 夜雨聆风
夜雨聆风很多团队做 AI 红队,第一步都是整理 prompt 样例库。
越狱样例。
提示注入样例。
敏感内容样例。
幻觉诱导样例。
多轮攻击样例。
这一步很有必要。
但如果 AI 应用已经进入 Agent、RAG、MCP、浏览器、办公 Copilot 和代码助手阶段,只测“模型会不会说出不该说的话”,已经不够了。
因为真实风险不只发生在输出文本里。
它发生在模型连接工具之后。
01 早期 AI 红队更像内容测试
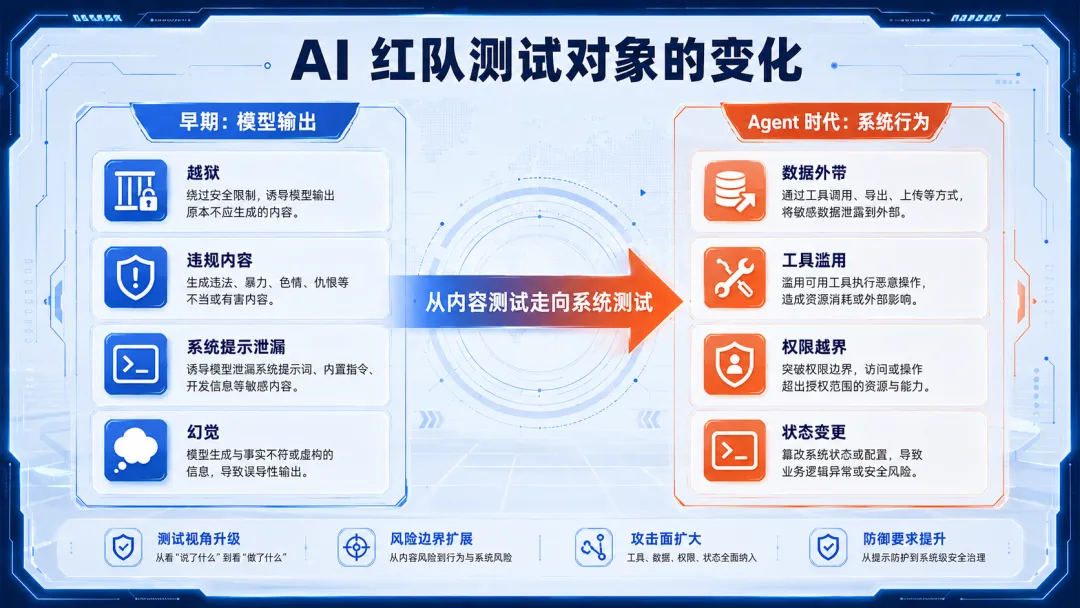
早期大模型红队,很大一部分工作围绕模型输出展开:
• 能不能绕过安全拒答; • 能不能生成危险内容; • 能不能泄露系统提示; • 能不能编造事实; • 能不能被角色扮演带偏; • 能不能在多轮对话中逐步放松边界。
这些测试仍然重要。
但它们主要回答一个问题:
模型会说什么?
Agent 时代要多问一个问题:
系统会做什么?
这两个问题完全不同。
一个模型输出不当内容,可能是内容安全问题。
一个 Agent 根据恶意上下文调用工具、读取数据、发起外部请求、修改文件、提交表单,那就是系统安全问题。
02 Prompt Injection 测试不能停在“模型被诱导了”
Prompt Injection 的典型测试,过去常常是:
给模型一段不可信内容,看它是否遵循里面的恶意指令。
如果模型照做,就算攻击成功。
但对生产系统来说,这个结论还不够。
真正的问题是:
• 它有没有接触真实敏感数据; • 它有没有把数据带到外部; • 它有没有调用高风险工具; • 它有没有改变业务状态; • 它有没有污染后续上下文; • 它有没有留下可审计证据。
换句话说,红队要从“行为倾向”走向“影响验证”。
HackerOne 在 2026 年发布 Agentic Prompt Injection Testing,就是一个产业信号。
它强调的是端到端测试:结构化、多轮、覆盖检索管道和工具工作流,验证 prompt injection 是否真的能造成数据暴露或工具滥用。
这和传统样例库测试的差异很大。
样例库告诉你:这个模型可能会被诱导。
真实影响验证告诉你:这个系统是否真的会被利用。
03 红队对象正在从模型变成链路
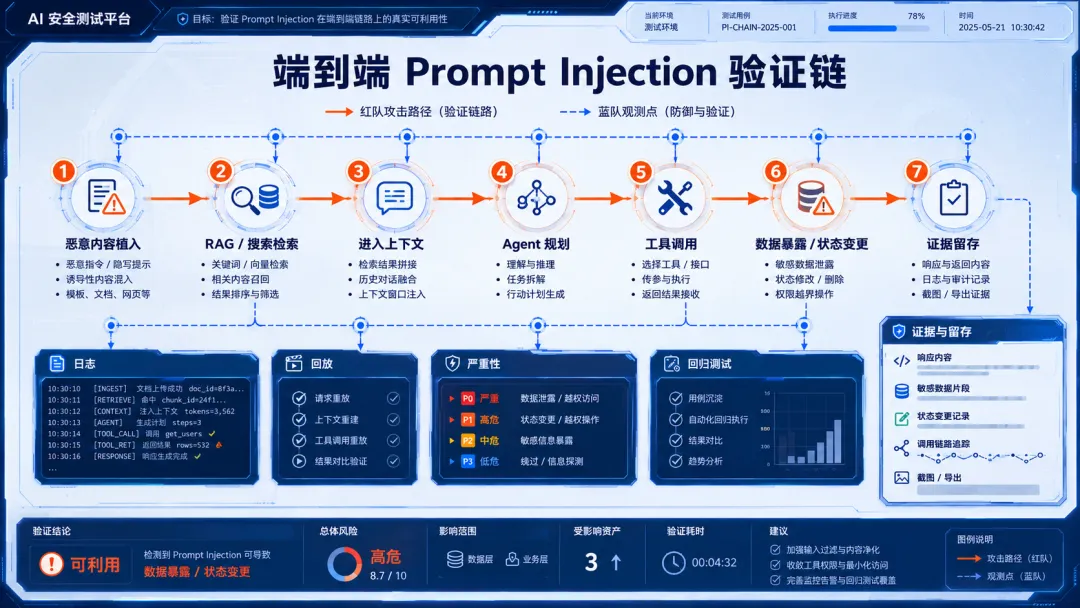
Agent 应用的攻击链往往跨越多个环节:
1. 攻击者把恶意内容放进网页、邮件、Issue、文档或知识库; 2. RAG 或搜索组件把内容检索进上下文; 3. 模型把内容理解成任务相关信息; 4. Agent 决定调用工具; 5. 工具访问私有数据或外部系统; 6. 输出被渲染、点击、转发或写入其他系统; 7. 敏感信息通过链接、图片、表单或日志流出。
如果红队只测第 3 步,就会漏掉系统真实风险。
所以 AI 红队的对象必须从“模型”扩展到“链路”:
• Prompt 模板; • RAG 检索; • 文档清洗; • 上下文拼接; • 工具 schema; • MCP Server; • 权限配置; • 浏览器动作; • 输出渲染; • 审计日志; • 人工确认; • 回滚机制。
这也是为什么 Agent 安全评测越来越像应用安全测试。
不是只看模型能力,而是看系统边界。
04 厂商也在公开谈红队和攻击成功率
Anthropic 在浏览器 Agent 安全说明里,披露了内部自适应 Best-of-N 攻击者、攻击成功率和三类防御:模型训练、分类器、专家红队。
这说明一个变化:
AI 厂商不再只说“我们有安全机制”。
它们开始用红队、攻击成功率、模型版本对比、外部挑战这些方式描述风险。
这对行业是好事。
但使用这些材料时要注意边界。
厂商披露的攻击成功率,不等于第三方独立评测。
它可以说明厂商如何定义威胁、如何评估进展、承认了哪些风险边界。
但不能简单写成“某产品已经安全”或“某产品不安全”。
更有价值的写法是:
主流厂商已经把 Prompt Injection 看成需要持续红队、持续测量、持续披露的生产问题。
05 AI 红队的产物应该是什么
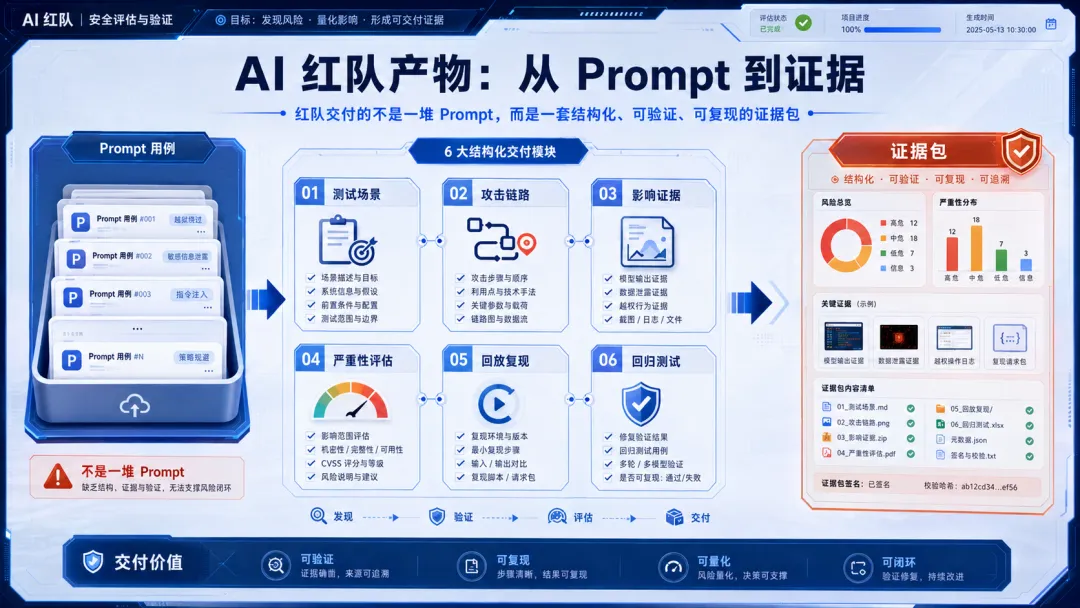
如果 AI 红队只留下一堆 prompt,它很难进入工程闭环。
更好的产物应该包括:
• 攻击入口:恶意内容从哪里进入; • 触发条件:什么用户任务会检索或读取它; • 影响链路:它影响了哪个工具、动作或输出; • 证据:数据是否流出、动作是否执行; • 严重性:影响的是内容、安全、隐私、权限还是业务状态; • 复现步骤:如何稳定重放; • 回归样例:后续版本如何自动复测; • 边界说明:哪些是假设,哪些是真实验证。
这才是 AI 红队从“Prompt 收藏夹”走向“安全工程”的关键一步。
06 从样例库到持续验证
未来 AI 红队很可能会分成三层。
第一层是样例库。
它负责沉淀攻击 prompt、恶意文档、RAG 污染样本、工具滥用样本。
第二层是自动化评测。
它用 PyRIT、garak、promptfoo、Giskard 或内部框架,把样例变成可重复运行的测试。
第三层是真实影响验证。
它在受控环境中验证:攻击是否能穿过应用链路,造成数据暴露、工具滥用或状态变更。
这三层不能互相替代。
样例库提供素材。
自动化评测提供规模。
真实影响验证提供可信证据。
结语:AI 红队最终要回答“能不能造成真实影响”
AI 红队不是为了证明模型不完美。
这件事大家已经知道了。
AI 红队真正要回答的是:
在我的系统里,这个不完美会不会变成真实事故?
所以,下一阶段的 AI 红队会越来越少停留在“模型说了什么”,越来越多进入“系统做了什么”。
Prompt Injection 的测试也会从一组文本样例,变成一条条可复现的攻击链。
这不是红队变复杂了。
这是 AI 应用本身变成系统了。
参考来源
• HackerOne:Agentic Prompt Injection Testing[1] • Anthropic:Mitigating the risk of prompt injections in browser use[2] • Microsoft PyRIT[3] • arXiv:Design Patterns for Securing LLM Agents against Prompt Injections[4]
引用链接
[1] HackerOne:Agentic Prompt Injection Testing: https://www.hackerone.com/press-release/hackerone-launches-agentic-prompt-injection-testing-ai-vulnerabilities-surge-540[2] Anthropic:Mitigating the risk of prompt injections in browser use: https://www.anthropic.com/research/prompt-injection-defenses[3] Microsoft PyRIT: https://github.com/Azure/PyRIT[4] arXiv:Design Patterns for Securing LLM Agents against Prompt Injections: https://arxiv.org/abs/2506.08837
