 夜雨聆风
夜雨聆风你大概率遇到过这种事。
你让 AI 助手干个活——查个订单、调个接口、读条记录,结果它不老老实实去查,反而给你编了一个。语气特别笃定,看着特别像真的,但就是错的。
大多数人第一反应是:模型嘛,幻觉很正常。
但有一种出错,跟模型聪不聪明一点关系都没有。它的原因特别无聊、特别结构性,无聊到几乎没人会去想。
真相是:AI 和它要对话的那个应用,手里拿的是两本不一样的说明书。
01
说明书对不上
举个例子。一个工程师要做一个工具,比如「按 ID 查客户」。
这个工具他得写两遍。
一边是普通的网页接口,给仪表盘和脚本调用。一边是 MCP 工具,给 Claude、Cursor 这种 AI agent 去发现和调用。
两遍共用同一套核心逻辑,但各自有各自的外壳:路由、校验、参数定义。
问题就出在外壳上。网页那份写着,查询要传一个数字 ID。AI 那份写着,要传一个文本名字。

或者更准确地说——三次更新之前,它确实是传文本名字的。后来有人把它改成了数字 ID,但忘了同步改 AI 那一份。
于是 AI 拿着旧说明书去调用,传了个错的格式。工具直接拒绝。
而这时候 AI 不会老老实实报错说「我格式传错了」,它会顺手填一个看着合理的猜测糊弄过去。
这就是那句话:模型没笨,是你给了它一张过时的地图,然后怪它撞墙。
02
92% 的工具都可能中招
你可能觉得,这种低级失误能有多普遍。
2025 年有一篇研究专门扒了这件事。结果是:AI agent 依赖的工具层,92% 都只是把现成的网页接口包了一层皮。
这个数字之所以要命,是因为它意味着「写两遍」是常态,不是个例。
AI 用一种语言去发现和调用工具,而仪表盘、脚本、手机 App、批处理用的是另一种语言。两种语言描述的是同一个能力。
只要是两份分开维护的定义,时间一长,就一定会对不上。这个对不上有个名字,叫 schema drift,模式漂移。
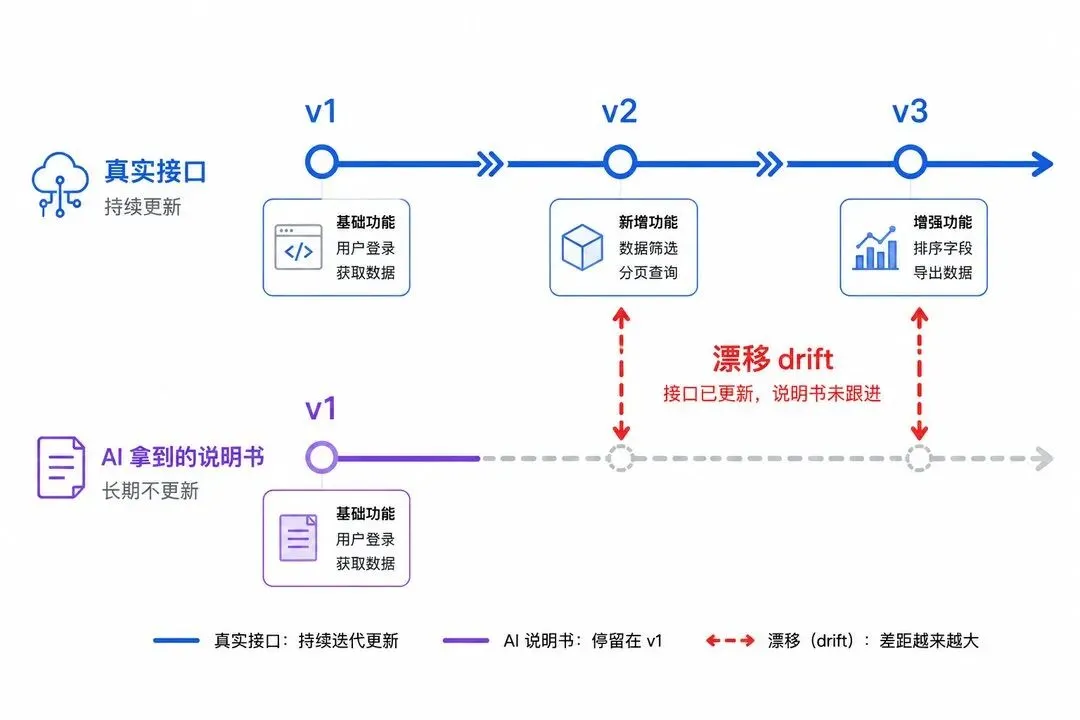
更隐蔽的是,漂移不一定是改代码改出来的。有人把模型从一个版本升级到下一个版本,模型就悄悄开始忽略某个字段,他四天后才发现——因为返回的数据还是合法的,工具照样能跑,输出看着也正常。
错就错在,它一直在错,只是没人看出来。
03
说到底,这是人的问题
这里有个容易被忽略的点。
我们总说模型不稳定、AI 今天行明天不行。Agent 今天生成的报告格式乱飞,明天代码审查漏掉关键漏洞,后天做规划直接跳步骤。
但很多时候,不是模型在漂移,是指令在漂移。
是人在两份说明书之间漏改了一份,是人每次运行都去手动改一改提示词,然后回过头纳闷:这 AI 怎么一天一个样。
模型只是忠实地执行了它当下拿到的那份说明书。它拿到的是过时的,它就给你过时的结果。
有个开发者说得挺到位:MCP 这类协议负责的是「编排」,它并不负责「校验」。底层的数据只要对不上——格式不一致、术语没定义、快照过时——你拿到的就是可复现的垃圾。
错得稳定,错得每次都一样。
04
两个方向
那怎么办?大方向有两个。
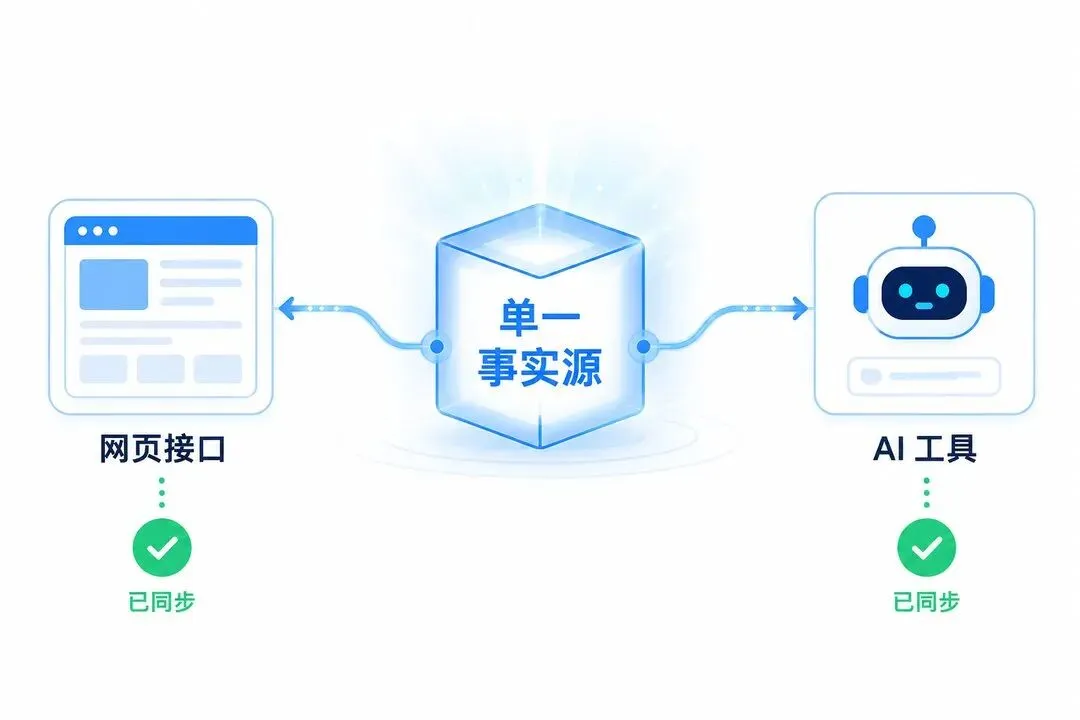
第一个是从源头堵。与其把一个能力的定义写两遍,不如只写一份「单一事实源」,让网页接口和 AI 工具都从这一份自动生成。一份改了,两边一起变,根本没有漂移的机会。研究里提到,这样做顺带还能砍掉 74% 的重复样板代码。
第二个是认命,然后兜底。有人干脆不再等模型变得不幻觉,而是把整个工作流建成「假设它一定会幻觉」的样子:限定它能动的范围、关键步骤要人审批、上线前跑冒烟测试、最后再过一遍差异审查。让一个错误必须连闯四关才能溜进生产环境。
这两个方向其实是一回事:别再盯着模型,去修模型周围那套早就该修的管道。
下次你的 Agent 又一本正经地胡说,先别急着骂它笨。低头看看,是不是你给它的那张地图,早就过期了。
关注 AI探花,继续帮你把这些 AI 工程里的弯弯绕绕讲明白。
都看到这了,关注下 AI探花。
后面我会继续挖这种 AI 工具和开源项目的信息差。
