 夜雨聆风
夜雨聆风YC 合伙人 Pete Koomen 与 Lightcode 主理人 Gary 展开对话,首次公开 YC 内部 AI 基础设施的构建历程。Pete 是 Optimizely 创始人,过去一年半主导了 YC 内部所有 Agent 基础设施的建设,从财务团队的自动化工具起步,逐步演变为覆盖全公司的 Agent 操作系统。
这期对话完整呈现了 YC 从零搭建内部 AI 基础设施的实战路径,核心判断是:真正的组织级智能不是靠单个 Agent 工具,而是靠统一的数据层、工具注册表和技能自进化机制。Pete 用 YC 内部的真实案例——从 SQL 查询到两句话描述技能的自进化——展示了这套架构如何让组织智能持续提升。
这期是 YC 首次公开内部 AI 基础设施的完整架构,信息密度极高,Pete 的视角兼具创业者(Optimizely 创始人)和投资人(YC 合伙人)的双重稀缺性。下面是整理后的 7 章笔记,完整内容建议听原片(链接在文末)。
阅读导览
为什么 YC 能比大多数公司更快地用上 AI? 如何用统一数据库让 Agent 回答任意业务问题? 工具注册表为什么是组织级 Agent 的关键基础设施? 技能自进化循环如何让 Agent 持续变强? 为什么说当前 Agent 仍处于“单人模式”时代? 如何用“两句话描述”技能实现组织知识沉淀? 从单 Agent 到多 Agent 协作,最大的瓶颈是什么?
第一章:统一数据层是 Agent 基础设施的起点
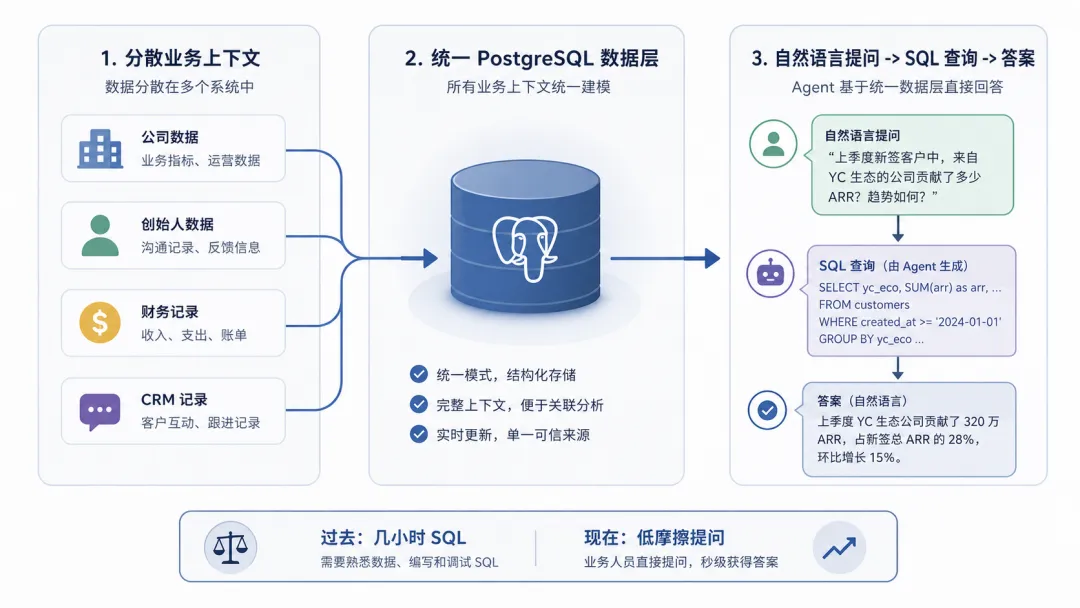
YC 之所以能在 AI 基础设施上快速推进,最根本的优势在于他们运行在自己的软件上,所有核心业务数据都存放在同一个 PostgreSQL 数据库中。这意味着公司信息、创始人信息、财务交易、内部 CRM 笔记——所有关键上下文都在一个地方。当 Pete 的团队给 Agent 加上只读 SQL 查询工具后,任何人都可以用自然语言问出“过去四期批次中投资了航天相关公司的投资者有哪些”这类复杂问题。
这个看似简单的功能带来了质变。过去用 BI 工具回答同样的问题需要写几小时 SQL,除非问题极其重要,否则没人会去问。但 Agent 让提问成本趋近于零,团队开始问更多、更复杂的问题。Pete 指出,这本质上是 Jevons 悖论的新实例——当获取答案的摩擦降低,需求会爆炸式增长。大多数公司仍然生活在需要跨部门排队等数据的世界里,而 YC 用统一数据层直接跳过了这个瓶颈。
第二章:工具注册表——将通用 Agent 转化为组织专用工具
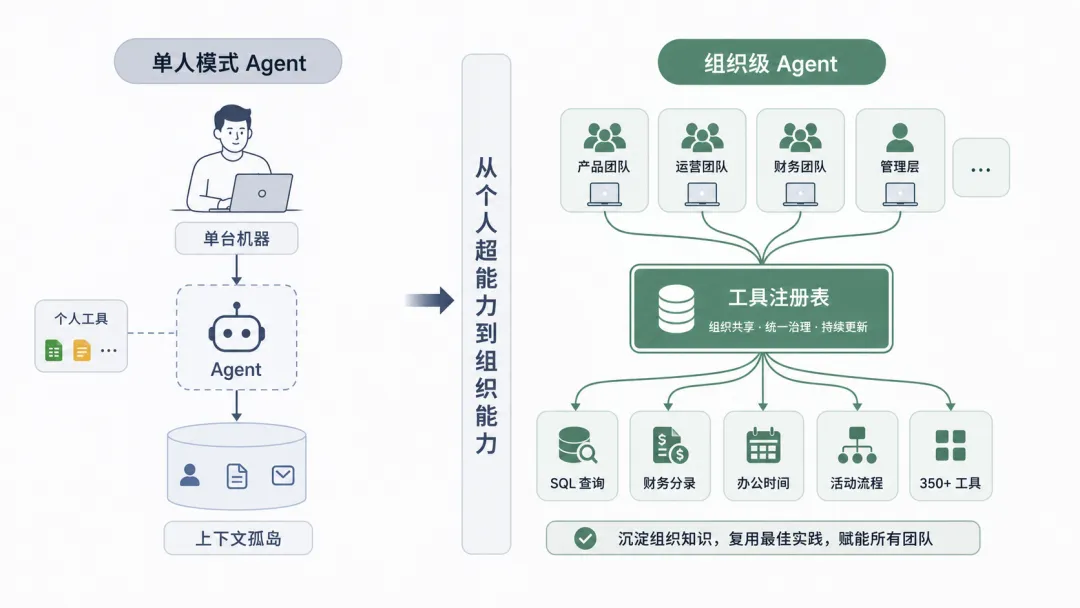
YC 内部 Agent 基础设施的核心组件是一个共享的工具注册表。最初只有 20 个工具,包括那个神奇的 SQL 查询工具。但随着时间的推移,每个团队都在往注册表里添加自己的工具——管理办公时间、记录财务分录、管理活动流程——到今天已经超过 350 个。每个工具都封装了 YC 特有的业务逻辑,让通用 Agent 能够处理具体工作场景。
工具注册表的价值在于它既是基础设施,也是协作平台。Pete 强调,这些工具不仅可以被 YC 内部构建的 Agent 调用,也可以被个人机器上运行的 Claude Code 等外部工具使用。这意味着工具注册表实际上成为了组织知识的编码层——每个工具都是一段可复用的业务能力。当团队遇到可以用 Agent 改进的工作时,他们只需要添加一个新工具,而不是重新构建整个系统。
第三章:从单人 Agent 到组织级智能的跨越
Pete 指出,当前 Agent 工具生态仍处于“单人模式”时代。Claude Code、Codex、OpenClaw、Hermes 等热门工具都是为单个用户、单台机器设计的。它们让个人变得极其强大,但如何将这种超能力扩展到团队和组织层面,还没有被很好地解决。
YC 内部基础设施的探索价值在于,他们正在尝试解决这个“多人协作”问题。Pete 认为,关键不在于构建更强大的单个 Agent,而在于创建能让团队共享 Agent 能力的原语。统一数据层和工具注册表就是这样的原语——它们让不同团队可以基于同一套基础设施构建自己的 Agent 工作流,同时保持上下文的连贯性和工具的可复用性。
第四章:技能的自进化循环
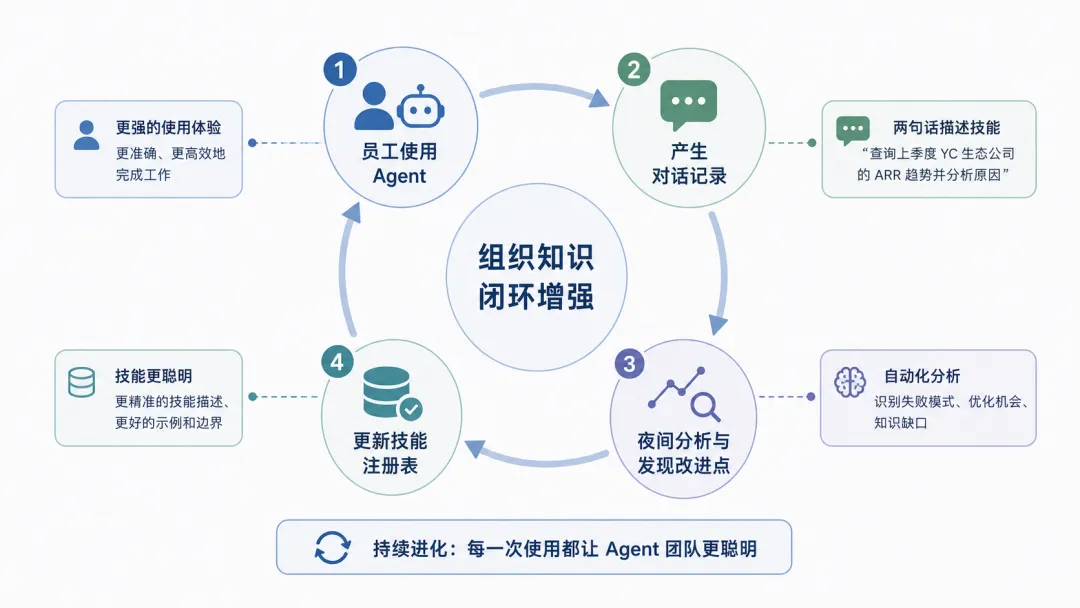
YC 内部已经出现了技能自进化的闭环。他们有一个通用 Agent,每晚自动读取所有员工的 Agent 对话记录,寻找可以改进的地方——哪些上下文如果提前提供会让任务更高效,哪些技能可以优化。这个机制类似于 OpenClaw 的“梦境循环”和 GBrain 的“梦境循环”,但 YC 将其应用到了组织层面。
具体案例是“两句话描述”技能。YC 合伙人 Tom 最初写了一个手工提示词,教 Agent 如何根据公司背景写出简洁的两句话描述。后来其他合伙人在与春季批次公司的办公会上,让每个创始人练习写两句话描述并给予反馈。这些会议记录被反馈给 Agent,Agent 读取后自动改进了“两句话描述”技能。Pete 说,改进后的技能已经比他自己写得更好。这就是组织内部超级智能的形成方式——知识从人的头脑流入对话记录,再从对话记录流入 Agent 技能,形成一个持续增强的循环。
第五章:技能注册表与“可解析性”原则
在 Agent 工具生态中,一个反复出现的模式是“技能注册表”或“工具注册表”作为解析器(resolver)存在。Pete 观察到,Claude Code 的技能注册表、YC 内部的工具注册表、OpenClaw 的 skillify 功能,本质上都在做同一件事:将可复用的能力注册到一个中心化的目录中,让 Agent 能够发现并调用它们。
在此基础上,Pete 提出了一个更高级的原则:技能注册表不仅要做到 DRY(不重复自己),还要做到 MECE(相互独立、完全穷尽)。他发现,当技能注册表同时满足这两个条件时,模型似乎天然就能更好地理解和使用这些技能。他开发了一个名为“check resolvable”的元技能,每次创建新技能后都会运行它,检查是否有重复或遗漏。这听起来像咨询公司的术语,但在实践中,它确实让 Agent 系统更加高效和可靠。
第六章:从单数据库到“大表”模式的回归
Gary 将 YC 的统一数据库策略类比为 Google 的 Bigtable 和 Karpathy 的 LLM Wiki。他认为,当前 Agent 时代正在回归一种“大表”模式——将分散在不同系统中的数据反范式化,放入一个针对 Agent 检索优化的统一格式中。无论是通过 MCP 协议包装,还是直接使用 CLI 接口,关键都是让 Agent 能够在一个地方找到所有需要的上下文。
Pete 认同这个观察。他指出,YC 的单一 PostgreSQL 数据库实际上就是一个针对 Agent 优化的“大表”。当所有重要上下文都在一个 schema 中,Agent 可以回答任意业务问题,而不需要在多个系统之间跳转。对于大多数运行在第三方 SaaS 工具上的公司来说,这确实是一个巨大的挑战——但也是一个巨大的机会。将内部上下文整合到一个统一的数据仓库中,是任何组织都可以开始做的事情。
第七章:组织级 Agent 基础设施的三个核心原语
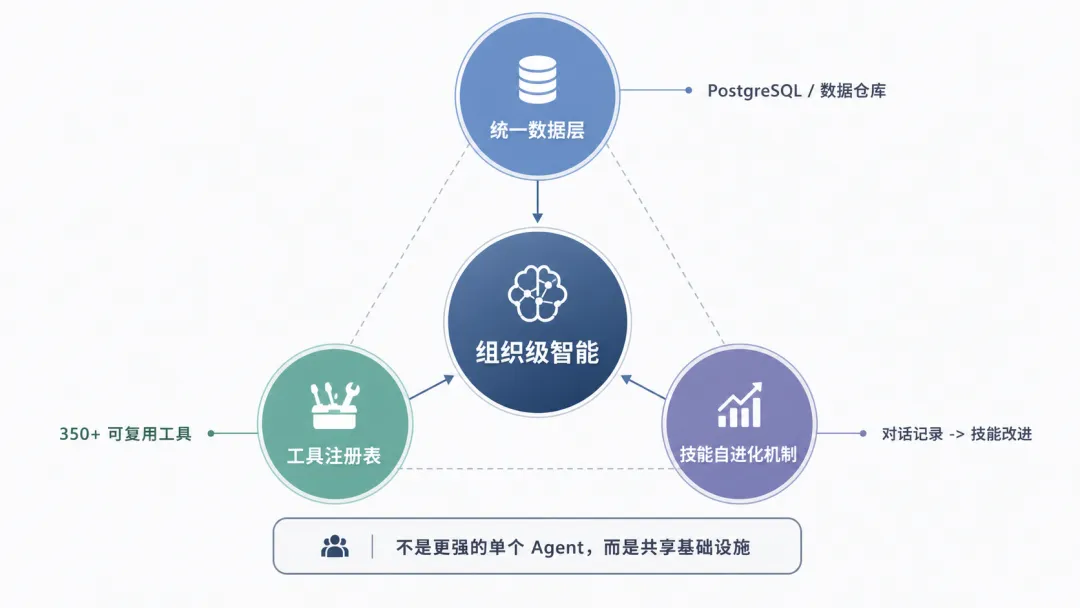
Pete 总结,如果要在任何组织中构建 Agent 基础设施,应该聚焦三个核心原语。第一是统一的数据层——一个数据仓库,让尽可能多的内部重要上下文集中存放。第二是内部的工具注册表——一个中心化的目录,让团队可以注册和共享可复用的工具。第三是技能的自进化机制——让 Agent 能够从使用记录中学习并自动改进。
这三个原语共同构成了一个“共享的组织大脑”。Pete 强调,这不仅仅是技术基础设施,更是一种组织能力的进化方式。当每个员工都能通过 Agent 调用整个组织的集体知识和技能,当 Agent 能够从每次交互中学习并改进,组织就获得了一种持续自我增强的智能。这可能是 AI 时代组织竞争力的真正来源。
值得反复回看的观点
统一数据层是 Agent 基础设施的起点——当所有业务上下文集中在一个数据库中,Agent 可以回答任意问题,提问成本趋近于零,需求会爆炸式增长。 工具注册表是组织级 Agent 的关键基础设施——350 多个 YC 特有工具封装了组织知识,让通用 Agent 能处理具体业务场景。 技能自进化循环让 Agent 持续变强——Agent 从员工对话记录中学习并自动改进技能,形成组织知识的闭环增强。 当前 Agent 仍处于“单人模式”时代——让个人变得极其强大的工具已经成熟,但组织级协作的 Agent 基础设施还没有被很好地解决。 技能注册表要做到 DRY 和 MECE——不重复且相互独立、完全穷尽的技能注册表,能让模型更高效地发现和使用技能。
最后总结
YC 内部 AI 基础设施的核心价值在于证明了:组织级超级智能不是靠更强大的单个 Agent,而是靠统一数据层、工具注册表和技能自进化循环这三个原语。Pete 的视角之所以稀缺,是因为他同时经历了创业者(构建 Optimizely)和投资人(YC 合伙人)的双重角色,并且亲自领导了 YC 从传统软件组织向 AI 原生组织的转型。他用 YC 内部的真实案例——从 SQL 查询到两句话描述技能的自进化——完整呈现了这套架构的构建逻辑和实际效果。
原片链接:https://www.youtube.com/watch?v=B246K_G7mHU
