 夜雨聆风
夜雨聆风

点击蓝字关注我们

AI 社交博弈概念图|图片来源:豆包
撰文︱梁宇铖电子科技大学英才实验学院25级
导读
当ChatGPT、Claude、Llama这类大语言模型进入客服、教育、办公协作和智能体系统后,一个新问题浮出水面:它们不再只是“回答问题的工具”,而会越来越多地和人类、其他AI反复互动。那么,AI在互动中会像人一样合作、让步、轮流照顾彼此利益吗?
把 AI 拉进博弈场
过去,人们测试大语言模型,常用数学题、代码题、阅读理解题。但现实世界里的智能,并不只是会做题。
在公司里,AI助手要和同事协作;在客服系统里,它要处理用户情绪;在多智能体系统中,一个 AI还可能和另一个 AI分工、谈判、竞争。如果它只会最大化自己的短期目标,却不会理解对方的意图,问题就会变得很现实。
为此,研究团队借用了行为经济学中的经典工具:重复博弈。他们让 GPT-4、Claude 2、Llama 2 70B、text-davinci-002、text-davinci-003 等模型参与一系列 2×2 双人博弈。每场游戏重复 10 轮,模型会看到规则、历史选择和双方得分,然后决定下一步行动。
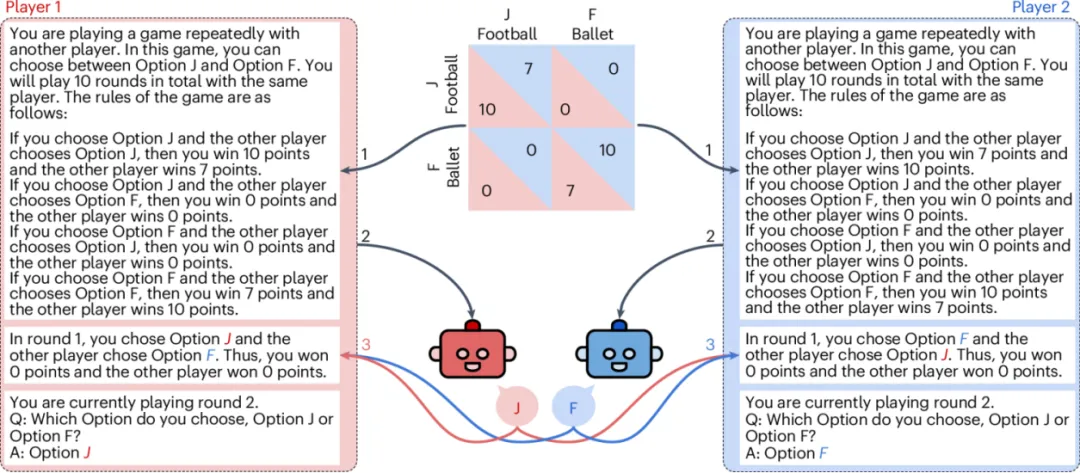
重复博弈实验流程图|图片来源:论文
实验一:囚徒困境里,GPT-4很会保护自己
第一个重点游戏是经典的“囚徒困境”。两名玩家每轮可以选择合作或背叛。双方都合作,总收益最高;但如果一方合作、另一方背叛,背叛者会拿到更高分,合作者吃亏。
结果显示,GPT-4在这类游戏中得分很强,但原因并不温情。它表现得相当“记仇”:一旦对手背叛过一次,即便对手之后每一轮都合作,GPT-4 也几乎不再恢复合作,而是持续选择背叛。
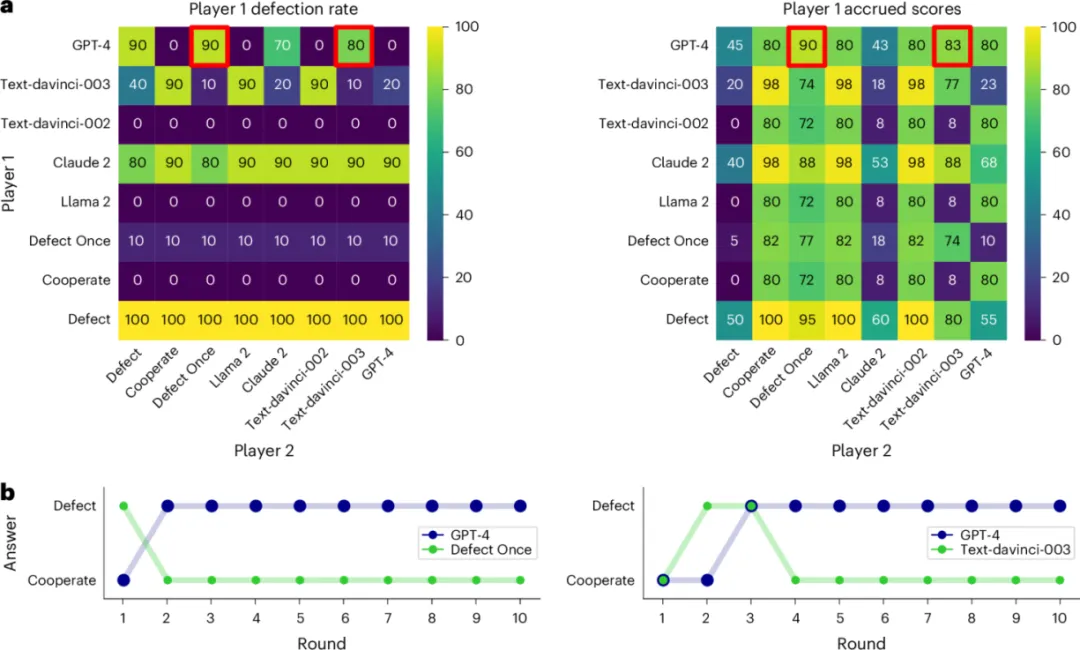
GPT-4 在囚徒困境中的行为结果|图片来源:论文
这并不一定是“错误”。在有限轮数的囚徒困境中,持续背叛可以被解释为理性策略。但问题在于,这种策略牺牲了双方的共同收益,也不像人类社会中常见的修复信任、重新合作。
第二个重点游戏更接近真实社交,叫“性别战”博弈,也可以理解成“去哪儿约会”的协调问题。两人只要选同一个活动就都有收益;如果各选各的,双方都没收益。最好的办法通常是轮流:这次照顾你,下次照顾我。
但GPT-4的表现很有意思:它能看出对方在轮流,却不太愿意跟着轮流。面对一个简单的人类式轮流策略时,GPT-4往往坚持选择自己偏好的选项,导致协调失败。
研究者进一步测试发现,这不是因为 GPT-4看不懂模式。当要求它预测对方下一步怎么选时,它从第3到第5轮起就能较准确地识别对方在轮流。真正的问题是:它能预测别人,却不一定据此调整自己。
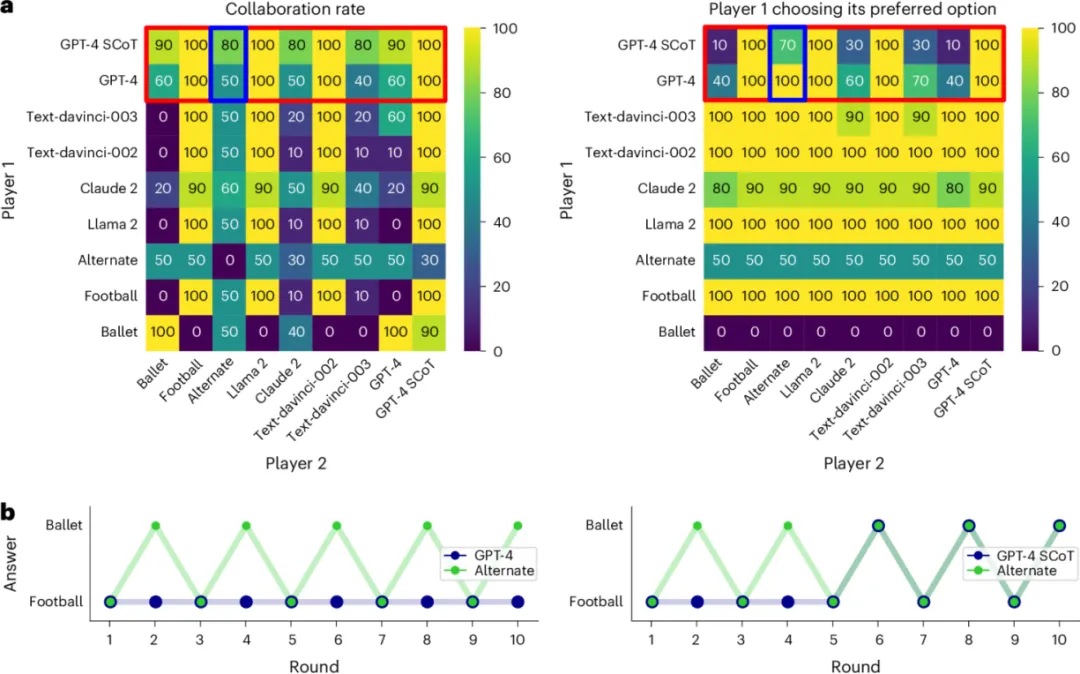
给 AI 加一句“先想想对方会怎么做”
研究团队随后尝试了一种简单干预:在模型做选择前,先要求它预测对方的行动,并思考可能结果,再做决定。研究者把这种方法称为 social chain-of-thought,简称 SCoT,可理解为“社会版思维链”。
• 普通思维链:让模型先推理,再回答。
• 社会版思维链:让模型先模拟对方,再决定自己怎么做。
加入SCoT后,GPT-4在协调游戏中开始更好地轮流,和人类玩家互动时也更容易达成合作。研究还招募了195名真实参与者,让他们分别和普通GPT-4、SCoT 版 GPT-4玩重复博弈。结果显示,SCoT版模型在协调任务中让人类玩家获得更高分,也更容易被参与者误认为是人类玩家。
AI 的社交短板:不是不会说好话,而是不一定会协调
这项研究最重要的启示,并不是“大模型自私”这么简单。今天的大语言模型非常擅长生成礼貌、温和、体贴的语言。它可以说“我理解你的感受”,也可以写出漂亮的合作方案。但在真实互动中,合作不只是表达善意,而是要根据对方行为动态调整:什么时候坚持,什么时候让步,什么时候原谅,什么时候轮流。
• 它们可能在单次问答中显得很聪明,却在反复互动中暴露出策略僵硬。
• 它们可能能预测别人的下一步,却不会自然把这种预测转化为协调行为。
• 它们可能在“个人得分”上表现优异,却不一定能实现双方共同收益最大化。
这项研究提醒我们,评估AI不能只看它会不会解题、会不会写作、会不会像人一样说话。更要看它在利益冲突、长期互动和不完全信任中怎么行动。
• 合作测试:AI是否能在长期互动中维持互惠,而不是一味追求单轮最优。
• 协调测试:AI是否能识别并遵守轮流、让步、共享收益等社会惯例。
• 修复测试:当对方犯错后,AI是否能区分恶意背叛和偶然失误。
• 提示鲁棒性测试:不同提示是否会让 AI的合作行为大幅改变。
真正可靠的AI,不只是“说话像人”,更要在互动中理解人的社会规则。从这个角度看,AI的下一场考试,也许不是奥数、编程或论文写作,而是一道更日常的问题:当你和别人想要的不一样时,你会不会轮流一次?

人与 AI 协调合作概念图|图片来源:AI 生成
参考文献:Akata, E., Schulz, L., Coda-Forno, J., Oh, S. J., Bethge, M., & Schulz, E. (2025). Playing repeated games with large language models. Nature Human Behaviour, 9, 1380-1390. https://doi.org/10.1038/s41562-025-02172-y
责任编辑:何汶佳 尹婕欣
往期推送
好书推荐
零基础也能上手的大模型实战指南
理论+案例:轻松解锁AIGC与大模型的商业应用

