 夜雨聆风
夜雨聆风👉 先问个扎心的问题:你还在为每个AI工具写定制化的API集成代码吗?
如果你点头了,那今天这篇文章,可能要颠覆你对AI工具集成未来的认知。
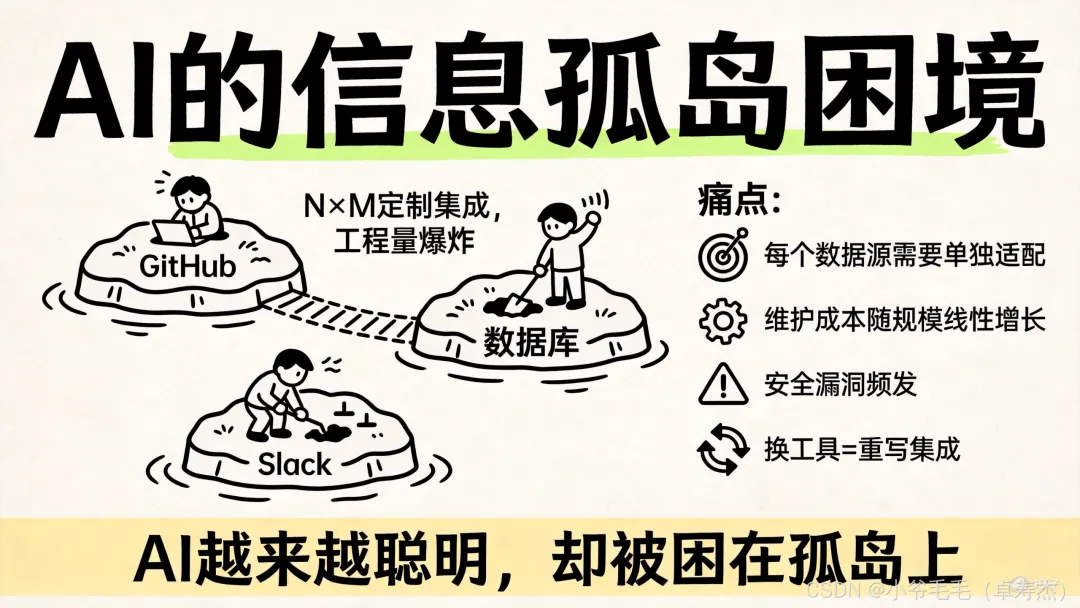
🔌 从"手拧螺丝"到"一线快充"
2016年,微软搞出了个叫**LSP(Language Server Protocol)**的东西——简单说,就是让IDE和各种编程语言服务器有了统一的对话语言。在此之前,每种语言(Python、Java、Go...)都得给每个IDE单独写插件,工程量堪称灾难。LSP一出来,IDE厂商和语言厂商各管一头,生态瞬间盘活。
八年后(2024年11月),Anthropic干了一件类似的事——发布了MCP(Model Context Protocol),只不过这次连接的不再是IDE和编程语言,而是AI模型和它需要的一切外部工具、数据、业务系统。
来源:Anthropic官方公告[1]
这么说可能还有点抽象。 想象一下:
• 没有MCP的Claude:被锁在"信息孤岛"里——想查GitHub?你得写代码。想操作数据库?还得写代码。想连Slack发消息?继续写代码。每个数据源都是一座"围城"。 • 有MCP的Claude:只要你配置好MCP服务器,直接说"帮我看看最近GitHub上那个bug修好了没,顺带给Slack群里发个通知",它就能自己搞定。
这差距,大概就是"手拧螺丝"和"电动螺丝刀"的区别吧。
🏗️ MCP到底是什么?一张图讲清楚
MCP的架构借鉴了LSP的设计哲学,但针对AI场景做了深度定制。核心组件就三个:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
┌─────────────────────────────────────────────────────────┐
│ Host(主机) │
│ Claude Desktop / VS Code / Claude Code │
│ │ │
│ MCP Client(客户端) │
│ "AI的瑞士军刀" │
└────────────────────────────┬────────────────────────────┘
│ 统一协议(MCP)
┌───────────────────┼───────────────────┐
▼ ▼ ▼
┌──────────────┐ ┌──────────────┐ ┌──────────────┐
│ MCP Server │ │ MCP Server │ │ MCP Server │
│ GitHub │ │ Slack │ │ PostgreSQL │
│ "仓库管理" │ │ "消息通知" │ │ "数据查询" │
└──────────────┘ └──────────────┘ └──────────────┘
各组件职责解析:
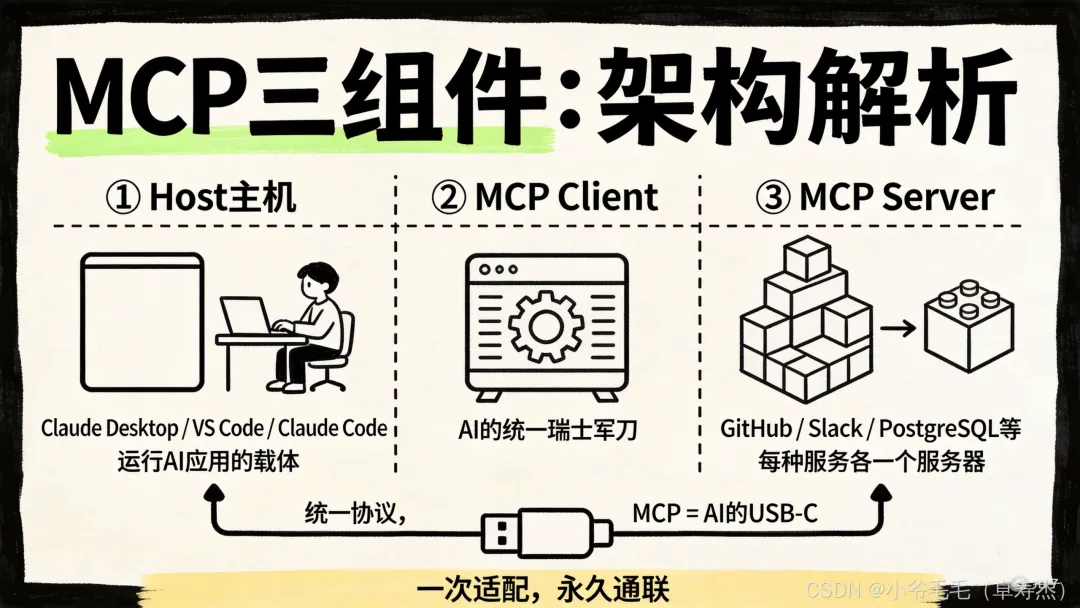
敲黑板: MCP的核心价值在于——AI工具开发者不再需要为每个数据源写定制代码,只要接入一个"通用接口",就能触达所有已接入MCP的服务。
📊 一周年成绩单:MCP跑得有多快?
2025年12月,Anthropic把MCP捐赠给了Linux Foundation旗下的Agentic AI Foundation(AAIF),联合创始方包括OpenAI、Google、Microsoft、AWS、Cloudflare、Bloomberg——这阵容,基本算是AI圈"全明星"了。
来源:Anthropic官方公告[2]
一年的数据(截至2026年初):
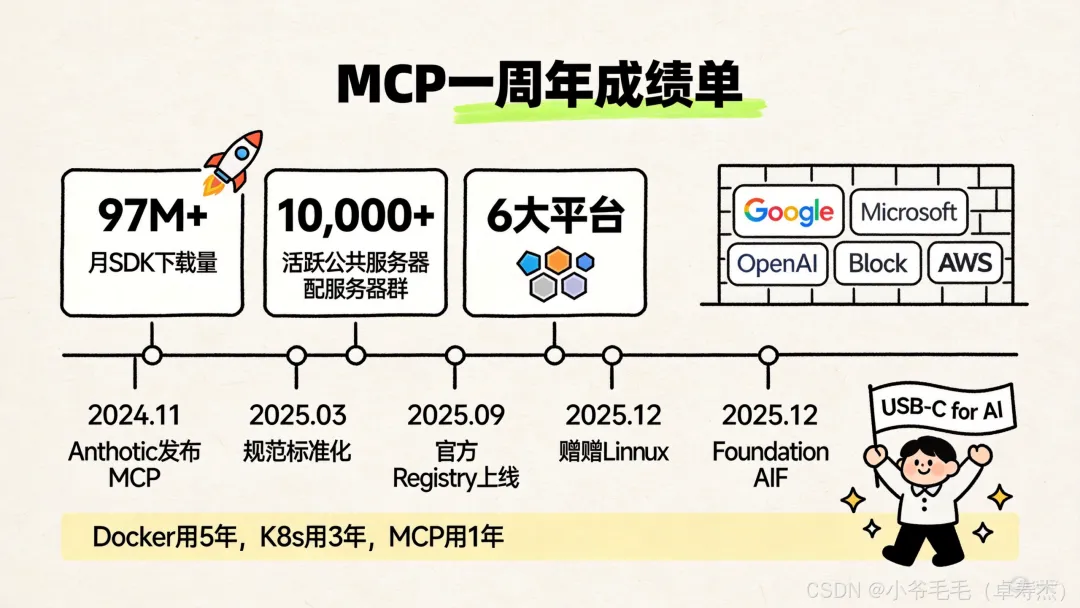
来源:MCP官方博客[3]
有人调侃说MCP就是"AI圈的USB-C"——一个接口搞定所有充电需求。虽然有点夸张,但确实抓住了本质。
🛠️ 你的Claude能用MCP做什么?
场景一:开发者日常(Claude Code)
Claude Code同时扮演MCP客户端和MCP服务器两个角色。作为客户端,它可以连接任意数量的MCP服务器;作为服务器,它能暴露自己的能力给其他支持MCP的工具。
连接方式有两种:
1 2 3 4 5 6 7 8
# 方式1:项目级配置(.mcp.json)
claude --mcp-config .mcp.json
# 方式2:全局配置
claude --mcp-config global
# 方式3:运行时动态连接
claude --mcp-server puppeteer://localhost:3000
配置示例(.mcp.json):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
{
"servers": {
"github": {
"command": "npx",
"args": ["-y", "@modelcontextprotocol/server-github"]
},
"filesystem": {
"command": "npx",
"args": ["-y", "@modelcontextprotocol/server-filesystem", "/path/to/workspace"]
},
"sentry": {
"command": "npx",
"args": ["-y", "@sentry/mcp-server"]
}
}
}
注释解读:
• command:启动服务器的命令(这里用npx拉取npm包)• args:传给命令的参数(包名 + 可选配置)• 每个服务器独立运行,Claude会按需调用
场景二:企业协作(Slack + GitHub + Notion)
以前:你要写一个"检查CI流水线 → 通知团队"的自动化脚本,得这样:
1 2 3 4 5 6 7
# 古老的方式:手动拼API
curl -X POST https://slack.com/api/chat.postMessage \
-H "Authorization: Bearer $SLACK_TOKEN" \
-H "Content-Type: application/json" \
-d '{"channel":"#dev","text":"Deploy complete"}'
# 错误处理?限速重试?Token刷新?都是你的活儿。
现在:直接说人话
1
Post "CI pipeline passed" to the #dev Slack channel and create a Notion task to update the release notes.
MCP服务器自动处理认证、限速、错误恢复,Claude只负责"想清楚要做什么"。
场景三:构建自己的MCP服务器
用Python SDK,几行代码就能暴露一个自定义工具:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57
# custom_database_server.py
from fastmcp import FastMCP
from typing import List, Dict, Any
import asyncpg
# 创建MCP服务器实例
mcp = FastMCP("Custom Database Server")
@mcp.tool()
async def query_data(
sql: str,
params: List[Any] = None,
limit: int = 100
) -> Dict[str, Any]:
"""
执行SQL查询
Args:
sql: SQL查询语句(SELECT语句)
params: 查询参数(元组形式)
limit: 返回结果数量上限(防止查询过大)
Returns:
包含查询结果的字典,格式为:
{
"success": true/false,
"data": [行数据列表],
"row_count": 符合条件的结果数
}
"""
try:
# 建立连接池(复用连接,提高性能)
pool = await asyncpg.create_pool(
"postgresql://user:pass@localhost/dbname",
min_size=1,
max_size=10
)
async with pool.acquire() as conn:
# 执行查询(带参数防注入)
if params:
rows = await conn.fetch(sql, *params)
else:
rows = await conn.fetch(sql)
# 转换为列表格式并应用限制
return {
"success": True,
"data": [dict(row) for row in rows[:limit]],
"row_count": len(rows)
}
except Exception as e:
return {
"success": False,
"error": str(e),
"data": []
}
代码注释补充说明:
• FastMCP:MCP官方提供的高层封装,省去协议处理的繁琐细节• @mcp.tool():装饰器,将函数注册为AI可调用的工具• asyncpg:Python生态里性能最高的PostgreSQL异步驱动• 连接池(pool):避免每次查询都重新建连接,降低数据库压力
🚀 2026年路线图:MCP的下一个里程碑
MCP官方博客在2026年3月发布了路线图,核心聚焦四个方向:
来源:MCP官方博客[3]
1️⃣ 传输层演进(Transport Evolution)
问题: 早期MCP大量依赖本地STDIO连接,但企业场景需要远程部署。Streamable HTTP解决了"能不能远程"的问题,但有状态会话成了新瓶颈——负载均衡搞不定,重启会话就丢。
2026解法:
• 推进"无状态/准无状态"会话模型 • 引入Server Cards(在 .well-known端点暴露元数据,支持不建连就能发现服务)• 类比:就像USB-C从"插线充电"进化到"磁吸快充"
2️⃣ Agent通信强化(Agent Communication)
问题: MCP的任务(Tasks)原语支持"调用-稍后取结果"模式,但生产环境里失败重试策略不清晰、结果保留多久没标准。
2026解法:
• 标准化重试语义(含指数退避指南) • 明确过期策略(结果保留多久、怎么通知客户端) • 类比:从"快递到付"升级到"带签收确认的快递"
3️⃣ 治理成熟(Governance Maturation)
背景: MCP进入Linux Foundation后,贡献者从几十人暴增到几百人,每个SEP(规范增强提案)都要核心维护者过一遍,成了新的瓶颈。
2026解法:
• 引入Contributor Ladder(贡献者阶梯) • SEP流程迁移到PR驱动(比GitHub Issues更利于代码审查) • 扩大维护团队(新增2名核心维护者)
4️⃣ 企业就绪(Enterprise Readiness)
问题: 大企业要审计日志、SSO集成、网关模式——这些"安全感"是采购决策的前置条件。
2026解法:
• 审计追踪扩展 • SSO集成指南 • 网关模式参考架构 • 重要: 这些都以轻量级扩展形式提供,不碰核心协议
💡 为什么说MCP是AI应用的基础设施革命?
聊技术容易枯燥,让我们回到本质问题:MCP到底解决了什么根本矛盾?
AI应用的矛盾是:
• 模型越来越聪明(上下文理解、推理能力) • 但模型越来越"孤立"(没法实时获取数据、没法执行操作) • 传统解法:每个数据源配一个"适配器"——工程量爆炸,且无法规模化
MCP的思路是:在模型和数据源之间,架一层"标准化翻译层"。
就像USB-C统一了充电线缆的物理接口,MCP统一的是AI与外部世界交互的"逻辑接口"。
🔮 展望:MCP的天花板在哪?
MCP官方说"目标是在2026年底成为真正的AI USB-C"。说实话,这个目标并不夸张。
看几个信号:
1. 生态锁定已经开始。 Cursor、VS Code、Claude都支持MCP之后,开发者换工具的迁移成本会越来越高——谁先深度绑定MCP,谁就掌握了生态入口。 2. 企业采购开始纳入考量。 随着审计、SSO等企业就绪功能完善,MCP会成为企业AI采购的"合规门槛"。 3. 2026年的主战场是传输层和Agent间通信。 这两个方向解决的是生产级部署的核心痛点,一旦突破,企业采用率会再上一个台阶。
但挑战同样存在:
• 碎片化风险: 服务器数量爆炸但质量参差(据Smithery数据,2500+服务器中只有8个安装量超5万) • 安全边界: 协议越开放,攻击面越大——工具注释(Tool Annotations)虽然引入了风险词汇,但还远远不够 • 互操作性天花板: 如果各厂商MCP实现出现分化,标准统一的优势会被蚕食
🙋 互动时间
好,理论聊完了,来点实在的——
你现在用Claude的时候,最希望它能连接什么工具? GitHub?飞书?你们的业务数据库?还是什么奇奇怪怪的冷门系统?
评论区聊聊,说不定下一个爆款MCP服务器就是你提的需求 👇

引用链接
[1] 来源:Anthropic官方公告: https://www.anthropic.com/news/model-context-protocol[2] 来源:Anthropic官方公告: https://www.anthropic.com/news/donating-the-model-context-protocol-and-establishing-of-the-agentic-ai-foundation[3] 来源:MCP官方博客: https://blog.modelcontextprotocol.io/tags/mcp/[4] MCP 2026路线图: https://a2a-mcp.org/blog/mcp-2026-roadmap
