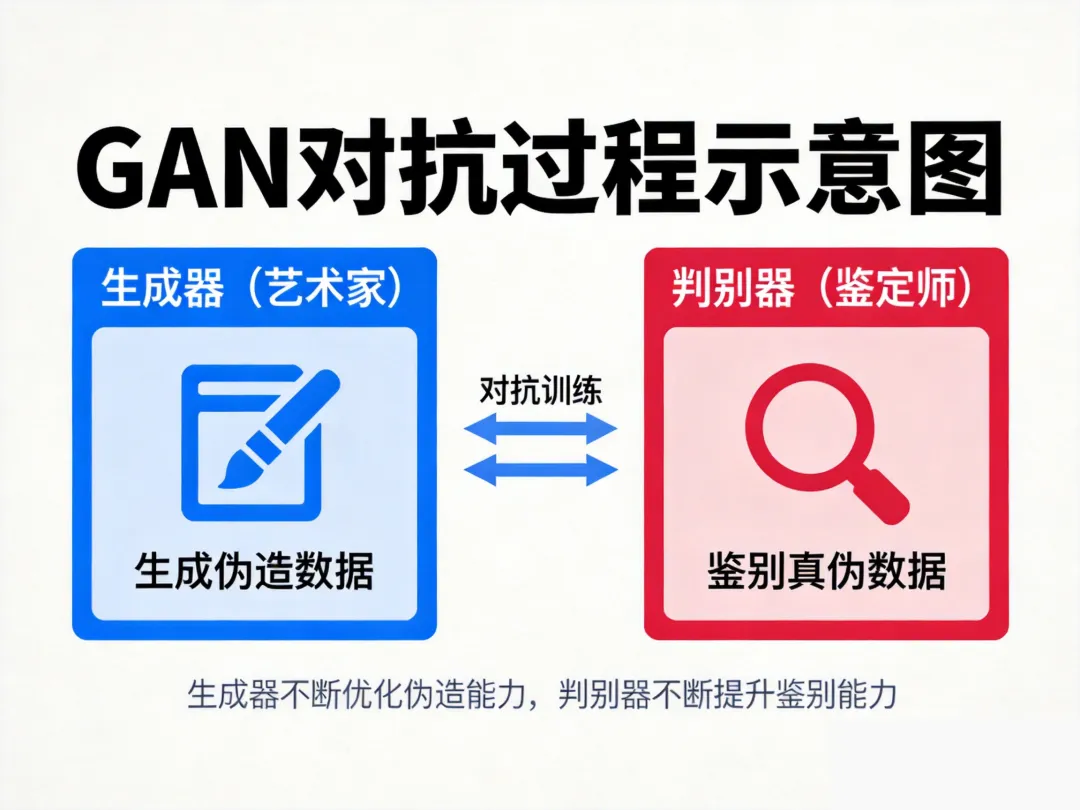
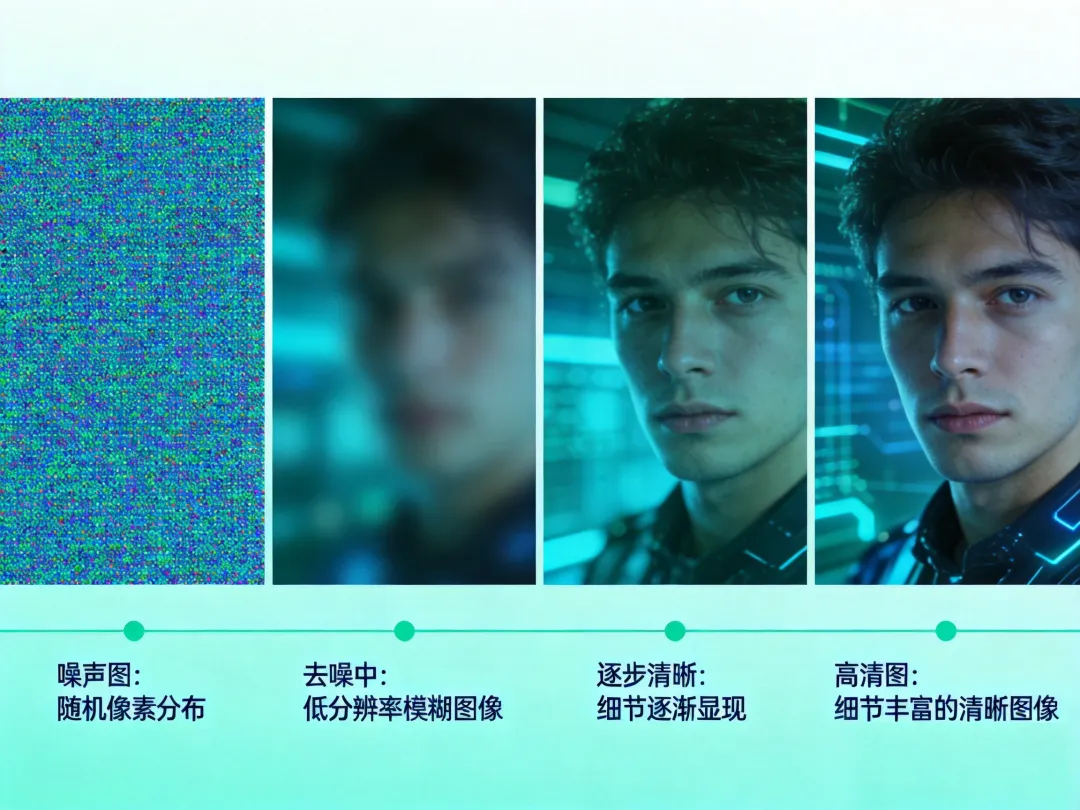
在 Figma 里反复调整一个按钮的圆角、阴影和渐变,灵感枯竭时随口说了一句:“要是能根据我的设计规范,自动生成一套图标就好了。” 现在,很多设计师已经可以做到:输入“暖色调、毛玻璃质感、微圆角 CTA 按钮”,AI 在几秒内就给出十几个可编辑方案。 这背后不是魔法,而是一套正在改变产品与设计工作流的技术系统—— Diffusion、GAN、CLIP 。 对产品经理和 UI/UX 设计师来说,理解它们,不是为了写代码,而是为了知道: 这篇文章,我们不讲复杂的数学公式,只 从产品和设计的视角 ,把这三位“幕后主角”彻底讲清楚。 一、GAN:那个让“假图”以假乱真的老前辈 GAN(生成对抗网络)是这场视觉生成革命的起点,它的核心思想非常像一场“艺术家与鉴定师”的博弈。 判别器(鉴定师) :负责判断这张图是“真品”还是“赝品”。 两人相互对抗、共同进化——艺术家越画越像,鉴定师眼光越来越毒。直到有一天,艺术家画出的图像连鉴定师都分不清真假。 它第一次证明了计算机可以“无中生有”,而且可以生成高清、逼真的图像。 很容易陷入“模式崩塌”——只会画同一类东西(比如只会画猫,不会画狗) 所以在产品层面,GAN 更多被用于 风格迁移、人脸编辑、图像修复 等特定任务,而不是作为一个开放式的“文本生图”工具。 它像一位天赋极高但情绪不稳的艺术家——你需要非常小心的调教,才能让他稳定发挥。 二、 Diffusion:从一片“雪花屏”中慢慢走出来的主角 如果说 GAN 是“一锤定音”,那 Diffusion 就是“渐进去噪”。 第一步(前向过程) :拿一张清晰图像,一步步往里面加噪声,直到它变成完全随机的“雪花屏”。 第二步(逆向过程) :让模型学习“如何从噪声中一步步恢复出清晰图像”。 当模型学好了这个过程,你只需要给它一段随机噪声,它就能像从迷雾中走出来一样,一步步生成一张全新的、清晰的图像。 为什么 Diffusion 能成为今天 AI 绘画的主流? 每一步去噪都是可追踪的,即使中间某一步出现偏差,后续步骤也能修正回来。不像 GAN 那样,一步走错满盘皆输。 它可以接受额外的“引导信号”(比如一段文字描述),然后根据这个信号去噪。这就是它能“听懂人话”的关键。 因为 Stable Diffusion 的开放策略,你可以把它部署在自己的电脑上、接入自己的设计系统、甚至微调成专属风格模型。这对产品团队来说意味着—— AI 能力可以私有化、定制化 。 一句话理解 Diffusion: 它像一位耐心、稳定、听得懂要求的画师——你给一段描述,它从一片噪点中慢慢把它画出来,而且每一步都可以干预。
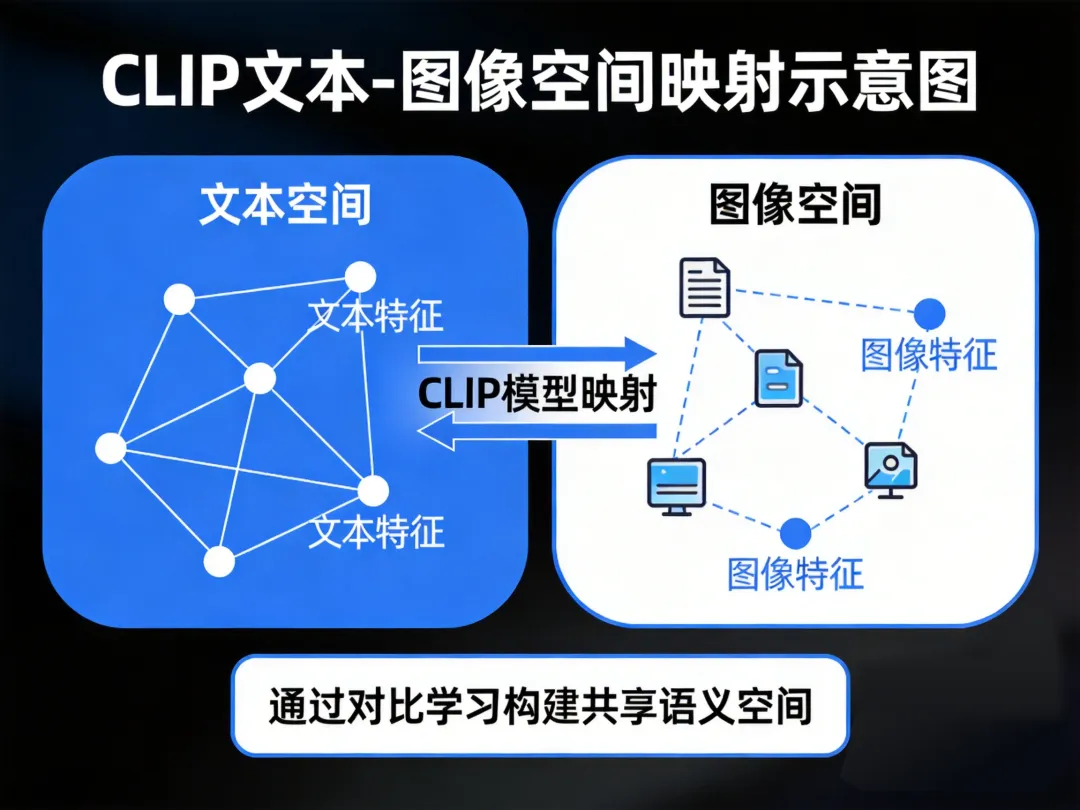
三、 CLIP:那个让 Diffusion“听懂人话”的翻译官 Diffusion 很强大,但它有一个天然的问题: 它只懂图像,不懂语言 。你输入“一只穿宇航服的企鹅”,它完全不知道你在说什么。 CLIP(对比语言-图像预训练模型)做的事很简单,也很了不起: 它学习了海量的“图像-文本”对,然后把 文本和图像映射到同一个语义空间 。 在这个空间里,“蓝色天空下的红色气球”这段文字,和真正的蓝色天空红色气球图片,向量距离非常近;而和一段无关的文字或图片,距离非常远。 CLIP 告诉 Diffusion“要画什么”,Diffusion 负责“怎么画得好”。
✅ 能处理复杂的组合概念(“穿宇航服的企鹅在火星打高尔夫”) ✅ 零样本泛化能力强(不需要专门训练就能理解没见过的新组合) ❌ 复杂文字渲染(比如生成清晰的菜单文字)仍然较弱 ❌ 多对象精细交互(“两个人握手时的阴影关系”)容易出错 这些边界,就是今天 AI 绘画工具“翻车”的根本原因。 2015 :Diffusion 理论出现,但很长时间停留在学术圈 2021 :CLIP 发布,彻底解决了“跨模态对齐”问题 2022 :Diffusion + CLIP 组合爆发(DALL·E 2、Stable Diffusion 等),AI 绘画真正出圈 因为 Diffusion + CLIP 这个组合,恰好同时解决了“稳定生成”和“语义理解”两大难题。 而 GAN 并没有消失,它在 小样本生成、实时风格迁移、视频生成 等场景下仍有优势。未来更可能是“多模型协作”——GAN 做快速草图,Diffusion 做精细渲染,CLIP 做跨模态理解。 对产品设计团队来说,不需要纠结用哪个模型,而是要知道: 今天的 AI 生成能力,本质上是“可控生成”+“语义对齐”的结合。 你提供的条件越清晰(文本、草图、参考图),AI 的输出就越可控。
一年前,多数设计师对 AI 的态度还是“玩一玩”。现在,越来越多的团队已经把 AI 嵌入工作流: 原型阶段 :输入“电商商品详情页,包含大图、标题、价格、购买按钮、评价区”,AI 直接生成可编辑的低保真原型。 UI 阶段 :在 Figma 里选中一个组件,右键“生成类似风格图标”,AI 按你的设计规范输出多个选项。 UX 阶段 :输入用户画像和任务目标,AI 生成多套信息架构方案供你评审。 AI 不是替代你画图,而是替你完成 重复性的、探索性的“脏活累活” ,让你聚焦于判断与决策。 2. 能力层面:什么才是 AI 时代设计师的核心竞争力? 我们做了个小调研,问了几十位产品与设计同行,大家比较一致的看法是:AI 不会让你失去价值,但会改变你的价值来源。 判断力 > 执行能力:知道“什么方案是对的”比“画出那个方案”更重要 系统思维 > 单点输出:能控制品牌风格一致性、信息层级、交互逻辑,而不是被 AI 的随机输出带着跑 AI 控制力 > 关键词堆砌:能用“设计语言”和 AI 对话,而不是依赖“赛博朋克、炫酷、高级感”这种模糊词 未来优秀的设计师,不是画得最快的人,而是能 最精准地定义问题、最有效地引导 AI 输出 的人。
版权归属 :AI 训练用了大量已有作品,生成的图像版权到底归谁?(目前各国法律尚无统一答案) 真假难辨 :以假乱真的生成内容已对信息真实性构成挑战,深度伪造可以用于虚假信息和欺诈。 一个有趣的趋势正在发生: “反 AI 造物” ——刻意追求手工艺感、随机性和“不完美”的痕迹,反而成为新的高端设计符号。因为 人为的不完美中,蕴含的“人类痕迹”正在变得稀缺。 这不是反对技术,而是提醒我们: 设计的本质不是“产出图像”,而是解决问题、传递情感、建立信任。 AI 再强,也做不到这一点。 六、 行动指南:5 个你现在就可以尝试的 AI 设计工具 读完理论,不如亲手试试。以下 5 个工具按从“完全免费/本地”到“深度集成工作流”排列: Stable Diffusion 4(本地版) ComfyUI 节点式工作流,精确控制 Diffusion 每一步 Midjourney (最新版) Figma AI (内测功能) Recraft v3
建议从 Stable Diffusion + ComfyUI 组合开始,本地跑通一个“文生图”流程,你会对 Diffusion 的每一步有直观感受。 写在最后 这篇文章是我们“AI + 产品 + UI/UX 设计”系列的第一篇。 我们不追求堆砌术语,而是希望帮助每一个产品人和设计师, 真正理解技术背后的逻辑,然后把它用在自己的工作中 。 如果你想看,或者你希望 AI 在 2026 年帮你解决某个具体的设计难题,欢迎在评论区告诉我们。 设计不会消失,但“只会画图的设计”会。 懂 AI、会用 AI、能定义 AI 产品体验的设计师,才刚刚迎来最好的时代。
—— 与你一起,探索 AI 时代的下一代产品与设计体验。
 夜雨聆风
夜雨聆风