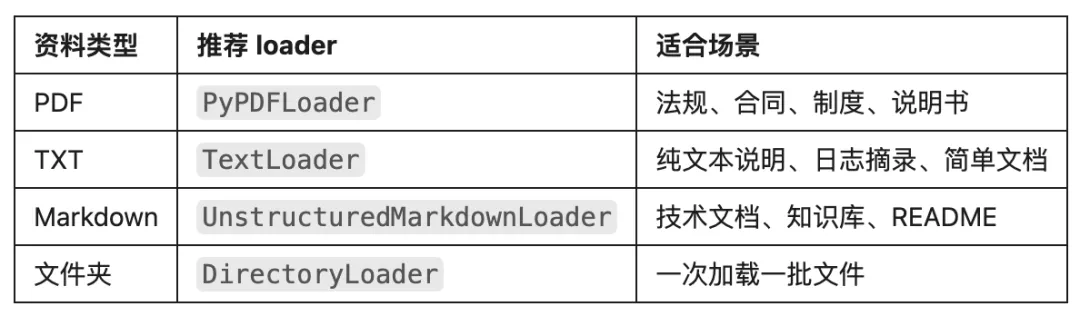
主要是让人更深的感受一下它的用法和适用场景,至于剩下的主流资料源,它们本质上都在做同一件事:把不同来源的资料加载成 LangChain 的 Document。所以本篇不展开赘述,只保留最常用、最容易在本地实际跑起来的几类:PDF、TXT、Markdown、文件夹批量加载,梭哈讲一下。一、先看怎么选
不用背。先看你的资料长什么样,再选 loader。别为了用高级 loader,把简单事情搞复杂。二、PDF:PyPDFLoader
默认建议先按页加载,因为页码对 RAG 很有用。用户问制度或法律问题时,最好能追到“第几页”。# 安装:uv add langchain-community pypdffrom pathlib import Pathfrom langchain_community.document_loaders import PyPDFLoaderpdf_path = Path("data/中华人民共和国数据安全法.pdf")# mode="page":一页 PDF 生成一个 Document。# 好处是 metadata 里会保留 page / page_label,方便后续引用页码。loader = PyPDFLoader(str(pdf_path), mode="page")documents = loader.load()print(len(documents))print(documents[0].page_content[:500])print(documents[0].metadata)
101 中华人民共和国数据安全法 (来源:中国人大网,2021-07-21) 中华人民共和国数据安全法 (2021 年6 月10 日第十三届全国人民代表大会常务委员会第二十九次会议通过) 目 录 第一章 总 则 第二章 数据安全与发展...{'producer': 'Microsoft® Word 2010', 'creator': 'Microsoft® Word 2010', 'creationdate': '2021-08-09T09:17:07+08:00', 'author': 'xxx', 'moddate': '2021-08-09T09:17:07+08:00', 'source': 'data/中华人民共和国数据安全法.pdf', 'total_pages': 10, 'page': 0, 'page_label': '1'}
三、纯文本:TextLoader
适合 .txt、简单日志、纯文本说明。一个文本文件默认读成一个 Document。所以就算 xiaoshuo.txt很长,len(documents) 也通常是1。这不是异常,说明 loader 已经把整份文本搬进来了。后面要不要按章节、段落、长度切开,是TextSplitter的事情。# 安装:uv add langchain-communityfrom pathlib import Pathfrom langchain_community.document_loaders import TextLoadertext_path = Path("data/xiaoshuo.txt")# encoding 很重要。中文文本建议显式写 utf-8,少给自己挖坑。loader = TextLoader(str(text_path), encoding="utf-8")documents = loader.load()print(len(documents))print(documents[0].page_content[:500])print(documents[0].metadata)
1第一章 崭露头角 青少年时代在意大利半岛的西面,有一个形状如鸡蛋的海岛,名为科西嘉岛。该岛山峦起伏、丛林密布。岛上居住着一个顽强好斗的民族,他们犹如雄鹰一般,时刻盘旋在自己的窝巢之上,对来犯敌人进行毫不留情的痛击。科西嘉岛属热那亚商业国,18世纪上半叶,岛上人民开始了反对热那亚占领者的民族独立运动。他们在自己的领袖保利的领导下,赶走了热那亚人,成立了科西嘉独立政府。然而,好景不长,1768年5月15日,热那亚同法国签订了科西嘉归让法国的秘密协定,把实际上已不拥有的对科西嘉的"权力"出售给法国。法国强大的远征军占领了该岛的沿海城镇。岛上居民对这种出卖和蹂躏科西嘉人民自由权利的行径极为愤慨,他们再度团结一致,在保利的指挥下,展开了反抗法国入侵者的战斗。 保利身边有位年轻的副官名叫夏尔。波拿巴,他是岛上阿雅克修城的一个贵族,当时正在攻读法律。夏尔具有狂热的性格,他痛恨法国人的入侵,毅然放下书本,带着妻子莱蒂齐亚。拉莫利诺参加了科西嘉保卫战。炮声隆隆,飞尘蔽日,岛上居民顽强地抗击着登陆的法军。夏尔的第一个孩子约瑟夫便出生在这个战火纷飞的年代。1769年春,岛上居民终因寡不敌众,被迫向征{'source': 'data/xiaoshuo.txt'}
如果一个 TXT 很长,TextLoader只是先读进来,后面通常还要接 TextSplitter。Loader 负责搬进门,切不切块是下一步。四、Markdown:UnstructuredMarkdownLoader
适合技术文档、README、内部知识库、Notion 导出的 Markdown。Markdown 比 TXT 多了标题、列表、链接这些结构。用普通 TextLoader也能读,但UnstructuredMarkdownLoader更适合保留一些文档结构信息。注意:这个 loader 依赖markdown包。如果没装,运行时可能会报ModuleNotFoundError: No module named 'markdown'。# 安装:uv add langchain-community unstructured markdownfrom pathlib import Pathfrom langchain_community.document_loaders import UnstructuredMarkdownLoadermd_path = Path("data/internal_refund_guide.md")md_path.write_text( "# 退款操作手册\n\n" "## 未发货订单\n" "用户可以直接在订单详情页申请退款。\n\n" "## 已发货订单\n" "需要先确认物流状态,再进入售后流程。\n", encoding="utf-8",)# mode="single":整篇 Markdown 作为一个 Document。# mode="elements":按标题、正文等元素拆成多个 Document,适合更细粒度处理。loader = UnstructuredMarkdownLoader(str(md_path), mode="single")documents = loader.load()print(documents[0].page_content[:500])print(documents[0].metadata)
退款操作手册未发货订单用户可以直接在订单详情页申请退款。已发货订单需要先确认物流状态,再进入售后流程。{'source': 'data/internal_refund_guide.md'}
- 想按标题、段落等结构拆得更细:`mode="elements"`
别一上来就 elements。先看你的文档是不是值得这么细。五、文件夹批量加载:DirectoryLoader
policies/ refund.txt invoice.txt 中华人民共和国数据安全法.pdf
这时候不要指望DirectoryLoader 自动识别所有格式。它的作用是批量找文件,然后把文件交给指定 loader。所以更清楚的做法是:按文件类型分批加载。# 安装:uv add langchain-community pypdffrom pathlib import Pathfrom langchain_community.document_loaders import DirectoryLoader, TextLoader, PyPDFLoaderfolder = Path("data/policies")folder.mkdir(exist_ok=True)# 第一批:加载 txt 文件。# DirectoryLoader 负责找到所有 txt;TextLoader 负责读取每个 txt。txt_loader = DirectoryLoader( str(folder), glob="**/*.txt", loader_cls=TextLoader, loader_kwargs={"encoding": "utf-8"},)# 第二批:加载 pdf 文件。# DirectoryLoader 负责找到所有 pdf;PyPDFLoader 负责按页读取每个 pdf。pdf_loader = DirectoryLoader( str(folder), glob="**/*.pdf", loader_cls=PyPDFLoader, loader_kwargs={"mode": "page"},)txt_documents = txt_loader.load()pdf_documents = pdf_loader.load()# 最后把不同类型加载出来的 Document 合并。documents = txt_documents + pdf_documentsprint("txt docs:", len(txt_documents))print("pdf docs:", len(pdf_documents))print("all docs:", len(documents))print(documents[0].page_content[:300])print(documents[0].metadata)
txt docs: 2pdf docs: 10all docs: 12未发货订单支持退款。{'source': 'data/policies/refund.txt'}
 夜雨聆风
夜雨聆风