项目地址:https://www.github.com/foxBMS/foxbms-2- 状态机会根据请求和诊断结果决定是否预充、闭合接触器或退出运行。
但一个成熟的 BMS 不能默认这些结果永远可信,FoxBMS2 在这方面做得很彻底,它专门用几层不同性质的检查,把异常输入逐步转成系统级故障:- Plausibility:同一类测量值之间是否自洽。
- SOA:即便没有越绝对阈值,当前工作点是否仍在安全工作区。
- DIAG:统一管理阈值、防抖、回调、fatal error 和对外广播。
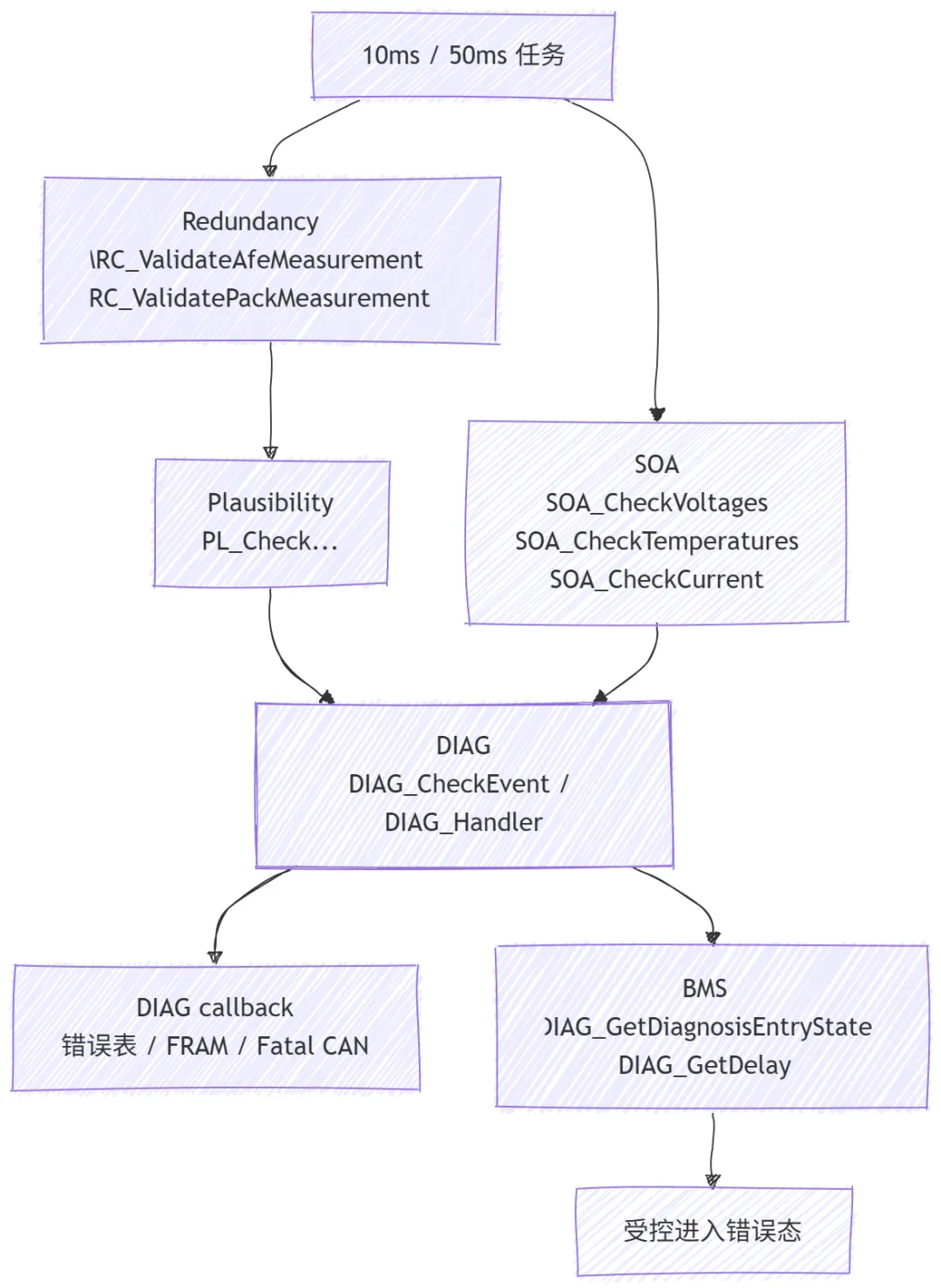
1.1 先用一张图看清谁发现、谁定性、谁执行退出
2. Plausibility
2.1 它不是独立调度的大模块,而是一组被调用的检查函数
如果只看文件名,很容易以为 plausibility.c 自己就是一条独立安全链,但当前仓库里更准确的理解是:- plausibility.c 提供 PL_CheckStringVoltage()、PL_CheckCellVoltage()、PL_CheckCellTemperature()、PL_CheckVoltageSpread()、PL_CheckTemperatureSpread() 这些检查函数。
- 它们主要在 redundancy.c 的校验路径里被调用。
- 检查结果会立刻通过 DIAG_CheckEvent() 进入 DIAG,而不是停留在本地模块内部。
所以从执行关系看,Plausibility 更像被 Redundancy 和测量校验链调用的一组判断器,而不是一个单独周期任务。2.2 当前实现里它主要做 4 类事
从源码能直接确认的 Plausibility 角色,主要有下面 4 类:- 比较 AFE 簇电压和电流传感器高压测量是否接近。
- 比较 base / redundancy0 两份 cell 电压是否一致;如果一致,输出两者平均值。
- 比较 base / redundancy0 两份 cell 温度是否一致;如果一致,输出两者平均值。
- 在已生成的有效 cell 表上,检查单体值与簇平均值的偏差是否超过 spread 容差。
这四类检查的配置分别来自 plausibility_cfg.h,例如:- PL_STRING_VOLTAGE_TOLERANCE_mV = 3000
- PL_CELL_VOLTAGE_TOLERANCE_mV = 10
- PL_CELL_TEMPERATURE_TOLERANCE_dK = 50
- PL_CELL_VOLTAGE_SPREAD_TOLERANCE_mV = 300
- PL_CELL_TEMPERATURE_SPREAD_TOLERANCE_dK = 100
2.3 Spread 检查不只是报错,还会把条目直接判成无效
这一点很值得单独强调。PL_CheckVoltageSpread() 和 PL_CheckTemperatureSpread() 不只是报个 warning 然后继续用原值,而是会:- 把偏离平均值过大的 cell 项直接标成 invalid;
- 然后由 Redundancy 重新计算 min / max / average;
- 同时通过 DIAG_CheckEvent() 更新对应的 Plausibility 诊断项。
所以这里的 Plausibility 会直接影响后续哪些测量值还能继续参与系统判断。3. Redundancy
3.1 Cell 冗余校验先查新鲜度,再决定是否比较
MRC_ValidateCellVoltageMeasurement() 和 MRC_ValidateCellTemperatureMeasurement() 的入口逻辑很清楚:- 先用 DATA_DatabaseEntryUpdatedAtLeastOnce() 判断 redundancy0 这条链是不是启用过;
- 再用 DATA_EntryUpdatedWithinInterval() 判断 base / redundancy0 是否超时;
- 再比较当前时间戳和上次处理时间戳,确认这次是否真的拿到了新样本。
只有当 base 和 redundancy0 两边都更新过时,才会进入真正的双路比对。3.2 如果只有一边更新,且另一边已超时,模块会降级使用单路值
这也是这套实现最像工程系统、而不是教科书伪代码的地方。- 如果只有 base 更新,而 redundancy0 已超时,就用 base 更新 validated 表;
- 如果只有 redundancy0 更新,而 base 已超时,就用 redundancy0 更新 validated 表;
- 同时把对应 timeout 诊断项送进 DIAG。
这说明 Redundancy 模块真正维护的是当前哪些值还能可信地继续维持系统运行,而不是执着于两路必须永远同时存在。3.3 Pack 级校验把 Plausibility、降级和重建混在了一起
MRC_ValidatePackMeasurement() 之后的 pack 校验更能体现这点:- MRC_ValidateCurrentMeasurement() 先检查电流测量是否及时、是否有效;
- MRC_ValidateStringVoltageMeasurement() 再把 AFE 簇电压与 current sensor 高压测量做 Plausibility 检查;
- 如果二者都不够完整,代码还会基于有效 cell 数和平均 cell 电压重建近似簇电压;
- 只有当无效单体数超过 MRC_ALLOWED_NUMBER_OF_INVALID_CELL_VOLTAGES 时,才把簇电压标成 invalid。
所以这里的 Redundancy 不是比较两个值然后二选一,而是一条包含 freshness、Plausibility、降级与估算重建的完整链路。3.4 这条链的真实任务上下文在 10ms 线程里,每 50ms 触发一次
- Redundancy 在初始化阶段先执行 MRC_Initialize();
- 其中 MRC_ValidateAfeMeasurement() 和 MRC_ValidatePackMeasurement() 每经过 5 个 10ms 周期执行一次,也就是 50ms 一次。
4. SOA:把当前运行点翻译成诊断事件
4.1 当前实现里,SOA 是 BMS 10ms 的一部分
BMS_Trigger() 在运行态每次都会按顺序做下面几件事:- BMS_GetMeasurementValues()
- BMS_UpdateBatterySystemState()
- SOA_CheckSlaveTemperatures()
也就是说,SOA 当前不是一个独立线程,而是直接嵌在 BMS 主状态机 10ms 路径里的系统约束检查层。4.2 电压和温度检查是分层阈值链,不是单一阈值 if
SOA_CheckVoltages() 和 SOA_CheckTemperatures() 都是典型的分层告警结构:这些阈值来自 battery_cell_cfg.h。例如当前配置里:- BC_VOLTAGE_MAX_MOL_mV = 2720
- BC_VOLTAGE_MIN_MSL_mV = 1500
- BC_VOLTAGE_DEEP_DISCHARGE_mV = BC_VOLTAGE_MIN_MSL_mV
- BC_TEMPERATURE_MAX_DISCHARGE_MSL_ddegC = 550
所以 SOA 的工作不是帮你算一个安全分数,而是把当前最值和工作方向翻译成一组层次化的 DIAG 事件。4.3 Deep Discharge 是带持久化语义的闭环
- 当欠压已经进入 DIAG_ID_CELL_VOLTAGE_UNDERVOLTAGE_MSL,且最低电压继续低于 BC_VOLTAGE_DEEP_DISCHARGE_mV 时,SOA_CheckVoltages() 会触发 DIAG_ID_DEEP_DISCHARGE_DETECTED;
- DIAG_ErrorDeepDischarge() 收到 DIAG_EVENT_NOT_OK 后,会把 fram_deepDischargeFlags.deepDischargeFlag[stringNumber] 置位并写入 FRAM_BLOCK_ID_DEEP_DISCHARGE_FLAG;
- 下次上电时,SYS_FSM_CHECK_DEEP_DISCHARGE 会读回这个 FRAM 块,并重新把该诊断项送进 DIAG。
4.4 current on open string 体现的是状态与物理路径的一致性检查
SOA_IsCurrentOnOpenString() 的判断依据也很直接:- 且当前 string 既不是 closed,也不是 precharging;
- 那么就认定这是 open string 上出现了不应有的电流。
这类问题很难只靠单一测量值表达,但放在 SOA 层就很自然,因为它本质上是在比对系统状态和物理电流是否一致。5.diag.c:前面三层只是发现问题,真正组织故障语义的是它
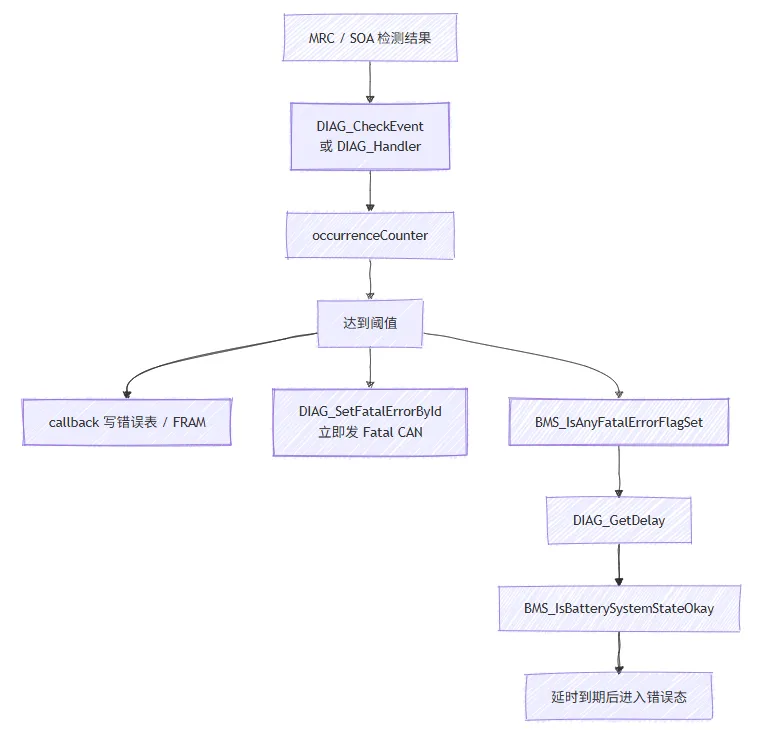
5.1 所有异常最终都要归一到DIAG_Handler()
FoxBMS 中各种模块不会自己去随意改全局错误位,而是统一通过:DIAG_Handler(diagId, DIAG_EVENT_NOT_OK, data)
DIAG_Handler(diagId, DIAG_EVENT_OK, data)
进入诊断框架,这让检测故障和决定故障是否真正激活被严格分开。5.2 DIAG_EVENT_NOT_OK的阈值语义比表面看更细
源码里,收到 DIAG_EVENT_NOT_OK 后的处理不是第一次异常就 active。逻辑是:而 DIAG_GetDiagnosisEntryState() 的 active 判定又是基于 occurrenceCounter > threshold。- 要理解某个故障何时真正进入 active,不能只看调用次数,还要看 threshold 语义。
这里还有一个容易忽略的配置细节:diag_cfg.h 里 DIAG_SEN_EVENT_1 = 0、DIAG_SEN_EVENT_10 = 9、DIAG_SEN_EVENT_20 = 19。也就是说,配置表里看见第 10 次生效,在实现层其实是counter 先累到 9,再在下一次 NOT_OK 时越过阈值并置 active。5.3 DIAG_EVENT_OK也采用了对称的渐退逻辑
恢复路径同样不是收到一次 OK 就立刻清故障。源码会逐步递减 occurrenceCounter,只有减回 0,才会:5.4 关键链路其实是检测模块 -> DIAG -> callback / fatal -> BMS
6. Fatal Error 不是一次性事件,而是周期性维持的系统状态
6.1 diag.c 会创建 fatal error resend timer
初始化阶段,诊断模块会建立一个周期性重发机制,周期是 100ms。这意味着 fatal error 一旦激活后,不是发一次 CAN 就结束,而是会持续重发相关信息。- 后接入的节点也需要感知当前处于 fatal error。
6.2 BMS 的错误延时就是建立在这层诊断上的
上一篇提到 BMS 会遍历所有 fatal diagnosis entry,并根据 DIAG_GetDelay() 选择最短延时。也就是说:- 前面 Plausibility / Redundancy / SOA 发现异常
- diag.c 决定异常何时真正 active、是否 fatal
- BMS 再根据 fatal error 的延时策略决定何时切断高压
- DIAG_SetFatalErrorById() 首次发现 fatal 后会立即发一次 fatal CAN,并在第一个 fatal 激活时启动 100ms 重发 timer;
- DIAG_ResendFatalErrors() 在 timer 回调里遍历所有 active fatal 项,逐个重发;
- BMS_IsAnyFatalErrorFlagSet() 会遍历 fatal 链接表,取所有 active fatal 项中最短的 delay;
- BMS_IsBatterySystemStateOkay() 再根据这个最短 delay 倒计时,直到真正允许状态机进入错误态。
7. 这一套设计真正解决了什么问题
把四层放在一起看,FoxBMS 的安全链条其实非常清楚:- DIAG 负责把这些离散异常整理成带阈值、带回调、带 fatal 语义的系统故障。
这让 FoxBMS 不是简单地看到异常就停机,而是能区分:小结
这一篇真正的核心不是列举了多少个诊断模块,而是建立了一条完整认识:FoxBMS 把检测异常和决定异常何时真正影响系统行为分成了不同层次。这也是它相比很多简单 BMS 项目更成熟的地方。后者往往是某个 if 条件一满足就直接断开,而 FoxBMS 明显更强调故障语义的整理和时序控制。下一篇收尾,我们把这些状态、请求和错误放回到 CAN 和工具链上下文里,看系统如何与外部世界交互,以及工程团队如何维护这些通信定义。推荐阅读顺序
- 先看 ftask_cfg.c 里的 10ms 路径,确认 MRC_ValidateAfeMeasurement()、MRC_ValidatePackMeasurement() 和 BMS_Trigger() 分别挂在哪个节拍上。
- 再读 redundancy.c,把 freshness 判断、单路降级和 pack 级 Plausibility 路径串起来。
- 然后回到 plausibility.c,看每个 PL_Check... 函数到底在比什么、改什么。
- 接着看 bms.c 里的 BMS_Trigger() 和 soa.c,理解 SOA 是怎样嵌入 BMS 主链的。
- 最后读 diag.c、diag_cfg.c、diag_cbs_deep-discharge.c 和 sys.c,把 threshold、生效、持久化和延时退出闭环起来。
 夜雨聆风
夜雨聆风