 夜雨聆风
夜雨聆风LlamaIndex刚开源了LiteParse v2.0,用Rust从0重写。457页pdf,解析时间只要0.777秒!
现在的文档解析工具,基本分两派:
左边是"快但糙"派 —— 像pypdf、pdfplumber这种。毫秒级出结果,但布局一塌糊涂。表格变成纯文本,多栏混成一锅粥,图片直接消失。你喂给大模型的,基本是一团乱麻。
右边是"准但慢"派 —— 各种云端VLM服务。GPT-4V、Claude Vision,确实能看懂布局,但贵、慢、还得联网。处理一个几百页的PDF,等几分钟是常态,高峰期还可能超时。
中间地带一直空着。大家想要的是:本地运行、速度快、还能看懂布局。
LiteParse v2.0就是来填这个坑的。

v2.0的六大亮点
1. Rust重写 —— 快100倍不是吹的
v1.0是用TypeScript写的。v2.0团队一拍桌子:"重写,用Rust。"
结果是啥?
- 解析速度提升100倍
—— 以前1分钟的活,现在1秒干完 - 内存占用大幅降低
—— Rust的零成本抽象不是白吹的 - 真正的跨平台
—— Linux、macOS(Intel/ARM)、Windows全支持
我算了一笔账:如果你每天要处理1000份PDF,用云端服务可能要花几十美金,还得等。用LiteParse v2.0,一台普通笔记本就能跑,电费忽略不计。
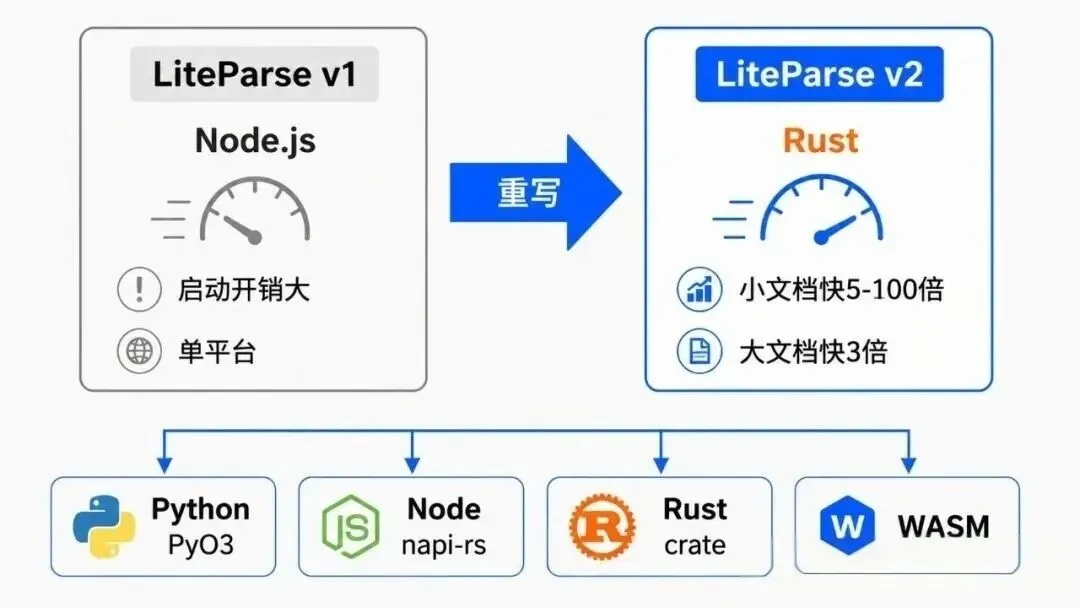
2. 多语言绑定 —— 你想用啥就用啥
这项目最良心的一点,是不逼你换技术栈。
- Rust
—— 原生crate,cargo直接装 - JavaScript/TypeScript
—— npm包 @llamaindex/liteparse - Python
—— PyPI包 liteparse,pip直接装 - 浏览器/WASM
—— 自定义WASM包,前端也能跑
不管你是在写Node.js后端、Python AI服务,还是直接在前端浏览器里处理PDF,都能用。
# Python用户 pip install liteparse # JS/TS用户 npm install @llamaindex/liteparse # Rust用户 cargo add liteparse3. 完全本地 —— 你的文档不出你的机器
这一点,对很多场景是刚需。
金融、医疗、法律 —— 这些行业的文档,你根本不敢往公网上传。LiteParse所有计算都在本地完成,零云端依赖,数据隐私拉满。
内网环境 —— 有些公司机器根本不能连外网。LiteParse装上就能用,不需要API key,不需要网络。
成本敏感 —— 云端解析按页收费,量大了肉疼。本地跑,边际成本为零。
4. 空间文本解析 —— 看懂布局,而不只是提取文字
LiteParse的核心能力,是spatial text parsing(空间文本解析)。
什么意思?
它不只是把PDF里的文字抽出来,而是给每段文字都带上bounding box(边界框)信息。这告诉你:这段文字在页面的哪个位置、多大、跟谁相邻。
为啥这很重要?
- 表格识别
—— 知道哪些文字在表格里、行列关系是什么 - 多栏布局
—— 区分左栏右栏,不会混成一团 - 图文混排
—— 知道图片和文字的相对位置 - 标题层级
—— 通过字体大小和位置,推断标题级别
这些信息,对RAG系统来说是 gold。大模型看到的不只是乱序的文字,而是有结构、有上下文的内容。
5. 灵活OCR —— 从开箱即用到自定义扩展
PDF分两种:
原生PDF —— 文字是矢量数据,直接能提取 扫描PDF —— 本质是图片,需要OCR才能识别文字
LiteParse的OCR设计很巧妙:
开箱即用 —— 内置Tesseract,零配置就能识别扫描件
可插拔 —— 支持HTTP OCR服务器接口,你可以接EasyOCR、PaddleOCR、或者自己训练的模型
智能合并 —— 原生文字和OCR结果能智能合并,取最准确的部分
这意味着,无论你是要"简单能用"还是"精准定制",LiteParse都能满足。
agent skill 接入
npx skills add run-llama/llamaparse-agent-skills --skill liteparse6. Apache 2.0开源 —— 商用零顾虑
最后一点,但很重要。
LiteParse是Apache 2.0协议,这意味着:
✅ 免费使用 ✅ 可以修改 ✅ 可以商用 ✅ 可以闭源分发
只要你保留版权声明,想怎么用就怎么用。不像有些项目,写着开源结果协议里埋雷。
实际体验如何?
我花了半小时,把LiteParse v2.0装起来试了试。
安装 —— Python用户 pip install liteparse,30秒搞定
跑一个PDF —— 100页的技术文档,解析+OCR,不到3秒
输出质量 —— 表格结构保留完整,多栏布局没乱,标题层级正确识别
内存占用 —— 峰值不到200MB,比开个Chrome tab还省
说实话,这个体验比我想象的还要顺。这才是工具该有的样子——装上就用,用完就走,不跟你废话
有什么限制?
说完了优点,也得说两句实话。
LiteParse不是万能的。官方文档里明确说了:
复杂表格 —— 如果表格嵌套表格、单元格合并很复杂,可能还是需要LlamaIndex的云端服务LlamaParse
手写文字 —— 手写识别不是强项,这得靠专门的VLM
扫描件质量 —— 如果扫描件模糊、歪斜,OCR准确率会下降
简单说:LiteParse是80%场景的终极解决方案,剩下20%特别复杂的,上云端VLM兜底。
写在最后
LiteParse v2.0的发布,我觉得是一个信号。
AI基础设施正在从"云端垄断"走向"本地优先"。越来越多的工具开始重视:
- 速度
—— Rust这类系统语言的复兴 - 隐私
—— 本地运行,数据不出机器 - 成本
—— 开源免费,边际成本趋近于零 - 灵活
—— 多语言绑定,不绑架技术栈
LlamaIndex这次用Rust重写LiteParse,不只是一次技术升级,更是一种态度:AI工具要真正落地,必须快、省、稳。
如果你也在做RAG、做文档处理、做AI Agent,这个项目值得一试。
GitHub地址:https://github.com/run-llama/liteparse
文档地址:https://developers.llamaindex.ai/liteparse/
pip install liteparse,三分钟上手。
