 夜雨聆风
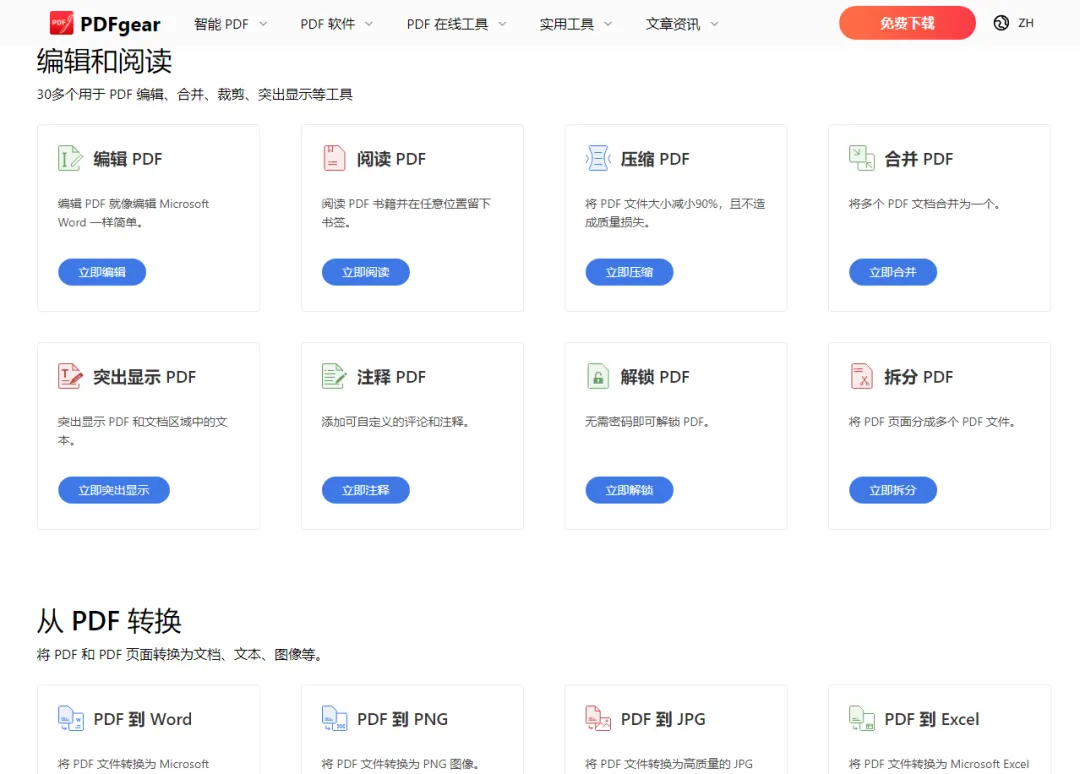
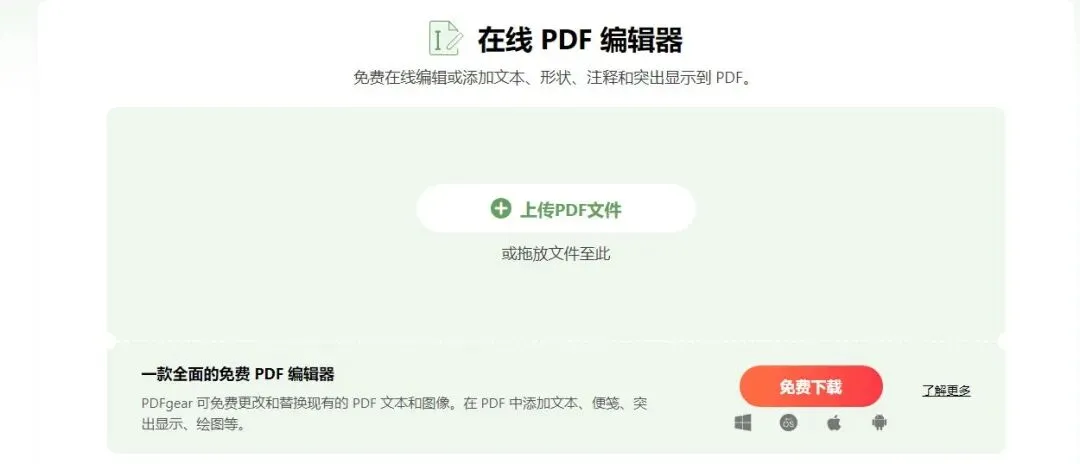
夜雨聆风1,PDFgear
它真的很好用,而且免费,几乎覆盖了日常对PDF的所有操作——阅读、编辑、批注、格式转换、合并拆分、压缩、OCR文字识别,它的下载也很简单:pdfgear.com/zh/

并且它还支持浏览器在线编辑
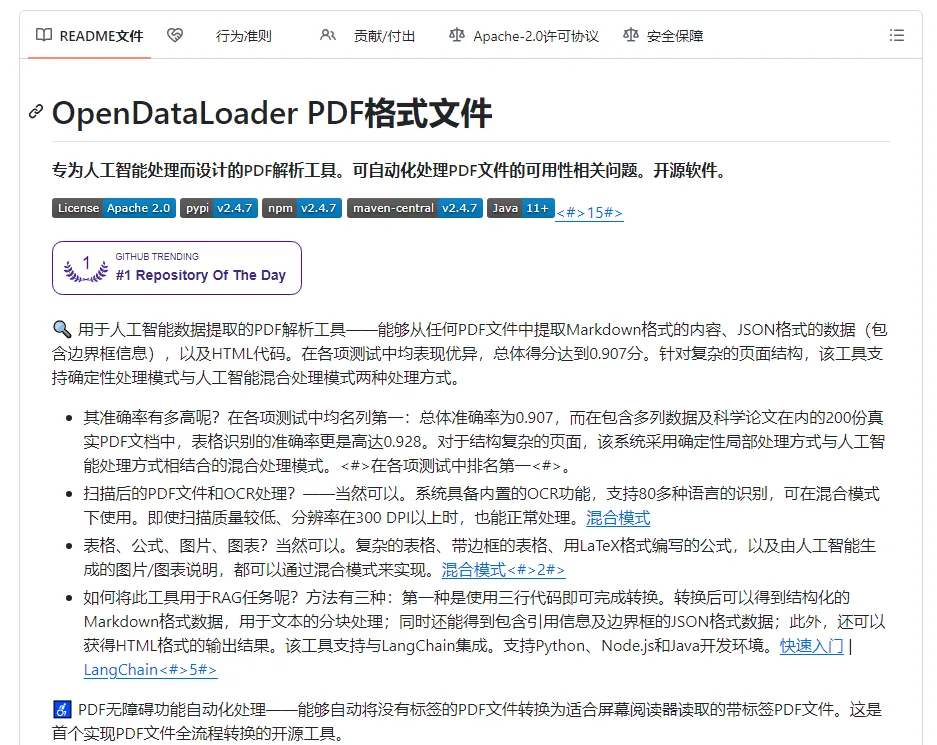
2,opendataloader-pdf
在GitHub开源的PDF解xi器。它能把PDF里的表格、多栏排版、图文混排内容,不乱序地提取出来,喂给AI让它看懂:https://github.com/opendataloader-project/opendataloader-pdf
对于需要处理大量 PDF 做 AI 训练、知识库构建的人来说,这东西是把最硬的骨头啃下来交给你
如果你有一篇这样的论文:
左边一栏是正文
右边一栏是图片和注释
中间还有一个复杂的表格
下面有道数学公式
你把这个PDF直接扔给AI,AI看到的是一堆乱七八糟的字符,分不清哪句是哪句,表格也变成一团乱码,而OpenDataLoader-PDF就像一个“翻译官”,它能把左右两栏的正文按正确顺序排好,表格完整地提取出来,数学公式识别成AI能理解的格式,扫描版的图片里的文字也能认出来,最后输出成一份干干净净的Markdown或JSON文件
环境要求
Java (https://adoptium.net/)点击“Download”,下载后,双击安装文件,一路点击“下一步”或“继续”,直到完成 Python(https://www.python.org/downloads/)
安装使用
安装OpenDataLoader-PDF:打开电脑的“终端”(Windows搜索“cmd”,Mac搜索“终端”),在黑框框里,输入这行命令:pip install opendataloader-pdf,然后按回车三行代码就能用:
1、新建一个文本文件,把下面代码复制进去,,保存文件名为 my_parse.py
2、打开终端,输入 python my_parse.py 并回车,等待运行结束
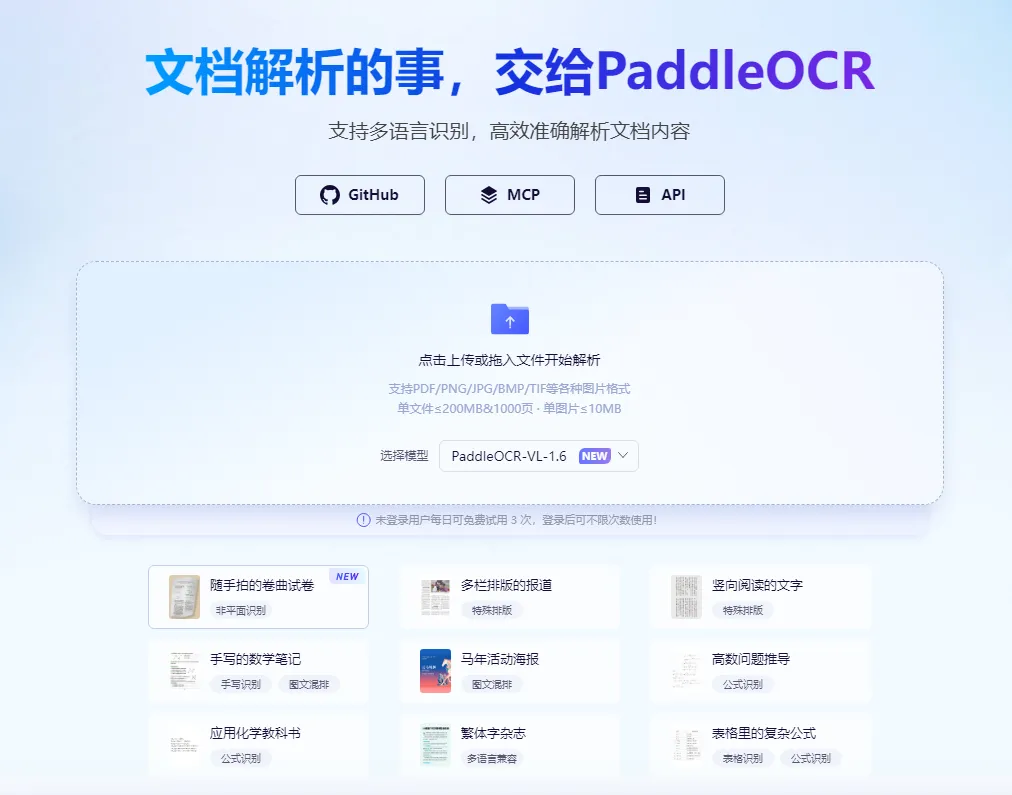
import opendataloader_pdfopendataloader_pdf.convert( input_path=["file1.pdf", "file2.pdf", "folder/"], output_dir="output/", format="markdown,json")3, PaddleOCR
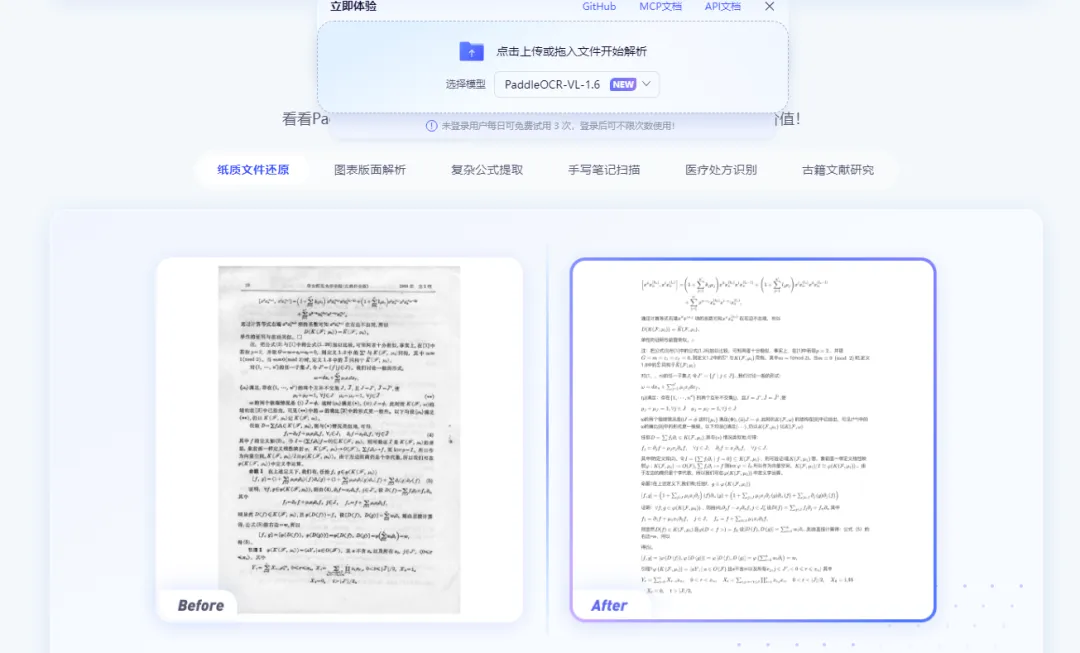
可以识别 纯扫描件(图片型PDF),没有文字层的PDF,无论是打印的、手写的,还是照片里的文字,它都能识别。
它支持 80 多种语言,对中英文的识别精准度高,表格、印章都能处理,不仅能识别文字,还能检测文字位置、判断排版方向
详细的安装、使用文档:https://www.paddleocr.ai/latest/#paddleocr-vl
GitHub:https://github.com/PaddlePaddle/PaddleOCR
在线使用:https://aistudio.baidu.com/paddleocr
I love PDF,合并、拆分、压缩、转换、旋转和解锁PDF文件,以及给PDF文件添加水印的工具等:https://www.ilovepdf.com/zh-cn
PDF派,几十个处理工具:https://www.pdfpai.com/
万兴HiPDF,PDF的转换、合并、压缩和拆分:https://www.hipdf.cn/
docsmall,图片压缩,PDF处理:https://docsmall.com/
iLovePDF(两个一样的名字,应该这个是正的):https://www.ilovepdf.com/
PDF24 Tools,PDF文件及其他各类文件在线处理:https://tools.pdf24.org/en
点分享

点收藏

点点赞

点在看
