 夜雨聆风
夜雨聆风AI模型的"粮食"怎么炼成?一文读懂《高质量数据集建设指南》
在人工智能火热的今天,很多人关注算法、算力,却忽略了一个关键基础——数据。尤其是高质量数据集,它就像AI的"粮食",直接决定了模型能不能"吃得饱、吃得好"。
那么,什么是高质量数据集?怎么建?有什么用?今天我们就来聊聊《高质量数据集建设指南》中的核心内容。
什么是高质量数据集? |
高质量数据集,简单说就是能让AI模型训练更高效、结果更准确的数据集合。它不仅是技术问题,更是系统工程。
当前面临四大痛点
| 建设路径不清晰:很多人不知道从哪开始,流程混乱,缺乏系统性的建设方法论。 | |
| 标准缺失:没有统一的方法论,数据质量参差不齐,难以形成规模化供给。 | |
| 供给不足:优质数据稀缺,模型训练受限,"数据饥饿"现象普遍。 | |
| 与需求脱节:建出来的数据用不上,价值释放不充分,供需错配严重。 |
指南带来的价值
| 规范流程:从需求到验证,全流程有章可循,降低建设门槛。 | |
| 统一标准:每个阶段都有方法指导,提升数据质量的一致性和可复用性。 | |
| 赋能AI:产出更多优质数据集,支撑模型开发,夯实智能底座。 | |
| 贴近实际:引导建设如工业质检、医疗诊断等实用数据集,拒绝"空中楼阁"。 |
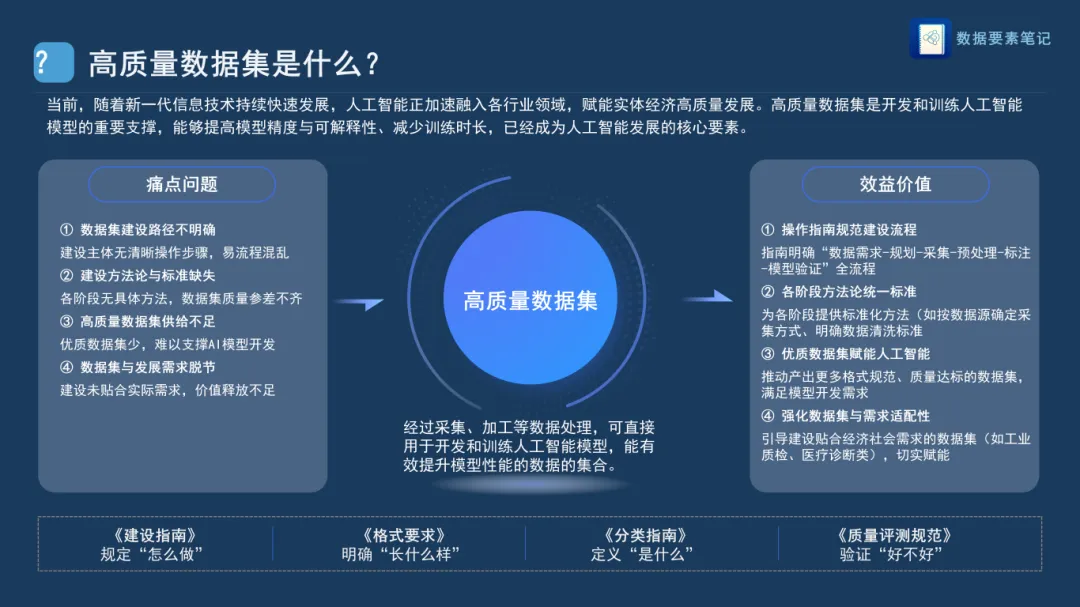
高质量数据集在可信数据空间中有什么用? |
如果把可信数据空间比作一个"数据流通的机场",那高质量数据集就是符合安检标准的乘客——只有经过严格筛选和标准化处理的数据,才能顺利"登机"并在流通中创造价值。
数据流通全流程中的关键角色
| 流通环节 | 高质量数据集的作用 |
|---|---|
| 数据接入 | |
| 数据封装 | |
| 数据上架 | |
| 数字合约 | |
| 数据交付 | |
| 使用与审计 |
💡 举个例子:某医疗影像数据集必须注明"设备类型、拍摄时间"才具备接入资格;某电商用户数据必须"经用户授权"才能合规使用。高质量标准让这些规则有据可依。
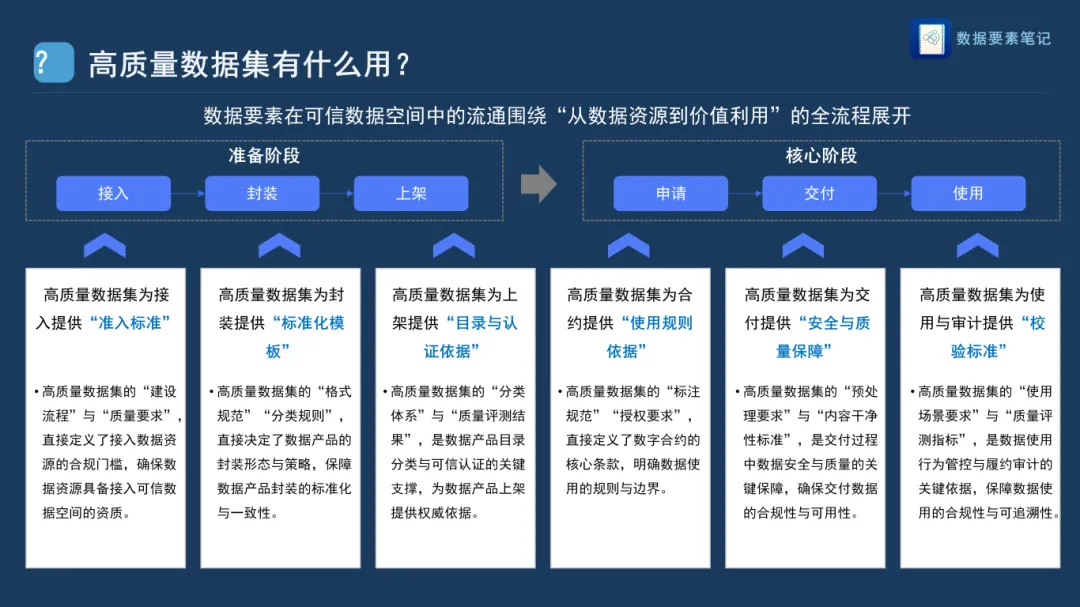

高质量数据集怎么建? |
指南提出了六步建设法,每一步都不能少。这就像做一道菜:先想好做什么(需求),再买食材(规划+采集),然后洗切备料(预处理),最后调味出锅(标注+验证)。
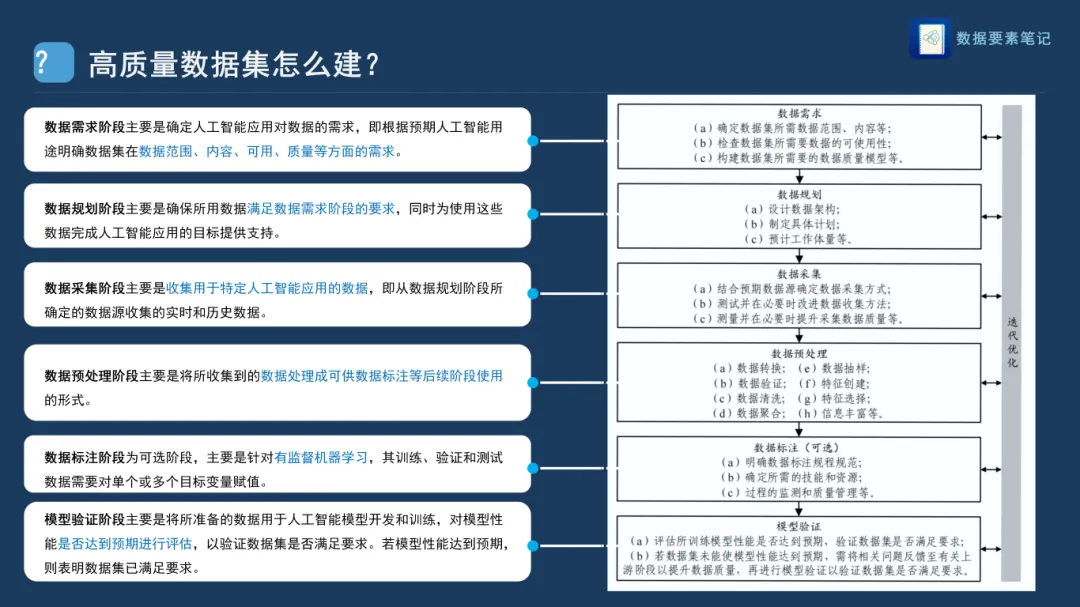
数据需求明确AI应用需要什么样的数据(范围、内容、质量等),回答"为什么建"的问题。 |
数据规划确保数据能满足需求,并为AI目标服务,设计整体建设蓝图与资源配比。 |
数据采集从规划好的数据源中收集实时或历史数据,建立稳定、合规的数据供给通道。 |
数据预处理清洗、转换数据,去除噪声与异常,为后续标注或建模做准备。 |
数据标注(可选)适用于有监督学习场景,为目标变量赋值,建立"数据-知识"映射。 |
模型验证用训练结果反推数据是否达标,形成闭环反馈,持续优化数据集质量。 |
写在最后
《高质量数据集建设指南》不仅是一份技术文档,更是一套可操作、可落地的方法论。
它解决了"数据怎么建、怎么用、怎么评"的根本问题,是推动AI从"讲故事"走向"干实事"的关键一步。
别再只盯着模型,先看看你的"粮食"够不够好。
觉得有用?欢迎点赞、收藏、转发给更多做AI的小伙伴
👍 点赞支持