 夜雨聆风
夜雨聆风这就是视觉语言模型(Vision Language Models,VLMs)在做的事:它给 AI 装上了眼睛。
最近重温写于2024年4月Hugging Face上的技术博客《Vision Language Models Explained》,那时候VLMs还是一个听起来很专业的领域。但两年后的今天,视觉语言模型已经渗透到了AI Agent的每一个前沿:从Claude Code能直接读图审查代码,到AI医生能分析医学影像,到自动驾驶系统实时理解路面情况。你看到的每一条"AI 能看懂你的截图并帮你操作"的功能,背后几乎都有 VLMs 的影子。
2年过后,有必要回顾下这篇技术博客,温故知新,也总结思考一下:智能体时代,智能体和VLMs放一起做一些类比也来预测下接下来会发生什么,走起!
一、什么是视觉语言模型:先从一个哲学问题开始
传统语言模型的问题是:它只活在文字里。
你告诉它"一只猫坐在窗台上",它能完美地处理这个描述——但它不知道窗台长什么样,不知道"猫"这个词对应的是什么样的毛色、体型、表情。它对世界的理解,是从人类的文字描述里蒸馏出来的概率分布,而不是从真实感知中生长出来的理解。
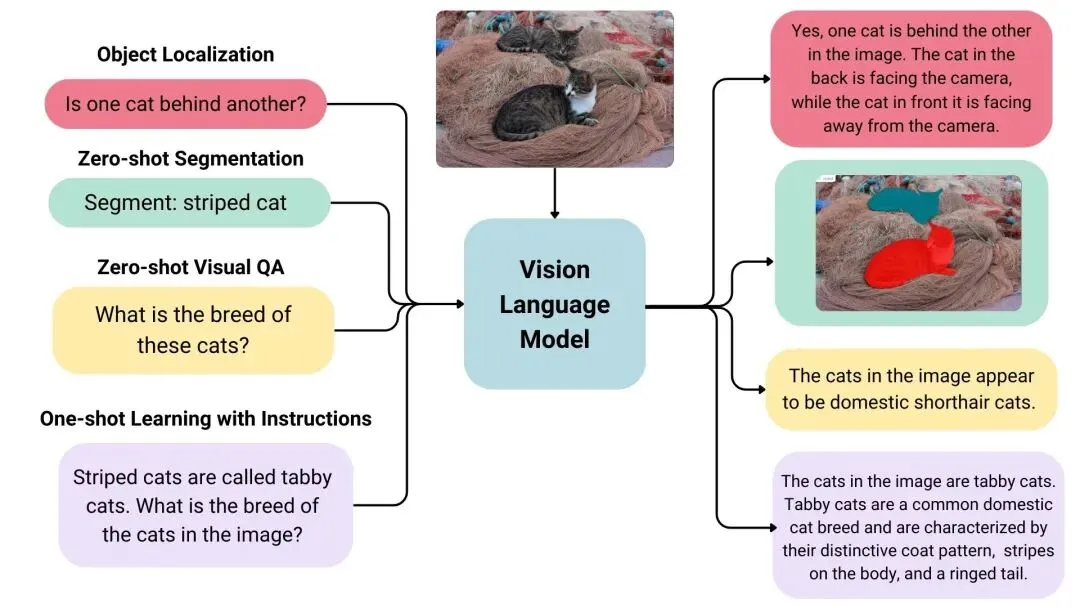
视觉语言模型试图打破这面墙。
VLM的定义很宽泛:能同时从图像和文本中学习的模型。 输入一张图片加一段文字,输出文字。这听起来简单,但它打开了一整个宇宙的能力:看图回答问题(VQA)、看图写说明、文档理解、目标检测、空间推理……
更厉害的是现代大型 VLMs 的零样本能力(zero-shot)——它们训练时见过的图片类型,不等于它们只能处理那些类型。一个 VLM 可以看网页截图、工厂仪表盘、艺术画作、代码界面、家庭装修图——不是专门为每种场景训练的,但它都能处理。
这引出了一个深刻的问题:当一个语言模型能"看",它的"理解"还是原来意义上的理解吗? 一只"看见"过十万张猫照片的 AI,它对"猫"这个概念的理解,和一个只读过"猫"这个词一千次的人,谁的理解更接近真实?
这个问题没有定论。但它指向了 VLMs 最有价值的方向:它们不只是处理图像的工具,它们在改变 AI 对世界的建模方式。
二、技术拆解:三个积木,一个目标
要理解VLM的内部机制,只需要记住三个组件。
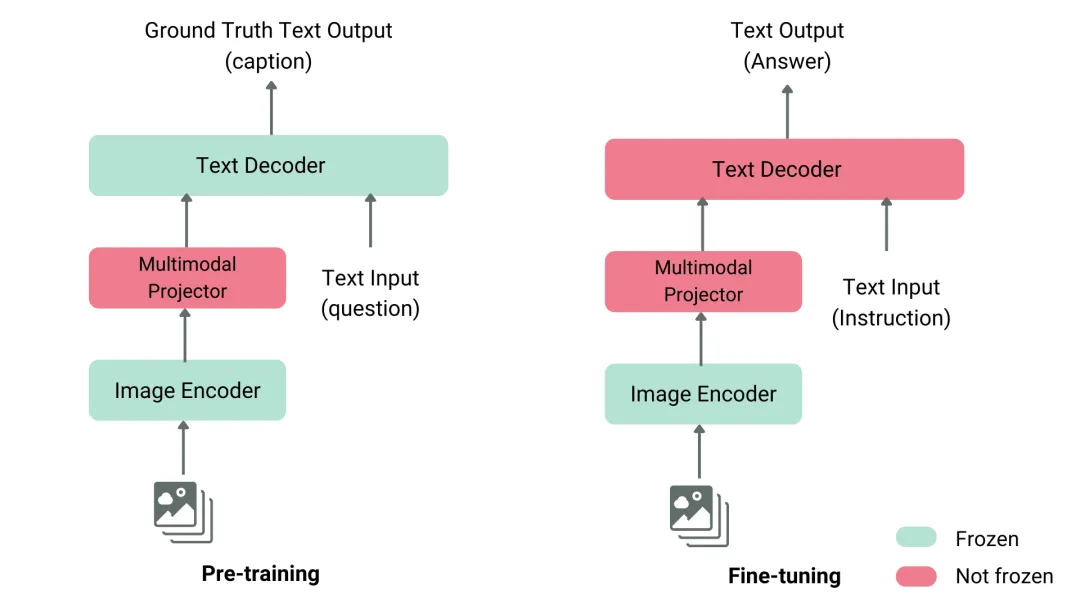
图示:VLM技术细节--一个典型的VLMs结构
组件一:图像编码器(Image Encoder)
图像编码器的任务是把像素信息转化成一个 AI 能处理的向量表示——一种"数字化的图像"。
不同的 VLM 选择不同的编码器。LLaVA 用的是 CLIP——OpenAI 开源的多模态预训练模型,专门在大规模图像-文本配对数据上训练过,能把图像和文字映射到同一个语义空间。简单说,CLIP 学会了一种能力:看到一张图,它知道这张图"在说什么";读到一个词,它知道这个词"长什么样"。
组件二:多模态投影器(Multimodal Projector)
这是 VLM 里最容易被忽略、但其实最关键的组件。它的任务是:把图像编码器输出的向量,翻译成语言模型能理解的格式。
打个比方:图像编码器是一个说中文的翻译员,语言模型是一个说英文的工程师,两者之间需要一座桥——多模态投影器就是那座桥。它把"这张图里有一个人坐在窗台边"的信息,转化成语言模型能处理的 token 序列。
有趣的是,这座"桥"的训练成本相对低——不需要从头训练整个模型。这也是 LLaVA 方法最聪明的地方:图像编码器和语言模型都可以冻结(frozen),只训练投影器。 这大幅降低了 VLM 的训练门槛。
组件三:文本解码器(Text Decoder)
这就是标准的语言模型——比如 Vicuna(一个开源 LLM)、Qwen,或者其他任何自回归文本生成器。它接收来自投影器的多模态向量,结合用户的文字输入,生成文本输出。
三者的顺序:图像编码器 → 多模态投影器 → 文本解码器。数据流是:图像 → 编码 → 投影 → 和文字一起 → 解码 → 文字输出。
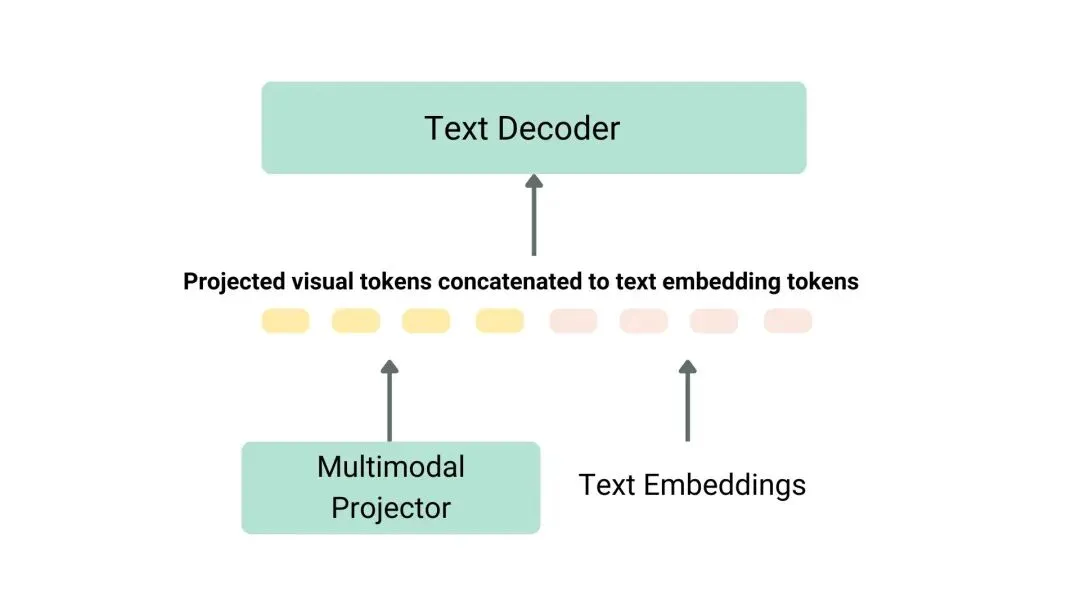
图示:VLM技术细节--投影和文本嵌入被连接在一起
三、训练方法:两阶段精调的智慧
LLaVA的训练方法值得专门讲,因为它展示了AI训练中一个非常聪明的工程决策:分阶段训练,而不是一股脑全扔进去。
第一阶段:投影器预训练。
团队做了一个很有创意的事:用 GPT-4 来生成图像描述问答对。具体来说:给 GPT-4 一张图和它的文字说明,让它问各种问题——"图里有什么颜色?""如果你是图中的人物,你会感觉到什么?"——然后生成大量这样的问答数据。
然后,他们冻结了图像编码器和文本解码器,只训练投影器。投影器在这种大规模图文问答数据上学会了:图像的哪些特征是语言模型"关心"的。
第二阶段:指令微调。
第一阶段结束后,团队解冻文本解码器(保留投影器继续训练),用更小但更精准的指令微调数据集,让模型学会"按照用户指令行动"——不只是描述图像,而是回答具体问题、执行具体任务。
这个两阶段框架后来成了大多数 VLM 训练的默认范式。原因很朴素:你不需要每次都从零开始训练整个模型。 把冻结的核心能力(图像理解 + 语言生成)和需要快速迭代的部分(投影器 + 指令遵循)分开,让精调变得便宜、快速、效果好。
四、开源VLM图谱:各有所长
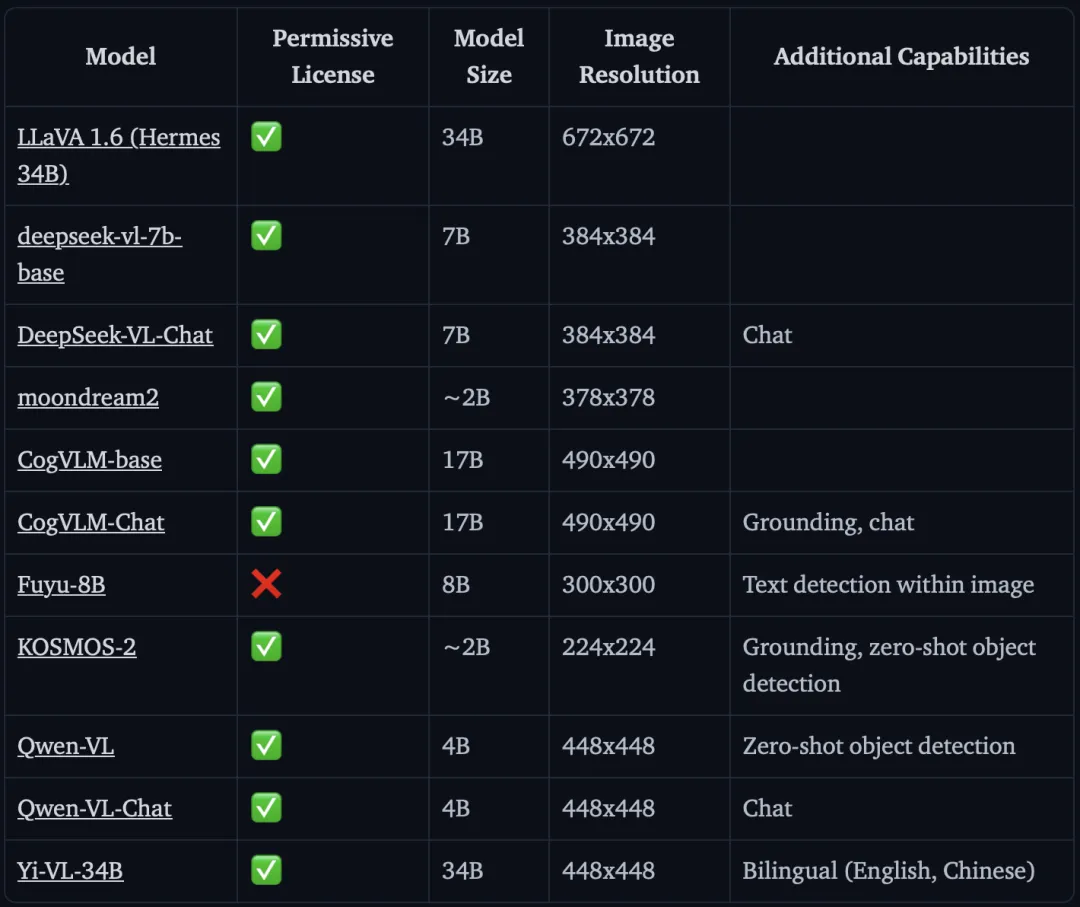
Hugging Face盘点了一批主流开源 VLM。几个值得关注的:
LLaVA 1.6 (Hermes 34B):最知名的开源 VLM 之一,34B 参数规模,672×672 图像分辨率。LLaVA 系列一直是开源 VLMs 的标杆,它的训练代码和数据集都是开源的。
Qwen-VL(通义千问视觉版):阿里开源,4B 参数,支持零样本目标检测。在中文场景下表现突出,而且阿里把它做进了产品线——你用的通义千问 App 里那些"看图"功能,很多背后就是 Qwen-VL。
DeepSeek-VL:7B 参数规模,DeepSeek 在 2024 年开源的多模态模型,性能在同等规模下表现优异。它的优势在于:DeepSeek 的语言模型底座(DeepSeek LLM)本身就强,视觉理解能力嫁接过来效果很好。
Moondream2:约 2B 参数,体积最小的开源 VLM 之一。它不是最强的,但它足够小——可以在消费级 GPU 上跑,可以在本地部署。这代表了 VLMs 的另一个方向:小而美,专为特定场景优化。
Fuyu-8B:Adept 出品,有一个反直觉的设计:它没有独立的图像编码器。 图像块(patches)直接被喂进投影层,序列通过自回归解码器处理。架构极简,但牺牲了某些能力。适合不需要精细图像理解的场景。
五、评测体系:怎么知道哪个模型更好
Hugging Face 提供了几个评测体系:
Vision Arena:匿名投票制——用户上传图片和提示词,系统匿名展示两个模型的输出,用户选择更喜欢哪个。完全基于人类偏好,没有固定答案。这种评测的好处是:它测的是"主观体验",而不是"标准答案"。对于 VLMs 这种模糊场景很关键。
Open VLM Leaderboard:基于固定评测指标的排行榜,包括 MMMU(多学科大学级视觉理解)、MMBench(20 项技能综合评测,含 OCR、目标定位等)等。
MMMU:最难的基准之一。包含 11,500 个多模态挑战,需要大学水平的学科知识和推理能力。涵盖艺术、工程、医学等不同领域。这相当于 VLM 领域的"高考"——能通过 MMMU 高分的模型,在学术和工业场景都有实战价值。
六、我的解读:从VLM到AI Agent技能自进化
重读这篇Hugging Face的博文,我一直在想一个更大的问题:VLMs的架构,和今天AI Agent Skills自进化系统之间,存在着一条深刻的类比线。
类比一:投影器 = 技能的"翻译层"
在 VLM 里,投影器的角色是把一种模态(图像)的信息翻译成另一种模态(文本)能理解的形式。这是跨模态的适配。
在 Garry Tan 的 Skillify 系统里,有一个类似的角色——技能定义文件(skill file)。它的任务是:把用户的自然语言意图,翻译成 Agent 能理解、进而执行的指令序列。两者都是"翻译层",都在两种不同的表示系统之间建立桥梁。
更进一步:当 Skillify 自动创建新技能时,它实际上是在做一件和 VLM 训练相似的事——观察大量样本(过去的对话和操作),提取可复用的模式,把它编码成结构化指令。 这和 VLM 从图文对中学习投影器的过程,在哲学上是同构的。
类比二:两阶段精调 = 技能的冷启动和适配
VLM 的两阶段训练——先在大规模数据上训练投影器,再在精准指令数据上微调——对应的是 AI Agent 技能系统的两个阶段:
第一阶段(预训练投影器) = 构建通用技能框架。Garry Tan 的 GBrain 系统里有大量通用技能——meeting-ingestion、enrich、media-ingest——它们在通用场景上被训练和验证过,形成了可复用的基础能力。
第二阶段(指令微调) = 针对具体用户和场景的技能适配。当用户说"skillify this"时,系统在用户的特定工作流上微调通用技能,形成个人化的技能配置。这就像 LLaVA 的第二阶段——同一个基础模型,通过微调变成不同用户的私人工具。
这个类比指向了一个更大的可能性:未来的 AI Agent 系统,可能会自然地涌现出类似"视觉语言模型"的跨模态能力。 当技能系统积累了足够多的"模态对"(输入输出模式),它可能会自动学会在未曾训练过的场景中"翻译"——就像 VLMs 能零样本处理各种图像类型一样。
类比三:模型层防御的局限性 = 技能的自卫边界
回到 Anthropic 那篇 Agent 安全博文里的核心洞察:模型层防御是概率性的,永远不是 100%。确定性边界才是真正的安全。
这和 VLM 的幻觉问题(hallucination)形成了有趣的对照。VLMs 也会产生幻觉——比如描述一张图里并不存在的物体。这是因为模型的"理解"本质上是统计推断,而不是真正的感知。
而 AI Agent 的 Skills 系统,如果要避免"幻觉式行为"(执行了一个用户没有意图的操作),同样需要确定性边界——也就是 Factor 7(用工具调用联系人类)和 Factor 8(拥有你的控制流)所描述的机制。
当一个 Agent 系统能同时"看见"(VLMs 的视觉理解能力)和"行动"(Skills 系统的执行能力),它就跨越了一个关键门槛:从"能聊"变成"能做"。 但跨越这个门槛的代价,是必须同时解决两套风险:视觉理解的幻觉问题,和执行控制的越界风险。
一个更大胆的预测
我认为VLMs和Skills自进化系统的下一波汇合点,会发生在"视觉技能"(Visual Skills)这个概念上。
想象一下:你不需要用文字描述一个UI界面,而是直接让AI看到它——AI能"看见"你的截图、"理解"你的Figma设计稿、"检测"代码界面里的状态变化。这不是科幻,这已经是Claude Code和多种 AI 辅助编程工具里的现实。
但更深的一层是:当Skills 能"看"时,它们就能自进化到更高的层次。 比如 Garry Tan 的 system 可以不再只依赖用户的手动输入,而能从视觉反馈中自动学习——看到自己生成的报告和真实数据之间的差距,自动调整提示词策略。这在 VLM 的术语里,叫"视觉反馈闭环"(visual feedback loop)。
七、实际应用:VLMs正在改变什么
说了这么多,VLMs在真实世界里能做什么?
文档智能(Document AI):表格识别、发票解析、手写体识别、合同关键条款提取。VLMs 比传统 OCR 加规则的方案强出一个数量级——它能理解上下文,理解文档的语义结构,而不只是识别单个字符。
医学影像辅助:虽然医疗 AI 有严格监管,但 VLMs 在 X 光、CT、病理切片上的初步分析能力已经被研究社区验证。在资源匮乏的地区,一个能在手机上跑的小型 VLM 可以提供初步筛查。
代码辅助与自动化:Claude Code 的截图分析、UI 自动测试生成、PRD 直接生成代码原型——这些能力依赖 VLM 对代码界面的视觉理解。
多语言 OCR 和翻译:Qwen-VL 和其他中文友好的 VLM,正在彻底改变跨境电商、国际物流、法律翻译等行业的信息提取效率。
八、现在可以开始做的事
Hugging Face的这篇博文末尾,附带了完整的 fine-tuning代码——用 TRL 的 SFTTrainer 来精调 LLaVA 1.5。只要一块 A100,你就能用260,000 条图文对话对在几小时内训练出一个适应你自己场景的 VLM。
即使你不打算训练自己的模型,理解VLM的架构也很有价值:当你用 Claude 的"上传图片"功能、让 AI 分析截图时,你用的是一个 VLM。 当你在某个产品里看到"AI 能理解这张图"的功能时,你至少知道它背后发生了什么——一个图像编码器,一个翻译层,一个语言模型,三者串联在一起,把像素变成了理解。
参考资料
原文来自 Merve、Edward Beeching @Hugging Face Blog《Vision Language Models Explained》,2024年4月。另有 2025 年更新版涵盖更全面的能力和模型。https://huggingface.co/blog/vlms
