 夜雨聆风
夜雨聆风
导语
最近一年我们接触了不少企业的 IT 部门、数据部门和数智化部门,频繁听到同一类对话:
这不是个别现象。Gartner 早在去年 6 月发布的预测就量化了这种困境:超过 40% 的 Agentic AI 项目预计将在 2027 年底前被叫停,3 个主因是价值不明、成本超支、风险失控。
这 3 点看似各自独立,实则指向同一个更前置的问题——方向没选对、产品没选对。
本期我们结合项目实践,帮你理清4件事:避开哪些误区、选什么场景、为什么是 Data Agent 方向、怎么选产品。
01 AI 转型项目的 3 个误区
接到任务后,很多团队的第一反应是直接进入技术选型:接一个大模型、搭一个知识库、上一个 Agent 平台。看起来动作很快,但方向从一开始就走偏了。
这背后有一个共同的根源:都是从“能做什么技术”出发找场景,而没有从“要解决什么业务问题”去判断 AI 是否合适。

误区 1:为了 AI 而 AI
老板说要做 AI,大家开始找场景,往往优先找“容易做”或“容易汇报”的,而不是真正有业务价值的。
正确的路径应该反过来:先找业务部门、管理层的真实数据痛点,再判断 AI 是否适合解决。
误区 2:把聊天机器人当 AI 项目
很多企业第一个 AI 项目都是“企业 GPT”——问制度、问流程、问知识。上线后使用率越来越低,原因很简单:员工原来不查文档,现在也不会因为换成聊天框就突然开始查。
Gartner 将这类现象称为"Agent Washing"——交互方式变了,业务价值却没有本质提升。
误区 3:无法量化价值
很多项目上线后只能评价说“方式很智能”、“效果还可以”,却回答不了两个基本问题:
技术部门的工作效率提升了多少?
业务部门和管理层获取数据分析结论是不是更快、更准了?
价值没有被清晰定义的项目,自然经不住复盘。这也是 Gartner 在同一份预测里明确建议的:仅在能够带来明确价值或投资回报率的情况下,才应采用 AI Agent。
02 选场景的 5 个判断标准
既然方向比技术更重要,那就先明确什么样的场景值得做。从我们参与的大量项目来看,一个能跑通、经得起复盘的 AI 场景,通常同时满足以下五个条件。

条件 1:高频——每天都在发生
如果一个场景一个月才触发一次,即使 AI 做得再好,价值也难以被感知和累积。优先选那些企业每天都在做的事,例如查经营数据、追进度、看异常、做对比。
条件2:结果可验证——有标准答案
AI 最大的风险是幻觉。对于要对数据准确性负责的技术团队来说,一旦 AI 给出一个错误数字,整个项目的信任基础就会崩塌。因此要优先选"有标准答案"的场景。
“华东昨天销售额多少”——答案来自数据库,可以核查;
“公司未来三年战略怎么走”——没有标准答案,不适合作为 AI 落地的起点。
条件 3:价值链足够长——从查数到给结论
这是最容易被低估、也是对管理层最有说服力的标准。如果 AI 只是让查数更快,但归因分析和决策建议还是要靠人来做,那 AI 只替代了最简单的环节,价值远没有最大化。
条件 4:不依赖大规模流程改造
需要重建流程、调整组织架构、改变考核机制的 AI 项目,推进阻力极大。真正能跑通的,往往是在现有工作习惯基础上提升效率:
数据团队少做重复取数,业务部门少等报告;
管理层从"等结论"变成随时获得经营洞察和归因建议,指标异动时系统还可以主动推送预警,而不必靠人盯着看板。
条件 5:第一个场景能成为后续扩展的基础
1个可以持续扩展的平台,比10个孤立的 Demo 更有说服力。销售分析、财务分析、库存分析、供应链分析——这些场景背后需要的核心能力是共通的:数据连接、语义理解、归因逻辑。第一个场景做扎实了,后续扩展有基础,持续申请预算才有底气。
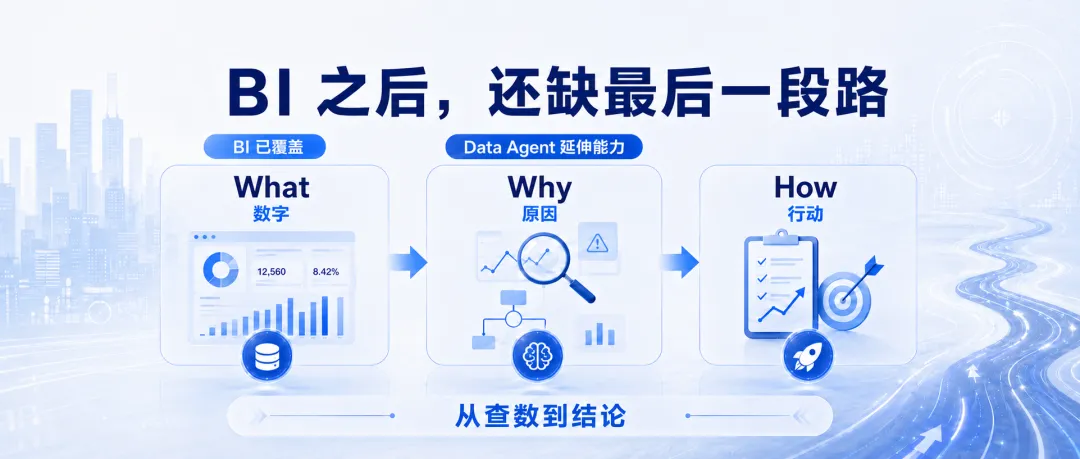
03 BI 之后,还缺“从数字到结论”的最后一段路
过去几年企业在 BI 上投入巨大,解决的是“What”:销售额多少、库存多少、利润多少。但业务层和决策层更想知道的是:
Why——为什么销量下降?为什么库存积压?为什么利润变差?
How——应该调整哪些区域?应该优化哪些商品?应该控制哪些费用?
这部分内容长期依赖资深分析师、数据团队、外部咨询公司——成本高,且无法规模化。
更棘手的是,要真正洞察 Why 和 How,往往还需要跨业务域拉通数据——各部门口径不统一、数据分散在不同系统,每做一次跨域归因分析都要对数、整理,周期长、存在误差风险。这进一步放大了能力瓶颈。
而这正是新一代 Data Agent 的切入点:它不是对 BI 的简单修补,而是把“从 What 到 Why 到 How”这条链路重新设计,变成可以稳定复现的自动化能力。
这个方向已成为行业共识。
被淘汰的是方向错误的项目,而不是这个方向本身。
04 选产品时最该关注的 3 件事
方向确定后,下一步是选产品。数据团队在评估产品时,建议重点关注3个问题:
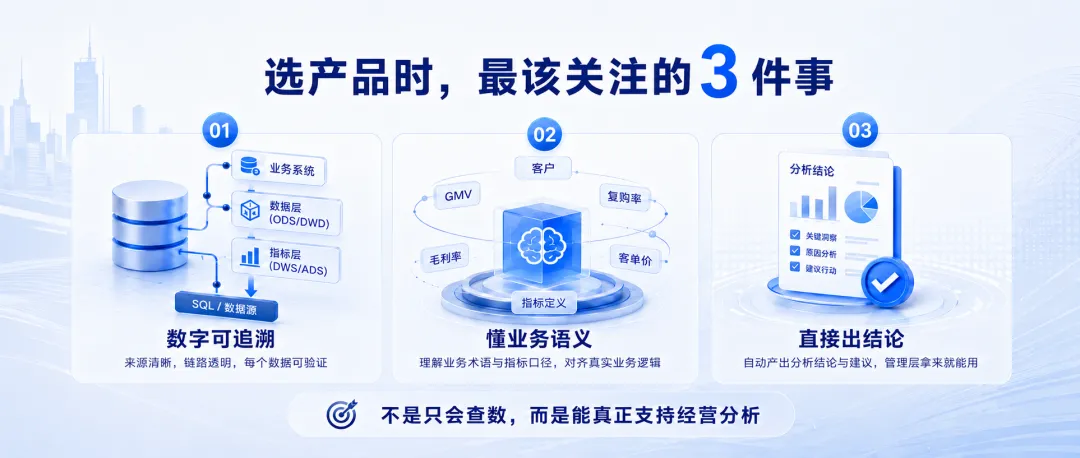
Q1:查出来的数字,能不能追溯来源?
AI 给出一个销售数字,业务部门的第一反应是:“这个数怎么算的?和我们自己算的对得上吗?” 如果系统只能说"大模型生成的,管理层不会把这个结论带进经营会议。可追溯性不是加分项,而是及格线。
评估时要看:系统是否展示了完整的计算过程?每个数字能否回溯到具体的数据源和 SQL 逻辑?
Q2:系统能不能理解这家公司的业务语义?
数据库里存的是字段名,业务部门说的是业务概念。
"销售额"是含税还是不含税?
"完成率"的分子分母是哪两个指标?
"华东区"包含哪些省份?
如果系统不理解这些语义,业务部门每次提问都要反复调整措辞,数据团队要不断介入修正——用几次之后就会放弃。这是经营分析场景使用率下滑最常见的直接原因。
评估时要看:系统是否有语义建模能力?能否把企业自己的指标口径、业务定义沉淀进系统?
Q3:输出的是结论,还是只是数据?
很多产品能帮用户更快地查到数字,但业务部门拿到的是一堆表格和图表,还需要自己理解、加工、整理成报告。这本质上只是换了一个查询界面,分析工作量并没有减少。
所以评估时还要再看一下:系统是否支持自动归因?能否生成可直接使用的分析报告?输出格式是否符合管理层的阅读习惯?
05 我们的实践经验
可追溯、懂语义、出结论——这3件事,也是我们在每个企业级项目中坚持做到的标准。
数字必须可信——管理层能直接验证,不需要“先相信 AI 再说”
经营会上用的数字,每一个都要经得起追问。
我们的做法是:每个数字都能回溯到具体的数据源和完整的计算逻辑,管理层可以直接验证,数据团队也不需要在会议室里现场解释"这个数怎么来的"。
背后的技术支撑是自研的 NL2LF2SQL 引擎(Alisa)——核心查询环节由确定性算法完成,不依赖大模型直接生成 SQL。5秒内、“无限上下文”、复杂语义、稳定输出:NL2SQL 怎么同时做到?
系统必须理解业务——用业务语言提问,得到基于正确口径的结论
“销售额”在你们公司是含税还是不含税?“完成率”的分子分母是哪两个指标?这些定义不在数据库里,只存在于业务人员脑子里。
我们在每个项目中都会做企业语义建模,把这些业务定义沉淀进系统(SemanticDB),让业务部门用自己的语言提问,不需要学习“怎么跟 AI 说话”。这是准确率能够长期稳定的真正原因。NL2SQL 的天花板,NL2LF2SQL 是怎么突破的?
输出必须能直接进入工作流——不是给一堆数字,是给一份可以直接用的报告
亿问 Data Agent 支持从提问到归因到报告的完整链路,生成的分析报告能直接用于经营会汇报,不需要数据团队再花时间整理和包装。
06 写在最后
AI 转型正在从“展示能力”、进入“创造价值”的阶段。
对于大多数企业而言,与其追逐最新的模型能力,不如先想清楚:哪个场景最值得做?价值怎么衡量?如何确保项目真正落地?
这些问题想通了,AI 才能从一个展示案例,成长为真正赋能企业经营的基础能力。
亿问 Data Agent 现已开放产品演示
欢迎扫码体验!


往期推荐

我们花了十年把表做成 BI 喜欢的模样,现在 AI 说:我不喜欢

关于我们


