 夜雨聆风
夜雨聆风嗨大家好,我是品薇~
你有没有这种时候:
公 Z 号、知h看到好文章,收藏。有创意有想法的视频,收藏。下载一堆PDF文档,磁盘都要爆了。
我们老有一种错觉,就是"我收了=我学了"。
事实呢?这里的问题无非 2 个。
一个是收藏渠道太分散了。红薯、抖音、微信收藏、浏览器书签都各自有自己的收藏夹,用的时候到处找,最后还是找不到。
另一个是收藏的格式不统一。PDF 全是图片格式,搜不到内容,想引用一段都复制不出来。
今天这篇文章,就是解决这两个问题。
我用这3个插件搭了一个信息流收集器,把文章、视频、PDF 全部变成结构化的、可搜索的、能复用的笔记。
废话不多说,干货来了。
收文章:转发一下就够了
品薇每天都会看公Z号。之前看到不错的文章,我会随手转发到元宝,元宝能帮你提取文章核心观点,但是特别不方便做知识沉淀和日后检索。
再加上腾讯生态对文章的保护,内容很难自动化提取和转存到外部工具里。
找了一圈,我用下来觉得笔记助手这个 Obsidian 第三方插件非常便捷。
它的核心能力是:一键把微信里的消息转存到 Obsidian、OneNote、Notion 这些主流笔记软件。
不仅仅是公Z号文章,知h、视频号、小红薯、抖音、B 站、YouTube 等的视频,它都能一键转成文字,做成图文笔记。
操作也很简单。扫一下下面的二维码,直接获取7 天的新用户试用。特别牛的是,试用期间就能解锁全部功能,包括视频转图文这种核心能力。
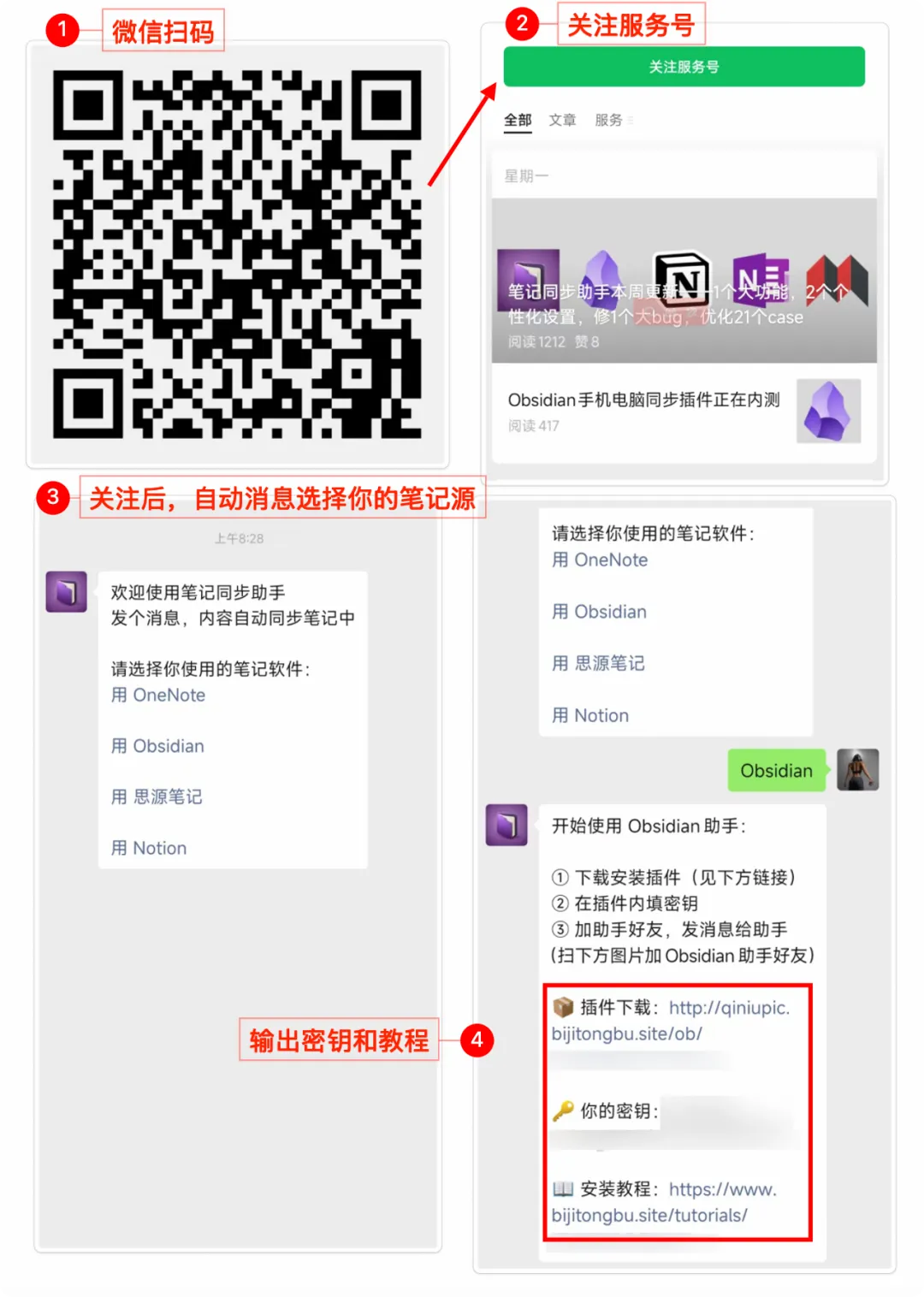
试用完想继续使用,直接冲个年卡,价格也很亲民。

公众号、微博、知乎、B 站等渠道的转存过程如下⬇️
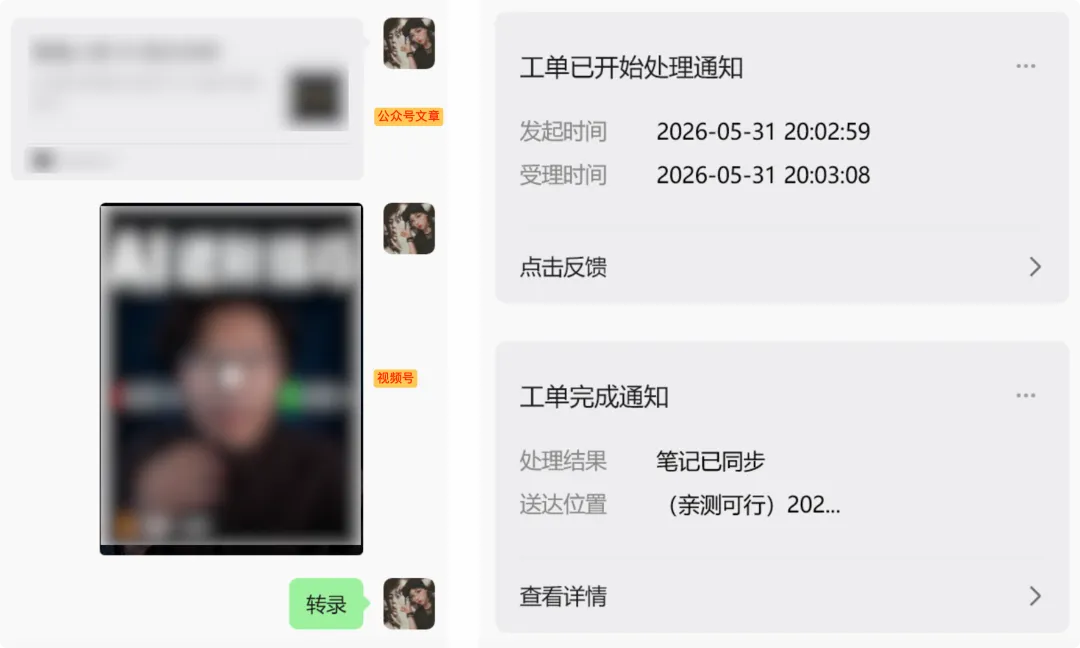
公众号采集文章的效果⬇️ 自动保留原文链接,方便日后回溯
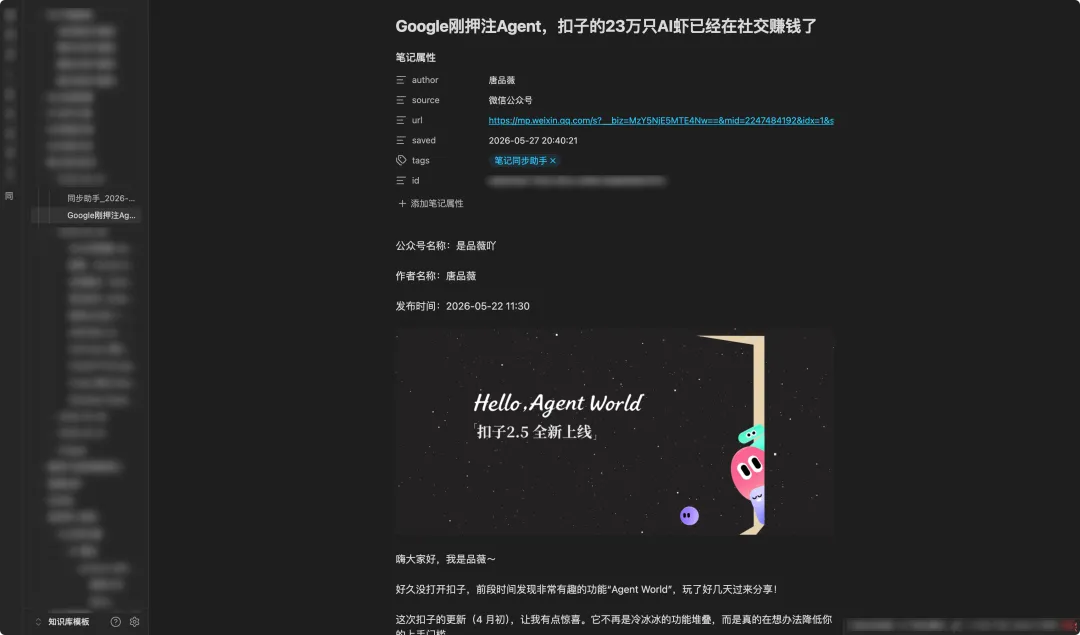
B 站采集视频的效果⬇️ 直接转成图文笔记
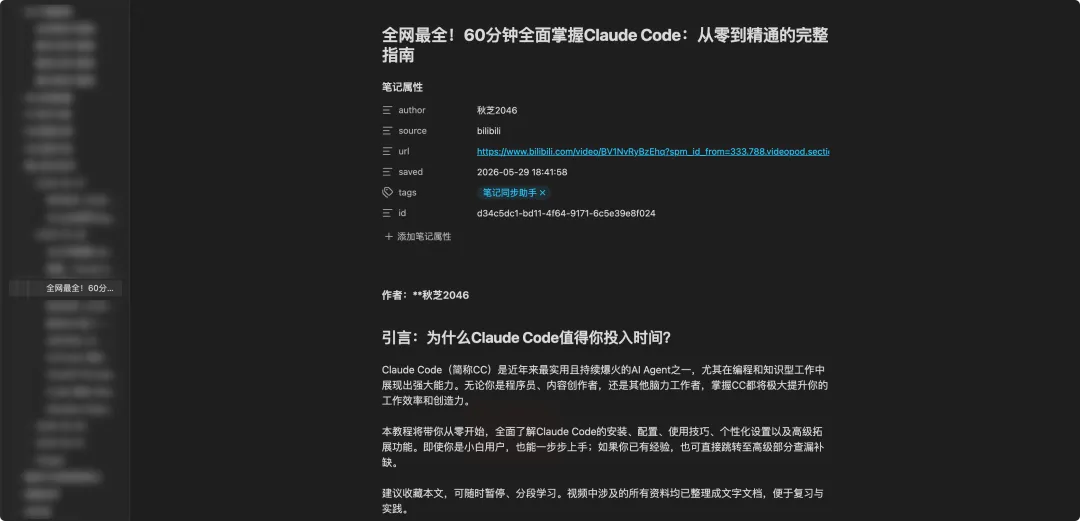
收视频
除了笔记同步助手,还有一个官方插件值得单独拎出来说。
Obsidian Web Clipper是 Obsidian 官方推出的浏览器剪藏扩展插件。它能帮你一键把网页内容(文章、视频、图片、高亮、笔记)保存到Obsidian 知识库。
Obsidian 官方插件,天然对 Obsidian 最友好,格式几乎零损耗。
安装很简单,直接在浏览器的扩展插件商店搜索 "Obsidian Web Clipper",装好就行。
品薇已经安装过了,所以显示的是"移除",你没装过的时候会显示"安装"按钮。
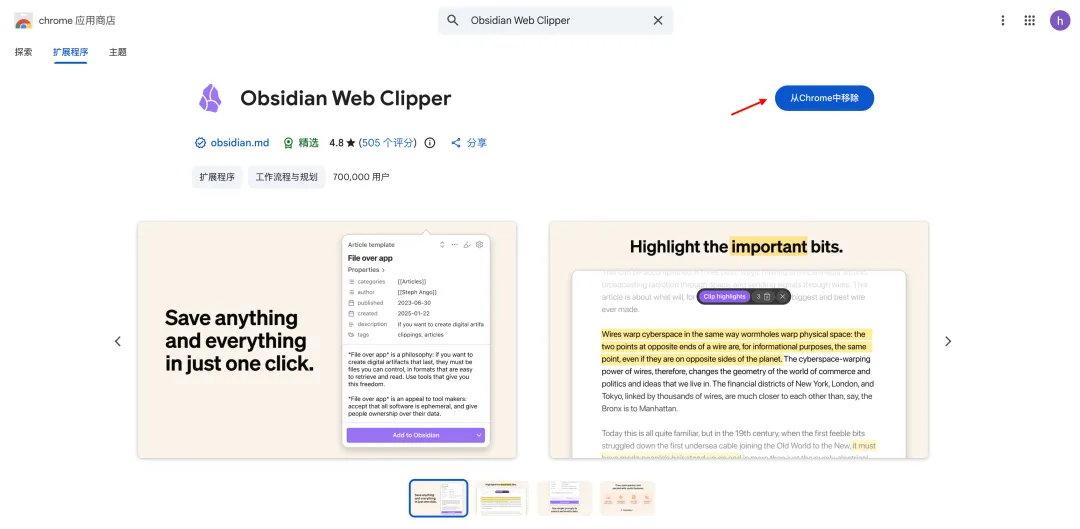
B 站采集视频的过程⬇️
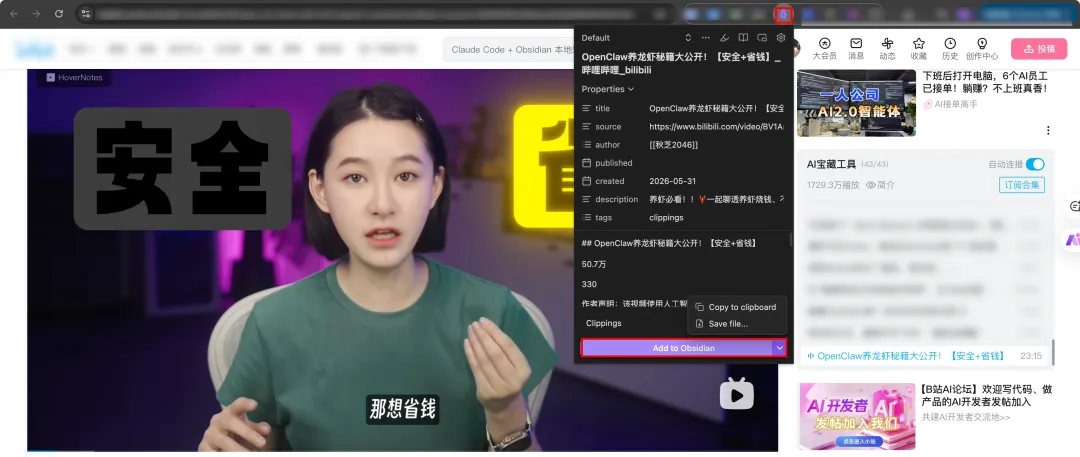
一键导入 Obsidian 后的效果⬇️

PDF 转 Markdown:终于不用跟扫描版较劲了
好了,文章和视频都搞定了,但还有一个硬骨头:PDF 文档。
品薇收了很多 PDF 版的研报和电子书,但几乎再也没打开过。这样大大浪费了一个权威的信息渠道。里面大量的准确知识和数据,本来都可以成为你未来输出时的参考和资料源。
但因为 PDF 的文字无法被 AI 快速读取,所以要做成方便知识提取的信息源,就必须转换成 Markdown 格式(Obsidian 的核心存储格式就是 Markdown)。转换后不仅能随意编辑、全局搜索,还能把 PDF 内容和其他笔记灵活关联,让知识真正流动起来。
基于这个需求,你需要一个能把 PDF / PPT / 图片 这些"展示格式",转换成 Obsidian 能真正使用的Markdown 格式。
MinerU可以解决这个问题,官网地址:https://mineru.net/
打开官网,看到定位"LLM 与 Agent 的智能文档解析引擎"。听起来很技术,但用起来很简单。

你可以选择下载到本地使用,也可以在线使用。直接在主页面上传文档转换即可。
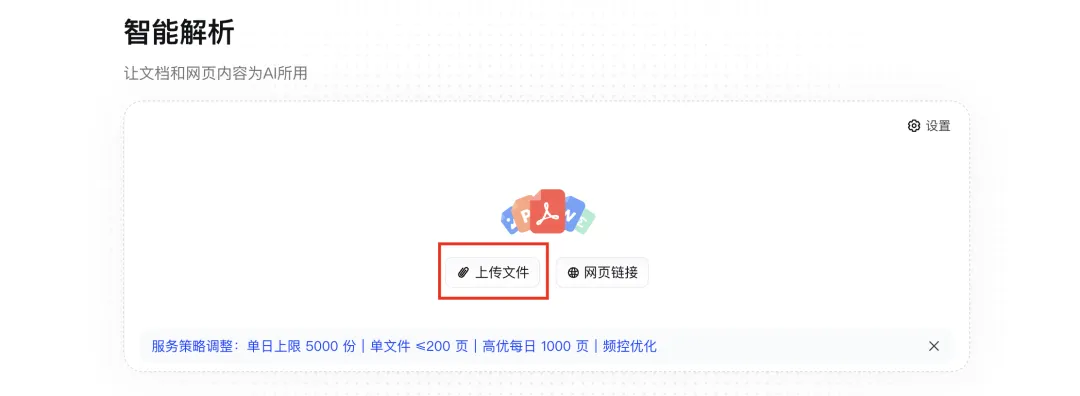
统一收口 Obsidian
前面我们用各类工具,把文章、视频、PDF、图片等五花八门的信息,统一转换成了 Markdown 格式。看到这里很多人会好奇:为什么非要费劲转格式、统一归集到 Obsidian?这也是我长期使用下来,最认可它的地方。
我陆续体验过 Notion、印象笔记等多款主流笔记工具,兜兜转转最终还是留在了 Obsidian。如今搭配上丰富的 AI 插件,Obsidian 的能力更是如虎添翼。
这里引用归藏和一些业界大佬的核心观点:
AI 时代的信息架构,必须把底层数据和对外展示形态完全拆分。
通俗来讲就是:Markdown 负责纯净存储内容,HTML 负责实现交互与页面展示。
Markdown 就像人的大脑。Obsidian 所有笔记都以原生 Markdown 保存,没有多余样式、冗余代码,内容结构干净规整,天生容易被 AI 识别、解读。
HTML 就像外在的展示界面。当需要对外分享内容时,再将文件渲染成精美网页即可。
Claude Code 的作者近期也公开表示,现在对外内容分享已全面转向 HTML;而 Obsidian 开发者始终认为,Markdown 是 AI 时代内容领域的通用共识,即业内所说的内容谢林点(由诺贝尔经济学奖得主托马斯・谢林提出,指无需约定就会默契选用的通用标准)。
结合两位行业前沿开发者的思路,背后的逻辑一目了然:
做知识沉淀,先要给内容做减法。
剥离花哨格式与无效信息,只留存核心内容,后续再根据需求做视觉包装、美化输出。我整套信息流收集体系,正是围绕这个理念搭建落地的。
相信不少朋友都有过囤积资料却无从利用的困扰,而这套「统一格式 + 集中沉淀」的方式,恰好能帮我们把零散信息变成可用的知识资产。
今天分享了如何获取并统一沉淀信息源,之后还会有知识库相关的干货分享,关注我,再看、点赞、转发是我创作的动力,感恩遇见🌸
我是品薇,专注记录一人公司与 AI 同行的成长日常。愿我们都能用好工具、沉淀知识,一起探索 AI 时代的更多可能。下期见~
|链接直达
PDF 转 Markdown:https://mineru.net/
一键转存视频:在浏览器的扩展插件商店搜索 "Obsidian Web Clipper"
文章、视频一键转存:微信扫下面 二维码 直达 笔记助手服务号

