 夜雨聆风
夜雨聆风算力的尽头是互联,互联的未来是光。
一、AI真正的瓶颈,正在从“算力”转向“连接”
过去谈人工智能,大家最关注的是GPU、HBM、先进制程和大模型参数量。但随着大模型从百亿、千亿参数走向更大规模,AI基础设施的核心矛盾正在发生变化:不是一颗芯片能算多快,而是成千上万颗芯片能不能像一台超级计算机一样协同工作。
在大模型训练中,GPU之间需要频繁交换梯度、参数、激活值和中间结果;在大规模推理中,模型并行、专家模型、长上下文和多模态输入,也会带来巨大的数据搬运需求。这意味着,AI数据中心不只是“算力工厂”,更是一个庞大的“数据流动系统”。
如果说GPU是AI的发动机,那么高速网络就是AI的血管;如果网络不够快、不够稳、不够低延迟,再强的GPU也可能在等待数据中浪费时间。AI时代的竞争,表面上是芯片竞争,深层次则是高速互联能力的竞争。
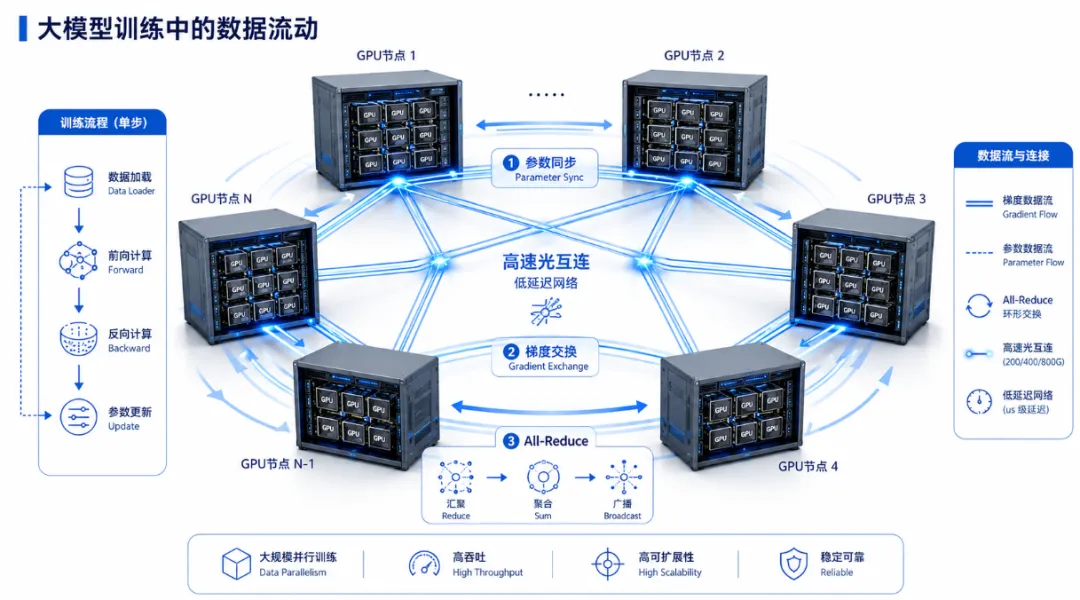
二、为什么AI需要高速光通信?
AI数据中心内部主要有三类连接需求:
第一类是Scale-up连接,也就是服务器内部或机柜内部GPU之间的高速互联,例如GPU与GPU、GPU与CPU、GPU与内存之间的数据交换。
第二类是Scale-out连接,也就是不同服务器、不同机柜之间的互联,用来把大量GPU组成一个训练集群。
第三类是Scale-across连接,也就是跨机房、跨园区甚至跨城市的数据中心互联,让更大规模的AI基础设施协同工作。
随着AI集群规模扩大,连接距离变长、端口速率提高、功耗密度上升,传统电互连和铜缆连接会遇到越来越明显的限制:
第一,带宽提升越来越困难。高速电信号在PCB、连接器和铜缆中传输时,损耗、串扰和反射都会急剧增加。
第二,传输距离受限。铜缆适合短距离连接,但当距离从几米扩展到几十米、几百米甚至更远时,光通信的优势会迅速显现。
第三,功耗压力越来越大。AI数据中心已经是高功耗系统,网络互联本身也会消耗大量电能。若每一比特数据传输都需要更高能耗,系统总能效将难以持续提升。
第四,部署密度和散热压力增大。800G、1.6T甚至更高速率的端口需要更高的信号完整性和热设计能力,传统插拔模块、铜缆和电接口都面临挑战。因此,AI基础设施的发展方向十分清晰:数据越多,距离越远,速率越高,越需要用光来传输。

三、光模块:AI数据中心的“光电转换器”
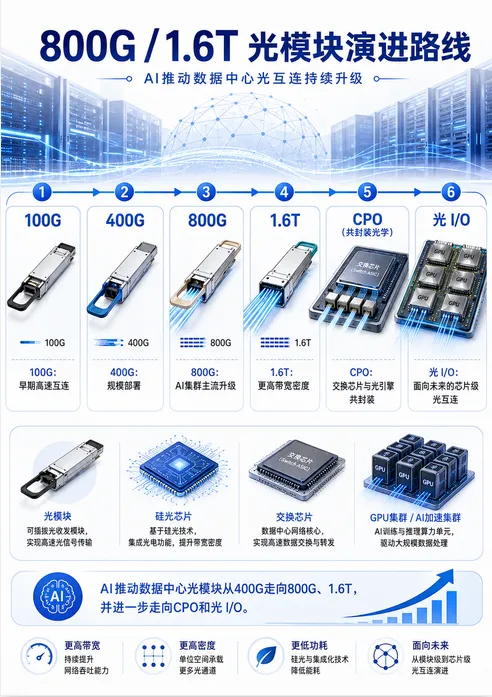
在AI数据中心中,光通信并不是抽象概念,而是通过一个个具体器件实现的,其中最核心的器件之一就是光模块。光模块的作用可以简单理解为:把芯片输出的高速电信号转换成光信号,通过光纤传输;到达另一端后,再把光信号转换回电信号。也就是说,光模块是AI服务器、交换机、网卡和光纤之间的关键桥梁。近年来,数据中心光模块速率不断演进:从100G、200G,到400G、800G,再到1.6T,速率提升背后的驱动力正是云计算、AI训练和高性能计算的爆发式增长。当前,800G正在成为AI数据中心的重要部署方向,1.6T则正在加速走向产业化。[参考1][参考2]
在短距离场景中,VCSEL、多模光纤等方案仍具有成本和功耗优势;在中长距离和更高速率场景中,硅光、EML、相干光通信、薄膜铌酸锂等技术路线正在快速发展。未来,不同场景不会由单一技术完全取代,而是形成多种光电技术并行演进的格局。
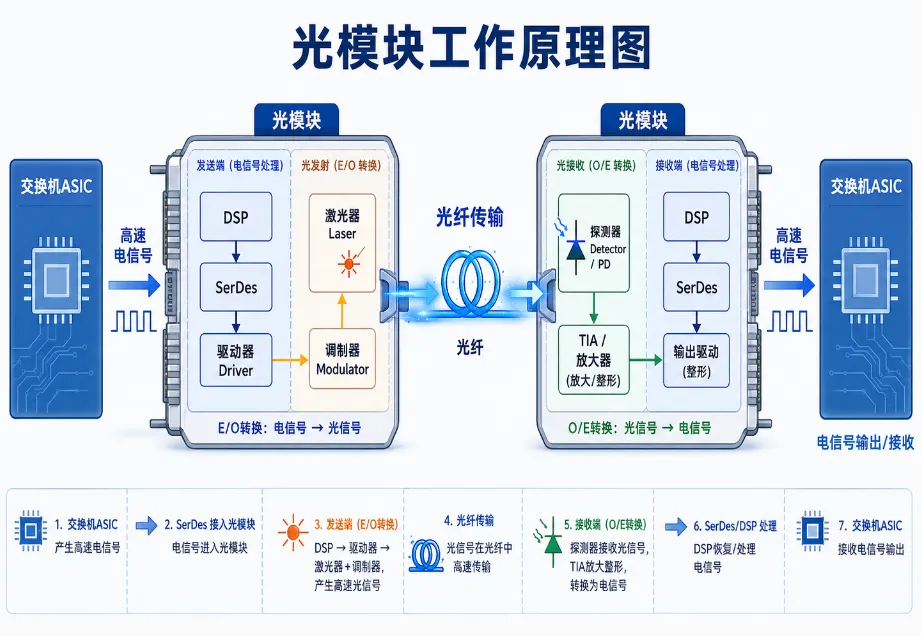
四、从800G到1.6T:AI正在推动光通信进入新周期
AI对网络的要求,不只是“更快”,还包括更低延迟、更高可靠性、更低功耗和更强可扩展性。
以800G和1.6T为代表的新一代高速光通信,正成为AI数据中心建设的重要基础设施。800G提升的是单端口带宽,1.6T则进一步提高端口密度和系统吞吐能力。
这背后有几个关键技术趋势:
1. 单通道速率从100G/lane走向200G/lane,甚至更高。这要求高速激光器、调制器、探测器、DSP和SerDes全面升级。
2. 光模块形态从QSFP-DD、OSFP走向更高密度封装。端口速率提高后,散热、功耗、信号完整性和可维护性都会成为系统级问题。
3. 硅光技术加速进入数据中心。硅光可以利用半导体工艺实现光子芯片集成,有望在高带宽、低功耗和大规模制造方面发挥优势。
4. CPO共封装光学成为下一代方向。传统方案中,交换芯片和光模块之间仍需要高速电连接。当速率继续提高时,把光引擎更靠近交换芯片,甚至与交换芯片共封装,可以减少高速电信号传输距离,降低功耗并提升带宽密度。[参考3]简单来说,过去光通信主要解决“远距离传输”问题;而AI时代,光通信正在进入服务器、交换机乃至芯片附近,解决“近距离超高速互联”问题。这就是所谓的:光进铜退,光电融合。
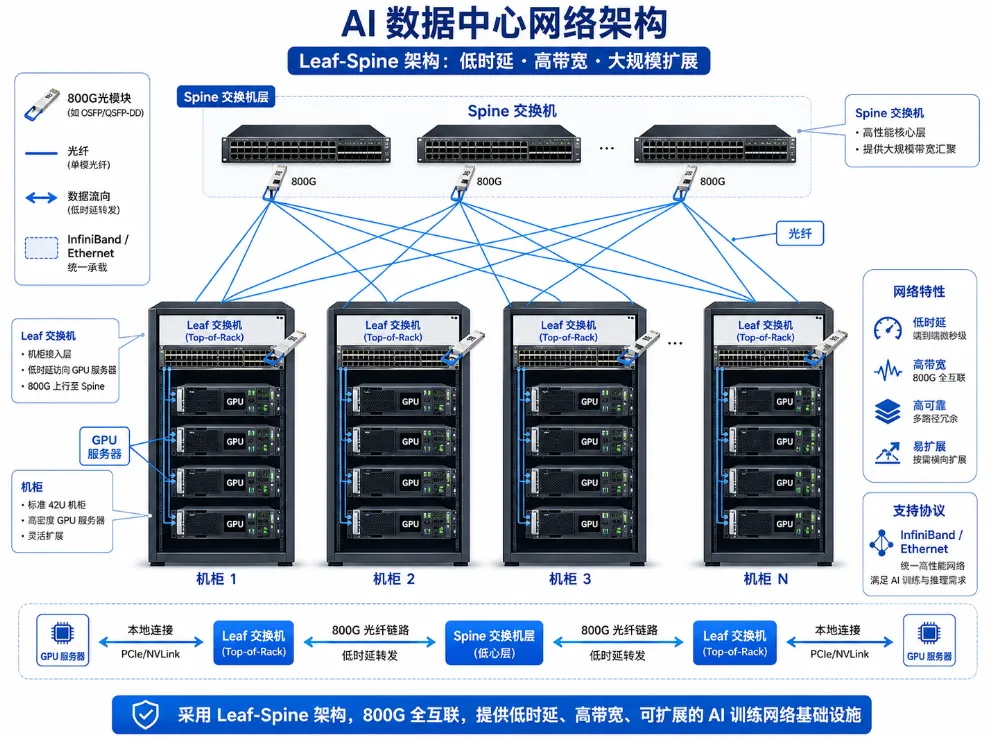
五、AI数据中心为什么离不开低延迟和高可靠网络?
很多人以为AI网络只要“带宽大”就够了,但实际上,AI训练对网络质量极其敏感。在分布式训练中,一个训练任务可能运行在数千甚至数万张GPU上。如果网络出现拥塞、丢包、抖动或链路故障,就会导致部分GPU等待其他GPU同步结果。只要有少数节点慢下来,整个训练任务就可能被拖慢。这就是AI网络和普通互联网流量最大的不同:普通网络更关注平均吞吐量;AI训练网络更关注可预测性能、低延迟、低抖动和高稳定性。因此,面向AI的数据中心网络不仅需要高速光模块,还需要高速交换芯片、智能网卡、拥塞控制、负载均衡、RDMA、网络遥测和自动化运维共同协同。高速光通信并不是孤立存在的器件产业,而是AI系统工程的一部分。
六、高速光通信的关键技术版图
面向AI时代,高速光通信产业链正在围绕以下方向展开竞争:
1. 高速激光器
激光器是光通信系统的光源。VCSEL、DFB、EML以及外置激光源等方案,在不同距离、成本和功耗场景中各有优势。随着200G/lane、400G/lane的推进,对激光器带宽、线宽、可靠性、温度稳定性和一致性提出了更高要求。
2. 高速调制器
调制器决定了如何把高速电信号加载到光波上。硅光调制器、薄膜铌酸锂调制器、EML等技术路线,正在围绕高速、低驱动电压、低损耗和可集成性展开竞争。
3. 高速探测器
探测器负责把光信号转换成电信号。更高速率意味着更高带宽、更低噪声、更高响应度和更好的线性度。
4. DSP与SerDes
在高速链路中,光器件并不是单独工作,DSP和SerDes负责信号均衡、编码、补偿和误码控制。随着速率提升,电芯片与光芯片的协同设计越来越重要。
5. 封装与散热
800G、1.6T时代,光模块不再只是一个“可插拔小盒子”,而是热、电、光、机械共同耦合的复杂系统。封装设计、散热路径、光纤连接、可靠性测试都会成为核心竞争力。
6. 测试与量产
高速光模块和光芯片的价值,不仅在于实验室指标,更在于能否稳定量产。眼图、误码率、TDECQ、灵敏度、老化、温循、插损、回损等测试能力,是产业化落地的关键。
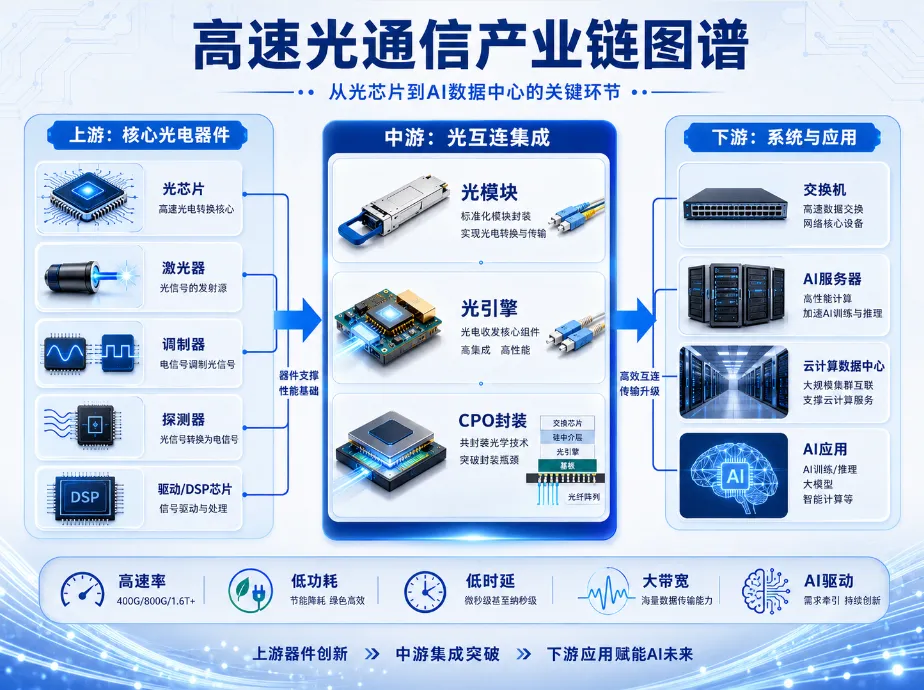
七、CPO:让光更靠近芯片
当交换芯片端口速率越来越高时,一个重要趋势是:不要再让高速电信号走太远,而是尽早把它变成光信号。这正是CPO,也就是共封装光学的核心思想。传统可插拔光模块位于交换机面板位置,交换芯片到光模块之间还需要高速电通道。当速率提升到800G、1.6T乃至更高时,这段电通道会带来更大的损耗、功耗和设计难度。CPO则把光引擎放到交换芯片附近,通过更短的电连接降低损耗,再通过光纤完成高速传输。这有望带来更高带宽密度、更低功耗和更强系统扩展能力。当然,CPO也并非没有挑战。它对封装、热管理、光纤连接、可靠性、维修更换和供应链协同提出了更高要求。因此,未来一段时间内,可插拔光模块、LPO、CPO等方案可能会长期共存,并根据不同应用场景选择最优解。

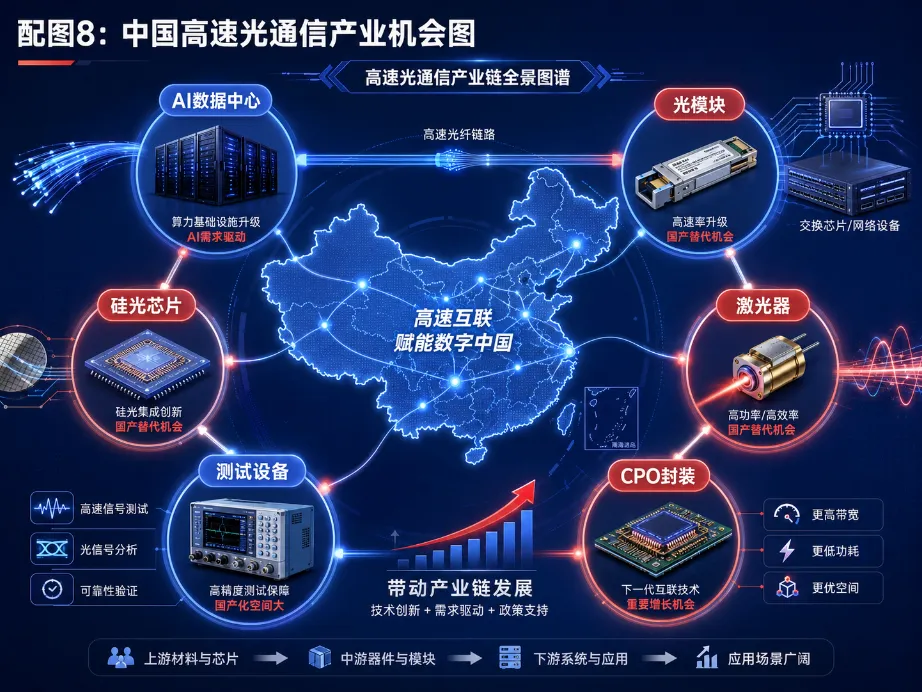
八、中国光通信产业的机会在哪里?
AI带来的高速光通信需求,不只是海外云厂商和芯片巨头的机会,也给中国光通信产业带来新的增长空间。中国在光模块制造、光器件封装、光纤连接、设备集成和工程交付方面具有较强产业基础。未来,如果能在高速光芯片、硅光平台、DSP芯片、先进封装、测试设备和系统级解决方案上继续突破,就有机会从“制造优势”走向“核心技术优势”。尤其值得关注的方向包括:
第一,800G和1.6T高速光模块。这是AI数据中心最直接的需求入口。
第二,硅光芯片与光电集成。硅光是未来光通信规模化、集成化的重要方向。
第三,高速激光器和探测器。光芯片仍然是产业链中技术壁垒最高的环节之一。
第四,CPO和光引擎。这是面向下一代AI数据中心的系统级创新方向。
第五,测试、封装和可靠性平台。 高速光通信从样品走向量产,离不开高水平测试和工程化能力。未来AI产业链的核心不只是GPU,也包括电力、散热、封装、存储、网络和光通信。谁能解决系统瓶颈,谁就能在AI基础设施中占据关键位置。
九、结语:AI越强,越需要光
AI的发展路径,本质上是不断扩大模型、数据和算力规模的过程但算力不会凭空形成智能,只有当大量计算单元被高速、低延迟、低功耗地连接起来,AI系统才能真正释放能力。未来的AI数据中心,将不再只是服务器的堆叠,而是计算、存储、网络、光电、散热和能源共同优化的复杂系统。在这个系统中,高速光通信不是配角,而是基础设施。从400G到800G,从1.6T到CPO,从光模块到硅光芯片,从数据中心互联到芯片级光互连,光通信正在一步步靠近AI的核心。
AI发展的尽头,不只是更强的芯片;也是更快的连接、更低的功耗、更高效的数据流动。高速光通信,正在成为AI发展的必由之路。
算力决定AI的上限,连接决定AI能否抵达上限。高速光通信,是AI时代最重要的基础设施之一。
