 夜雨聆风
夜雨聆风字数 4306,阅读大约需 22 分钟
Claude Code底裤被扒之后:国产AI编程工具,到底差在哪?
当Claude Code的51.2万行源码被扒得底裤都不剩,所有人才意识到:AI编程工具真正的壁垒,从来就不在代码里。
3月31日,普林斯顿博士生Chaofan Shou公开披露:Anthropic的旗舰编程Agent Claude Code,完整源码暴露在npm包中——51.2万行,1906个文件,任何人都可以下载。
整个行业炸了。但热闹过后,一个更值得追问的问题浮出水面:当源码摆在你面前,你能学到什么?
答案是:架构可以抄,流水线可以仿,但设计背后的问题意识才是真正的壁垒。AI Agent 90%的工作量在"AI"之外——安全边界、上下文压缩、验证隔离、工具治理,这些脏活累活才是决定产品上限的东西。
而国产AI编程工具走到哪了?功能覆盖基本追平,但在"信任工程""上下文经济学"这些隐形战场上,差距依然清晰。今天这篇文章,就是把差距摊开来看。
⏱本文功能对比数据截至2026年5月14日。5月15日Qoder 1.0发布、Trae 5月更新等后续变化,将在下一篇增量追踪中分析。定价数据更新至发文日。
一、Claude Code泄露:一场意外揭开的行业底牌
1.1 事件复盘:不是黑客太强,是防线太松
先说结论:这不是一次"高级攻击",而是一次"低级失误"的连锁反应。
时间线拉一下:
•2025年2月:Claude Code源码首次因相同机制泄露,但未引起广泛关注 •2026年3月26日:Anthropic CMS系统配置错误,源码路径被外部索引 •3月31日:Chaofan Shou公开披露,npm包中的完整源码可被任何人下载
泄露的根因链是这样的:
Bun bundler默认生成
.map文件(source map)→ 项目未配置.npmignore排除.map文件 → 无发布前检查流程 → npm包体积达59.8MB,内含完整源码
最讽刺的是:Claude Code内部有一个叫"Undercover Mode"的功能,专门防止内部人员泄密。结果呢?防线从内部铜墙铁壁,外部却连.map文件都没删干净。一个耗资巨大的安全体系,败给了一条.npmignore配置。
1.2 源码里到底藏着什么?
泄露的不是什么"秘密武器",而是一套工程哲学。先看几个数字:
•51.2万行代码 /1906个文件 •42个Agent工具 / **85+**Slash命令 •六层分层架构 /14步工具治理流水线
六层架构长这样:

几个真正值得关注的工程细节:
•System Prompt静态/动态分离:静态部分编译时注入,动态部分运行时拼接——仅此一项,节省92%的Token消耗 •Fail-closed安全设计:默认拒绝,显式授权才放行,跟很多国产工具的"默认放行"完全相反 •读前写约束(Read-before-Write):改文件之前必须先读,防止"盲改" •Verification Agent:独立的验证Agent,与编码Agent利益隔离——自己写的代码,自己不能验 •三层上下文压缩 + autoDream记忆蒸馏:不是无脑塞上下文,而是主动压缩和提炼 •ToolSearch延迟加载:42个工具不是一次性全加载,按需检索
1.3 泄露给行业的最大认知冲击
源码泄露最大的价值,不是"白嫖了Anthropic的架构",而是它像一面镜子,照出了整个行业的认知盲区:
AI Agent 90%的工作量在"AI"之外。
模型能力是天花板,但决定你能不能触到天花板的,是工程基础。System Prompt分离节省92% Token——这不是模型能力,这是工程智慧。Fail-closed安全设计——这不是算法创新,这是问题意识。Verification Agent利益隔离——这不是技术突破,这是对"AI会犯错"这件事的深刻理解。
**架构可以抄,流水线可以仿,但设计背后的问题意识才是真正的壁垒。**当然,核心护城河仍在模型本身——你可以复制架构,但无法复刻推理能力。架构决定下限,模型决定上限,工程决定你离上限有多近。
二、国产AI编程工具:一超两强多极的战国时代
2.1 市场格局
2025年,国内AI编程工具市场规模约25亿元(据多方估算),增速惊人,但格局已初步形成"一超两强多极"的结构:
•一超:Trae,市场份额约41% •两强:通义灵码约19%,文心快码Comate约12% •多极:CodeBuddy、CodeGeeX、MarsCode等瓜分剩余份额
Trae一个产品吃掉四成蛋糕,背后是字节跳动的流量和豆包大模型的双重加持。但份额大≠技术强,我们后面细说。
2.2 七款工具横评:功能覆盖谁最全?
先说结论:功能"量"上,国产工具已基本追平;差异在"质"的深度。
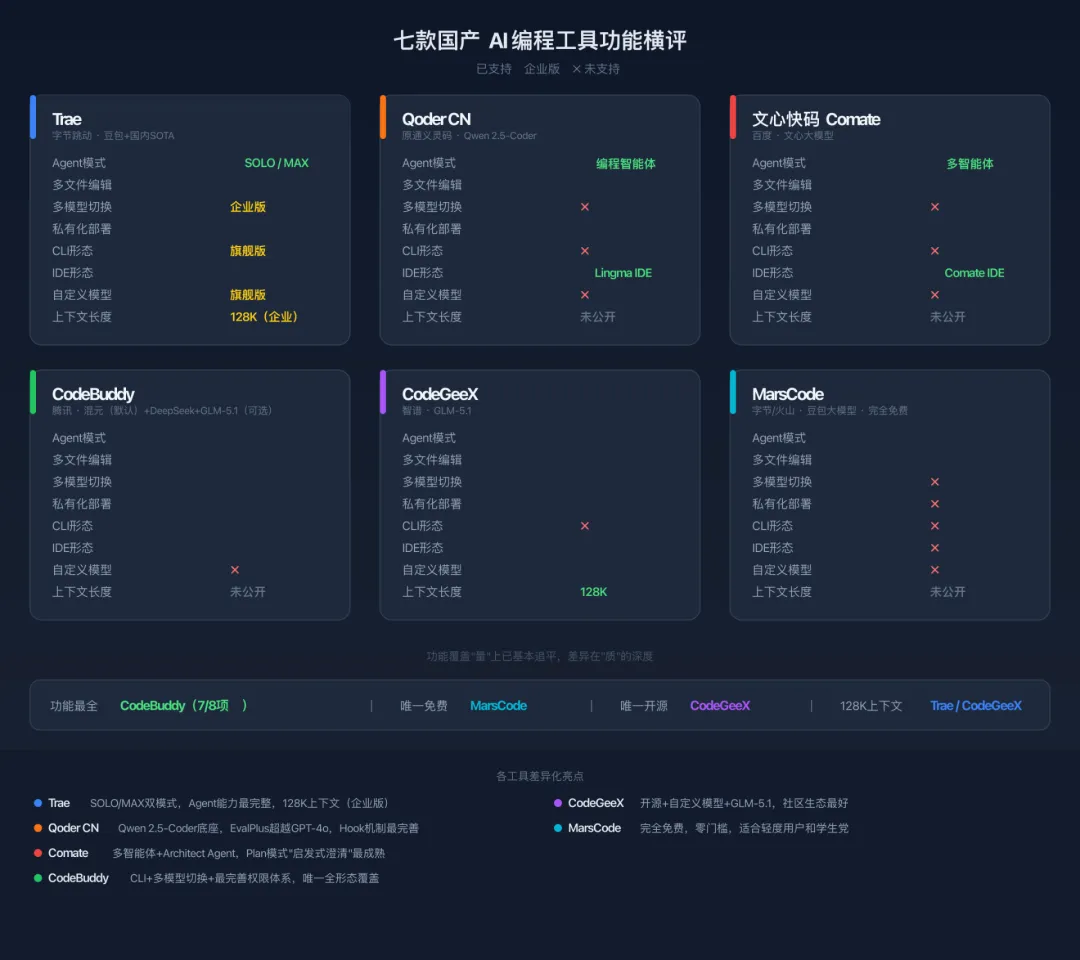
各家的差异化亮点:
•Trae:SOLO/MAX双模式切换,Agent能力最完整,128K上下文(企业版) •通义灵码:Qwen 2.5-Coder底座强,EvalPlus评测超越GPT-4o,最近改名Qoder CN •Comate:多智能体+Architect Agent,有审阅机制 •CodeBuddy:CLI形态+多模型切换(混元默认,DeepSeek+GLM-5.1可选)+最完善的权限体系 •CodeGeeX:开源+自定义模型+GLM-5.1(4月上线),社区生态好 •MarsCode:完全免费,零门槛,适合轻度用户
但记住:"有这个功能"和"这个功能好用"是两码事。都有多文件编辑,但编辑后的冲突处理能力天差地别;都有Agent模式,但Agent的工具调用链深度和容错能力完全不同。
2.3 谁在认真做"工程",谁在堆"功能"?
这是本文最核心的对比。方法论先说清楚:
• ✅已确认:有公开文档、技术博客或可验证信息支撑 • ⚠️未确认:未公开或不明确,可能做了但没说,也可能没做 • ❌确认未实现:经确认不存在此机制

三个关键发现:
① 已确认的差距:Verification Agent(利益隔离验证)
这是Claude Code的杀手级设计——编码Agent和验证Agent是独立的,写代码的人不能自己验自己的代码。Trae有Selector Agent做补丁选择+多数投票,是国产工具中最接近的方案,但逻辑偏"从多个方案中选最优"而非"独立审查有没有问题"。其余工具确认无类似机制。
② 因"未公开"无法判断的差距
System Prompt分离、上下文压缩的具体实现——说实话,Claude Code也是因为源码泄露才知道的。国产工具不做声,不代表没做,但**"看不见"不等于"做得好"**。这恰恰是问题所在。
③ 已确认的国产亮点
•Trae:Lakeview摘要 + 回归测试验证 + 多数投票 → 三阶段流水线有工程深度 •CodeBuddy:三层Memory体系(Session/Project/Organizational)→ 长期记忆工程有独到之处;权限体系设计 → 最接近Claude Code的Fail-closed理念
Claude Code的源码泄露告诉我们:AI编程工具真正的壁垒在"AI之外"。但讽刺的是——正因为国产工具的工程实践不透明,我们连差距有多大都说不清。看得见的差距不可怕,看不见的才可怕。
三、收费模式:免费是真福利还是试用诱饵?
3.1 个人版定价全景
| 完全免费 | |||
几笔账算一下:
•MarsCode完全免费→ 目前是真正的免费,不是"免费试用"→ 适合轻度用户和学生党 •Trae免费10M Tokens→ 听着多,但Agent模式一次对话可能消耗数万Token,MAX模式更甚 → 够日常用,但重度用户会捉襟见肘 •通义灵码改名Qoder CN后,个人专业版从"限时免费"变为¥59/月(2,000 Credits),企业标准版从¥59→¥99/席/月(涨幅67.8%)→ "免费"的红利期正式结束 •CodeBuddy 500 Credits→ 基本不够用,专业版2000 Credits对于日均几十次调用的开发者也只是"勉强够";企业版5月15日起从¥78→¥198/人/月(涨幅154%)
3.2 企业版定价
3.3 计费模式背后的产品哲学
四种计费模式,四种哲学:
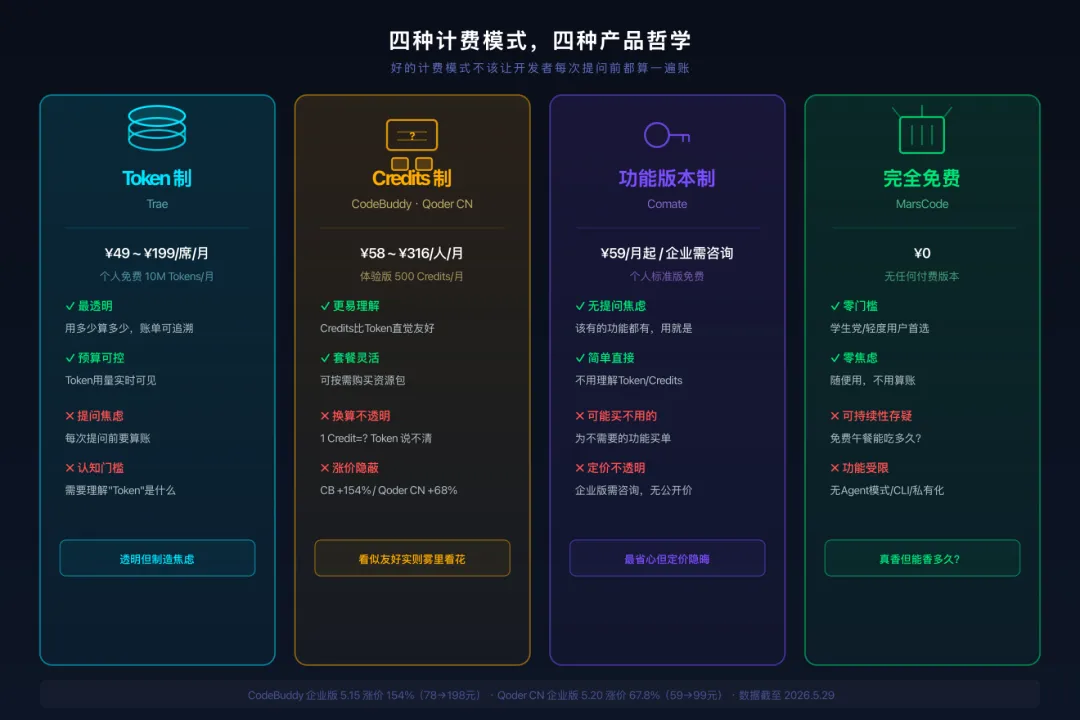
说句大实话:好的计费模式不该让开发者每次提问前都算一遍账。你在写代码的时候,最不想做的事就是思考"这个问题值不值得问"。Token制和Credits制虽然透明,但天然制造"提问焦虑"——问多了怕超,问少了效率低。功能版本制反而更让人放松:该有的功能都有,用就是了。
四、代码质量:同一个Prompt,谁写的代码最靠谱?
4.1 公开评测数据:谁在跑分,谁在实战?
目前各家公布的"成绩单":
看出问题了吗?口径完全不统一。通义灵码说的是"跑分",文心快码说的是"接受率",CodeBuddy说的是"准确率"——三个维度,无法横向比较。每家都说自己"超越GPT-4",但没人拿同一道题比过。这不是评测,这是各说各话。
4.2 实测方案:统一Prompt横评
坦诚说明:实测数据尚未跑出。与其编几个数字糊弄读者,不如先把测试框架亮出来,邀请大家一起测。
测试工具清单(6+2):Trae、Qoder CN、Comate、CodeBuddy、CodeGeeX、MarsCode + Claude Code、GitHub Copilot(参照)
3道实战题(从基础到实战,每道埋暗坑):
5维度评分标准(加权):
最终以红黑榜呈现——每个维度谁是冠军、谁翻车、有没有"一票否决"的致命伤(如密钥硬编码、击穿保护缺失等)。不做学术评分,直说谁行谁不行。
如果你有兴趣参与测试,欢迎按照以上Prompt跑一遍你常用的工具,把结果发给我。多一份样本,就少一分信息差。
4.3 中文场景:国产工具的真正主场
一个数据:Trae中文指令理解准确率95.3%,比Cursor高约18%(数据来自Trae官方,未经独立第三方验证)。
这个差距是真实的,也是合理的。国产大模型在中文语料上天然有优势,加上国内团队的中文场景优化,中文理解确实是国产工具的"入场券"。
但中文好只是入场券,不是免死金牌。你让一个中文理解100分的工具写一个满是安全漏洞的JWT中间件,它照样不靠谱。中文好是前提,不是结果。
五、终局判断:国产工具到底走到哪了?
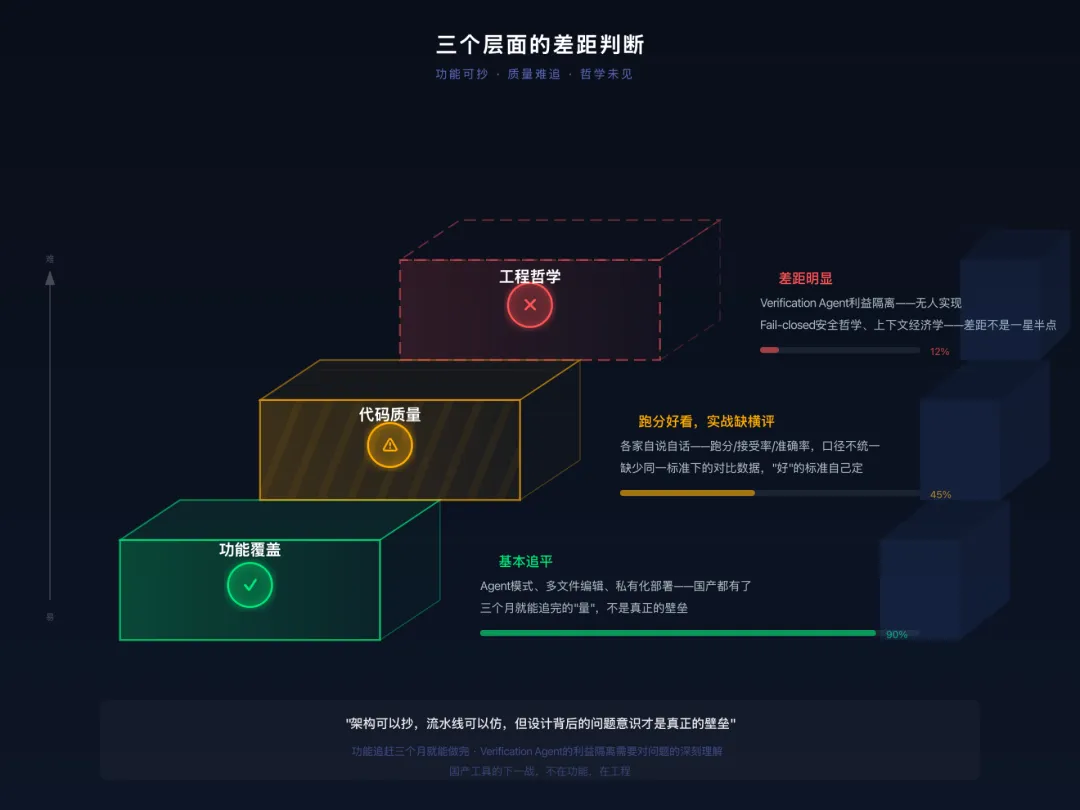
5.1 三个层面的差距判断
5.2 给不同人群的选购建议
如果你是个人开发者/学生:
• 试试MarsCode:完全免费,零门槛入门 • 想要Agent能力:Trae免费版够日常用,SOLO模式体验不错 • 需要CLI + 多模型切换:CodeBuddy体验版先摸摸底
如果你是团队技术负责人:
• 追求Agent深度 + 工程验证:Trae企业版(Lakeview + 回归测试 + 多数投票,国产最接近Claude Code的工程方案) • 重视安全边界 + 权限管控:CodeBuddy企业版(默认只读 + 沙箱 + 写入限制,Fail-closed理念最接近Claude Code;注意5月15日起企业版已涨至¥198/人/月) • 需要私有化部署 + 大模型自主可控:Qoder CN或Comate(背靠阿里/百度,私有化方案成熟)
如果你对中文场景有强需求:
•Trae95.3%的中文指令理解准确率是实打实的优势,尤其是中文注释、中文变量名场景
5.3 结尾
回到开头的那个问题:51.2万行源码泄露,到底有什么价值?
价值不在于"白嫖了架构",而在于它让整个行业看到了一个事实——AI编程工具真正的壁垒在"AI之外"。安全边界、上下文压缩、验证隔离、工具治理,这些不性感的工程细节,才是决定产品上限的东西。
国产工具的下一战,不在功能,在工程。
功能追赶是最容易的阶段——加个Agent模式、支持多文件编辑、搞个CLI,三个月就能做完。但Verification Agent的利益隔离、Fail-closed的安全哲学、三层上下文压缩的Token经济学——这些需要的是对问题的深刻理解,而不是对功能的快速复制。
而且,还有一个更大的问题:正因为国产工具的工程实践不透明,我们连差距有多大都说不清。Claude Code是因为源码泄露才让我们看到了它的工程深度;国产工具如果不主动公开,用户永远只能看到"功能列表",看不到"工程深度"。
希望有一天,国产工具不需要"源码泄露"来证明自己的工程实力。
📌下一篇预告:差距看清了,那两个月后呢?5月15日Qoder 1.0发布,宣称具备"自主执行、验证和交付"能力——这是否意味着Verification Agent的国产突破?CodeBuddy搭安全工具链、Trae疯狂迭代却方向模糊——6大工程实践完成度最高仅60%,System Prompt分离仍为0%。三个信号正在改写格局:免费到收费、补全到自主、功能到安全。《Claude Code泄露两个月后,国产AI编程工具到底进步了多少》,敬请关注。
附录:数据来源说明
•数据时效:本文功能对比数据截至2026年5月14日。5月15日Qoder 1.0发布、Trae 5月更新等后续变化,将在下一篇增量追踪中分析。定价数据更新至发文日 •市场份额数据:约25亿元(2025年,据多方估算),Trae 41%/通义灵码 19%/Comate 12%,为行业综合估算,非单一机构发布 •Claude Code泄露细节:基于Chaofan Shou公开披露信息及社区分析 •Claude Code架构信息:基于泄露源码的社区逆向分析 •功能对比数据:基于各产品官网、文档及公开信息整理,截至2026年5月14日 •定价数据:基于各产品官网公示价格,更新至发文日。CodeBuddy企业版5月15日调价(78→198元),Qoder CN企业版5月20日调价(59→99元) •Trae中文指令理解准确率95.3%:来自Trae官方公布数据 •通义灵码EvalPlus/MBPP超越GPT-4o:来自通义灵码官方公布数据 •文心快码代码接受率44%:来自百度官方公布数据 •GitHub Copilot代码接受率30-40%:来自GitHub官方公布数据 •工程实践对比:✅/⚠️/❌分类基于公开文档、技术博客及可验证信息,⚠️不等于"没做",仅表示"未公开确认"
