 夜雨聆风
夜雨聆风【导读】30 页手写毕业论文被判"98% AI 生成",学校拒看编辑记录,学生面临停学和 4.5 万美元奖学金被撤。X 上直言"AI detectors are a scam"的帖子拿下 2.4 万点赞。Vanderbilt 早已关停 Turnitin AI 检测,MIT 和 Stanford 同时警告:检测器误报率高、对非母语写作者有偏差,根本不该当处分依据。
2.4 万人点赞:「AI 检测器就是骗局,完全没用」
5 月 30 日,X 账号 Reddit Lies 发帖:
"Daily reminder that AI detectors are a scam and literally do not work."
「每日提醒:AI 检测器就是骗局,完全没用。」
帖子配了一张来自 Reddit 的学生求助长截图。
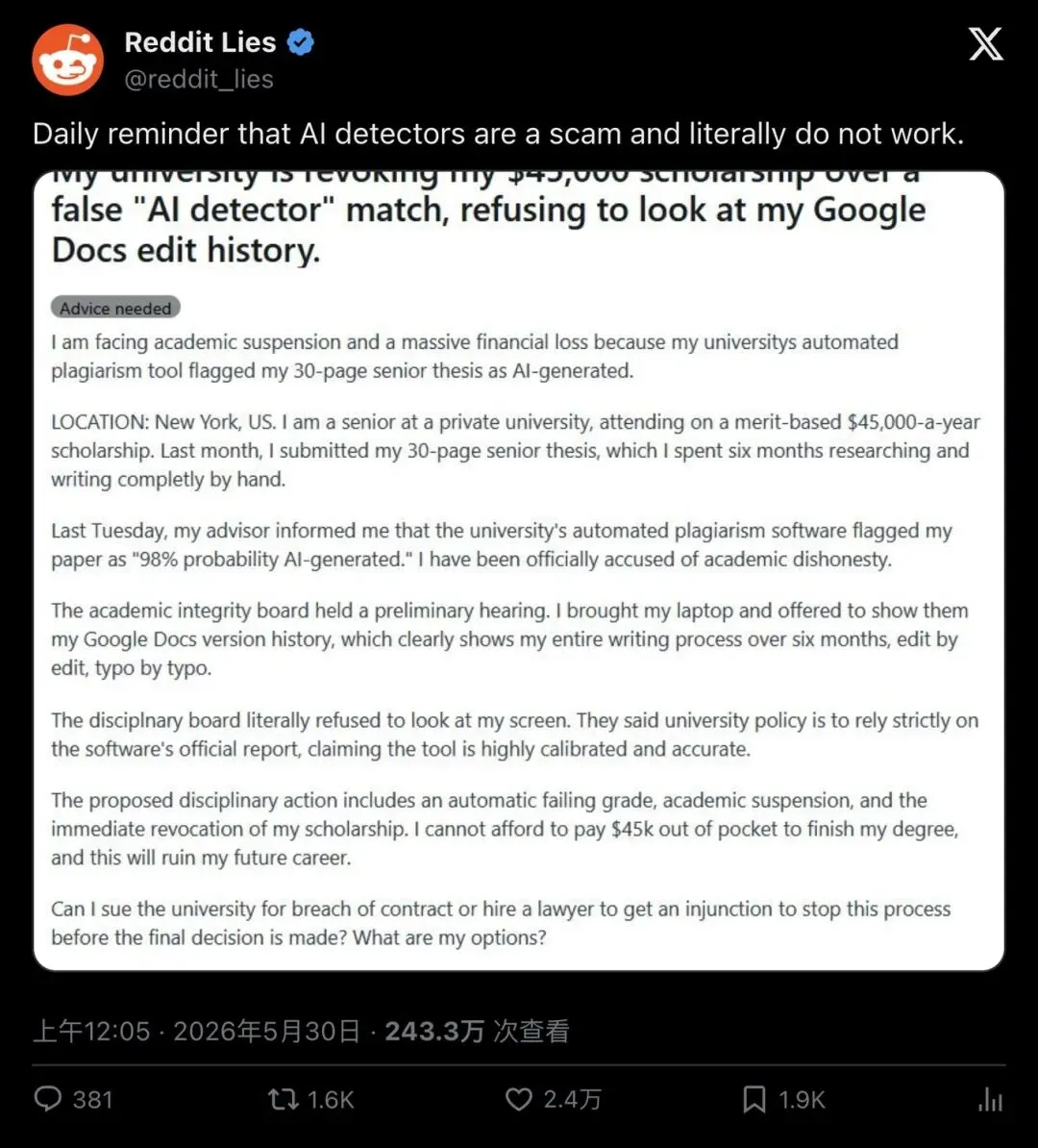
▲ Reddit Lies 推文及附图,获得 2.4 万点赞、243 万次浏览
截图里的学生自述:他在纽约一所私立大学读大四,靠每年4.5 万美元的 merit scholarship 上学。上个月提交了花六个月手写的30 页毕业论文,结果学校的自动查重/AI 检测工具把论文标记为「98% probability AI-generated」。
学校已正式指控他学术不端(academic misconduct)。
他提出展示Google Docs 编辑历史和研究笔记,证明论文确实是逐字敲出来的。但教授和学术诚信委员会拒绝查看,称学校政策以检测软件的官方报告为准,认为工具"高度校准且准确"。
后果摆在眼前:自动挂科、停学、奖学金立即撤销。继续读完学位,得自掏 4.5 万美元。
需要指出:这个案例目前仍是社交平台上的匿名自述,未经独立媒体或校方核实。但它击中了一个被反复验证过的真问题——当一个黑箱工具说"98% AI 生成"时,学校该不该无视写作过程证据,直接走处分流程?
回复区更炸裂:1976 年的论文也被判成 AI
帖子下面的回复区,几乎变成了"AI 检测器受害者互助会"。
Mary Rayburn自称退休材料科学工程师,她1976 年发表的研究文章被某 AI 工具标成">98% AI generated"。
"I'm a retired materials science engineer. Research articles I published/wrote in 1976 were flagged as >98% AI generated."
「我是退休的材料科学工程师。我 1976 年发表的研究文章被标记为 >98% AI 生成。」
1976 年。那时个人电脑都没普及。
Brian H说,他1999 年的博士论文被两位教授使用的 AI 工具判定"95% chance AI used"。
还有人提到葛底斯堡演说和圣经的部分段落也会被检测器标红。
这些都是个人在社交平台上的自述,不能等同于统计研究。但它们指向同一个现实:AI 检测器倾向于把规范化、简洁、结构化的写作判定为"AI 生成"。越认真写、格式越标准的文本,越容易被误判。
另一批高互动回复聚焦在程序公平上:
建议学生保留 Google Docs 版本历史、Word 修改记录、研究笔记和邮件往来 建议要求学校把教授自己的毕业论文也放进同一个检测器跑一遍 有人直接说:请律师,起诉学校和工具供应商
也有人质疑原始截图的真实性,认为大多数大学不会只靠 AI 检测结果做处分决定。这类反向声音同样重要——但问题在于,只要有一所学校真的这么做,对那个学生来说就是灭顶之灾。
Vanderbilt 大学:我们已经关停了 Turnitin 的 AI 检测功能
社交媒体上的吐槽可以当情绪看,高校自己的表态才是真正的证据。
Vanderbilt 大学在 2023 年 8 月发文,标题已经说明了立场:《Guidance on AI Detection and Why We're Disabling Turnitin's AI Detector》(关于 AI 检测的指引,以及为什么要关停 Turnitin 的 AI 检测器)。
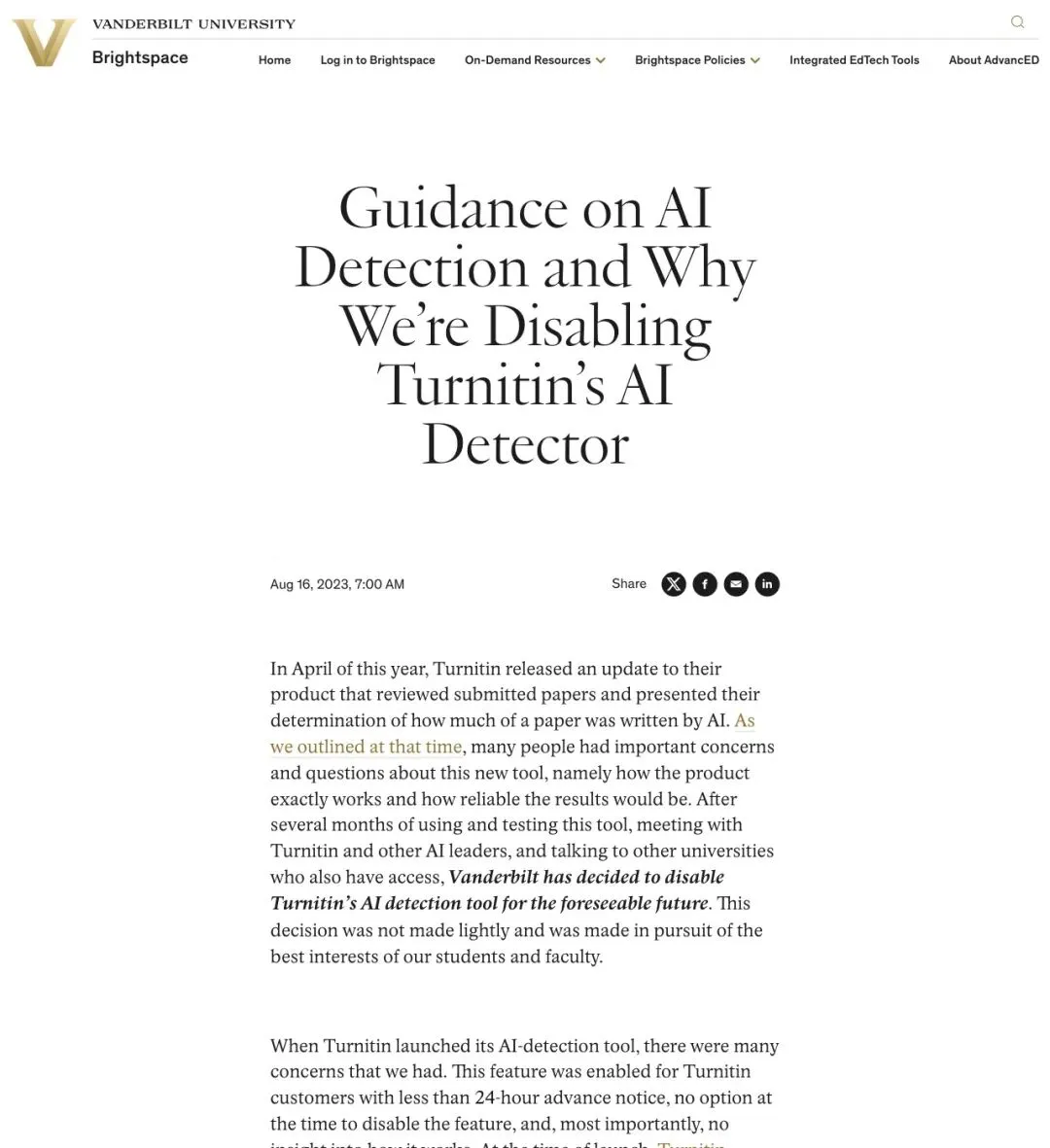
▲ Vanderbilt 大学 Brightspace 页面,解释为什么禁用 Turnitin AI 检测功能
Vanderbilt 表示,Turnitin 在 2023 年 4 月推出了 AI 检测更新,会对提交的论文给出"AI 写成比例"的判定。学校经过数月测试,与 Turnitin 及其他高校反复沟通后,决定禁用这项功能。
原因包括:
- 工具运行机制不透明
——教师和学生都无法理解分数怎么算出来的 - 教师容易把 AI 分数当成铁证
——但它只是概率估计 - 误报在大规模部署后变成真实伤害
——声称 1% 的 false positive rate,几千篇论文里就是几十个被冤枉的学生 - 学生被迫自证清白
——举证责任被倒置 - 学术诚信程序需要可解释性
——黑箱工具提供不了这一点
高校内部早就知道 AI 检测有问题。Vanderbilt 选择了最直接的处理方式——关掉它。
对比 X 帖子里描述的场景:学校拒绝查看编辑历史,只认自动工具的报告。如果这是真实的,它恰好违背了 Vanderbilt 这类学校公开发布的谨慎建议。
MIT 开门见山:「AI 检测器没用,应该换个思路」
MIT Sloan 的教学技术团队也发了文章,标题直截了当:
"AI Detectors Don't Work. Here's What to Do Instead."
「AI 检测器没用。应该怎么办?看这里。」

▲ MIT Sloan 教学技术页面:AI 检测器没用,应该怎么办
MIT 的核心建议是:与其死盯最终文本查 AI 痕迹,不如从课程设计和过程管理入手。四个方向:
1.设计 AI-resilient 的学习体验——让作业本身就需要个人经历、课堂讨论或特定场景参与 2.从开课就把规则定好——哪些场景可以用 AI、哪些不行,学期初就摆上台面 3.促进透明对话——让学生主动声明 AI 使用情况,把事后稽查变成事前约定 4.关注过程证据——草稿、编辑记录、口头答辩、阶段性提交
这和 X 帖里 Google Docs 编辑历史的争议直接相关:如果学生能提供完整的写作过程记录,而学校仍然只看一个概率分数,那问题已经超出了检测器本身——整套评估制度在偷懒。
Stanford 研究补上最后一块拼图:检测器对非母语英语写作者有系统性偏差
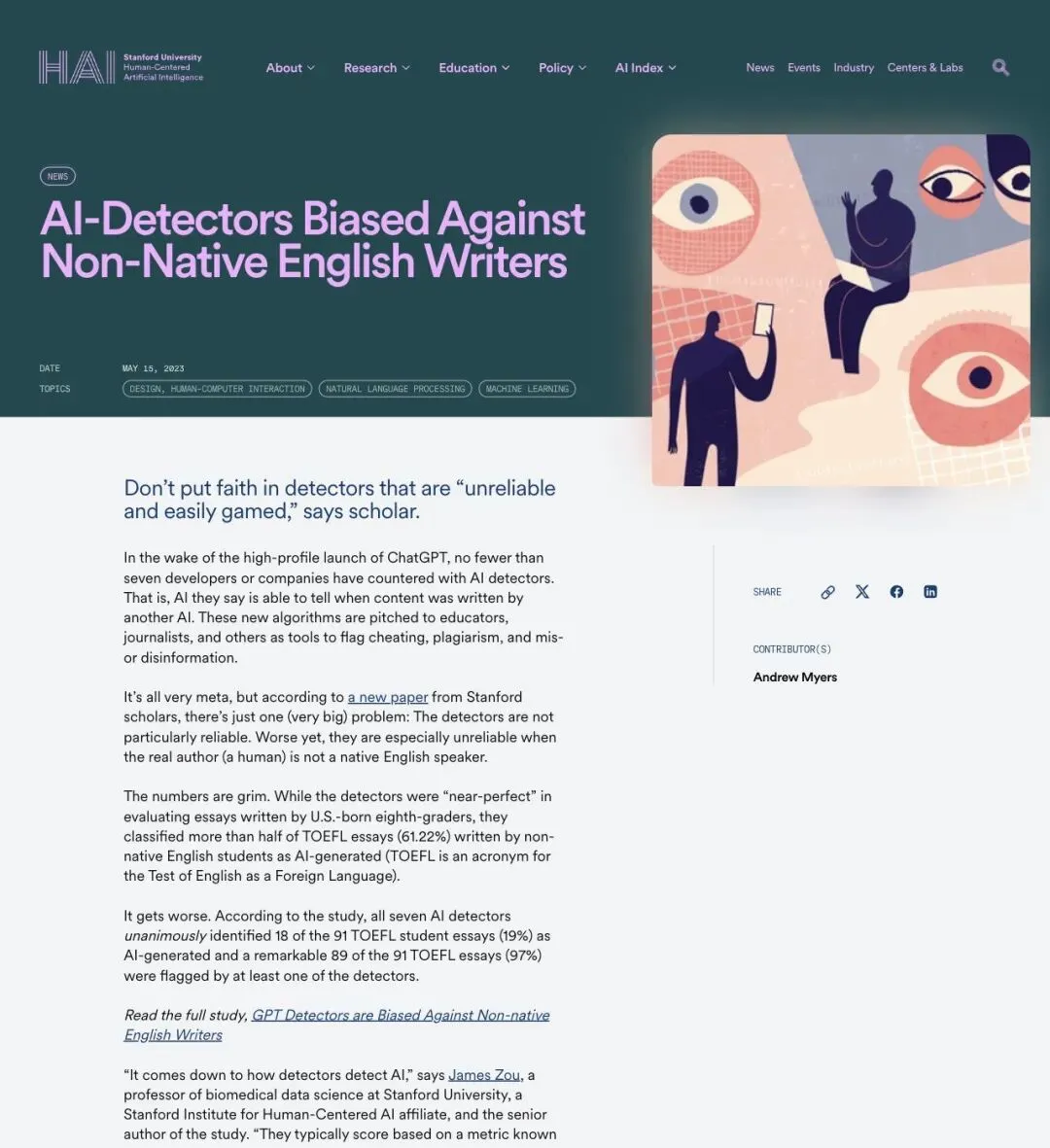
Stanford HAI(Human-Centered AI)的研究结论更扎心:
"Don't put faith in detectors that are 'unreliable and easily gamed.'"
「别指望那些"不可靠且容易被绕过"的检测器。」
▲ Stanford HAI 文章:AI 检测器对非母语英语写作者存在偏差
Stanford 研究者发现,常见的 GPT 检测器在评估非母语英语写作者的文本时,误报率显著偏高。
原因并不复杂:AI 检测器主要靠"困惑度"(perplexity)来判断——困惑度低、句式规整、表达可预测的文本更容易被标上 AI 标签。但非母语英语写作者天然倾向于使用更简单、更规范的句式和词汇。
换句话说:一个中国留学生认真写的英文论文,可能比美国本土学生的论文更容易被检测器标红。
国际学生、ESL 学生、技术文档写作者、使用标准模板格式的学科(比如实验报告、工程文档),都在这个系统性偏差的打击范围内。
Stanford 还指出了硬币的另一面:真正的 AI 生成文本,经过人工编辑或改写后,反而容易逃过检测。
两头失败。把真人写作判成 AI,又放过了真 AI 内容。用来做低风险的课堂讨论素材,勉强说得过去。但拿它来决定一个学生的停学、奖学金、学术诚信记录、签证乃至职业前途——就是在用一个不合格的工具做高风险裁决。
一个概率分数,凭什么决定一个人的前途?
回到开头那条帖子。它之所以能获得 243 万次浏览和 2.4 万点赞,是因为它把一个抽象的技术争论压缩成了所有人都能代入的场景:
一个软件说"98% AI 生成",学校就可以直接处分学生了?
Vanderbilt 禁用了检测器。MIT 说"别用检测器当判官"。Stanford 证明检测器对非母语写作者有偏差。Washington Post 报道的标题更绝望:「Detecting AI may be impossible.」(检测 AI 可能本身就做不到。)
这些机构之所以纷纷表态,是因为 AI 检测器背后藏着三重不对称:
证据不对称。检测器吐出一个看似精确的概率值,但学生根本不知道这个分数怎么来的——用的什么模型、阈值怎么定的、在自己的学科和语言下误报率到底多高。黑箱输出,堵死了申辩空间。
后果不对称。对工具供应商来说,一次误报是统计噪声;对学生来说,可能意味着停学、奖学金、毕业、签证和职业前途全部归零。Vanderbilt 说得对——1% 误报率放到几千篇论文里,就是几十个真实的人生被搅乱。
责任不对称。教师和行政人员把难判断外包给软件,供应商在 FAQ 里写满免责条款,最终被逼着自证清白的只有学生。这就是 X 回复区里反复出现 Google Docs 编辑历史、track changes、草稿和律师的原因——大家真正愤怒的焦点,是机构用一个有缺陷的工具来逃避做出人工判断的责任。
AI 检测器可以用吗?可以。用来做低风险的课堂参考,用来提醒学生注意写作规范,用来辅助教师的初步判断——都没问题。
但它绝不应该被当作停学、奖学金撤销、学术诚信处分的唯一依据。
一个连 1976 年论文都会判错的黑箱工具,凭什么决定一个学生的前途?
— END —
