 夜雨聆风
夜雨聆风AI生图总是"差口气"?因为你只给了它一句话
你有没有过这种经历——
打开AI生图工具,输入"温馨的客厅",满怀期待点了生成。
结果呢?
出来的要么像酒店大堂,要么像售楼处样板间。灯是亮的,沙发是摆的,但怎么看都不是你家。
你心里想的是那盏落地灯打在亚麻毯上的暖光,AI给你的是一排射灯照得锃光瓦亮。
差在哪?
不是AI蠢。是你"喂"的方式太粗糙了。你给了一句模糊的感觉词,AI只能还你一个模糊的结果。
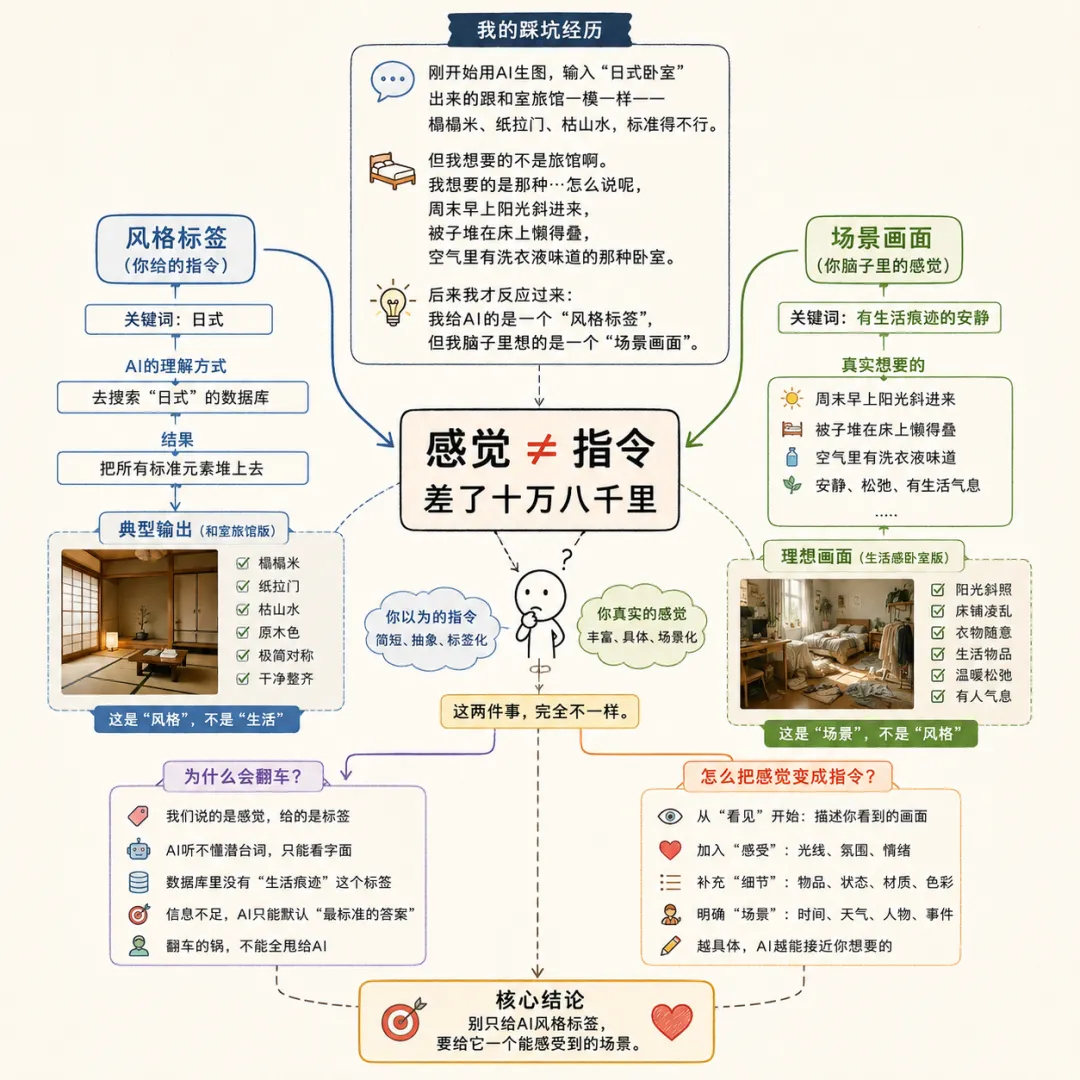
感觉 ≠ 指令,差了十万八千里
说真的,我刚开始用AI生图的时候也这样。输入"日式卧室",出来的跟和室旅馆一模一样——榻榻米、纸拉门、枯山水,标准得不行。
但我想要的不是旅馆啊。我想要的是那种...怎么说呢,周末早上阳光斜进来,被子堆在床上懒得叠,空气里有洗衣液味道的那种卧室。
后来我才反应过来:我给AI的是一个"风格标签",但我脑子里想的是一个"场景画面"。
这两件事,完全不一样。
风格标签是"日式",AI就去搜索"日式"的数据库,把所有标准元素堆上去。但场景画面是"有生活痕迹的安静",这四个字我从来没告诉过AI。
所以翻车的锅,真的不能全甩给AI。
把感觉翻译成要素,你就赢了一半
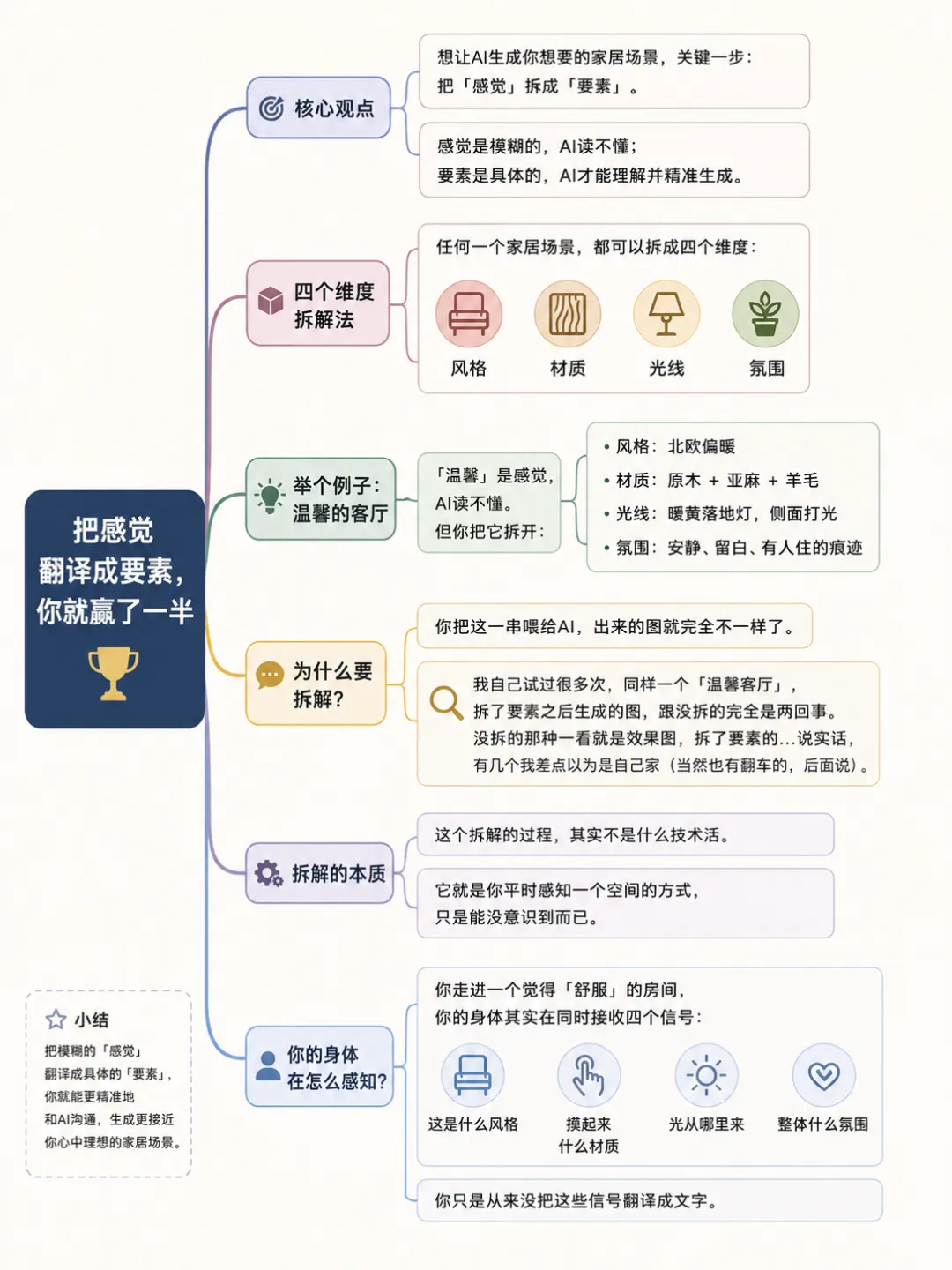
那怎么"喂"对呢?我觉得关键就一步:把感觉拆成要素。
任何一个家居场景,都可以拆成四个维度——风格、材质、光线、氛围。
我来举个例子。
你想要"温馨的客厅"。
"温馨"是感觉,AI读不懂。但你把它拆开:
• 风格:北欧偏暖
• 材质:原木 + 亚麻 + 羊毛
• 光线:暖黄落地灯,侧面打光
• 氛围:安静、留白、有人住的痕迹
你把这一串喂给AI,出来的图就完全不一样了。
我自己试过很多次,同样一个"温馨客厅",拆了要素之后生成的图,跟没拆的完全是两回事。没拆的那种一看就是效果图,拆了要素的...说实话,有几个我差点以为是自己家(当然也有翻车的,后面说)。
这个拆解的过程,其实不是什么技术活。它就是你平时感知一个空间的方式,只是你没意识到而已。
你走进一个觉得"舒服"的房间,你的身体其实在同时接收四个信号:这是什么风格、摸起来什么材质、光从哪来、整体什么氛围。
你只是从来没把这些信号翻译成文字。
有参照图就别只靠文字
还有一点特别重要。
如果你手里已经有一张"差不多这个感觉"的图——别犹豫,直接用图生图。
为什么?因为文字描述有天花板。你说"暖色调",AI理解的可能和你理解的完全不一样。你说"有点像那个咖啡店的感觉",哪个咖啡店?哪个角落?什么时间的?
但一张图,千言万语都在里面了。
我自己常用的做法是:先存一批我喜欢的家居图(Pinterest上随便扒),然后把风格迁移一下,换成我想要的户型和布局。出来的效果,比纯文字描述靠谱得多。
不过吧,图生图也不是万能的。有时候AI太忠实于原图了,改动的幅度很小,你得迭代几轮才行。
说到迭代——
第一版是草稿,不是成品
很多人用AI生图,生成一次就放弃了。"啊不行,不是我要的。"
不是的。
AI生图不是"下单",更像"对话"。第一版只是让你们对上话,后面才是真正出活儿的时候。
我一般的流程是这样:
第一轮:先定大方向。提示词粗一点没关系,看整体风格对不对。如果风格就不对,后面的细节都没意义。
第二轮:调细节。加具体的家具、材质、颜色。这一轮基本能看出个七成了。
第三轮:修氛围。调光线、加氛围词、控制画面情绪。到这一步,基本就是你想要的了。
有时候三轮就够了,有时候得五六轮。看运气,也看你一开始"喂"得够不够具体。
对,这事儿确实有点费时间。但比起你自己画效果图...那还是快多了。
即拿即用:家居场景提示词模板
说了这么多,给你一个直接能用的东西。
下次生成之前,别直接打"温馨的客厅"了。按照这个模板填空:
[风格] + [空间] + [核心家具/元素] + [材质] + [光线] + [氛围]
三个示例,你直接抄:
客厅
北欧偏暖 + 客厅 + 布艺沙发和原木书架 + 亚麻与白橡木 + 落地灯侧面暖光 + 安静、有人住、周末下午
卧室
日式偏简 + 卧室 + 低床和藤编床头柜 + 原木与棉麻 + 侧面自然光纱帘 + 留白、松弛、不刻意
书房
中古混搭 + 书房 + 胡桃木书桌和皮质椅 + 胡桃木与做旧皮 + 台灯暖光 + 沉浸、旧物感、可以发呆
复制,填空,粘贴,出图。
第一版不满意?正常。接着聊,逐轮调,别急着放弃。
AI不是许愿池。
你丢一句话,它还你一张梦中的图——这事儿不存在的。
它更像一面镜子。你喂得多具体,它就映得多清晰。
而喂对AI这件事,本质上是在练一个能力:你能不能说清楚,你到底想要什么样的生活。
这个能力,比任何AI工具都值钱。
下次打开生图工具之前,先把"我想要一个好看的家"拆成四个要素。试一次,你就知道差别在哪了。
