// K8s 原生资源定义 v1 "k8s.io/api/core/v1" metav1 "k8s.io/apimachinery/pkg/apis/meta/v1"// 工具包:循环等待"k8s.io/apimachinery/pkg/util/wait"// client-go 核心:Informer、缓存、事件处理"k8s.io/client-go/informers""k8s.io/client-go/kubernetes""k8s.io/client-go/tools/cache""k8s.io/client-go/tools/clientcmd"// 读取用户家目录"k8s.io/client-go/util/homedir"// client-go 队列实现(限速队列、重试队列)"k8s.io/client-go/util/workqueue")// ===================== 控制器结构体定义 =====================// Controller 自定义控制器,整合四大核心组件:// 1. clientset: 与 K8s APIServer 交互的客户端// 2. informer: 资源监听器,内部包含 Indexer 本地缓存// 3. queue: 工作队列,实现事件解耦、去重、重试、削峰type Controller struct { clientset *kubernetes.Clientset // K8s 客户端 informer cache.SharedIndexInformer // 共享Informer,内置Indexer缓存 queue workqueue.RateLimitingInterface // 限速工作队列}// ===================== 创建控制器 =====================// NewController 初始化控制器、队列、Informer、事件处理器func NewController(clientset *kubernetes.Clientset) *Controller {// 1. 创建【限速工作队列】// DefaultControllerRateLimiter:K8s标准限速器,失败后递增重试间隔,避免风暴 queue := workqueue.NewRateLimitingQueue(workqueue.DefaultControllerRateLimiter())// 2. 创建 SharedInformerFactory 工厂// 第二个参数 resync 周期:1分钟全量同步一次集群资源,防止事件丢失、数据不一致 factory := informers.NewSharedInformerFactory(clientset, 1*time.Minute)// 3. 获取 Pod 资源对应的 Informer// Core().V1().Pods() 代表监听 v1 版本的 Pod 资源 podInformer := factory.Core().V1().Pods().Informer()// 4. 注册【资源事件处理器】ResourceEventHandlers// 核心设计:事件回调里**只做一件事**:对象转Key → 放入队列,不执行业务逻辑 podInformer.AddEventHandler(cache.ResourceEventHandlerFuncs{// AddFunc:监听到资源新建时触发 AddFunc: func(obj interface{}) {// MetaNamespaceKeyFunc:固定格式生成资源唯一Key:namespace/name key, err := cache.MetaNamespaceKeyFunc(obj)if err == nil { log.Println("新增事件,入队 KEY:", key) queue.Add(key) // Key 加入队列 } },// UpdateFunc:监听到资源更新时触发(状态、标签、配置变更都会触发) UpdateFunc: func(oldObj, newObj interface{}) { key, err := cache.MetaNamespaceKeyFunc(newObj)if err == nil { log.Println("更新事件,入队 KEY:", key) queue.Add(key) // Key 加入队列 } },// DeleteFunc:监听到资源删除时触发 DeleteFunc: func(obj interface{}) {// DeletionHandlingMetaNamespaceKeyFunc:兼容已删除的对象,安全生成Key key, err := cache.DeletionHandlingMetaNamespaceKeyFunc(obj)if err == nil { log.Println("删除事件,入队 KEY:", key) queue.Add(key) // Key 加入队列 } }, })// 组装并返回控制器实例return &Controller{ clientset: clientset, informer: podInformer, queue: queue, }}// ===================== 启动控制器 =====================// Run 启动Informer、同步缓存、启动队列消费协程func (c *Controller) Run(ctx context.Context) {// 程序退出时关闭队列,释放资源defer c.queue.ShutDown()// 1. 启动 Informer// Informer 内部会启动 Reflector,建立 ListWatch 长连接监听 APIServergo c.informer.Run(ctx.Done())// 2. 等待本地缓存(Indexer)全量同步完成// 作用:确保启动时集群现有资源全部加载到本地缓存,再开始处理业务if !cache.WaitForCacheSync(ctx.Done(), c.informer.HasSynced) { log.Fatal("缓存同步失败,程序退出") } log.Println("缓存同步完成,Indexer 本地缓存已就绪")// 3. 启动 Worker 循环:持续消费队列// wait.Until:每隔1秒执行一次 runWorker,ctx 取消则停止go wait.Until(c.runWorker, time.Second, ctx.Done())// 阻塞主线程,等待退出信号 <-ctx.Done() log.Println("收到退出信号,控制器停止运行")}// ===================== 队列消费主循环 =====================// runWorker 死循环:不断从队列取出任务并处理func (c *Controller) runWorker() {// processNextWorkItem 返回 true 则继续循环,false 退出for c.processNextWorkItem() { }}// ===================== 处理单个队列任务 =====================// processNextWorkItem:从队列取Key → 调用业务逻辑 → 处理重试/成功标记// 对应流程:ProcessItem 从队列取 Keyfunc (c *Controller) processNextWorkItem() bool {// 从队列获取 Key// quit=true 代表队列已关闭,终止循环 key, quit := c.queue.Get()if quit {return false }// defer 标记任务完成:无论成功失败,都标记当前Key处理完毕defer c.queue.Done(key)// 调用核心调谐逻辑:根据Key执行业务 err := c.syncHandler(key.(string))if err == nil {// 处理成功:清除该Key的重试记录 c.queue.Forget(key)return true }// 处理失败:使用限速策略重新入队,自动重试 c.queue.AddRateLimited(key) log.Printf("处理失败,KEY: %s,错误: %v", key, err)return true}// ===================== 核心业务逻辑(调谐逻辑) =====================// syncHandler:根据Key从 Indexer 读取最新对象 + 执行业务// 对应流程:根据Key从Indexer取最新对象 → HandleObject 业务处理func (c *Controller) syncHandler(key string) error {// --------------------------// Indexer 本地缓存使用(重点)// GetIndexer() 获取 Informer 内置的本地索引缓存// GetByKey(key):根据 namespace/name 读取对象,**纯本地查询,不请求APIServer**// -------------------------- obj, exists, err := c.informer.GetIndexer().GetByKey(key)if err != nil {return err }// exists=false:缓存中找不到该对象,说明资源已被删除,直接返回if !exists { log.Printf("缓存中已无该对象:%s", key)return nil }// 类型断言:转为 Pod 对象 pod, ok := obj.(*v1.Pod)if !ok {return fmt.Errorf("对象类型错误,非Pod资源") }// ===================== 自定义业务逻辑区域 ===================== log.Printf("========================================") log.Printf("【开始处理Pod】命名空间: %s 名称: %s", pod.Namespace, pod.Name) log.Printf("Pod当前状态: %s", pod.Status.Phase) log.Printf("Pod创建时间: %s", pod.CreationTimestamp.Format(time.RFC3339)) log.Printf("========================================")// 演示 Indexer 批量查询:列出本地缓存中所有 Pod(依旧本地读取) allPods := c.informer.GetIndexer().List() log.Printf("Indexer本地缓存中Pod总数:%d\n", len(allPods))return nil}// ===================== 程序入口 =====================func main() {// 1. 解析命令行参数,读取 kubeconfig 配置文件var kubeconfig *string// 自动适配 Linux/Windows,读取 ~/.kube/configif home := homedir.HomeDir(); home != "" { kubeconfig = flag.String("kubeconfig", filepath.Join(home, ".kube", "config"), "K8s kubeconfig 文件路径") } flag.Parse()// 2. 加载 kubeconfig,生成客户端配置 config, err := clientcmd.BuildConfigFromFlags("", *kubeconfig)if err != nil { log.Fatalf("加载kubeconfig失败: %v", err) }// 3. 创建 K8s 客户端 clientset clientset, err := kubernetes.NewForConfig(config)if err != nil { log.Fatalf("创建clientset客户端失败: %v", err) }// 4. 初始化控制器 controller := NewController(clientset)// 5. 上下文:用于优雅退出(接收终止信号) ctx, cancel := context.WithCancel(context.Background())defer cancel() log.Println("自定义控制器启动成功,开始监听Pod资源变化...")// 6. 启动控制器 controller.Run(ctx)}1.4.7、ByIndex的Demo
从本地Indexer支持创建索引和按索引查询,有如下demo
package mainimport ("context""flag""fmt""log""path/filepath""time" v1 "k8s.io/api/core/v1""k8s.io/client-go/informers""k8s.io/client-go/kubernetes""k8s.io/client-go/tools/cache""k8s.io/client-go/tools/clientcmd""k8s.io/client-go/util/homedir")// ==========================// 索引函数:按标签 app 建立索引// ==========================func podAppIndexFunc(obj interface{}) ([]string, error) { pod, ok := obj.(*v1.Pod)if !ok {return nil, fmt.Errorf("not pod") }return []string{pod.Labels["app"]}, nil}func main() {// 加载 kubeconfigvar kubeconfig *stringif home := homedir.HomeDir(); home != "" { kubeconfig = flag.String("kubeconfig", filepath.Join(home, ".kube", "config"), "") } flag.Parse()// 创建k8s客户端 config, _ := clientcmd.BuildConfigFromFlags("", *kubeconfig) clientset, _ := kubernetes.NewForConfig(config)// 创建 informer factory := informers.NewSharedInformerFactory(clientset, time.Minute) podInformer := factory.Core().V1().Pods().Informer()// ==========================// 1. 添加索引// ========================== _ = podInformer.AddIndexers(cache.Indexers{"app": podAppIndexFunc, })// 启动 informer 同步缓存 ctx := context.Background()go podInformer.Run(ctx.Done()) cache.WaitForCacheSync(ctx.Done(), podInformer.HasSynced) log.Println("✅ 缓存同步完成,每3秒执行一次 ByIndex 查询")// ==========================// 2. 【核心】只演示 ByIndex// ==========================for {// 从本地 Indexer 按索引查询 app=nginx pods, _ := podInformer.GetIndexer().ByIndex("app", "nginx") log.Printf("===== ByIndex(app=nginx) 找到 %d 个 Pod =====", len(pods))for _, obj := range pods { pod := obj.(*v1.Pod) log.Printf("→ %s/%s\n", pod.Namespace, pod.Name) } time.Sleep(3 * time.Second) }}1.5、在kube-scheduler中的informer源码解读
InformerFactory的初始化如下
// C:\git\kubernetes-1.22.3\cmd\kube-scheduler\app\options\options.go// Config return a scheduler config objectfunc (o *Options) Config() (*schedulerappconfig.Config, error) { c := &schedulerappconfig.Config{} c.InformerFactory = scheduler.NewInformerFactory(client, 0)return c, nil}追踪scheduler.NewInformerFactory(client, 0),其中传入的resync=0,代表不进行周期性的list,而是通过第一次的全量list,加上后续的增量更新。
// C:\git\kubernetes-1.22.3\pkg\scheduler\scheduler.go// NewInformerFactory creates a SharedInformerFactory and initializes a scheduler specific// in-place podInformer.func NewInformerFactory(cs clientset.Interface, resyncPeriod time.Duration) informers.SharedInformerFactory { informerFactory := informers.NewSharedInformerFactory(cs, resyncPeriod) informerFactory.InformerFor(&v1.Pod{}, newPodInformer)return informerFactory}追踪informers.NewSharedInformerFactory,可以看到informers: make(map[reflect.Type]cache.SharedIndexInformer),这个就是各个类型到对应的Informer的映射
// C:\git\kubernetes-1.22.3\vendor\k8s.io\client-go\informers\factory.go// NewSharedInformerFactoryWithOptions constructs a new instance of a SharedInformerFactory with additional options.func NewSharedInformerFactoryWithOptions(client kubernetes.Interface, defaultResync time.Duration, options ...SharedInformerOption) SharedInformerFactory { factory := &sharedInformerFactory{ client: client, namespace: v1.NamespaceAll, defaultResync: defaultResync,/* 可以想想成为 informers = { 类型(v1.Pod): Pod 专用的 SharedInformer(唯一), 类型(v1.Node): Node 专用的 SharedInformer(唯一), 类型(appsv1.Deployment): Deployment 专用的 SharedInformer(唯一), } */ informers: make(map[reflect.Type]cache.SharedIndexInformer), startedInformers: make(map[reflect.Type]bool), customResync: make(map[reflect.Type]time.Duration), }// Apply all optionsfor _, opt := range options { factory = opt(factory) }return factory}1.5.1、pod-informer初始化
// C:\git\kubernetes-1.22.3\pkg\scheduler\scheduler.go// NewInformerFactory creates a SharedInformerFactory and initializes a scheduler specific// in-place podInformer.func NewInformerFactory( cs clientset.Interface, resyncPeriod time.Duration,) informers.SharedInformerFactory {// 1. 创建系统默认的共享 Informer 工厂 informerFactory := informers.NewSharedInformerFactory(cs, resyncPeriod)// 2. 重点:替换/注册 Pod 的 Informer,使用我们自定义的 newPodInformer informerFactory.InformerFor(&v1.Pod{}, newPodInformer)return informerFactory}func newPodInformer( cs clientset.Interface, resyncPeriod time.Duration,) cache.SharedIndexInformer {/* 只监听不是成功、不是失败的Pod,也就是只监听: Pending,Running,Unknown 已经跑完的、退出的 Pod 不监听、不缓存、不占内存! */ selector := fmt.Sprintf("status.phase!=%v,status.phase!=%v", v1.PodSucceeded, v1.PodFailed, )// 把过滤条件设置到 FieldSelector tweakListOptions := func(options *metav1.ListOptions) { options.FieldSelector = selector }// 创建【带过滤条件的】Pod Informerreturn coreinformers.NewFilteredPodInformer( cs, metav1.NamespaceAll, resyncPeriod,nil, tweakListOptions, // 过滤器 )}追踪informerFactory.InformerFor(&v1.Pod{}, newPodInformer)
// C:\git\kubernetes-1.22.3\vendor\k8s.io\client-go\informers\factory.go// InformerFor 方法的作用:// 为指定的 K8s 资源(Pod/Deployment/Node 等)创建【唯一的一个】SharedIndexInformer// 如果已经创建过,就直接返回旧的,不再创建新的 → 实现共享、节约内存func (f *sharedInformerFactory) InformerFor( obj runtime.Object, // 要监听的资源,例如 &v1.Pod{} newFunc internalinterfaces.NewInformerFunc, // 创建 informer 的函数) cache.SharedIndexInformer {// 加锁:保证多协程并发调用时,不会同时创建同一个资源的 informer f.lock.Lock()defer f.lock.Unlock()// 拿到资源的反射类型,比如 Pod 类型、Deployment 类型// 这个类型会作为 map 的 key informerType := reflect.TypeOf(obj)// 从 map 中查看:这个类型的 informer 已经创建过了吗? informer, exists := f.informers[informerType]// 如果已经创建过 → 直接返回,不再创建!// 这就是共享的核心:一个资源只创建一个 informerif exists {return informer }// 获取 resync 同步周期// 如果有自定义周期用自定义,没有就用默认的 defaultResync resyncPeriod, exists := f.customResync[informerType]if !exists { resyncPeriod = f.defaultResync }// 调用 newFunc 函数,创建一个新的 informer informer = newFunc(f.client, resyncPeriod)// 把创建好的 informer 存进 map// 下次有人需要,直接从 map 取 f.informers[informerType] = informer// 返回创建好的 informerreturn informer}继续追踪coreinformers.NewFilteredPodInformer
// NewFilteredPodInformer 作用:// 创建一个【带过滤功能】的 Pod 专用 SharedIndexInformer// 官方建议:一定要用共享的 informer,不要自己独立创建// 好处:节约内存、减少对 APIServer 的连接数func NewFilteredPodInformer( client kubernetes.Interface, // k8s 客户端 namespace string, // 监听的命名空间(all 表示所有) resyncPeriod time.Duration, // 全量同步周期 indexers cache.Indexers, // 索引配置(比如按标签索引) tweakListOptions internalinterfaces.TweakListOptionsFunc, // 过滤条件) cache.SharedIndexInformer {// 创建并返回一个 共享的 SharedIndexInformerreturn cache.NewSharedIndexInformer(// --------------------------// 第1部分:配置 ListWatch// 这是 informer 监听 APIServer 的核心// -------------------------- &cache.ListWatch{// ListFunc:全量拉取数据时调用// 程序启动时会调用一次 ListFunc: func(options metav1.ListOptions) (runtime.Object, error) {// 如果有过滤条件(比如只看 Running 的 Pod),先设置过滤if tweakListOptions != nil { tweakListOptions(&options) }// 调用 APIServer 获取 Pod 列表return client.CoreV1().Pods(namespace).List(context.TODO(), options) },// WatchFunc:监听变化(创建/更新/删除)// 建立长连接,实时接收事件 WatchFunc: func(options metav1.ListOptions) (watch.Interface, error) {// 同样可以设置过滤条件if tweakListOptions != nil { tweakListOptions(&options) }// 调用 APIServer Watch 接口return client.CoreV1().Pods(namespace).Watch(context.TODO(), options) }, },// 第2部分:告诉 informer 要监听的资源类型是 Pod &corev1.Pod{},// 第3部分:同步周期 + 索引配置 resyncPeriod, indexers, )}尽管coreinformers.NewFilteredPodInformer中入参的indexers cache.Indexers是nil
coreinformers.NewFilteredPodInformer( cs, metav1.NamespaceAll, resyncPeriod, nil, tweakListOptions, // 过滤器 )但是还是要研究一下Indexers。
// C:\git\kubernetes-1.22.3\vendor\k8s.io\client-go\tools\cache\store.go// NewIndexer returns an Indexer implemented simply with a map and a lock.func NewIndexer(keyFunc KeyFunc, indexers Indexers) Indexer {return &cache{ cacheStorage: NewThreadSafeStore(indexers, Indices{}), keyFunc: keyFunc, }}一、
keyFunc的作用作用:给每个对象生成一个唯一的
key用途:把对象存进
items map时,当map的key例子(默认)
keyFunc(obj) → "default/nginx-pod"存到
items里items["default/nginx-pod"] = Pod对象特点
唯一 一个对象只有 一个 key 用来 定位单个对象
而indexers入参的作用如下
二、
indexers的作用作用:给对象生成【分类标签】,建立索引
用途:用来快速查询一批对象
例子
indexers["app"](obj) → "nginx"存到
indices索引表里indices["app"]["nginx"] = { "default/nginx-pod", "default/nginx-1" }特点
可以有 多个索引 一个对象可以属于 多个分类 用来 批量查询
追踪threadSafeMap
// C:\git\kubernetes-1.22.3\vendor\k8s.io\client-go\tools\cache\thread_safe_store.go// threadSafeMap implements ThreadSafeStoretype threadSafeMap struct { lock sync.RWMutex items map[string]interface{}// indexers maps a name to an IndexFunc indexers Indexers// indices maps a name to an Index indices Indices}// Index maps the indexed value to a set of keys in the store that match on that valuetype Index map[string]sets.String// Indexers maps a name to a IndexFunctype Indexers map[string]IndexFunc// Indices maps a name to an Indextype Indices map[string]Indextype String map[string]Empty要理解上面各个字段的用途,可以查看下面的例子,我们现在一共有 4 个 Pod
"default/nginx-pod" → &Pod{Name:"nginx-pod", Labels:{"app":"nginx"}}"default/nginx-1" → &Pod{Name:"nginx-1", Labels:{"app":"nginx"}}"default/nginx-2" → &Pod{Name:"nginx-2", Labels:{"app":"nginx"}}"default/mysql-1" → &Pod{Name:"mysql-1", Labels:{"app":"mysql"}}先看 items中存放的数据
items = {"default/nginx-pod": Pod{Name: "nginx-pod-1", app: nginx},"default/nginx-1": Pod{Name: "nginx-1", app: nginx},"default/nginx-2": Pod{Name: "nginx-2", app: nginx},"default/mysql-1": Pod{Name: "mysql-1", app: mysql},}再看 indexers(索引规则)
indexers := Indexers{"app": podAppIndexFunc, }func podAppIndexFunc(obj interface{}) ([]string, error) { pod := obj.(*v1.Pod)return []string{pod.Labels["app"]}, nil}最后看indices 中存放的数据
indices = {"app": { // 索引名称"nginx": { // 索引值"default/nginx-pod": {}, // 指向 items 里的 key"default/nginx-1": {},"default/nginx-2": {}, },"mysql": { // 索引值"default/mysql-1": {}, }, },}NewIndexer时传入的keyFunc,使用的是MetaNamespaceKeyFunc,也就是对象的namespace/name
// C:\git\kubernetes-1.22.3\vendor\k8s.io\client-go\tools\cache\store.go// MetaNamespaceKeyFunc is a convenient default KeyFunc which knows how to make// keys for API objects which implement meta.Interface.// The key uses the format <namespace>/<name> unless <namespace> is empty, then// it's just <name>.//// TODO: replace key-as-string with a key-as-struct so that this// packing/unpacking won't be necessary.func MetaNamespaceKeyFunc(obj interface{}) (string, error) {if key, ok := obj.(ExplicitKey); ok {return string(key), nil } meta, err := meta.Accessor(obj)if err != nil {return "", fmt.Errorf("object has no meta: %v", err) }if len(meta.GetNamespace()) > 0 {return meta.GetNamespace() + "/" + meta.GetName(), nil }return meta.GetName(), nil}1.5.2、 kube-scheduler给各种 Informer 注册对应的事件处理函数
addAllEventHandlers用于调度器中给各种 Informer 注册对应的事件处理函数,用来增/删/改 同步到调度器缓存。
// C:\git\kubernetes-1.22.3\pkg\scheduler\scheduler.go// New returns a Schedulerfunc New(client clientset.Interface, informerFactory informers.SharedInformerFactory, recorderFactory profile.RecorderFactory, stopCh <-chan struct{}, opts ...Option) (*Scheduler, error) { addAllEventHandlers(sched, informerFactory, dynInformerFactory, unionedGVKs(clusterEventMap))return sched, nil}追踪addAllEventHandlers其中的AddFunc,UpdateFunc,DeleteFunc
func addAllEventHandlers( sched *Scheduler, // 调度器实例 informerFactory informers.SharedInformerFactory, // 内置资源 informer 工厂 dynInformerFactory dynamicinformer.DynamicSharedInformerFactory, // 动态资源 informer 工厂 gvkMap map[framework.GVK]framework.ActionType, // 需要监听的资源类型(GVK)与事件类型) {// ====================== 1. 监听【已调度成功的 Pod】 ======================// 作用:维护调度器内部缓存,记录哪些 Pod 已经调度到节点上 informerFactory.Core().V1().Pods().Informer().AddEventHandler( cache.FilteringResourceEventHandler{// 过滤器:只处理【已经分配了节点的 Pod】 FilterFunc: func(obj interface{})bool {switch t := obj.(type) {case *v1.Pod:/* 判断 Pod 是否已经分配节点(nodeName 不为空) // assignedPod selects pods that are assigned (scheduled and running). func assignedPod(pod *v1.Pod) bool { return len(pod.Spec.NodeName) != 0 } */return assignedPod(t)case cache.DeletedFinalStateUnknown:// 处理删除事件的兜底对象if pod, ok := t.Obj.(*v1.Pod); ok {return assignedPod(pod) } utilruntime.HandleError(fmt.Errorf("unable to convert object %T to *v1.Pod in %T", obj, sched))return falsedefault: utilruntime.HandleError(fmt.Errorf("unable to handle object in %T: %T", sched, obj))return false } },// 事件处理:增/删/改 同步到调度器缓存 Handler: cache.ResourceEventHandlerFuncs{ AddFunc: sched.addPodToCache, // 已调度Pod新增 → 加入缓存 UpdateFunc: sched.updatePodInCache, // 已调度Pod更新 → 更新缓存 DeleteFunc: sched.deletePodFromCache, // 已调度Pod删除 → 从缓存删除 }, }, )// ====================== 2. 监听【未调度的 Pod】 ======================// 作用:把新创建、待调度的 Pod 加入调度队列,让调度器开始工作// unscheduled pod queue informerFactory.Core().V1().Pods().Informer().AddEventHandler( cache.FilteringResourceEventHandler{ FilterFunc: func(obj interface{})bool {switch t := obj.(type) {case *v1.Pod:return !assignedPod(t) && responsibleForPod(t, sched.Profiles)case cache.DeletedFinalStateUnknown:if pod, ok := t.Obj.(*v1.Pod); ok {return !assignedPod(pod) && responsibleForPod(pod, sched.Profiles) } utilruntime.HandleError(fmt.Errorf("unable to convert object %T to *v1.Pod in %T", obj, sched))return falsedefault: utilruntime.HandleError(fmt.Errorf("unable to handle object in %T: %T", sched, obj))return false } }, Handler: cache.ResourceEventHandlerFuncs{ AddFunc: sched.addPodToSchedulingQueue, UpdateFunc: sched.updatePodInSchedulingQueue, DeleteFunc: sched.deletePodFromSchedulingQueue, }, }, )// ====================== 3. 监听 Node 节点变化 ======================// 作用:维护调度器的节点缓存,节点增/删/改都会同步到缓存// ====================== 4. 构造通用事件处理器 ======================// 作用:根据传入的事件类型(Add/Update/Delete),生成对应的事件处理函数// 当集群资源变化时,将等待的 Pod 重新加入调度队列// ====================== 5. 遍历所有需要监听的资源,注册事件 // 监听 PV/PVC/Service/CSI/StorageClass 等影响调度的资源 }追踪AddEventHandler
// C:\git\kubernetes-1.22.3\vendor\k8s.io\client-go\tools\cache\shared_informer.gofunc (s *sharedIndexInformer) AddEventHandler(handler ResourceEventHandler) { s.AddEventHandlerWithResyncPeriod(handler, s.defaultEventHandlerResyncPeriod)}追踪AddEventHandlerWithResyncPeriod
// C:\git\kubernetes-1.22.3\vendor\k8s.io\client-go\tools\cache\shared_informer.gofunc (s *sharedIndexInformer) AddEventHandlerWithResyncPeriod(handler ResourceEventHandler, resyncPeriod time.Duration) { s.startedLock.Lock()defer s.startedLock.Unlock()if s.stopped { klog.V(2).Infof("Handler %v was not added to shared informer because it has stopped already", handler)return }if resyncPeriod > 0 {if resyncPeriod < minimumResyncPeriod { klog.Warningf("resyncPeriod %v is too small. Changing it to the minimum allowed value of %v", resyncPeriod, minimumResyncPeriod) resyncPeriod = minimumResyncPeriod }if resyncPeriod < s.resyncCheckPeriod {if s.started { klog.Warningf("resyncPeriod %v is smaller than resyncCheckPeriod %v and the informer has already started. Changing it to %v", resyncPeriod, s.resyncCheckPeriod, s.resyncCheckPeriod) resyncPeriod = s.resyncCheckPeriod } else {// if the event handler's resyncPeriod is smaller than the current resyncCheckPeriod, update// resyncCheckPeriod to match resyncPeriod and adjust the resync periods of all the listeners// accordingly s.resyncCheckPeriod = resyncPeriod s.processor.resyncCheckPeriodChanged(resyncPeriod) } } } listener := newProcessListener(handler, resyncPeriod, determineResyncPeriod(resyncPeriod, s.resyncCheckPeriod), s.clock.Now(), initialBufferSize)if !s.started { s.processor.addListener(listener)return }// in order to safely join, we have to// 1. stop sending add/update/delete notifications// 2. do a list against the store// 3. send synthetic "Add" events to the new handler// 4. unblock s.blockDeltas.Lock()defer s.blockDeltas.Unlock() s.processor.addListener(listener)for _, item := range s.indexer.List() { listener.add(addNotification{newObj: item}) }}追踪上面的代码的如下部分
// C:\git\kubernetes-1.22.3\vendor\k8s.io\client-go\tools\cache\shared_informer.golistener := newProcessListener(handler, resyncPeriod, determineResyncPeriod(resyncPeriod, s.resyncCheckPeriod), s.clock.Now(), initialBufferSize)if !s.started { s.processor.addListener(listener)return }追踪newProcessListener
// C:\git\kubernetes-1.22.3\vendor\k8s.io\client-go\tools\cache\shared_informer.gofunc newProcessListener(handler ResourceEventHandler, requestedResyncPeriod, resyncPeriod time.Duration, now time.Time, bufferSize int) *processorListener { ret := &processorListener{ nextCh: make(chan interface{}), addCh: make(chan interface{}), handler: handler, pendingNotifications: *buffer.NewRingGrowing(bufferSize), requestedResyncPeriod: requestedResyncPeriod, resyncPeriod: resyncPeriod, } ret.determineNextResync(now)return ret}然后继续追踪processorListener.nextCh是如何被写入事件的,后面processorListener.run会消费这个被写入的事件。
// C:\git\kubernetes-1.22.3\vendor\k8s.io\client-go\tools\cache\shared_informer.go// pop 是 processorListener 的核心事件转发协程// 作用:从 addCh 接收事件,通过环形缓冲削峰,最终转发到 nextCh 交给 run() 处理// 核心设计:// 1. 局部变量 nextCh 是“写入开关”,不是 p.nextCh,但会动态指向 p.nextCh// 2. 第一个事件不会丢弃,会暂存在 notification 变量中,再打开开关发送// 3. 没有事件时,nextCh = nil,让 select 不阻塞、不浪费资源// 4. 事件处理顺序:addCh → 缓冲/暂存 → nextCh → run() → 你的 OnAdd/OnUpdate/OnDeletefunc (p *processorListener) pop() {defer utilruntime.HandleCrash() // 崩溃保护,防止 panic 导致整个 informer 挂掉defer close(p.nextCh) // pop 退出时关闭 nextCh,通知 run() 协程停止// 关键:这里的 nextCh 是【局部变量】,不是 p.nextCh// 作用是“动态写入开关”:// - 为 nil 时:case nextCh <- notification 永远不触发(关闭写入)// - 指向 p.nextCh 时:才允许向真正的通道发送事件var nextCh chan<- interface{}// 用来暂存“待发送”的事件,避免直接写入通道导致阻塞var notification interface{}// 无限循环,处理事件for {select {// ==============================================// 【分支1】向 nextCh 写入事件(只有 nextCh != nil 时才会触发)// 此时局部变量 nextCh 已经指向 p.nextCh// ==============================================case nextCh <- notification:// 事件已成功发送到 nextCh,run() 会收到并处理// 从环形缓冲区读取下一个待发送事件var ok bool notification, ok = p.pendingNotifications.ReadOne()// 如果缓冲区没有更多事件了if !ok { nextCh = nil // 关闭写入开关:局部 nextCh 变回 nil,不再触发此 case }// ==============================================// 【分支2】从 addCh 接收新事件(来自 sharedProcessor 分发)// ==============================================case notificationToAdd, ok := <-p.addCh:// addCh 被关闭,直接退出协程if !ok {return }// ==============================================// 你问过:第一个事件会不会丢?// 答案:绝对不会!这里先暂存,再打开开关// ==============================================if notification == nil {// 优化场景:当前没有待发送事件,缓冲区也为空// 1. 把新事件直接暂存到局部变量 notification notification = notificationToAdd// 2. 打开开关:让局部 nextCh 指向真正的 p.nextCh// 下一轮循环就会进入上面的 case,把事件发出去 nextCh = p.nextCh } else {// 当前已有事件等待发送,新事件写入环形缓冲区,防止阻塞 p.pendingNotifications.WriteOne(notificationToAdd) } } }}上面这段代码,这是 Go 并发编程的神级写法,也是 k8s 高性能的关键!理解它有点迷惑,所以有如下简单的demo
package mainimport ("fmt""time")// 演示:动态把 channel 设为 nil(开关效果)func main() {// 创建一个真实的 channel ch := make(chan int)// 局部变量:动态开关var dynamicCh chan<- int // 初始 = nilvar currentValue int// 模拟生产者:每隔1秒发一个数据go func() {for i := 1; i <= 3; i++ { time.Sleep(1 * time.Second) fmt.Printf("\n 生产者发送数据: %d\n", i) ch <- i }// 发送完关闭 channelclose(ch) fmt.Println("\n 生产者关闭 channel") }()// 模拟 processorListener.pop() 的核心逻辑 fmt.Println("=== 开始监听 ===")for {select {// ======================================// 【发送端】只有 dynamicCh != nil 时才生效// ======================================case dynamicCh <- currentValue: fmt.Println(" 数据发送成功到消费者")// 发送完 → 没有数据了 → 关闭开关(设为 nil) dynamicCh = nil currentValue = 0 fmt.Println(" 发送完成,关闭开关 (dynamicCh = nil)")// ======================================// 【接收端】接收生产者数据// ======================================case val, ok := <-ch:if !ok { fmt.Println(" 消费者退出")return } fmt.Printf(" 消费者收到数据: %d\n", val)// 拿到数据 → 打开开关!让发送端可以工作 currentValue = val dynamicCh = ch // 指向真实 channel,打开开关 fmt.Println(" 拿到数据,打开开关 (dynamicCh = ch)") } }}这个https://cloud.tencent.com.cn/developer/article/2623224页面上有关于go语言的这个feature的详细解是。
每次添加一个handler,那么创建一个listener,然后把listener添加到processor。后续启动 listener.run()处理事件(调用用户注册的 AddFunc/UpdateFunc/DeleteFunc)
// C:\git\kubernetes-1.22.3\vendor\k8s.io\client-go\tools\cache\shared_informer.gofunc (p *sharedProcessor) addListener(listener *processorListener) { p.listenersLock.Lock()defer p.listenersLock.Unlock() p.addListenerLocked(listener)if p.listenersStarted { p.wg.Start(listener.run) p.wg.Start(listener.pop) }}1.5.3、启动informers
// C:\git\kubernetes-1.22.3\cmd\kube-scheduler\app\server.go// Run executes the scheduler based on the given configuration. It only returns on error or when context is done.func Run(ctx context.Context, cc *schedulerserverconfig.CompletedConfig, sched *scheduler.Scheduler)error {// Start all informers. cc.InformerFactory.Start(ctx.Done())// Wait for all caches to sync before scheduling. cc.InformerFactory.WaitForCacheSync(ctx.Done()) sched.Run(ctx)return fmt.Errorf("finished without leader elect")}追踪InformerFactory.Start
// C:\git\kubernetes-1.22.3\staging\src\k8s.io\client-go\informers\factory.go// Start 启动所有已经创建好的 informer// 作用:遍历所有已注册的 informer,启动它们的 Run 循环(开始监听 APIServer)func (f *sharedInformerFactory) Start(stopCh <-chan struct{}) { f.lock.Lock()defer f.lock.Unlock()// 遍历工厂中所有已经创建好的 informer// f.informers map[reflect.Type]cache.SharedIndexInformerfor informerType, informer := range f.informers {// 判断这个类型的 informer 是否已经启动过// 没有启动才执行启动if !f.startedInformers[informerType] {// 【关键】启动 informer 的事件循环(后台协程)// informer.Run() 会启动 List + Watch,开始同步数据go informer.Run(stopCh)// 标记为已启动,防止重复启动 f.startedInformers[informerType] = true } }}继续追踪go informer.Run(stopCh)
// C:\git\kubernetes-1.22.3\staging\src\k8s.io\client-go\tools\cache\shared_informer.go// Run 方法:启动 sharedIndexInformer,开始监听、同步、处理数据// 这是 Informer 的主循环,一旦启动就会一直运行func (s *sharedIndexInformer) Run(stopCh <-chan struct{}) {defer utilruntime.HandleCrash() // 崩溃处理,防止程序直接挂掉// ====================== 1. 创建 DeltaFIFO 队列 ======================// DeltaFIFO:存储从 APIServer 监听到的事件(Add/Update/Delete)// KnownObjects:s.indexer 就是本地缓存,用于队列同步、去重 fifo := NewDeltaFIFOWithOptions(DeltaFIFOOptions{ KnownObjects: s.indexer, EmitDeltaTypeReplaced: true, })// ====================== 2. 配置 Controller ======================// Controller 是真正执行 List + Watch 的核心组件 cfg := &Config{ Queue: fifo, // 事件队列 ListerWatcher: s.listerWatcher, // 用来 List/Watch APIServer ObjectType: s.objectType, // 监听的资源类型(Pod/Node等) FullResyncPeriod: s.resyncCheckPeriod, // 全量同步周期 RetryOnError: false, ShouldResync: s.processor.shouldResync, // 是否需要重新同步 Process: s.HandleDeltas, // 从队列取出事件后的处理函数 WatchErrorHandler: s.watchErrorHandler, // 监听出错处理 }// ====================== 3. 初始化并创建 Controller ======================func() { s.startedLock.Lock()defer s.startedLock.Unlock() s.controller = New(cfg) // 创建 controller s.controller.(*controller).clock = s.clock s.started = true // 标记 informer 已启动 }()// ====================== 4. 启动事件处理器 ======================// processorStopCh:专门用来关闭事件处理器 processorStopCh := make(chan struct{})var wg wait.Groupdefer wg.Wait() // 等待处理器完全退出defer close(processorStopCh) // 退出时关闭处理器// 启动缓存检测器 + 事件分发处理器 wg.StartWithChannel(processorStopCh, s.cacheMutationDetector.Run) wg.StartWithChannel(processorStopCh, s.processor.run)// 退出时标记已停止defer func() { s.startedLock.Lock()defer s.startedLock.Unlock() s.stopped = true }()// ====================== 5. 【真正启动】Controller 主循环 ======================// 这里会一直阻塞:执行 List + Watch,不断从 APIServer 同步数据到队列 s.controller.Run(stopCh)}其中sharedIndexInformer
// C:\git\kubernetes-1.22.3\staging\src\k8s.io\client-go\tools\cache\shared_informer.gotype sharedIndexInformer struct {// 1. 本地缓存(存储Pod/Node等数据) indexer Indexer// 2. 类型:cache.Controller (来自 client-go/tools/cache)// 作用:负责 启动Reflector + 消费队列 + 同步数据 controller Controller// 3. 事件分发器(把变化事件发给scheduler等业务代码) processor *sharedProcessor// 4. 定义怎么去APIServer拉取数据(List/Watch函数) listerWatcher ListerWatcher// 5. 其他都是配置:同步周期、锁、状态... objectType runtime.Object resyncCheckPeriod time.Duration defaultEventHandlerResyncPeriod time.Duration clock clock.Clock started, stopped bool startedLock sync.Mutex watchErrorHandler WatchErrorHandler}sharedIndexInformer (总控:整个监听器) │ ├── indexer (本地缓存) ├── processor (事件分发) ├── listerWatcher(怎么拉数据) └── controller 【你问的这个】(同步控制器) │ └── reflector (真正去APIServer拉数据)追踪s.processor.run,查看事件分发处理。
// C:\git\kubernetes-1.22.3\staging\src\k8s.io\client-go\tools\cache\shared_informer.go// run 方法:启动 sharedProcessor(事件分发器)// 作用:启动所有注册的 listener,开始分发事件// 一直运行到 stopCh 收到停止信号func (p *sharedProcessor) run(stopCh <-chan struct{}) {// ====================== 1. 启动所有监听器 ======================// 加读锁,防止遍历期间 listeners 被修改func() { p.listenersLock.RLock()defer p.listenersLock.RUnlock()// 遍历所有注册的 listener(每个 AddEventHandler 都会创建一个 listener)for _, listener := range p.listeners {// 启动 listener.run():处理事件(调用用户注册的 AddFunc/UpdateFunc/DeleteFunc) p.wg.Start(listener.run)// 启动 listener.pop():从队列里取事件 p.wg.Start(listener.pop) }// 标记所有监听器已启动 p.listenersStarted = true }()// ====================== 2. 等待停止信号 ======================// 阻塞在这里,直到外部关闭 stopCh <-stopCh //<================程序会卡在这里一直运行listener.run和listener.pop// ====================== 3. 收到停止信号 → 优雅关闭 ====================== p.listenersLock.RLock()defer p.listenersLock.RUnlock()// 关闭每个 listener 的 addCh 通道 → 通知 pop 协程停止for _, listener := range p.listeners {close(listener.addCh) }// 等待所有 run() 和 pop() 协程全部退出 p.wg.Wait()}追踪listener.run,前面每次添加一个handler,那么创建一个listener,然后把listener添加到processor。后续启动 listener.run()处理事件(调用用户注册的 AddFunc/UpdateFunc/DeleteFunc)
// C:\git\kubernetes-1.22.3\staging\src\k8s.io\client-go\tools\cache\shared_informer.go func (p *processorListener) run() {// this call blocks until the channel is closed. When a panic happens during the notification// we will catch it, **the offending item will be skipped!**, and after a short delay (one second)// the next notification will be attempted. This is usually better than the alternative of never// delivering again. stopCh := make(chan struct{}) wait.Until(func() {for next := range p.nextCh {switch notification := next.(type) {case updateNotification: p.handler.OnUpdate(notification.oldObj, notification.newObj)case addNotification: p.handler.OnAdd(notification.newObj)case deleteNotification: p.handler.OnDelete(notification.oldObj)default: utilruntime.HandleError(fmt.Errorf("unrecognized notification: %T", next)) } }// the only way to get here is if the p.nextCh is empty and closedclose(stopCh) }, 1*time.Second, stopCh)}在processorListener的run中执行eventHandler注册的回调方法
// C:\git\kubernetes-1.22.3\vendor\k8s.io\client-go\tools\cache\shared_informer.go// run 是 processorListener 的消费协程// 职责:从 nextCh 读取事件,分发给用户注册的 OnAdd/OnUpdate/OnDelete// 核心保障:// 1. 即使业务代码(OnAdd)panic,也不会导致整个 informer 挂掉// 2. panic 后会自动恢复,1秒后继续处理下一条事件// 3. 事件处理是串行的,保证顺序func (p *processorListener) run() {// 用于停止内部循环的通道 stopCh := make(chan struct{})// wait.Until 是 Kubernetes 工具函数:// 作用:无限循环执行传入的函数,除非 stopCh 被关闭// 如果函数 panic,会自动 recover,等待1秒后重试 wait.Until(func() {// 核心循环:不断从 nextCh 读取事件// 只有 nextCh 被 close 时,for 循环才会退出for next := range p.nextCh {// 根据事件类型,分发到不同的回调switch notification := next.(type) {case updateNotification:// 调用你写的 OnUpdate 函数 p.handler.OnUpdate(notification.oldObj, notification.newObj)case addNotification:// 调用你写的 OnAdd 函数(例如 addPodToCache) p.handler.OnAdd(notification.newObj)case deleteNotification:// 调用你写的 OnDelete 函数 p.handler.OnDelete(notification.oldObj)default:// 未知事件,报错但不崩溃 utilruntime.HandleError(fmt.Errorf("unrecognized notification: %T", next)) } }// 只有 p.nextCh 被关闭,才会走到这里// 关闭 stopCh → 让 wait.Until 停止循环close(stopCh) }, 1*time.Second, stopCh) // 1秒:panic 后的重试间隔}继续回到sharedIndexInformer.Run,追踪其中的controller.Run
// C:\git\kubernetes-1.22.3\staging\src\k8s.io\client-go\tools\cache\shared_informer.go// Run 方法:启动 sharedIndexInformer,开始监听、同步、处理数据// 这是 Informer 的主循环,一旦启动就会一直运行func (s *sharedIndexInformer) Run(stopCh <-chan struct{}) { // ====================== 5. 【真正启动】Controller 主循环 ======================// 这里会一直阻塞:执行 List + Watch,不断从 APIServer 同步数据到队列 s.controller.Run(stopCh)}追踪controller.Run
// C:\git\kubernetes-1.22.3\staging\src\k8s.io\client-go\tools\cache\controller.gofunc (c *controller) Run(stopCh <-chan struct{}) {defer utilruntime.HandleCrash()go func() { <-stopCh c.config.Queue.Close() }() r := NewReflector( c.config.ListerWatcher, c.config.ObjectType, c.config.Queue, c.config.FullResyncPeriod, ) r.ShouldResync = c.config.ShouldResync r.WatchListPageSize = c.config.WatchListPageSize r.clock = c.clockif c.config.WatchErrorHandler != nil { r.watchErrorHandler = c.config.WatchErrorHandler } c.reflectorMutex.Lock() c.reflector = r c.reflectorMutex.Unlock()var wg wait.Group wg.StartWithChannel(stopCh, r.Run) wait.Until(c.processLoop, time.Second, stopCh) wg.Wait()}追踪r.Run,r.Run 代表生产,往Queue里放数据
// C:\git\kubernetes-1.22.3\staging\src\k8s.io\client-go\tools\cache\reflector.go// Run repeatedly uses the reflector's ListAndWatch to fetch all the// objects and subsequent deltas.// Run will exit when stopCh is closed.func (r *Reflector) Run(stopCh <-chan struct{}) { klog.V(3).Infof("Starting reflector %s (%s) from %s", r.expectedTypeName, r.resyncPeriod, r.name) wait.BackoffUntil(func() {if err := r.ListAndWatch(stopCh); err != nil { r.watchErrorHandler(r, err) } }, r.backoffManager, true, stopCh) klog.V(3).Infof("Stopping reflector %s (%s) from %s", r.expectedTypeName, r.resyncPeriod, r.name)}继续追踪Reflector.ListAndWatch
// C:\git\kubernetes-1.22.3\staging\src\k8s.io\client-go\tools\cache\reflector.go// ListAndWatch first lists all items and get the resource version at the moment of call,// and then use the resource version to watch.// It returns error if ListAndWatch didn't even try to initialize watch.func (r *Reflector) ListAndWatch(stopCh <-chan struct{}) error {if err := r.watchHandler(start, w, &resourceVersion, resyncerrc, stopCh); err != nil { }}继续追踪Reflector.watchHandler
// C:\git\kubernetes-1.22.3\staging\src\k8s.io\client-go\tools\cache\reflector.go// watchHandler watches w and keeps *resourceVersion up to date.func (r *Reflector) watchHandler(start time.Time, w watch.Interface, resourceVersion *string, errc chan error, stopCh <-chan struct{}) error { eventCount := 0// Stopping the watcher should be idempotent and if we return from this function there's no way// we're coming back in with the same watch interface.defer w.Stop()loop:for {select {case event, ok := <-w.ResultChan():switch event.Type {case watch.Added:// 添加到队列 err := r.store.Add(event.Object)if err != nil { utilruntime.HandleError(fmt.Errorf("%s: unable to add watch event object (%#v) to store: %v", r.name, event.Object, err)) }// 更新队列中事件case watch.Modified: err := r.store.Update(event.Object)if err != nil { utilruntime.HandleError(fmt.Errorf("%s: unable to update watch event object (%#v) to store: %v", r.name, event.Object, err)) }// 删除队列中事件case watch.Deleted:// TODO: Will any consumers need access to the "last known// state", which is passed in event.Object? If so, may need// to change this. err := r.store.Delete(event.Object)if err != nil { utilruntime.HandleError(fmt.Errorf("%s: unable to delete watch event object (%#v) from store: %v", r.name, event.Object, err)) }case watch.Bookmark:// A `Bookmark` means watch has synced here, just update the resourceVersiondefault: utilruntime.HandleError(fmt.Errorf("%s: unable to understand watch event %#v", r.name, event)) } *resourceVersion = newResourceVersion r.setLastSyncResourceVersion(newResourceVersion)if rvu, ok := r.store.(ResourceVersionUpdater); ok { rvu.UpdateResourceVersion(newResourceVersion) } eventCount++ } }}那么在哪里消费队列中的事件
// C:\git\kubernetes-1.22.3\staging\src\k8s.io\client-go\tools\cache\controller.go// Run begins processing items, and will continue until a value is sent down stopCh or it is closed.// It's an error to call Run more than once.// Run blocks; call via go.func (c *controller) Run(stopCh <-chan struct{}) {defer utilruntime.HandleCrash()go func() { <-stopCh c.config.Queue.Close() }() r := NewReflector( c.config.ListerWatcher, c.config.ObjectType, c.config.Queue, c.config.FullResyncPeriod, ) r.ShouldResync = c.config.ShouldResync r.WatchListPageSize = c.config.WatchListPageSize r.clock = c.clockif c.config.WatchErrorHandler != nil { r.watchErrorHandler = c.config.WatchErrorHandler } c.reflectorMutex.Lock() c.reflector = r c.reflectorMutex.Unlock()var wg wait.Group// 这里向队列写入事件 wg.StartWithChannel(stopCh, r.Run)// 这里消费写入队列的事件 wait.Until(c.processLoop, time.Second, stopCh) wg.Wait()}继续追踪controller.processLoop,追踪消费事件
// C:\git\kubernetes-1.22.3\staging\src\k8s.io\client-go\tools\cache\controller.go// processLoop drains the work queue.// TODO: Consider doing the processing in parallel. This will require a little thought// to make sure that we don't end up processing the same object multiple times// concurrently.//// TODO: Plumb through the stopCh here (and down to the queue) so that this can// actually exit when the controller is stopped. Or just give up on this stuff// ever being stoppable. Converting this whole package to use Context would// also be helpful.func (c *controller) processLoop() {for { obj, err := c.config.Queue.Pop(PopProcessFunc(c.config.Process))if err != nil {if err == ErrFIFOClosed {return }if c.config.RetryOnError {// This is the safe way to re-enqueue. c.config.Queue.AddIfNotPresent(obj) } } }}追踪其中的c.config.Process,也就是sharedIndexInformer.HandleDeltas
// C:\git\kubernetes-1.22.3\staging\src\k8s.io\client-go\tools\cache\shared_informer.go// HandleDeltas:处理从 DeltaFIFO 弹出来的事件// 核心职责:// 1. 维护本地缓存 indexer(Add/Update/Delete)// 2. 将事件分发给所有注册的 handler(listener)// 3. 区分普通事件 和 全量同步(resync)事件func (s *sharedIndexInformer) HandleDeltas(obj interface{}) error {// 加锁:防止在添加新 handler 时,事件乱序 s.blockDeltas.Lock()defer s.blockDeltas.Unlock()// 遍历 Deltas(一批事件,按旧→新顺序)for _, d := range obj.(Deltas) {switch d.Type {// 处理:新增 / 更新 / 替换 / 同步 事件case Sync, Replaced, Added, Updated:// 缓存检测(调试用,忽略) s.cacheMutationDetector.AddObject(d.Object)// 尝试从本地缓存获取旧对象if old, exists, err := s.indexer.Get(d.Object); err == nil && exists {// 1. 【更新本地缓存】if err := s.indexer.Update(d.Object); err != nil {return err }// 判断是否是【Resync 同步事件】 isSync := falseswitch {case d.Type == Sync:// 明确的 Sync 事件 → 标记为同步 isSync = truecase d.Type == Replaced:// 如果对象被替换但 ResourceVersion 没变 → 视为同步 isSync = meta.GetResourceVersion(old) == meta.GetResourceVersion(d.Object) }// 2. 【分发 UPDATE 事件】给所有 handler s.processor.distribute( updateNotification{oldObj: old, newObj: d.Object}, isSync, // 只传给需要 resync 的 listener ) } else {// 缓存中不存在 → 新增对象// 1. 【写入本地缓存】if err := s.indexer.Add(d.Object); err != nil {return err }// 2. 【分发 ADD 事件】 s.processor.distribute( addNotification{newObj: d.Object},false, ) }// 处理:删除事件case Deleted:// 1. 【从本地缓存删除】if err := s.indexer.Delete(d.Object); err != nil {return err }// 2. 【分发 DELETE 事件】 s.processor.distribute( deleteNotification{oldObj: d.Object},false, ) } }return nil}可以看到上面的代码功能就是,在indexer中判断对象是否存在,存在更新,不存在就新增同时调用distribute函数分发给listener。至此更新store也就是indexer,然后分发事件全部完成。
APIServer ↓Reflector(List/Watch) ↓DeltaFIFO(事件队列) ↓HandleDeltas 【你现在看的这个函数】 1. 更新本地缓存 indexer 2. 构造 add/update/delete 通知 ↓sharedProcessor(事件总线) ↓每个 handler 对应一个 processorListener ↓pop() + run() ↓你的业务代码:OnAdd/OnUpdate/OnDelete,也就是添加到`internalqueue.NewSchedulingQueue`中1.6、kube-scheduler利用informer机制调度pod
// C:\git\kubernetes-1.22.3\pkg\scheduler\scheduler.go// Scheduler 是 Kubernetes 调度器的核心结构体// 作用:监听未调度的 Pod,为 Pod 选择合适节点,并将绑定结果写回 APIServertype Scheduler struct {// 调度器本地内存缓存:保存所有节点、Pod 的资源与状态信息// 调度器不直接访问 APIServer,而是读缓存,大幅提升调度速度// NodeLister(节点列表)和 Algorithm(调度算法)都会依赖这个缓存 SchedulerCache internalcache.Cache// 调度算法核心:实现 预选(Predicate) + 优选(Priority) 逻辑// 负责从所有节点中过滤、打分,最终选出最优节点 Algorithm ScheduleAlgorithm// 调度扩展器:支持外部 HTTP 调度服务扩展调度逻辑(外挂调度器) Extenders []framework.Extender// 获取下一个待调度 Pod 的函数:会阻塞直到有新 Pod 可用// 不用 channel 是因为调度耗时可能很长,channel 会导致 Pod 信息过期 NextPod func() *framework.QueuedPodInfo// 调度出错时的回调函数:传入出错的 Pod 和错误信息// 用于打印日志、上报事件、处理重试 Error func(*framework.QueuedPodInfo, error)// 调度器关闭信号:关闭这个通道,调度器会优雅退出 StopEverything <-chan struct{}// 待调度 Pod 优先级队列:所有未调度的 Pod 在这里排队// 支持优先级、退避重试、抢占、nominated 机制 SchedulingQueue internalqueue.SchedulingQueue// 调度配置集合:一个调度器可以支持多套调度策略/插件配置// 不同 Pod 可以使用不同的调度 profile Profiles profile.Map// K8s 客户端:与 kube-apiserver 通信// 最终调度完成后,通过它将 Pod 与 Node 的绑定关系写入 etcd client clientset.Interface}其中的Profiles profile.Map使用KubeSchedulerConfiguration完成,启动 kube-scheduler 时通过命令行参数 --config 指定文件路径:
kube-scheduler --config=/etc/kubernetes/scheduler-config.yaml其中KubeSchedulerConfiguration配置类似如下
# scheduler-config.yamlapiVersion: kubescheduler.config.k8s.io/v1kind: KubeSchedulerConfigurationclientConnection:kubeconfig: /etc/kubernetes/scheduler.conf# 核心:定义多套调度Profileprofiles:# Profile1:默认调度器,所有不指定schedulerName的Pod走这套规则- schedulerName: default-schedulerplugins:filter:enabled:- name: NodeName- name: TaintToleration- name: NodeResourcesFitscore:enabled:- name: NodeResourcesFitweight: 5# Profile2:GPU专用调度器,Pod指定schedulerName=gpu-scheduler才会使用- schedulerName: gpu-schedulerplugins:filter:enabled:- name: NodeName- name: GpuFilter # 自定义GPU过滤插件score:enabled:- name: GpuPriorityweight: 10参考:https://kubernetes.io/zh-cn/docs/reference/scheduling/config/
pod调度的时候,可以使用schedulerName去指定调度器
apiVersion: v1kind: Podmetadata:name: gpu-podspec:# 匹配配置文件中 schedulerName: gpu-scheduler 的ProfileschedulerName: gpu-schedulercontainers:- name: gpu-containerimage: nvidia/cudaresources:limits:nvidia.com/gpu: 1继续追踪SchedulingQueue的初始化
// C:\git\kubernetes-1.22.3\pkg\scheduler\scheduler.go// New returns a Schedulerfunc New(client clientset.Interface, informerFactory informers.SharedInformerFactory, recorderFactory profile.RecorderFactory, stopCh <-chan struct{}, opts ...Option) (*Scheduler, error) {var sched *Schedulerif options.legacyPolicySource == nil {// Create the config from component config sc, err := configurator.create()if err != nil {return nil, fmt.Errorf("couldn't create scheduler: %v", err) } sched = sc } else {// Create the config from a user specified policy source. policy := &schedulerapi.Policy{}switch {case options.legacyPolicySource.File != nil:if err := initPolicyFromFile(options.legacyPolicySource.File.Path, policy); err != nil {return nil, err }case options.legacyPolicySource.ConfigMap != nil:if err := initPolicyFromConfigMap(client, options.legacyPolicySource.ConfigMap, policy); err != nil {return nil, err } }// Set extenders on the configurator now that we've decoded the policy// In this case, c.extenders should be nil since we're using a policy (and therefore not componentconfig,// which would have set extenders in the above instantiation of Configurator from CC options) configurator.extenders = policy.Extenders sc, err := configurator.createFromPolicy(*policy)if err != nil {return nil, fmt.Errorf("couldn't create scheduler from policy: %v", err) } sched = sc }// Additional tweaks to the config produced by the configurator. sched.StopEverything = stopEverything sched.client = client// Build dynamic client and dynamic informer factoryvar dynInformerFactory dynamicinformer.DynamicSharedInformerFactory// options.kubeConfig can be nil in tests.if options.kubeConfig != nil { dynClient := dynamic.NewForConfigOrDie(options.kubeConfig) dynInformerFactory = dynamicinformer.NewFilteredDynamicSharedInformerFactory(dynClient, 0, v1.NamespaceAll, nil) } addAllEventHandlers(sched, informerFactory, dynInformerFactory, unionedGVKs(clusterEventMap))return sched, nil}追踪configurator.create()
// C:\git\kubernetes-1.22.3\pkg\scheduler\factory.go// create() 方法:根据注册的插件,创建并返回一个完整的 Scheduler 调度器实例// 这是调度器创建的核心方法,所有组件(队列、算法、profile、缓存)都在这里组装完成func (c *Configurator) create() (*Scheduler, error) {// 定义扩展器切片和被忽略的扩展资源列表var extenders []framework.Extendervar ignoredExtendedResources []string// 1. 初始化并处理 Extenders(外部 HTTP 调度扩展器) // 如果配置了 extenders,遍历创建 HTTP 扩展器// 2. 将 Extender 忽略的资源注入 NodeResourcesFit 插件 // 如果有扩展资源需要忽略,更新每个 Profile 里的 NodeResourcesFit 插件配置// 3. 创建 Pod 提名器(用于 Pod 抢占机制) // nominator 用于记录被抢占的 Pod,调度器会优先重试这些 Pod// 4. 创建 Profiles Map(核心:多套调度规则) // 根据配置文件中的 profiles 数组,创建 profile.Map// key = schedulerName, value = 完整调度框架 Framework// 5. 创建调度队列 SchedulingQueue // 所有 Profile 必须使用同一个队列排序函数(保证全局排序一致) lessFn := profiles[c.profiles[0].SchedulerName].QueueSortFunc()// 创建优先级调度队列 podQueue := internalqueue.NewSchedulingQueue( lessFn, c.informerFactory, internalqueue.WithPodInitialBackoffDuration(time.Duration(c.podInitialBackoffSeconds)*time.Second), internalqueue.WithPodMaxBackoffDuration(time.Duration(c.podMaxBackoffSeconds)*time.Second), internalqueue.WithPodNominator(nominator), internalqueue.WithClusterEventMap(c.clusterEventMap), )// 6. 启动缓存调试器(用于观测缓存状态) // 7. 创建调度算法实例(GenericScheduler) // 实现预选 + 优选逻辑// 8. 组装所有组件,返回最终的 Scheduler 结构体 return &Scheduler{ SchedulerCache: c.schedulerCache, // 本地内存缓存 Algorithm: algo, // 调度算法(预选+优选) Extenders: extenders, // 外部扩展器 Profiles: profiles, // 多套调度规则(核心!) NextPod: internalqueue.MakeNextPodFunc(podQueue), // 从队列取Pod的函数 Error: MakeDefaultErrorFunc(c.client, c.informerFactory.Core().V1().Pods().Lister(), podQueue, c.schedulerCache), // 错误处理 StopEverything: c.StopEverything, // 退出信号 SchedulingQueue: podQueue, // 待调度Pod优先级队列 }, nil}追踪internalqueue.NewSchedulingQueue这是一个带有优先级的队列
// C:\git\kubernetes-1.22.3\pkg\scheduler\internal\queue\scheduling_queue.go// NewSchedulingQueue initializes a priority queue as a new scheduling queue.func NewSchedulingQueue( lessFn framework.LessFunc, informerFactory informers.SharedInformerFactory, opts ...Option) SchedulingQueue {return NewPriorityQueue(lessFn, informerFactory, opts...)}为什么会有优先级?因为有些pod比较重要,需要优先调度,运行。
关于调度优先级,可以查看这个文档 https://kubernetes.io/zh-cn/docs/concepts/scheduling-eviction/pod-priority-preemption/
# high-priority.yaml 高优先级apiVersion: scheduling.k8s.io/v1kind: PriorityClassmetadata:name: high-priorityvalue: 2000000# 数字越大优先级越高globalDefault: false# 不作为全局默认description: "高优先级,用于核心服务"# low-priority.yaml 低优先级apiVersion: scheduling.k8s.io/v1kind: PriorityClassmetadata:name: low-priorityvalue: 1000000# 数字越小优先级越低globalDefault: falsedescription: "低优先级,用于测试业务"创建和查看优先级
[root@master]# kubectl apply -f high-priority.yaml[root@master]# kubectl apply -f low-priority.yaml[root@master]# kubectl get PriorityClassNAME VALUE GLOBAL-DEFAULT AGElow-priority 1000000 true 12dhigh-priority 2000000 true 12d使用高优先级
apiVersion: v1kind: Podmetadata:name: nginx-highspec:priorityClassName: high-priority# 使用高优先级containers:- name: nginximage: nginxresources:requests:cpu: 100mmemory: 128Mi继续追踪internalqueue.MakeNextPodFunc(podQueue),也就是NextPod的初始化
// C:\git\kubernetes-1.22.3\pkg\scheduler\internal\queue\scheduling_queue.go// MakeNextPodFunc returns a function to retrieve the next pod from a given// scheduling queuefunc MakeNextPodFunc(queue SchedulingQueue)func() *framework.QueuedPodInfo {return func() *framework.QueuedPodInfo { podInfo, err := queue.Pop()if err == nil { klog.V(4).InfoS("About to try and schedule pod", "pod", klog.KObj(podInfo.Pod))return podInfo } klog.ErrorS(err, "Error while retrieving next pod from scheduling queue")return nil }}可以看到就是从 podQueue中 pop一个pod的信息。那么pod是如何添加到队列中的
// C:\git\kubernetes-1.22.3\pkg\scheduler\eventhandlers.gofunc addAllEventHandlers( sched *Scheduler, informerFactory informers.SharedInformerFactory, dynInformerFactory dynamicinformer.DynamicSharedInformerFactory, gvkMap map[framework.GVK]framework.ActionType,) {// scheduled pod cache informerFactory.Core().V1().Pods().Informer().AddEventHandler( cache.FilteringResourceEventHandler{ FilterFunc: func(obj interface{})bool { }, Handler: cache.ResourceEventHandlerFuncs{ AddFunc: sched.addPodToCache, UpdateFunc: sched.updatePodInCache, DeleteFunc: sched.deletePodFromCache, }, }, )通过调用sched.addPodToCache,sched.updatePodInCache和sched.deletePodFromCache
至此 创建的pod入队出队我们都了解了。
1.6.1、pod的调度过程
接下来我们追踪一下pod的调度过程,从NewSchedulerCommand.Run入口
// C:\git\kubernetes-1.22.3\cmd\kube-scheduler\app\server.go// runCommand runs the scheduler.func runCommand(cmd *cobra.Command, opts *options.Options, registryOptions ...Option)error { verflag.PrintAndExitIfRequested() cliflag.PrintFlags(cmd.Flags()) ctx, cancel := context.WithCancel(context.Background())defer cancel()go func() { stopCh := server.SetupSignalHandler() <-stopCh cancel() }() cc, sched, err := Setup(ctx, opts, registryOptions...)if err != nil {return err }return Run(ctx, cc, sched)}追踪Run
// C:\git\kubernetes-1.22.3\cmd\kube-scheduler\app\server.go// Run executes the scheduler based on the given configuration. It only returns on error or when context is done.func Run(ctx context.Context, cc *schedulerserverconfig.CompletedConfig, sched *scheduler.Scheduler)error { sched.Run(ctx)return fmt.Errorf("finished without leader elect")}继续追踪sched.Run(ctx)
// C:\git\kubernetes-1.22.3\pkg\scheduler\scheduler.go// Run begins watching and scheduling. It starts scheduling and blocked until the context is done.func (sched *Scheduler) Run(ctx context.Context) { sched.SchedulingQueue.Run() wait.UntilWithContext(ctx, sched.scheduleOne, 0) sched.SchedulingQueue.Close()}继续追踪sched.scheduleOne,sched.scheduleOne调度原理如下:
// C:\git\kubernetes-1.22.3\pkg\scheduler\scheduler.go// scheduleOne 为单个Pod执行完整的调度工作流。// 所有调度逻辑都是串行执行的,保证节点筛选的准确性。func (sched *Scheduler) scheduleOne(ctx context.Context) {// 1. 从调度队列中取出下一个要调度的Pod podInfo := sched.NextPod()// 如果队列为空或Pod已无效,直接退出if podInfo == nil || podInfo.Pod == nil {return } pod := podInfo.Pod// 2. 根据Pod的 spec.schedulerName 找到对应的调度框架Profile fwk, err := sched.frameworkForPod(pod)if err != nil {// 理论上不会走到这里,因为入队的Pod都会匹配到一个profile klog.ErrorS(err, "Error occurred")return }// 3. 判断是否需要跳过本次调度(比如Pod已被删除、已调度等)if sched.skipPodSchedule(fwk, pod) {return } klog.V(3).InfoS("Attempting to schedule pod", "pod", klog.KObj(pod))// ------------------------------// 【调度周期 Scheduling Cycle 开始】// ------------------------------ start := time.Now()// 创建本次调度的上下文状态,存储插件中间数据 state := framework.NewCycleState() state.SetRecordPluginMetrics(rand.Intn(100) < pluginMetricsSamplePercent)// 存储需要被激活的Pod(由插件填充) podsToActivate := framework.NewPodsToActivate() state.Write(framework.PodsToActivateKey, podsToActivate)// 创建调度周期的上下文 schedulingCycleCtx, cancel := context.WithCancel(ctx)defer cancel()// 4. 【核心】调用调度算法:预选(Predicate) + 优选(Priority),选出最优节点 scheduleResult, err := sched.Algorithm.Schedule(schedulingCycleCtx, sched.Extenders, fwk, state, pod)// ------------------------------// 调度失败处理:没有合适节点// ------------------------------if err != nil { nominatedNode := ""// 如果是因为所有节点都不满足(FitError)if fitError, ok := err.(*framework.FitError); ok {// 执行 PostFilter 插件(主要做抢占 Preemption)if fwk.HasPostFilterPlugins() { result, status := fwk.RunPostFilterPlugins(ctx, state, pod, fitError.Diagnosis.NodeToStatusMap)if status.IsSuccess() && result != nil { nominatedNode = result.NominatedNodeName } }// 记录指标:Pod无法调度 metrics.PodUnschedulable(fwk.ProfileName(), metrics.SinceInSeconds(start)) } else if err == ErrNoNodesAvailable {// 没有可用节点 metrics.PodUnschedulable(fwk.ProfileName(), metrics.SinceInSeconds(start)) } else {// 调度出错 klog.ErrorS(err, "Error selecting node for pod", "pod", klog.KObj(pod)) metrics.PodScheduleError(fwk.ProfileName(), metrics.SinceInSeconds(start)) }// 记录失败,将Pod放回队列等待重试 sched.recordSchedulingFailure(fwk, podInfo, err, v1.PodReasonUnschedulable, nominatedNode)return }// 调度算法执行耗时指标 metrics.SchedulingAlgorithmLatency.Observe(metrics.SinceInSeconds(start))// ------------------------------// 5. 【Assume 假定绑定】乐观预占节点资源// 作用:在真正绑定之前,先在缓存里标记Pod已调度到该节点,避免并发调度超配// ------------------------------ assumedPodInfo := podInfo.DeepCopy() assumedPod := assumedPodInfo.Pod// 给Pod设置NodeName,并写入SchedulerCache err = sched.assume(assumedPod, scheduleResult.SuggestedHost)if err != nil { metrics.PodScheduleError(fwk.ProfileName(), metrics.SinceInSeconds(start)) sched.recordSchedulingFailure(fwk, assumedPodInfo, err, SchedulerError, "")return }// ------------------------------// 6. 运行 Reserve 插件:预留节点资源// ------------------------------if sts := fwk.RunReservePluginsReserve(schedulingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost); !sts.IsSuccess() { metrics.PodScheduleError(fwk.ProfileName(), metrics.SinceInSeconds(start))// 失败则回滚资源 fwk.RunReservePluginsUnreserve(schedulingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost) sched.SchedulerCache.ForgetPod(assumedPod) sched.recordSchedulingFailure(fwk, assumedPodInfo, sts.AsError(), SchedulerError, "")return }// ------------------------------// 7. 运行 Permit 插件:允许/等待/拒绝 调度// ------------------------------ runPermitStatus := fwk.RunPermitPlugins(schedulingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost)if runPermitStatus.Code() != framework.Wait && !runPermitStatus.IsSuccess() {// 插件拒绝本次调度,清理资源并重试 metrics.PodScheduleError(fwk.ProfileName(), metrics.SinceInSeconds(start)) fwk.RunReservePluginsUnreserve(schedulingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost) sched.SchedulerCache.ForgetPod(assumedPod) sched.recordSchedulingFailure(fwk, assumedPodInfo, runPermitStatus.AsError(), SchedulerError, "")return }// 如果有需要激活的Pod,激活它们(从backOff队列放回活跃队列)if len(podsToActivate.Map) != 0 { sched.SchedulingQueue.Activate(podsToActivate.Map) podsToActivate.Map = make(map[string]*v1.Pod) }// ------------------------------// 【绑定周期 Binding Cycle 开始】// 异步执行,不阻塞调度主循环// ------------------------------go func() { bindingCycleCtx, cancel := context.WithCancel(ctx)defer cancel() metrics.SchedulerGoroutines.WithLabelValues(metrics.Binding).Inc()defer metrics.SchedulerGoroutines.WithLabelValues(metrics.Binding).Dec()// ------------------------------// 等待 Permit(允许) 插件放行// ------------------------------ waitOnPermitStatus := fwk.WaitOnPermit(bindingCycleCtx, assumedPod)if !waitOnPermitStatus.IsSuccess() { metrics.PodScheduleError(fwk.ProfileName(), metrics.SinceInSeconds(start)) fwk.RunReservePluginsUnreserve(bindingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost) sched.SchedulerCache.ForgetPod(assumedPod) sched.recordSchedulingFailure(fwk, assumedPodInfo, waitOnPermitStatus.AsError(), SchedulerError, "")return }// ------------------------------// 运行 PreBind 插件:绑定前准备// ------------------------------ preBindStatus := fwk.RunPreBindPlugins(bindingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost)if !preBindStatus.IsSuccess() { metrics.PodScheduleError(fwk.ProfileName(), metrics.SinceInSeconds(start)) fwk.RunReservePluginsUnreserve(bindingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost) sched.SchedulerCache.ForgetPod(assumedPod) sched.recordSchedulingFailure(fwk, assumedPodInfo, preBindStatus.AsError(), SchedulerError, "")return }// ------------------------------// 【真正绑定】调用APIServer将Pod绑定到Node// ------------------------------ err := sched.bind(bindingCycleCtx, fwk, assumedPod, scheduleResult.SuggestedHost, state)if err != nil {// 绑定失败:清理资源、重试 metrics.PodScheduleError(fwk.ProfileName(), metrics.SinceInSeconds(start)) fwk.RunReservePluginsUnreserve(bindingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost) sched.SchedulerCache.ForgetPod(assumedPod) sched.recordSchedulingFailure(fwk, assumedPodInfo, fmt.Errorf("binding rejected: %w", err), SchedulerError, "") } else {// ------------------------------// 绑定成功!调度完成// ------------------------------ klog.InfoS("Successfully bound pod to node", "pod", klog.KObj(pod), "node", scheduleResult.SuggestedHost)// 指标统计 metrics.PodScheduled(fwk.ProfileName(), metrics.SinceInSeconds(start)) metrics.PodSchedulingAttempts.Observe(float64(podInfo.Attempts))// 运行 PostBind 插件:绑定后清理 fwk.RunPostBindPlugins(bindingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost) } }()}有三个地方需要特殊关注sched.Algorithm.Schedule,sched.assume,sched.bind三个处理
1.6.1.1、追踪sched.Algorithm.Schedule
整个函数只做 4 件事:
拍快照
把集群节点、资源信息复制一份,防止调度中途数据变化。
预选(
Filter)调用所有过滤插件,筛选出能运行这个
Pod的节点(FeasibleNodes)。没有合格节点 → 调度失败 只剩 1 个合格节点 → 直接用它 优选(
Score)给所有合格节点打分。
选最高分
选出分数最高的节点,封装成
ScheduleResult返回。
// C:\git\kubernetes-1.22.3\pkg\scheduler\generic_scheduler.go// Schedule 尝试将给定的Pod调度到节点列表中的一个。// 成功:返回选中的节点名称// 失败:返回包含失败原因的 FitError 错误func (g *genericScheduler) Schedule(ctx context.Context, extenders []framework.Extender, fwk framework.Framework, state *framework.CycleState, pod *v1.Pod) (result ScheduleResult, err error) {// 调度链路追踪,用于打印耗时日志 trace := utiltrace.New("Scheduling", utiltrace.Field{Key: "namespace", Value: pod.Namespace}, utiltrace.Field{Key: "name", Value: pod.Name})defer trace.LogIfLong(100 * time.Millisecond)// 1. 对节点和Pod信息做内存快照(保证调度过程中数据不变)if err := g.snapshot(); err != nil {return result, err } trace.Step("Snapshotting scheduler cache and node infos done")// 2. 如果集群没有任何节点,直接返回错误if g.nodeInfoSnapshot.NumNodes() == 0 {return result, ErrNoNodesAvailable }// 3. 【预选阶段】调用过滤插件,找出所有 符合条件的节点(FeasibleNodes) feasibleNodes, diagnosis, err := g.findNodesThatFitPod(ctx, extenders, fwk, state, pod)if err != nil {return result, err } trace.Step("Computing predicates done")// 4. 如果没有任何合格节点,返回调度失败(FitError)if len(feasibleNodes) == 0 {return result, &framework.FitError{ Pod: pod, NumAllNodes: g.nodeInfoSnapshot.NumNodes(), Diagnosis: diagnosis, // 记录每个节点为什么不合格 } }// 5. 如果预选后只剩1个节点,直接用它,不用再打分if len(feasibleNodes) == 1 {return ScheduleResult{ SuggestedHost: feasibleNodes[0].Name, // 最终节点 EvaluatedNodes: 1 + len(diagnosis.NodeToStatusMap), // 总评估节点数 FeasibleNodes: 1, // 合格节点数 }, nil }// 6. 【优选阶段】对所有合格节点进行打分 priorityList, err := prioritizeNodes(ctx, extenders, fwk, state, pod, feasibleNodes)if err != nil {return result, err }// 7. 选择分数最高的节点 host, err := g.selectHost(priorityList) trace.Step("Prioritizing done")// 8. 返回调度结果(最终节点、检查过多少节点、合格多少节点)return ScheduleResult{ SuggestedHost: host, EvaluatedNodes: len(feasibleNodes) + len(diagnosis.NodeToStatusMap), FeasibleNodes: len(feasibleNodes), }, err}追踪其中的findNodesThatFitPod,这个方法内部完成了PreFilter和Filter操作
// C:\git\kubernetes-1.22.3\pkg\scheduler\generic_scheduler.go// findNodesThatFitPod// 根据调度框架的 filter 插件和外部扩展器(extender)过滤节点,找到适合当前 Pod 的节点。// 也就是:预选阶段 → 筛选出 Feasible Nodes(合格节点)func (g *genericScheduler) findNodesThatFitPod( ctx context.Context, extenders []framework.Extender, fwk framework.Framework, state *framework.CycleState, pod *v1.Pod,) ([]*v1.Node, framework.Diagnosis, error) {// 初始化诊断信息:记录每个节点为什么不合格、哪个插件导致调度失败 diagnosis := framework.Diagnosis{ NodeToStatusMap: make(framework.NodeToStatusMap), // key:节点名 value:失败原因 UnschedulablePlugins: sets.NewString(), // 导致不可调度的插件列表 }// 1. 运行 PreFilter 插件(预过滤,准备工作) // 提前计算 Pod 亲和性、拓扑等信息,给后面过滤阶段提速 s := fwk.RunPreFilterPlugins(ctx, state, pod)// 获取当前集群所有节点的快照列表 allNodes, err := g.nodeInfoSnapshot.NodeInfos().List()if err != nil {return nil, diagnosis, err }// 如果 PreFilter 直接失败if !s.IsSuccess() {// 如果不是“不可调度”错误,直接返回真正的错误if !s.IsUnschedulable() {return nil, diagnosis, s.AsError() }// PreFilter 判定 Pod 无法调度 → 所有节点都标记为失败for _, n := range allNodes { diagnosis.NodeToStatusMap[n.Node().Name] = s }// 记录是哪个插件导致的失败 diagnosis.UnschedulablePlugins.Insert(s.FailedPlugin())// 返回空合格节点列表return nil, diagnosis, nil }// 2. 优先检查“提名节点”(Nominated Node)优化 // "NominatedNodeName" 可能是在之前的调度周期中,由于抢占机制而被设置的。// 这个节点很可能是唯一适合该 Pod 的节点,因此我们在遍历所有节点之前,优先尝试这个节点。if len(pod.Status.NominatedNodeName) > 0 && feature.DefaultFeatureGate.Enabled(features.PreferNominatedNode) {// 只检查提名的那一个节点 feasibleNodes, err := g.evaluateNominatedNode(ctx, extenders, pod, fwk, state, diagnosis)if err != nil { klog.ErrorS(err, "Evaluation failed on nominated node", "pod", klog.KObj(pod), "node", pod.Status.NominatedNodeName) }// 如果提名节点合格 → 直接返回,不再检查其他节点if len(feasibleNodes) != 0 {return feasibleNodes, diagnosis, nil } }// 3. 【核心】过滤所有节点:运行内置 Filter 插件 // 遍历所有节点,执行 Filter 插件(如资源、污点、亲和性、端口等检查)// 筛选出通过所有内置插件的节点 feasibleNodes, err := g.findNodesThatPassFilters(ctx, fwk, state, pod, diagnosis, allNodes)if err != nil {return nil, diagnosis, err }// 4. 再次过滤:通过外部 Extender 扩展器检查 // 让外部扩展器再过滤一遍(自定义调度逻辑) feasibleNodes, err = findNodesThatPassExtenders(extenders, pod, feasibleNodes, diagnosis.NodeToStatusMap)if err != nil {return nil, diagnosis, err }// 5. 返回最终合格节点 + 诊断信息 return feasibleNodes, diagnosis, nil}追踪g.evaluateNominatedNode
// C:\git\kubernetes-1.22.3\pkg\scheduler\generic_scheduler.go// evaluateNominatedNode// 作用:**只检查 Pod 提名的那个节点(NominatedNodeName),看看能不能用**// 目的:如果这个节点能用,就直接用,不用检查所有节点,调度更快!func (g *genericScheduler) evaluateNominatedNode( ctx context.Context, extenders []framework.Extender, pod *v1.Pod, fwk framework.Framework, state *framework.CycleState, diagnosis framework.Diagnosis,) ([]*v1.Node, error) {// 1. 拿到 Pod 的【提名节点名字】// 也就是 pod.Status.NominatedNodeName(之前抢占时标记的节点) nnn := pod.Status.NominatedNodeName// 2. 从缓存里拿到这个提名节点的信息 nodeInfo, err := g.nodeInfoSnapshot.Get(nnn)if err != nil {return nil, err // 节点不存在,直接返回错误 }// 包装成列表,只检查这一个节点 node := []*framework.NodeInfo{nodeInfo}// 3. 【核心】只检查这一个节点是否合格// 调用你刚才学的 findNodesThatPassFilters// 检查:资源、污点、亲和性、两遍 Nominated Pod 安全检查 feasibleNodes, err := g.findNodesThatPassFilters(ctx, fwk, state, pod, diagnosis, node)if err != nil {return nil, err }// 4. 再让外部扩展器检查一下这个节点 feasibleNodes, err = findNodesThatPassExtenders(extenders, pod, feasibleNodes, diagnosis.NodeToStatusMap)if err != nil {return nil, err }// 5. 如果合格,返回这个节点// 调度器就会直接用它,不再检查其他节点return feasibleNodes, nil}追踪findNodesThatPassFilters
// C:\git\kubernetes-1.22.3\pkg\scheduler\generic_scheduler.go// findNodesThatPassFilters 核心作用:// 遍历所有节点,通过 Filter 插件检查,筛选出【能运行当前 Pod】的合格节点(Feasible Nodes)func (g *genericScheduler) findNodesThatPassFilters( ctx context.Context, fwk framework.Framework, state *framework.CycleState, pod *v1.Pod, diagnosis framework.Diagnosis, nodes []*framework.NodeInfo) ([]*v1.Node, error) { numNodesToFind := g.numFeasibleNodesToFind(int32(len(nodes)))// Create feasible list with enough space to avoid growing it// and allow assigning. feasibleNodes := make([]*v1.Node, numNodesToFind)if !fwk.HasFilterPlugins() { length := len(nodes)for i := range feasibleNodes { feasibleNodes[i] = nodes[(g.nextStartNodeIndex+i)%length].Node() } g.nextStartNodeIndex = (g.nextStartNodeIndex + len(feasibleNodes)) % lengthreturn feasibleNodes, nil } errCh := parallelize.NewErrorChannel()var statusesLock sync.Mutexvar feasibleNodesLen int32 ctx, cancel := context.WithCancel(ctx) checkNode := func(i int) {// We check the nodes starting from where we left off in the previous scheduling cycle,// this is to make sure all nodes have the same chance of being examined across pods. nodeInfo := nodes[(g.nextStartNodeIndex+i)%len(nodes)] status := fwk.RunFilterPluginsWithNominatedPods(ctx, state, pod, nodeInfo)if status.Code() == framework.Error { errCh.SendErrorWithCancel(status.AsError(), cancel)return }if status.IsSuccess() { length := atomic.AddInt32(&feasibleNodesLen, 1)if length > numNodesToFind { cancel() atomic.AddInt32(&feasibleNodesLen, -1) } else { feasibleNodes[length-1] = nodeInfo.Node() } } else { statusesLock.Lock() diagnosis.NodeToStatusMap[nodeInfo.Node().Name] = status diagnosis.UnschedulablePlugins.Insert(status.FailedPlugin()) statusesLock.Unlock() } } beginCheckNode := time.Now() statusCode := framework.Successdefer func() {// We record Filter extension point latency here instead of in framework.go because framework.RunFilterPlugins// function is called for each node, whereas we want to have an overall latency for all nodes per scheduling cycle.// Note that this latency also includes latency for `addNominatedPods`, which calls framework.RunPreFilterAddPod. metrics.FrameworkExtensionPointDuration.WithLabelValues(runtime.Filter, statusCode.String(), fwk.ProfileName()).Observe(metrics.SinceInSeconds(beginCheckNode)) }()// Stops searching for more nodes once the configured number of feasible nodes// are found. fwk.Parallelizer().Until(ctx, len(nodes), checkNode) processedNodes := int(feasibleNodesLen) + len(diagnosis.NodeToStatusMap) g.nextStartNodeIndex = (g.nextStartNodeIndex + processedNodes) % len(nodes) feasibleNodes = feasibleNodes[:feasibleNodesLen]if err := errCh.ReceiveError(); err != nil { statusCode = framework.Errorreturn nil, err }return feasibleNodes, nil}追踪fwk.RunFilterPluginsWithNominatedPods
// C:\git\kubernetes-1.22.3\pkg\scheduler\framework\runtime\framework.go// RunFilterPluginsWithNominatedPods// 作用:在【抢占场景】下对节点做 Filter 检查// 专门处理:这个节点上有 **Nominated Pod(提名Pod,等待抢占的高优先级Pod)**func (f *frameworkImpl) RunFilterPluginsWithNominatedPods( ctx context.Context, state *framework.CycleState, pod *v1.Pod, info *framework.NodeInfo,) *framework.Status {var status *framework.Status podsAdded := false // 是否真的添加了 Nominated Pod 进行模拟// ==============================// 核心:最多执行【两遍过滤】// ==============================for i := 0; i < 2; i++ { stateToUse := state nodeInfoToUse := info// ==============================// 第一遍检查(i=0)// 把节点上的 **Nominated Pod 假装已经运行**// ==============================if i == 0 {var err error// 把节点上【同优先级 / 更高优先级】的 Nominated Pod// 临时加到节点里,模拟它们已经占用资源 podsAdded, stateToUse, nodeInfoToUse, err = addNominatedPods(ctx, f, pod, state, info)if err != nil {return framework.AsStatus(err) } } else if !podsAdded || !status.IsSuccess() {// 如果没有 Nominated Pod,或者第一遍失败,就不跑第二遍break }// 执行所有 Filter 插件(NodeName、资源、污点、亲和性等) statusMap := f.RunFilterPlugins(ctx, stateToUse, pod, nodeInfoToUse) status = statusMap.Merge()// 如果出现系统错误(不是普通不可调度),直接返回if !status.IsSuccess() && !status.IsUnschedulable() {return status } }// 返回最终检查结果return status}Nominated Pod(提名Pod)和Victim Pod(牺牲Pod)是 Kubernetes 调度器在Pod优先级与抢占(Preemption)机制中使用的两个关键角色:
Nominated Pod(提名Pod):指一个高优先级Pod因资源不足调度失败后,被调度器 “提名” 到某个节点(设置.status.nominatedNodeName)以等待低优先级Pod被驱逐。它尚未实际运行在该节点上,只是表达 “意图” 在资源释放后优先调度至此;提名不保证最终调度成功(更高优先级Pod可能后来居上,覆盖这个节点的提名)。Victim Pod(牺牲Pod):指被高优先级抢占者选中、将在该节点上被优雅终止(graceful termination)以释放资源的低优先级Pod,由调度器的DefaultPreemption插件根据优先级和驱逐策略选出。
两者完整抢占流程:高优先级Pod(抢占者)→ 遍历节点计算可驱逐资源,选中目标节点并标记自身为Nominated Pod → 在该节点筛选低优先级Pod作为Victim Pod → 下发删除指令给所有Victim Pod → 等待Victim Pod走完优雅终止周期、释放资源后,Nominated Pod才有可能被真正调度绑定节点。
上面代码的,RunFilterPluginsWithNominatedPods是抢占场景下的双重验证
因为
Nominated Pod是不确定的:
它们还没真正运行 它们可能最终调度到别的节点 它们也可能真的运行在这个节点 所以调度器必须 保守判断:
第一遍检查:假设
Nominated Pod真的会来这个节点
把它们假装加到节点上 占用资源 检查当前 Pod还能不能放下第二遍检查:假设
Nominated Pod最终不来这个节点
不把它们加进来 再检查一遍当前 Pod能不能放下两遍都通过 → 节点安全,任意一遍不通过 → 节点不安全
继续追踪statusMap := f.RunFilterPlugins(ctx, stateToUse, pod, nodeInfoToUse)
// C:\git\kubernetes-1.22.3\pkg\scheduler\framework\runtime\framework.go// RunFilterPlugins runs the set of configured Filter plugins for pod on// the given node. If any of these plugins doesn't return "Success", the// given node is not suitable for running pod.// Meanwhile, the failure message and status are set for the given node.// RunFilterPlugins// 作用:对 一个节点 运行 所有 Filter 插件// 返回结果:每个插件的通过/失败状态func (f *frameworkImpl) RunFilterPlugins( ctx context.Context, state *framework.CycleState, // 调度上下文 pod *v1.Pod, // 要调度的Pod nodeInfo *framework.NodeInfo, // 当前正在检查的节点) framework.PluginToStatus {// 用来保存:每个插件 -> 检查结果(成功/失败) statuses := make(framework.PluginToStatus)// 遍历所有注册的 Filter 插件// 例如:NodeName、资源检查、污点检查、亲和性检查、端口检查...for _, pl := range f.filterPlugins {// 【核心】运行当前这个插件的过滤逻辑(runFilterPlugin) pluginStatus := f.runFilterPlugin(ctx, pl, state, pod, nodeInfo)// ------------------------------// 如果插件执行结果 != 成功// ------------------------------if !pluginStatus.IsSuccess() {// 如果不是“不可调度”,而是真正的错误(比如崩溃、异常)if !pluginStatus.IsUnschedulable() {// 构造错误信息,标记是哪个插件挂了 errStatus := framework.AsStatus(fmt.Errorf("running %q filter plugin: %w", pl.Name(), pluginStatus.AsError())).WithFailedPlugin(pl.Name())// 直接返回错误,终止所有检查return map[string]*framework.Status{pl.Name(): errStatus} }// 标记:是哪个插件导致的失败 pluginStatus.SetFailedPlugin(pl.Name())// 把失败结果存起来 statuses[pl.Name()] = pluginStatus// 如果配置了【不需要跑完所有插件】// 只要有一个插件失败,立刻停止,直接返回结果(性能优化)if !f.runAllFilters {return statuses } } }// 所有插件都通过了,返回空(或全部成功)return statuses}追踪runFilterPlugin
// C:\git\kubernetes-1.22.3\pkg\scheduler\framework\runtime\framework.go// runFilterPlugin// 调度框架统一执行 Filter 插件的方法// 作用:调用具体插件的 Filter 逻辑,并统一处理指标统计func (f *frameworkImpl) runFilterPlugin( ctx context.Context, pl framework.FilterPlugin, // 具体要执行的插件,例如 NodeName、TaintToleration state *framework.CycleState, pod *v1.Pod, nodeInfo *framework.NodeInfo,) *framework.Status {// 如果不需要记录插件监控指标// 直接调用插件的 Filter 方法,返回结果if !state.ShouldRecordPluginMetrics() {return pl.Filter(ctx, state, pod, nodeInfo) }// ===================== 下面是需要记录指标的情况 =====================// 记录插件开始执行时间 startTime := time.Now()// 【真正执行】调用具体插件的 Filter 方法(比如 NodeName.Filter())// 检查 Pod 是否能调度到当前节点 status := pl.Filter(ctx, state, pod, nodeInfo)// 异步记录插件执行耗时(成功/失败 耗时) f.metricsRecorder.observePluginDurationAsync(Filter, pl.Name(), status, metrics.SinceInSeconds(startTime))// 返回过滤结果(成功 / 不可调度 / 错误)return status}追踪其中的pl.Filter,可以看到有下面的这些过滤插件,都实现了Filter方法
拿出其中的一个最简单的NodeName的Filter去看看具体是如何实现的
// C:\git\kubernetes-1.22.3\pkg\scheduler\framework\plugins\nodename\node_name.go// Name 返回插件名称,用于日志、识别插件func (pl *NodeName) Name() string {return Name}// Filter 是插件的核心方法// 作用:判断当前 Pod 是否**允许**调度到当前节点// 调度器在预选阶段(Filter)会调用它func (pl *NodeName) Filter(ctx context.Context, _ *framework.CycleState, pod *v1.Pod, nodeInfo *framework.NodeInfo) *framework.Status {// 如果节点信息不存在,返回错误if nodeInfo.Node() == nil {return framework.NewStatus(framework.Error, "node not found") }// 调用 Fits() 检查:Pod 是否能放到这个节点if !Fits(pod, nodeInfo) {// 不满足 → 返回“不可调度”状态return framework.NewStatus(framework.UnschedulableAndUnresolvable, ErrReason) }// 满足条件 → 允许调度,返回 nilreturn nil}// Fits 真正的检查逻辑// 检查 Pod 是否允许调度到当前节点func Fits(pod *v1.Pod, nodeInfo *framework.NodeInfo)bool {// 满足两个条件之一就算匹配:// 1. Pod 没有指定 nodeName(可以随便调度)// 2. Pod 指定了 nodeName,且和当前节点名字一样return len(pod.Spec.NodeName) == 0 || pod.Spec.NodeName == nodeInfo.Node().Name}// New 创建插件实例func New(_ runtime.Object, _ framework.Handle) (framework.Plugin, error) {return &NodeName{}, nil}追踪NodeName其中的New方法,也就是这个过滤插件被创建的地方
// C:\git\kubernetes-1.22.3\pkg\scheduler\framework\plugins\registry.go// NewInTreeRegistry builds the registry with all the in-tree plugins.// A scheduler that runs out of tree plugins can register additional plugins// through the WithFrameworkOutOfTreeRegistry option.func NewInTreeRegistry() runtime.Registry { fts := plfeature.Features{ EnablePodAffinityNamespaceSelector: feature.DefaultFeatureGate.Enabled(features.PodAffinityNamespaceSelector), EnablePodDisruptionBudget: feature.DefaultFeatureGate.Enabled(features.PodDisruptionBudget), EnablePodOverhead: feature.DefaultFeatureGate.Enabled(features.PodOverhead), EnableReadWriteOncePod: feature.DefaultFeatureGate.Enabled(features.ReadWriteOncePod), }return runtime.Registry{ selectorspread.Name: selectorspread.New, imagelocality.Name: imagelocality.New, tainttoleration.Name: tainttoleration.New,// 这里注册了nodename过滤插件 nodename.Name: nodename.New, nodeports.Name: nodeports.New, nodepreferavoidpods.Name: nodepreferavoidpods.New, nodeaffinity.Name: nodeaffinity.New, podtopologyspread.Name: podtopologyspread.New, nodeunschedulable.Name: nodeunschedulable.New, noderesources.FitName: func(plArgs apiruntime.Object, fh framework.Handle) (framework.Plugin, error) {return noderesources.NewFit(plArgs, fh, fts) }, noderesources.BalancedAllocationName: func(plArgs apiruntime.Object, fh framework.Handle) (framework.Plugin, error) {return noderesources.NewBalancedAllocation(plArgs, fh, fts) }, noderesources.MostAllocatedName: func(plArgs apiruntime.Object, fh framework.Handle) (framework.Plugin, error) {return noderesources.NewMostAllocated(plArgs, fh, fts) }, noderesources.LeastAllocatedName: func(plArgs apiruntime.Object, fh framework.Handle) (framework.Plugin, error) {return noderesources.NewLeastAllocated(plArgs, fh, fts) }, noderesources.RequestedToCapacityRatioName: func(plArgs apiruntime.Object, fh framework.Handle) (framework.Plugin, error) {return noderesources.NewRequestedToCapacityRatio(plArgs, fh, fts) }, volumebinding.Name: volumebinding.New, volumerestrictions.Name: func(plArgs apiruntime.Object, fh framework.Handle) (framework.Plugin, error) {return volumerestrictions.New(plArgs, fh, fts) }, volumezone.Name: volumezone.New, nodevolumelimits.CSIName: nodevolumelimits.NewCSI, nodevolumelimits.EBSName: nodevolumelimits.NewEBS, nodevolumelimits.GCEPDName: nodevolumelimits.NewGCEPD, nodevolumelimits.AzureDiskName: nodevolumelimits.NewAzureDisk, nodevolumelimits.CinderName: nodevolumelimits.NewCinder, interpodaffinity.Name: func(plArgs apiruntime.Object, fh framework.Handle) (framework.Plugin, error) {return interpodaffinity.New(plArgs, fh, fts) }, nodelabel.Name: nodelabel.New, serviceaffinity.Name: serviceaffinity.New, queuesort.Name: queuesort.New, defaultbinder.Name: defaultbinder.New, defaultpreemption.Name: func(plArgs apiruntime.Object, fh framework.Handle) (framework.Plugin, error) {return defaultpreemption.New(plArgs, fh, fts) }, }}继续追踪NewInTreeRegistry,这里又回到了之前分析过的New方法,其中注册了所有的过滤插件。
// C:\git\kubernetes-1.22.3\pkg\scheduler\scheduler.go// New returns a Schedulerfunc New(client clientset.Interface, informerFactory informers.SharedInformerFactory, recorderFactory profile.RecorderFactory, stopCh <-chan struct{}, opts ...Option) (*Scheduler, error) {// 这里注册了所有过滤插件 registry := frameworkplugins.NewInTreeRegistry()if err := registry.Merge(options.frameworkOutOfTreeRegistry); err != nil {return nil, err } configurator := &Configurator{ registry: registry, } addAllEventHandlers(sched, informerFactory, dynInformerFactory, unionedGVKs(clusterEventMap))return sched, nil}1.6.1.2、追踪sched.assume
// C:\git\kubernetes-1.22.3\pkg\scheduler\scheduler.go// assume 向调度缓存发送信号:假定这个Pod已经绑定到节点了。// 目的是让后续的绑定操作可以异步进行,不阻塞调度循环。// 注意:这个函数会直接修改传入的 assumed 对象func (sched *Scheduler) assume(assumed *v1.Pod, host string) error {// 【关键步骤1】给Pod强行设置目标节点名称// 乐观假设:绑定一定会成功,先把NodeName写上// 这样后续调度就会认为这个Pod已经在这个节点上了 assumed.Spec.NodeName = host// 【关键步骤2】把这个“假定已调度”的Pod存入调度缓存// 缓存会更新节点的资源占用(CPU/内存/端口),相当于预占资源// 防止其他Pod同时被调度到同一个节点,导致资源超卖if err := sched.SchedulerCache.AssumePod(assumed); err != nil { klog.ErrorS(err, "scheduler cache AssumePod failed")return err }// 【清理工作】如果这个Pod之前是被“提名”的抢占Pod,现在调度成功,从队列里删掉if sched.SchedulingQueue != nil { sched.SchedulingQueue.DeleteNominatedPodIfExists(assumed) }return nil}继续追踪sched.SchedulerCache.AssumePod
// C:\git\kubernetes-1.22.3\pkg\scheduler\internal\cache\cache.go// schedulerCache 调度器本地内存缓存// 作用:保存节点、Pod、资源的最新状态,让调度器不用每次都请求 apiserver// 是调度器高性能的核心:所有预选、优选、资源计算都读这个缓存type schedulerCache struct {// 关闭调度器的信号通道 stop <-chan struct{}// 假定Pod(Assumed Pod)的过期时间// 如果一个Pod假定绑定后,太久没真正Bind,就会自动清理 ttl time.Duration// 后台定期清理过期Pod的周期 period time.Duration// 全局互斥锁:保证多协程并发操作缓存时安全// 保护下面所有字段 mu sync.RWMutex// 【假定Pod集合】// 存储所有处于 Assume 状态(还没真正Bind)的Pod的key// 作用:快速区分哪些Pod是“假调度”,哪些是真绑定 assumedPods sets.String// Pod状态映射表:key=pod唯一标识,value=pod状态// 记录每个Pod是 假定/已绑定/待删除 状态 podStates map[string]*podState// 节点信息映射表:key=节点名,value=节点完整信息(资源、Pod列表) nodes map[string]*nodeInfoListItem// 最近更新过的节点(链表头)// 频繁变动的节点放头部,加速访问(调度器性能优化) headNode *nodeInfoListItem// 节点树:用于根据标签、亲和性快速筛选节点 nodeTree *nodeTree// 镜像缓存:记录每个节点上有哪些镜像,加速调度决策 imageStates map[string]*imageState}// podState:调度器缓存中,记录【单个 Pod 的状态】// 主要用来管理 Assume(假定)状态的 Pod:是否过期、是否绑定完成type podState struct {// 指向真实的 Pod 对象 pod *v1.Pod// 过期截止时间// 作用:给 Assume 状态的 Pod 设置“有效期”// 如果超过这个时间还没完成绑定,就认为这个 Assume 失效,需要清理 deadline *time.Time// 标记:绑定是否已经完成// 作用:// 1. 如果还在绑定中(bindingFinished=false)→ 不能清理这个 Pod// 2. 如果绑定已经完成(bindingFinished=true)→ 可以正常处理 bindingFinished bool}// nodeInfoListItem holds a NodeInfo pointer and acts as an item in a doubly// linked list. When a NodeInfo is updated, it goes to the head of the list.// The items closer to the head are the most recently updated items.type nodeInfoListItem struct { info *framework.NodeInfo next *nodeInfoListItem prev *nodeInfoListItem}继续追踪schedulerCache.AssumePod
// C:\git\kubernetes-1.22.3\pkg\scheduler\internal\cache\cache.go// AssumePod// 作用:将一个【假定已调度】的 Pod 加入调度缓存// 逻辑:标记这个 Pod 已经占用了节点资源,防止其他 Pod 重复调度func (cache *schedulerCache) AssumePod(pod *v1.Pod) error {// 1. 获取 Pod 的唯一标识 key(namespace/name) key, err := framework.GetPodKey(pod)if err != nil {return err }// 2. 加锁:保证并发安全(调度器多协程操作缓存) cache.mu.Lock()defer cache.mu.Unlock()// 3. 检查 Pod 已经存在 → 不能重复 Assumeif _, ok := cache.podStates[key]; ok {return fmt.Errorf("pod %v is in the cache, so can't be assumed", key) }// 4. 【核心】把 Pod 加入节点,更新节点的资源占用 cache.addPod(pod)// 5. 记录 Pod 状态:标记为【假定】状态 ps := &podState{ pod: pod, } cache.podStates[key] = ps// 6. 把 Pod 标记为【假定 Pod】(和真实已绑定 Pod 区分开) cache.assumedPods.Insert(key)return nil}// C:\git\kubernetes-1.22.3\pkg\scheduler\internal\cache\cache.go// addPod// 作用:将 Pod 挂载到对应节点,更新节点信息(已加锁)func (cache *schedulerCache) addPod(pod *v1.Pod) {// 1. 根据 NodeName 找到节点 n, ok := cache.nodes[pod.Spec.NodeName]// 2. 节点不存在就新建一个if !ok { n = newNodeInfoListItem(framework.NewNodeInfo()) cache.nodes[pod.Spec.NodeName] = n }// 3. 【核心】把 Pod 加到节点上,更新节点资源 n.info.AddPod(pod)// 4. 把节点移到链表头部:提升下次调度查询速度 cache.moveNodeInfoToHead(pod.Spec.NodeName)}// C:\git\kubernetes-1.22.3\pkg\scheduler\framework\types.go// AddPod// 包装函数,简化调用func (n *NodeInfo) AddPod(pod *v1.Pod) { n.AddPodInfo(NewPodInfo(pod))}// C:\git\kubernetes-1.22.3\pkg\scheduler\framework\types.go// AddPodInfo// 【最底层核心】把 Pod 资源计入节点,更新节点所有资源信息func (n *NodeInfo) AddPodInfo(podInfo *PodInfo) {// 1. 计算这个 Pod 需要的所有资源:CPU、内存、存储、GPU等 res, non0CPU, non0Mem := calculateResource(podInfo.Pod)// 2. 把 Pod 资源【累加到节点已用资源】上 n.Requested.MilliCPU += res.MilliCPU // 节点已用 CPU n.Requested.Memory += res.Memory // 节点已用内存 n.Requested.EphemeralStorage += res.EphemeralStorage // 节点已用存储// 累加自定义资源(GPU、RDMA 等)for rName, rQuant := range res.ScalarResources { n.Requested.ScalarResources[rName] += rQuant }// 3. 记录非零资源(调度算法需要) n.NonZeroRequested.MilliCPU += non0CPU n.NonZeroRequested.Memory += non0Mem// 4. 把 Pod 加入节点的 Pod 列表 n.Pods = append(n.Pods, podInfo)// 5. 如果 Pod 有亲和性/反亲和性,单独记录if podWithAffinity(podInfo.Pod) { n.PodsWithAffinity = append(n.PodsWithAffinity, podInfo) }if podWithRequiredAntiAffinity(podInfo.Pod) { n.PodsWithRequiredAntiAffinity = append(n.PodsWithRequiredAntiAffinity, podInfo) }// 6. 更新节点已占用端口、PVC引用计数 n.updateUsedPorts(podInfo.Pod, true) n.updatePVCRefCounts(podInfo.Pod, true)// 7. 节点版本+1,代表节点资源发生变化 n.Generation = nextGeneration()}至此完成了Assume验证解读
1.6.1.3、追踪sched.bind
// C:\git\kubernetes-1.22.3\pkg\scheduler\scheduler.go// bind 真正将 Pod 绑定到目标节点// 绑定优先级:1. 外部扩展器(extenders) 优先 2. 框架插件(framework plugins)// 这个函数会**异步执行**,不阻塞调度主循环func (sched *Scheduler) bind(ctx context.Context, fwk framework.Framework, assumed *v1.Pod, targetNode string, state *framework.CycleState) (err error) {// 【收尾函数】无论绑定成功/失败,最后都会执行 finishBinding// 作用:更新缓存状态、记录指标、清理资源defer func() { sched.finishBinding(fwk, assumed, targetNode, err) }()// 1. 先尝试让【外部扩展器 Extenders】执行绑定// 如果 Extenders 处理了绑定(bound=true),直接返回结果 bound, err := sched.extendersBinding(assumed, targetNode)if bound {return err }// 2. 扩展器没处理 → 执行【框架内置 Bind 插件】// 真正向 kube-apiserver 发送绑定请求,将 Pod 与 Node 绑定 bindStatus := fwk.RunBindPlugins(ctx, state, assumed, targetNode)// 绑定成功 → 返回 nilif bindStatus.IsSuccess() {return nil }// 绑定失败 → 返回错误if bindStatus.Code() == framework.Error {return bindStatus.AsError() }// 其他异常情况return fmt.Errorf("bind status: %s, %v", bindStatus.Code().String(), bindStatus.Message())}追踪sched.extendersBinding
// C:\git\kubernetes-1.22.3\pkg\scheduler\scheduler.go// TODO(#87159): Move this to a Plugin.func (sched *Scheduler) extendersBinding(pod *v1.Pod, node string) (bool, error) {for _, extender := range sched.Extenders {if !extender.IsBinder() || !extender.IsInterested(pod) {continue }return true, extender.Bind(&v1.Binding{ ObjectMeta: metav1.ObjectMeta{Namespace: pod.Namespace, Name: pod.Name, UID: pod.UID}, Target: v1.ObjectReference{Kind: "Node", Name: node}, }) }return false, nil}继续追踪extender.Bind
// C:\git\kubernetes-1.22.3\pkg\scheduler\extender.go// Bind 将 Pod 绑定到节点的操作 委托给外部扩展器(extender) 去执行// 也就是说:不自己绑定,而是发请求让外部服务完成绑定func (h *HTTPExtender) Bind(binding *v1.Binding) error {// 定义外部扩展器的绑定结果结构体var result extenderv1.ExtenderBindingResult// 如果当前扩展器没有开启绑定能力(不是binder),直接报错// 理论上不会走到这里,因为只有配置了bind能力才会调用if !h.IsBinder() {return fmt.Errorf("unexpected empty bindVerb in extender") }// 构造要发送给外部扩展器的参数// 包含:Pod名字、命名空间、Pod唯一ID、目标节点 req := &extenderv1.ExtenderBindingArgs{ PodName: binding.Name, PodNamespace: binding.Namespace, PodUID: binding.UID, Node: binding.Target.Name, }// 【核心】发送 HTTP 请求给外部扩展器// 让外部服务去执行真正的 Pod 绑定操作if err := h.send(h.bindVerb, req, &result); err != nil {return err }// 如果外部扩展器返回了错误信息,则返回错误if result.Error != "" {return fmt.Errorf(result.Error) }// 外部扩展器绑定成功return nil}这里发出了HTTP 请求给apiserver,让外部服务去执行真正的 Pod 绑定操作。
1.7、参考文献:
https://midbai.com/post/kubernete-event/
https://cloud.tencent.com/developer/article/1731747
https://cloud.tencent.com.cn/developer/article/2623224https://kubernetes.io/zh-cn/docs/reference/scheduling/config/
https://kubernetes.io/zh-cn/docs/reference/scheduling/config/
