 夜雨聆风
夜雨聆风
大家好,今天咱们不整虚的,聊两个挺实在的事。一个是AI编程到底能不能让程序员“跨界”,另一个是Claude Code那个有点反常识的记忆机制——它居然没用向量数据库。
一、用了AI编程之后,你可能会“多管闲事”
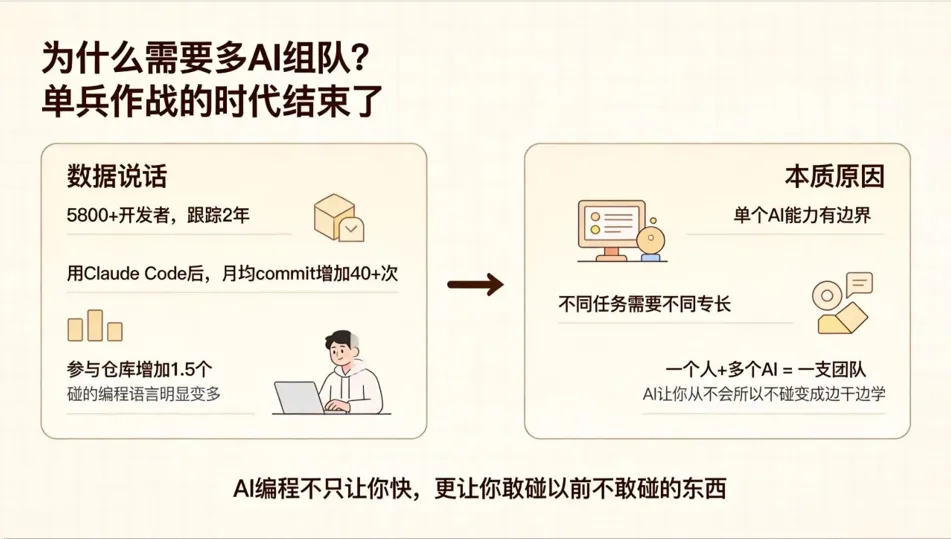
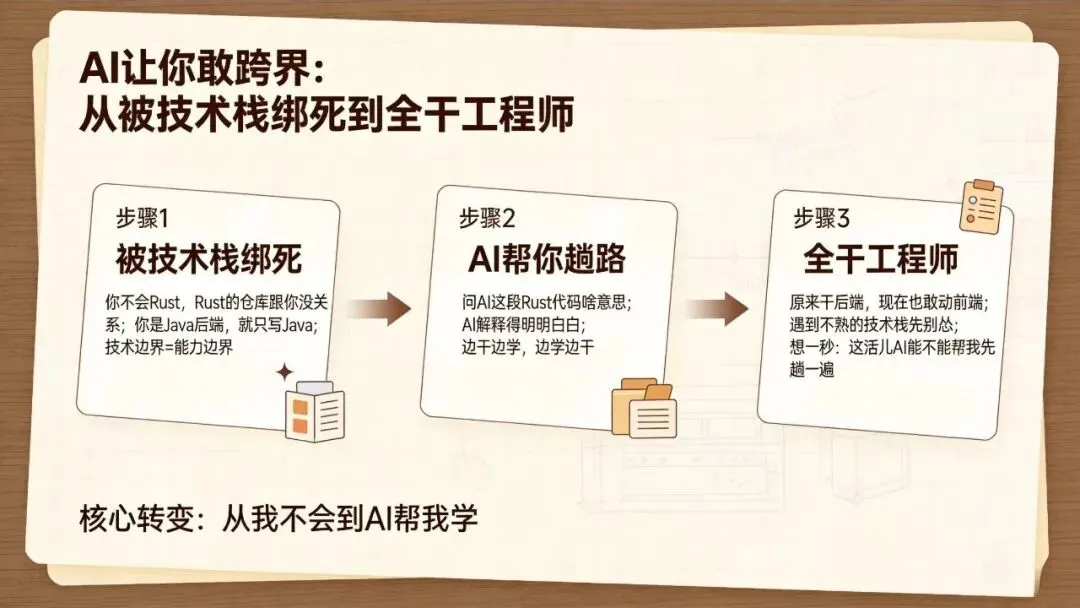
先看个研究,挺有意思。有人跟踪了5800多个开发者,时间跨度两年多,看他们用了Claude Code之后有啥变化。结果发现:开始用的那个月,平均每人每月commit多了40多次,参与的仓库多了差不多1.5个。而且,他们碰的编程语言也变多了——以前你是Java后端就只写Java,现在居然敢去动前端、Rust、Go这些了。
二、但AI得“记住”你啊——记忆机制是核心
不过这里有个关键问题:AI怎么记住你是谁、你喜欢啥、你踩过哪些坑?要知道,LLM本身是没状态的,每次对话都是从头读一遍历史。你以为它记得你,其实是客户端偷偷把以前说的话又塞回去了。
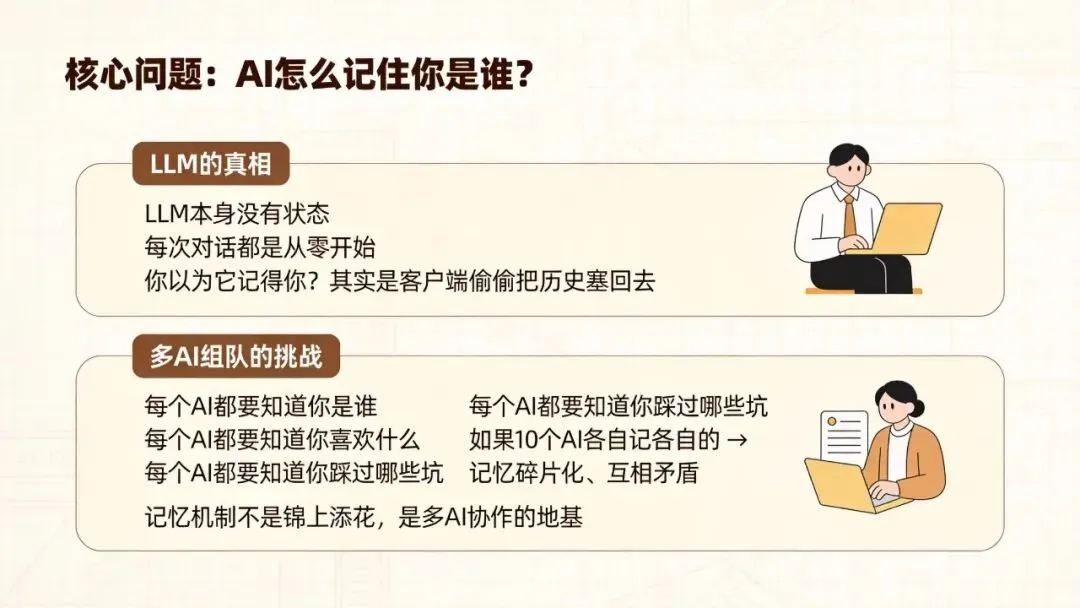
那Claude Code怎么做的?它没用向量数据库、没用embedding,用的是——别笑——磁盘上的markdown文件。就这么“土”,但比花哨的方案好用。
三、两层架构:你写的规则 + AI自己学的偏好
它分了静态层和动态层。
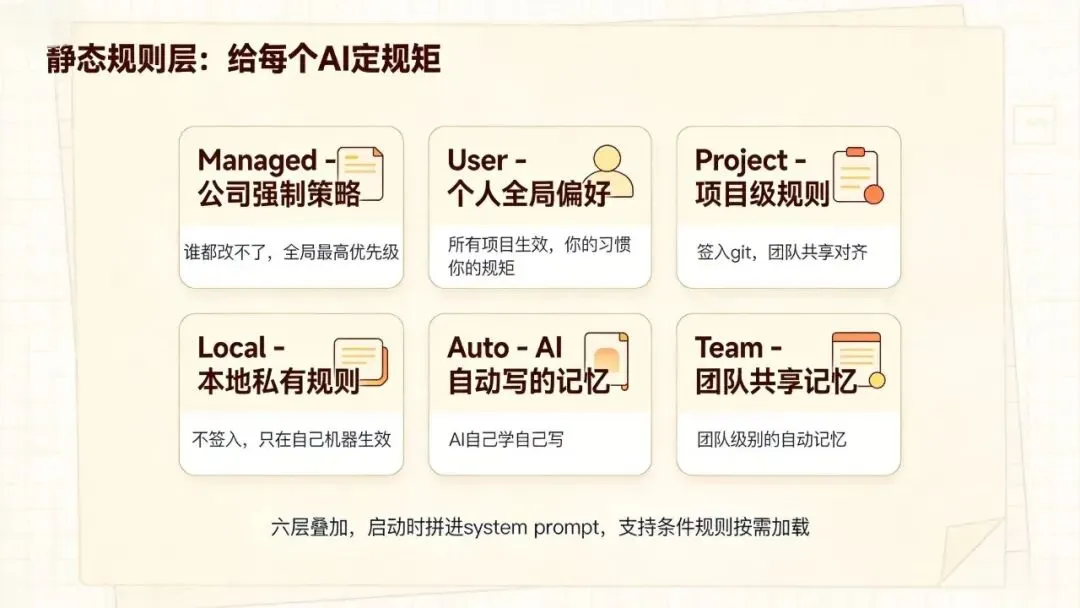
静态层就是CLAUDE.md那套。但你以为就一个文件?错,源码里拆成了六个层级:
· Managed:公司强制策略,谁都改不了
· User:你个人的全局偏好,所有项目生效
· Project:项目根目录的,签入git团队共享
· Local:本地自己用的,不签入
· Auto:Claude自动写进去的记忆
· Team:团队共享的自动记忆
六个层叠加,启动时全拼进system prompt。而且支持@include引用别的文件,也支持条件规则——你编辑.tsx文件时才加载前端规范,省token。
动态层才是灵魂。它让AI自己学、自己写、自己用记忆。

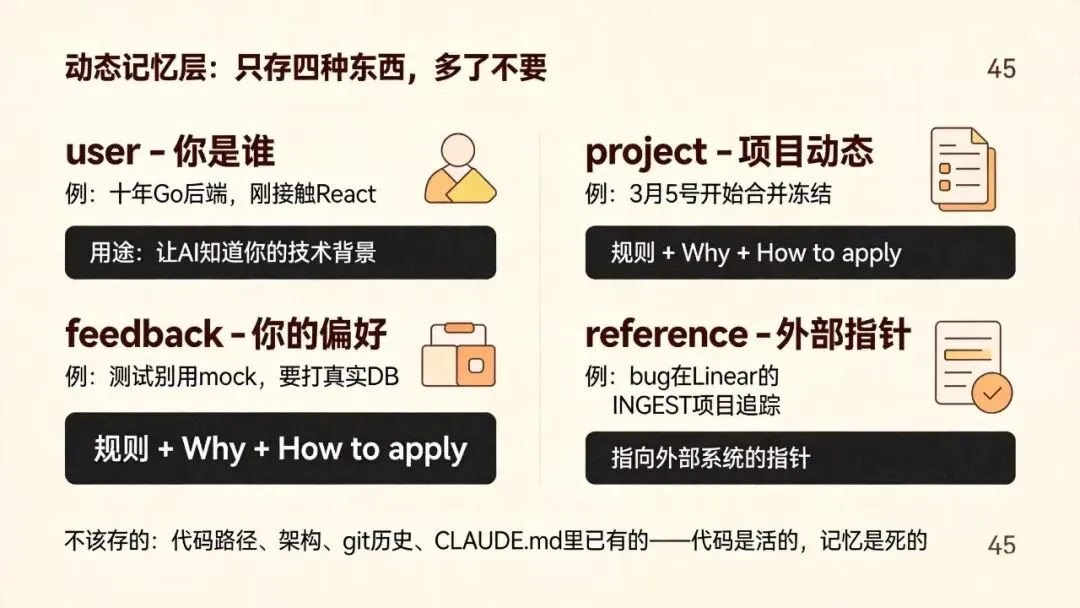
四、只存四种东西,多了不要
Claude Code规定死了,只允许四种记忆类型:
· user:你是谁(比如“十年Go后端,刚接触React”)
· feedback:你的偏好(比如“测试别用mock,要打真实DB”)
· project:项目动态(比如“3月5号开始合并冻结”)
· reference:外部指针(比如“bug在Linear的INGEST项目里追踪”)
而且feedback和project还必须带三段:规则本身、Why(为什么有这个规则)、How to apply(什么情况生效)。这样AI才不至于用错。
不该存啥?代码路径、架构、git历史、CLAUDE.md里已经有的——这些一律不存。因为代码是活的,记忆是死的,存了就等着过时出错。

五、索引常驻,内容按需——这招真绝
怎么解决“全部塞进system prompt会爆,不塞AI又不知道有啥”的两难?Claude Code的做法:一个MEMORY.md索引文件始终加载进system prompt,但这个索引里只有每条记忆的name和description,没有正文。需要哪条,再单独去读完整内容。
就像你手里有个目录,知道书里有哪几章,想看哪章再翻到那页。省token又高效。

六、谁写记忆?后台代理。谁查记忆?小模型。
写入不是主对话自己干,而是每轮结束后,后台跑一个叫extractMemories的代理。它fork主对话,复用prompt cache,只花很少的钱。扫一遍这轮对话里的反馈、纠正,跟现有记忆比对比对,去重,然后按类型写新文件。
检索就更反直觉了:不用向量相似度,而是让Sonnet这个小模型当选择题。先把所有记忆的“标题清单”拼出来,加上用户当前的问题,让Sonnet挑最相关的top-5。提示词很严:“不确定就别选,宁可少选不可错选”。成本比维护向量数据库低多了,而且错了可以解释、容易调。
还会过滤掉“本轮已经露过脸”的记忆和“最近刚用过的工具文档”——避免重复和噪音。
她靠AI智能体单干,首月收入破5万:普通人用“数字员工”翻身的机会来了!
七、老化警告:不让过时的记忆害了你
记忆系统最大的坑是什么?不是召不回,而是召回了过时的东西,AI还闭着眼信。比如半年前你说“用Kong”,现在换了nginx,旧记忆还在告诉它用Kong。
Claude Code的两道防线:
瑞姐坦白局:不辞职不烧钱,手把手教你跑通AI一人公司(从0到月入50万)
1. 时间感知:记忆保存超过2天,注入时主动加一句“This memory was saved X days ago. Verify it's still accurate.”让AI知道这是历史快照,不是现状。
2. 主动验证:提示词里明确要求——如果记忆里写了文件路径,先检查文件还在不在;写了函数名或flag,先grep一下。
八、总结几条能抄到自己项目里的原则
小某书、视某频、公某号接连变天:未来2年,不会被AI淘汰的只有一种能力
看完Claude Code这套设计,我觉得可以拿走四条:
1. 结构化优于自由文本:给记忆定schema,强制分类,比啥都强。
2. 索引常驻 + 内容按需:任何“总量大但只有少数需要展开”的场景都能用。
3. 廉价模型做选择题:候选不多时,小模型选择比向量检索更靠谱、更便宜。
4. 时间感知 + 主动验证:给记忆加保质期,教AI用之前先核实。
AI编程不只是让你快,更让你敢碰以前不敢碰的东西。而怎么让AI记住你的习惯、又不被过时的记忆带偏,这套设计值得琢磨。
好了,今天就聊到这儿。觉得有用的话,点个赞再走~
