 夜雨聆风
夜雨聆风我做过一次实验:把量化研究拆成 5 轮对话 + 一份可自动执行的 plan.md,人只定标的、因子逻辑和验收标准,其余交给 AI 写代码、跑回测、做检查。
自动执行那一段,机器跑了大约 22 分钟(6 个阶段、6 次 git commit,中间有 7 次它自己发现并改掉的实现问题——前视偏差、止损逻辑之类,另一篇文章里按条写过)。这 22 分钟不包括你前期想清楚策略、写 CLAUDE.md / plan 的时间;我这边对话定方向大概还要 10–15 分钟。
若按我以前的节奏,从零拉数据、写因子、回测、风控、调参到能看的报告,一个人通常要 1–2 周(复杂一点才会拖到 3–4 周);这次我没有手写实现代码,但仓库里照样有成百上千行 Python,只是作者换成了 AI。回测做过一次专门挑前视偏差的内审,纸面结果、未实盘——审计前后差异详见《Sharpe 1.74 是假的:22 分钟 AI 量化》。
这套流程能重复,靠的不是运气,而是把 AI 摆在对的位置:它不是替你思考策略的"军师",是替你写代码的"分析师"。你做决策,它做执行。
整套 SOP 的骨架长这样:

下面拆解这套 SOP,从核心比喻、三个文件的角色分工,到 5 轮对话每一轮该说什么,再到两个最容易踩的坑。
一、你是研究总监,AI 是分析师
把 AI 当军师让它帮你"找一个 Sharpe 大于 2 的策略",结果只会是一个挖了过拟合数据的垃圾。Alpha 来自人对市场的理解,不是来自 AI 在历史数据里搜索。
更合适的比喻是:你是研究总监,AI 是分析师。
总监的活:
分析师的活:

总监花 10-15 分钟对话定方向,分析师花 22 分钟全自动执行,7 次自修正,0 次人工干预。这是一次完整的分工。
为什么要这么分?因为这两类工作的核心能力差太远了。
研究总监要做的,是判断"什么是好策略"——动量突破在科技股上历史有效、4 层 AND 过滤能压住假信号、追踪止损比固定止损更适合趋势策略。这套判断来自市场认知和经验,AI 没有,而且短期内也学不会。
分析师要做的,是把判断翻译成代码——拉数据、算指标、跑回测、扣成本、做参数扫描。这是确定性工作,规则清晰、有标准答案、能自动验证。AI 在这里是降维打击。
颠倒一下会怎么样?让 AI 当总监,你当分析师——AI 拍脑袋说"我建议你做截面因子策略,配 RSI 和 MACD",你照着写代码。半个月写完跑出来,赚不赚钱看运气,因为没人为这个策略的内在逻辑负责。
我第一次让 AI 跑量化的时候,它把止损价用了"当天最低价"——而当天最低点是收盘后才能知道的,这就是经典的前视偏差。光这一个 bug 就能让 Sharpe 虚高 70%。5 轮对话不是噱头,是被这种坑教训出来的。
你不需要会写 Python,只需要知道:好策略长什么样、如何系统地找到它。
二、三个文件 = 三个角色
5 轮对话沉淀下来的不是聊天记录,是三份持久化的项目文件。它们是 AI 的外部记忆系统,下次唤醒能精确恢复上下文。
把这三个文件想成一个工地的三种文档:
• CLAUDE.md 是项目宪法——告诉所有人这个工地不许偷工减料 • plan.md 是施工图纸——告诉施工队第几天该砌墙、第几天该浇梁 • progress.md 是工地日报——记录今天砌到哪、出了什么状况、明天接着干
这是全文最重要的一节,因为只要这三个文件分得清,5 轮对话就只是水到渠成的填空题。
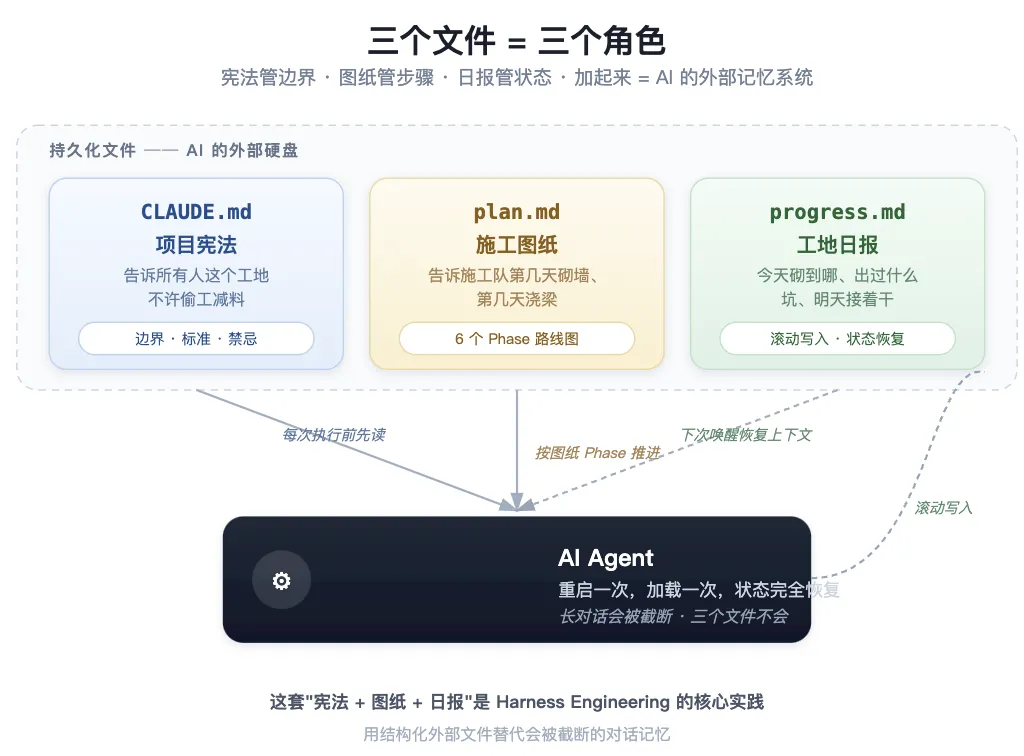
为什么不直接靠对话历史?因为长对话会被截断,记忆会漂移。三个文件就是 AI 的外部硬盘——重启一次,加载一次,状态完全恢复。
CLAUDE.md:项目宪法
宪法定边界,不定步骤。它告诉 AI:"你能做什么、不能做什么、做到什么程度算成功"。
# CLAUDE.md - Project Constitution## Project Overview- Universe: 15 US tech stocks- Strategy: CTA momentum breakout## Tech Stack- Python 3.12 / uv / pytest## Acceptance Criteria- Sharpe > 0.8 after cost- MaxDD < 30%## Forbidden- 严禁使用未来数据(lookahead bias)- 每个 Phase 必须 git commit宪法的关键组成:项目边界(标的/数据/频率)、技术约束(Python/uv/pytest)、验收标准(Sharpe/DD/交易数)、协作规则(每 Phase commit)、禁忌事项(禁用未来数据)。
没有 CLAUDE.md,AI 会自由发挥——参数漂移、依赖混乱、跑出来的结果下次复现不了。有 CLAUDE.md,AI 每次执行前先读规范,行为一致。
plan.md:施工图纸
宪法说"不能偷工减料",图纸说"先打地基、再砌墙、最后封顶"。plan.md 把研究拆成 6 个 Phase,每个 Phase 只做一件事,前一步是后一步的输入:
P0 数据获取 → P1 因子实现 → P2 向量化粗筛→ P3 bar-by-bar 精细 → P4 仓位优化 → P5 鲁棒性检验施工图纸的设计原则:
1. 渐进式:每 Phase 单一职责,不混搭 2. 可回溯:每 Phase 完 commit,出问题能 reset 重跑 3. 自验证:AI 自动比对验收标准,不达标自动修正 4. 可中断:任何 Phase 都能暂停,下次断点续传
图纸越详细,返工越少。
progress.md:工地日报
施工队边干边记。progress.md 不是 AI 写给你看的,是 AI 写给"下一次的自己"看的。
Phase 3 完成v5: Sharpe 1.23, MaxDD 44.89%(仓位等权,未优化)v6: Sharpe 1.04, MaxDD 27.08%(C3 波动率加权)踩坑:止损价用了当天最低价,已修复为预设止损线当前最优参数:MA50, ATR×3, T+15它记录当前 Phase、踩过的坑、最优参数、中间结果。等你回头看回测演变史,progress.md 就是完整的审计日志。
这套"宪法 + 图纸 + 日报"的组合,是 Harness Engineering 的核心实践——用结构化外部文件替代会被截断的对话记忆。
三、5 轮对话拆解
知道了三个文件的角色,5 轮对话就是按顺序把它们填出来。
第 1 轮:定项目宪法(输出 CLAUDE.md)
你给一段约束,AI 写出 CLAUDE.md。
你的输入大概长这样:
项目: 一个实验性的量化项目标的: AMD,AMZN,AVGO,GOOGL,IBM,INTC, LSCC,MSFT,NVDA,NXPI,QCOM,TSLA,TSM,BIDU,CSCO策略类型: CTA momentum breakout数据源: futu-api daily OHLCV因子逻辑: 4-layer AND entry验收: Sharpe > 0.8, MaxDD < 30%工具链: Python 3.12 + uv + pytestAI 接过这些约束,扩写成完整的 CLAUDE.md,包括项目边界、验收标准、禁忌事项、协作规则。这一轮的关键是把"什么算成功"写死,后面 AI 自己评判达没达标,就靠这条标尺。
经验:验收门槛一定要写具体数字,不要写"表现要好"。我吃过一次亏——只写了"Sharpe 高一点",AI 默认 Sharpe > 1.5 才算达标,跑出来不达标就反复加规则、套滤镜,最后做出一个明显过拟合的版本。改成 "Sharpe > 0.8" 之后,第一轮就能跑出干净的策略,其余时间都用在审计和优化上。
第 2 轮:固化因子池(输出 factors.md)
你不需要会写 Python,只要把因子讲清楚——大白话、数学公式、伪代码都行:
因子 1:收盘价连续 5 日站上 MA50,确认中期趋势
因子 2:当日 High 突破过去 63 日最高价,3 个月新高
因子 3:成交量大于 20 日均量的 1.2 倍,确认资金参与
因子 4:当日涨幅大于 ATR14 × SMA3,波动突破
描述越清晰,AI 产出质量越高。AI 接到这些描述会做三件事:判断歧义(如果有,反过来追问你)、补充工程细节(warmup、NaN 处理)、生成单元测试。
输出是一份 factors.md 注册表:
### Factor_01_MA50_Standdesc: 收盘价连续 5 日站上 MA50impl: factors/ma50_stand.pytest: ✓ unit_test passed### Factor_02_3M_Highdesc: 当日 High 突破 63 日最高impl: factors/high_3m.pytest: ✓ unit_test passed这一轮的核心理念:你提供金融逻辑,AI 负责工程实现。专业壁垒在你对市场的理解,不在你会不会写 Python。
实战提醒:因子描述里的"模糊表达"要主动消除。比如"放量"——多少倍算放?"突破"——突破谁?"持续向上"——多少天算持续?这些含糊的词在你的脑子里有默认值,但在 AI 那里没有。第二轮的输入越精确,第二轮就越短;输入糊弄过去,AI 写出来的因子和你想的就是两回事,等到 Phase 5 才发现就晚了。
第 3 轮:对齐计划(7 个决策点)
这是最关键的一轮。AI 列出它理解的执行计划,你逐项 approve 或 modify,形成"执行合同"。
| modify:追加成本压力测试 |
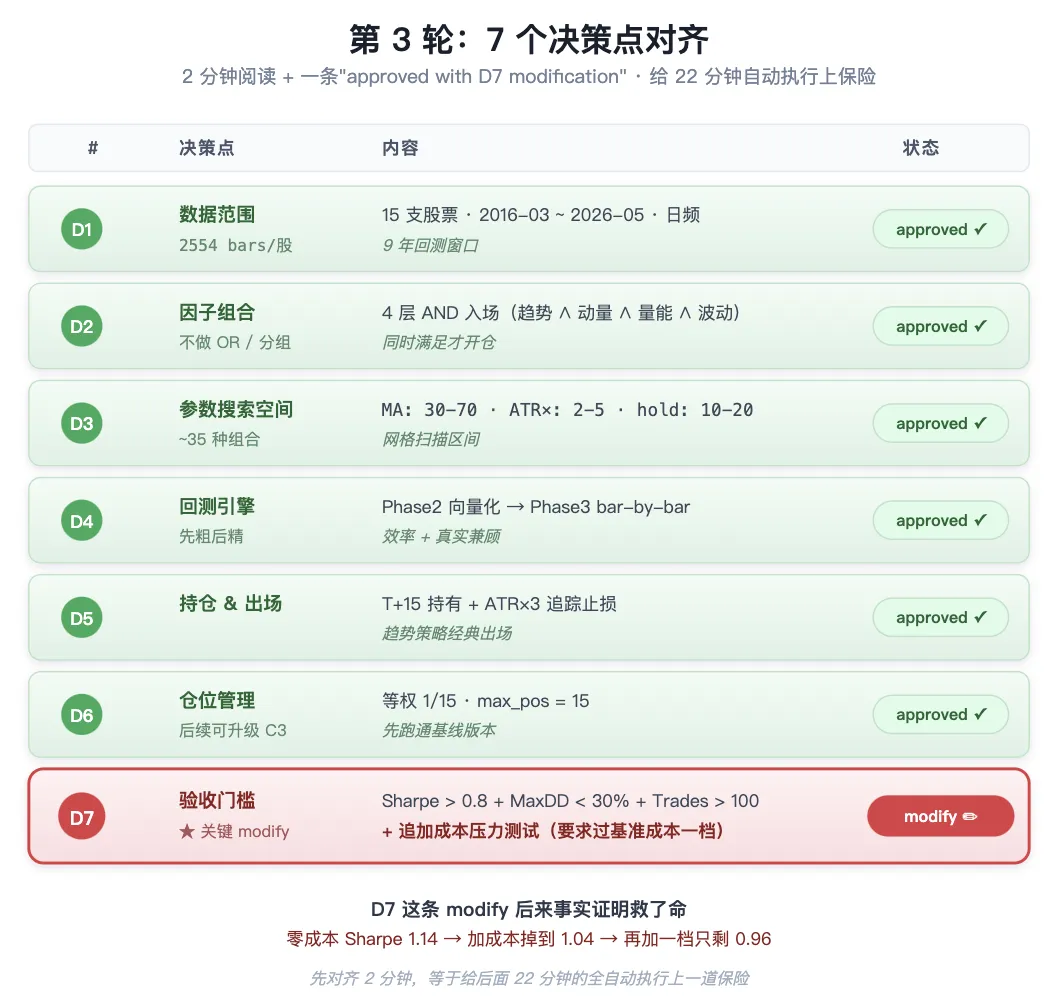
7 项确认 ≈ 2 分钟阅读 + 一条"approved with D7 modification"消息。
为什么必须要这一轮?因为 AI 跑偏的代价是返工 22 分钟。先对齐 2 分钟,等于给后面的全自动执行上一道保险。
我自己最容易在这一轮发现 AI 理解偏差——比如它把"3 个月新高"理解成了"过去 90 自然日",我会改成"过去 63 个交易日"。或者它默认了向量化回测就够了,我会要求加上 bar-by-bar 精细验证。这种细节对齐,越早做越省事。
D7 那个 modify 标记是个真实例子。AI 第一版给的验收门槛只有"Sharpe + MaxDD + Trades"三条,我加了一条"成本压力测试必须过基准成本一档"——后来事实证明这一条救了命,因为初版策略在零成本下 Sharpe 1.14,加完佣金滑点掉到 1.04,再往上一档就只有 0.96 了。如果验收门槛里没有这条,AI 跑完会自信地报"达标",但实际上策略对成本相当敏感。
第 4 轮:固化 plan.md(6 阶段路线图)
7 个决策点 approve 完,AI 把它们编织成一份 plan.md——6 个 Phase 的执行路线图:
总计 22 分钟,0 人工干预,7 次自修正。
plan.md 审批通过后,AI 不再问你"我下一步该做什么"——它有图纸了。
这一轮要看 AI 写出来的 plan.md,重点检查三件事:每个 Phase 的输出物是否具体可验收(比如"产出净值曲线 PNG"而不是"完成精细回测")、Phase 之间的依赖是否正确(P3 必须在 P2 之后)、回退方案是否清晰(某个 Phase 失败了怎么办)。
第 5 轮:发执行 Prompt(你的最后一条消息)
最后一条消息约 500 字,规则细到 AI 想跑偏都没空间:
请按 plan.md 从 Phase 0 开始执行,规则:1. 每个 Phase 完成后 git commit(commit message 含 Phase 编号)2. 每个因子必须有 pytest 单元测试3. 回测扣减佣金 5bp + 滑点 3bp4. 不得使用未来数据(strict no-lookahead)5. Phase 3 必须实现追踪止损:highest - 3×ATR(14)6. Phase 5 跑 5 项鲁棒性测试: - 参数网格(MA30-70 × ATR2-5) - 期间拆分(3 段) - 成本压力(0/基准/中等/高) - 滑点敏感度(0-10bp) - 持仓天数扰动(T+10/15/20)最终验收:Sharpe(基准成本)> 0.8 且 MaxDD < 30%发送出去。AI 立即开始 Phase 0,22 分钟自动执行,逐 Phase commit,遇错自动修正。你要做的,就是等 22 分钟,回来看完整的 Python 项目和 HTML 报告。
Prompt 写得越具体,AI 返工越少——这就是为什么前 4 轮要把约束写清楚。
四、避坑:两个最常见的误解
跑完几次以后我发现,新手翻车的姿势惊人地一致,永远是这两个。
误解 1:"AI 帮我找 alpha"
错误姿势:「帮我找一个 Sharpe 大于 2 的策略」。
AI 收到这个 Prompt 会怎么干?它不会拒绝,它会过度拟合历史数据,挖出一个 Sharpe 3.0 的"纸面策略"。你拿去实盘跑,第一周就爆亏。
正确姿势:你定逻辑(动量突破 + 4 层过滤),AI 负责实现 + 验证 + 优化参数。Alpha 来自你对市场的认知,不是 AI 在数据里的搜索。
把 AI 当军师,它会把你带沟里。把 AI 当分析师,它能帮你节省 99% 的实现成本。
这是一个特别反直觉的点:AI 越强,越要克制对它的"信任范围"。你越愿意让它替你想策略,它就越乐意拿历史数据反向工程一个看上去漂亮的答案给你。这不是 AI 在骗你,是它的优化目标和你的真实目标错位了——它在追求"在你给的数据上表现好",你在追求"在未来的市场里能赚钱"。
误解 2:"回测好 = 能赚钱"
我第一版跑出来的策略,Sharpe 1.74、年化 54.66%,看上去封神。审计完之后剩多少?Sharpe 1.04,年化 31.82%——直接砍掉 40%。
为什么差这么多?因为 v1 里藏着两个看不见的 bug:
1. 未来数据泄漏:止损用了当天最低价,等同于先看了答案再答题 2. 执行差异:向量化回测的"理想成交"和 bar-by-bar 的"真实成交"对不上 3. 成本缺失:佣金和滑点没扣干净,高换手策略虚高严重
第一版生成完立刻审计,不要等到觉得"差不多了"再审。审计后掉到 1.04 才是真实表现,没有审计的回测等于自欺欺人。
更重要的是养成一个反射:看到漂亮的回测结果,第一反应不是"我赚了",是"哪里出了 bug"。Sharpe 1.74 在日频策略里已经是优秀级别的数字,能轻松跑出这种结果,大概率是回测引擎里偷偷开了"上帝视角"。养成这个反射,比多写 100 行代码都管用。
黄金法则
你负责"策略逻辑是否合理",AI 负责"代码实现是否正确"。
两者不能互相替代——即使 AI 写的代码完美,策略逻辑错了照样亏钱。
每跑完一轮,你的审查清单就 6 条:
1. 策略逻辑是否符合我的市场认知? 2. 入场/出场规则是否清晰无歧义? 3. 参数范围是否符合常识? 4. 有无使用未来数据的风险? 5. 成本假设是否接近真实? 6. 样本外表现是否稳定?
全过 → 讨论实盘。有疑问 → 追加对话修正。逻辑错 → 回第 3 轮重来。
写在最后
5 轮对话 + 22 分钟,跑出 Sharpe 1.04 的策略,听上去很酷。但这套 SOP 真正的价值不是"快",是"分工"。
你把时间花在该花的地方——想清楚要做什么、好策略长什么样、不能踩什么坑——而不是在 pandas 文档里翻 rolling().apply() 的用法。AI 把它擅长的事做好——读规范、按图纸、自我修正、commit 历史——而不是替你想策略逻辑。
这套 SOP 的可复用性也不错。换标的:把 CLAUDE.md 里的 universe 列表改一下;换策略类型:把因子描述改一下;换市场:换数据源 SDK。骨架不动,5 轮对话的节奏不变。第一次跑要 30 分钟磨合,第二次跑可能 15 分钟就能搞定。
更深一层的价值是它给"AI Agent 协作"提供了一个具体可见的范式:宪法管边界、图纸管步骤、日报管状态、对话管对齐。这套范式不止用在量化,写代码、写文章、做调研、做 RPA,都能套——你只要想清楚"什么是宪法、什么是图纸、什么是日报",剩下的就是把对话拆成 5 轮往里填。
下一篇会讲这 22 分钟里到底发生了什么:7 次自修正每次修了什么、回测审计怎么砍掉 40% 的 Sharpe、5 项鲁棒性检验跑出来什么、最后是怎么决定能不能上实盘的。预告一句:审计完的 Sharpe 才是真表现,没审计前的 1.74 是幻觉。
