 夜雨聆风
夜雨聆风如果你这两个月还在问“国内外所有大模型到底谁最强”,我劝你先把这个问题拆掉。
不是因为它不重要。
是因为它太像 2015 年问“所有手机谁最好”。你当然能拉一个跑分榜,但最后你会发现:有人要拍照,有人要游戏,有人要续航,有人只是想微信别卡。
大模型也一样。
截至 2026 年 6 月 2 日,国内外主流模型已经分成几条很清晰的路:OpenAI、Anthropic、Google 在推前沿闭源能力;Meta、Mistral 在开源和企业部署里打得很凶;国内的 DeepSeek、Qwen、Kimi、豆包、混元、GLM、MiniMax,则在成本、中文、长上下文、代码、视频和私有化上各自找位置。
这篇不做“全宇宙模型百科”。那玩意儿写完就过期。
我只做一张能力地图:你到底该用谁,为什么用它,以及别被哪些幻觉糊弄。
第一梯队不是一个榜单,而是几种性格

先说国外。
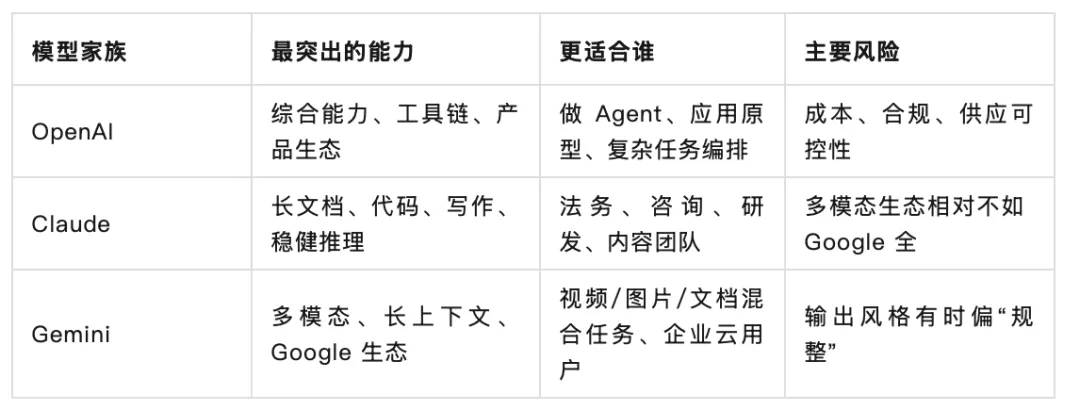
OpenAI 的优势依然是综合能力和产品化速度。官方模型文档里,OpenAI 已经把模型线拆成了面向复杂推理、实时对话、视觉、多模态生成、嵌入、音频等不同用途的产品矩阵。它最强的地方不只是“会聊天”,而是 API、工具调用、文件处理、视觉、语音、Agent 工作流这些东西被打包得比较顺。
说白了,OpenAI 像一套已经装修好的办公室。贵,规矩多,但你今天搬进去,明天就能开工。
Anthropic 的 Claude 系列,尤其适合长文档、代码审查、写作和复杂任务的安全边界控制。它的产品气质一直很明显:少一点花哨,多一点稳。很多团队喜欢 Claude,不是因为它每个 benchmark 都第一,而是因为它在长上下文、指令遵循和“别乱来”这件事上比较有分寸。
Google Gemini 则是另一种打法。Gemini 的核心优势是原生多模态、超长上下文,以及和 Google 生态的结合。你如果处理的是视频、图片、文档、搜索、Workspace、Android、云服务,Gemini 的位置会很自然。
三句话粗暴概括:
这不是排名。
硬要排,就会变成那种特别无聊的表格:A 模型数学强,B 模型代码强,C 模型便宜。看起来很专业,实际帮不了你做决定。
真正的问题是:你的业务到底在消耗哪一种能力。
如果你做的是客服、数据分析、销售助手、知识库问答,模型“世界第一”没有那么值钱。稳定、便宜、能接系统、能控权限,可能更值钱。
如果你做的是代码 Agent、自动化运维、复杂研究,那前沿推理和工具调用就值钱。
如果你做的是短视频、广告、商品图、语音直播,那多模态和生成质量比文字推理更值钱。
别拿尺子量水。
国内模型不是“追赶者”这么简单
国内模型过去最容易被写成“追赶 OpenAI”。这话有一半对,一半懒。
对的是,前沿通用推理上,海外闭源模型仍然有很强的领先窗口。尤其是复杂数学、长链路 Agent、跨模态任务和英文高质量知识任务,OpenAI、Anthropic、Google 的头部模型依然能打。
懒的是,只用“追赶”两个字,会遮住国内模型真正有意思的地方。
DeepSeek 的价值,不只是某个版本能力强,而是它把“高性能 + 低成本 + 开放权重/开放推理路线”的叙事打穿了。DeepSeek-R1 之后,很多团队第一次认真计算:我是不是没必要每个任务都上最贵的闭源模型?
Qwen 是另一个典型。阿里 Qwen3 发布时强调了混合推理模型、开源权重、多尺寸模型和多语言能力。它的优势是模型谱系完整,从小模型、本地部署到大模型 API,都有路线。对企业来说,这比“某个单点模型很强”更实用。
Kimi 的标签是长上下文和中文内容处理。它适合处理大段材料、研报、合同、会议纪要、长网页。你把几十页材料扔进去,它不会立刻摆烂。这一点很具体,也很值钱。
豆包/Seed 的位置更偏产品和多模态。字节系模型背后有内容、推荐、视频和 C 端产品经验,做图像、视频、语音、应用入口时,打法和纯 API 公司不太一样。
混元、GLM、MiniMax、百度 ERNIE 这些模型,也不是“谁强谁弱”一句话能盖住。腾讯混元有腾讯云和产业场景,GLM 在 Agent 和国产私有化语境里存在感强,MiniMax 在语音、角色和视频相关产品上跑得很快,百度 ERNIE 则和搜索、文心一言、企业智能体平台绑得更深。
国内模型的真实优势,可以压成四个字:场景贴地。
中文语境、国内合规、私有化部署、价格战、调用延迟、和本地云厂商/办公系统/内容平台的连接,这些东西在论文榜单里不性感,但在公司预算会上很性感。
嗯。
预算会上没人会因为你用了“最聪明的模型”鼓掌。老板只会问:一个月多少钱?数据能不能出境?出错谁负责?能不能接我们的老系统?这周能不能上线?
只看能力,你会选错;要按任务切模型
我更建议把模型能力拆成 7 个维度。
这张表有点粗。
但比“某某模型第一”有用。
举个例子。你要做一个公司内部知识库,目标是让员工问制度、查合同、找流程。这个任务的核心不是模型会不会写诗,也不是数学题能不能秒杀。它的核心是:长文档召回、权限隔离、引用来源、稳定响应、成本可控。
这时候 Kimi、Qwen、GLM、DeepSeek 或者国内云厂商方案,可能比直接上最贵的海外模型更合适。
再换一个场景。你要做一个能自动读 issue、改代码、跑测试、提 PR 的代码 Agent。那就不能只图便宜。模型需要理解大型代码库,需要工具调用稳定,需要长链路任务不跑偏。Claude、OpenAI、DeepSeek/Qwen Coder 这类模型都值得测,但测试方式不能是“写个二分查找”。
写二分查找,太糊弄了。
你应该拿真实仓库测:让模型修一个边界 bug、补一个单元测试、解释一段祖传代码、处理一次失败 CI。谁能少问废话、少改无关文件、少产生隐藏 bug,谁才是真的强。
再比如内容团队。公众号、短视频脚本、商品详情页、直播话术,这些任务的“模型智商”没那么玄。中文风格、可控语气、稳定产出、配图/视频/语音链路,反而决定效率。豆包、Kimi、Qwen、MiniMax 这类国内产品,经常更贴手。
别笑。
很多团队不是被模型能力卡住,是被工作流卡住。
国外模型强在上限,国内模型强在落地缝隙

如果一定要给一个判断,我会这样说:
国外头部模型强在能力上限,国内模型强在落地缝隙。
上限是什么?复杂推理、前沿多模态、Agent 工具链、模型产品一致性、开发者生态。这些地方,OpenAI、Anthropic、Google 的优势还在,而且不是一天两天能追平。
缝隙是什么?中文办公、国产云、私有化、价格、垂直行业、内容平台、企业采购流程、数据合规。这里国内模型会越跑越顺,因为它们知道地面是什么样子。
这就像汽车。
F1 赛车当然强,但你每天上班不需要 F1。你需要的是不挑路、不费油、维修方便、停车不心疼。可如果你要跑赛道,那小电驴再便宜也没用。
大模型选型最蠢的方式,就是所有任务只认一个模型。
有些公司现在已经开始做“模型路由”:简单任务走便宜模型,复杂任务走强模型;中文材料走国内模型,英文研究走海外模型;高敏数据走私有化,公开内容走 API;生成初稿走低成本,最终审校走高能力。
这才像个正常系统。
模型不是信仰,是供应链。
供应链最怕单点依赖。今天一个 API 涨价,明天一个服务限流,后天一个政策变化,你整套业务就潮湿了,拧都拧不干。
2026 年最该看的,不是模型名字
接下来半年,我会重点看 5 件事。
第一,Agent 能不能从演示走到稳定工作流。现在很多 Agent demo 很漂亮,真上生产就开始瞎折腾:多调用一步工具、多改一个文件、多编一个参数。小错不贵,连环小错很贵。
第二,多模态会不会从“看懂图片”走到“处理真实业务”。比如读票据、看视频、理解屏幕、生成可用素材、操作软件。这比聊天更接近钱。
第三,长上下文会不会变成真长记忆。现在不少模型能塞很多 token,但塞进去不等于找得到,找得到不等于用得对。长上下文如果只是一个大胃王,那也挺尴尬。
第四,开源模型会不会继续压低闭源模型利润。DeepSeek、Qwen、Llama、Mistral 这条线如果继续进步,闭源模型就必须证明自己贵得有道理。
第五,国内模型会不会出现真正的全球开发者生态。不是国内企业采购,不是聊天产品装机量,而是 GitHub、Hugging Face、开发者工具链、第三方插件、海外创业公司愿不愿意长期用。
这个指标很硬。
也很残酷。
如果今天让我选,我会这样配
别问“最强模型是哪一个”。问“我的任务该怎么配”。
如果是个人知识工作:Claude / OpenAI / Gemini 选一个主力,再配 Kimi 或 Qwen 处理中文长文档。 如果是公司内部知识库:优先测 Qwen、DeepSeek、Kimi、GLM、混元这类国内方案,再看是否需要海外模型补强。 如果是代码 Agent:Claude、OpenAI、DeepSeek Coder、Qwen Coder 都测,拿真实仓库说话。 如果是内容生产:豆包、Kimi、Qwen、MiniMax、OpenAI 都可以进候选,重点看图文音视频工作流。 如果是私有化和成本敏感:DeepSeek、Qwen、Llama、Mistral 这类开放路线必须进池子。 如果是研究和复杂推理:头部闭源模型还是要留一张牌,别为了省钱把最难的任务交给最便宜的模型。
我的个人偏见是:2026 年不要押单一模型。
押模型组合。
前沿能力用最强的,日常任务用最稳的,批量调用用最便宜的,敏感数据用最可控的。这样不浪漫,但活得久。
大模型竞争已经过了“谁更像神”的阶段,进入了“谁更像电”的阶段。
电不需要被崇拜。
它要稳定,要便宜,要接得进插座,还不能一开空调就跳闸。
你现在用的模型,更像神,还是更像电?
