 夜雨聆风
夜雨聆风兄弟们,这个PDF解析项目确实有点离谱。它叫OpenDataLoader PDF,目标很直接:把PDF转成适合AI和RAG使用的Markdown、JSON和HTML,而且强调本地CPU运行,不用GPU、不依赖云端,也不需要你把文件先传给第三方服务。
官方文档写得很狠:普通本地模式可以做到每秒60页以上,批处理并行能到100页以上;GitHub仓库说明里也提到它会保留阅读顺序、表格结构、边界框和页码。这对做知识库的人很关键,因为PDF解析错了,后面的向量库和大模型都会跟着错。

它解决的不是聊天,是RAG前处理
很多人做知识库,一上来就问哪个模型更强。其实PDF这一步没处理好,模型再强也会被脏数据拖死。多栏论文、财报表格、扫描件、页眉页脚、隐藏提示注入,这些都会影响最终问答质量。OpenDataLoader的卖点就是先把文档拆成更干净的结构化内容。
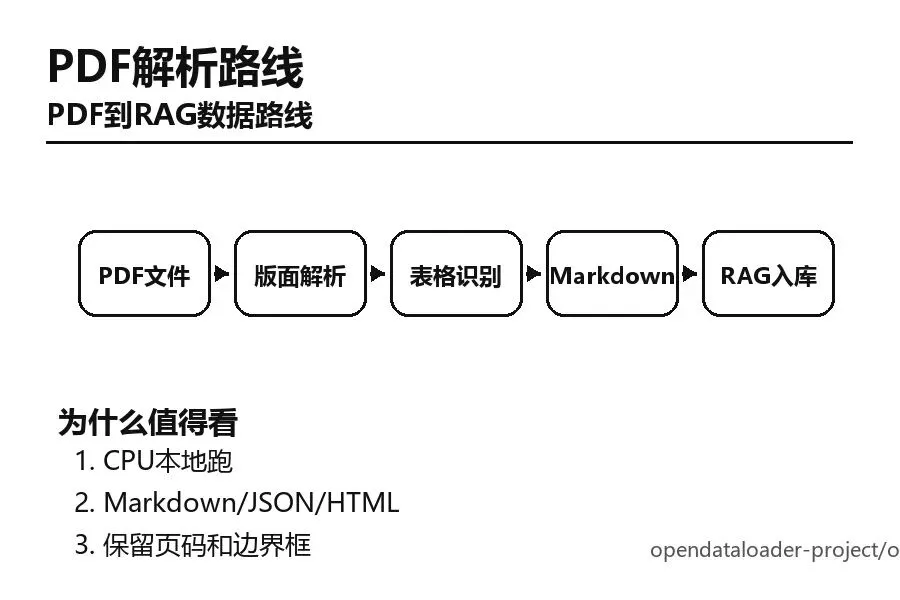
它的输出不只是纯文本。Markdown适合直接喂给RAG流程,JSON适合保留元素类型、页码和边界框,HTML适合预览。也就是说,你不仅知道模型回答了什么,还能追到它参考的PDF位置。
最小上手路径
如果你只是想试一下,不要先搭完整RAG系统。先拿一份PDF转Markdown,确认表格、标题、段落顺序有没有乱。能稳定转出结构,再接向量库和问答系统。
pip install opendataloader-pdf opendataloader-pdf input.pdf --format markdown --output output.md如果遇到扫描件、复杂表格或公式,可以再看官方的hybrid模式和OCR能力。新手第一天别追求全自动处理所有文档,先用一份简单PDF、一份多列表格PDF、一份扫描PDF做三组测试。
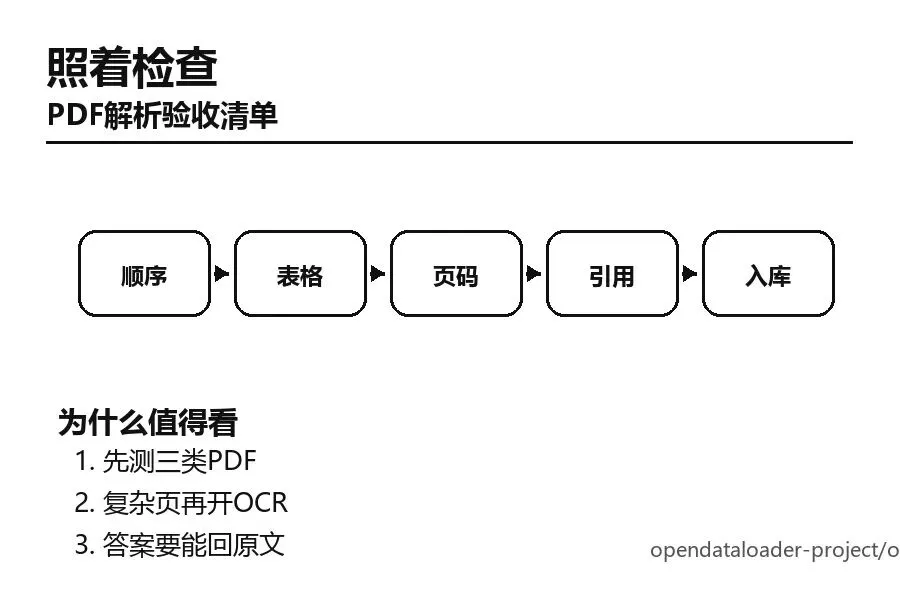
验收标准
第一,看Markdown阅读顺序是否正常。第二,看表格是否还能看出行列结构。第三,看每个元素是否能追到页码或位置。第四,用转出来的内容做一次RAG问答,看答案引用是不是能回到原文。
这个项目最适合资料多的人:合同、财报、论文、产品说明书、政策文件、培训手册。它不是替代大模型,而是把大模型吃进去的资料先洗干净。对于AI应用来说,这一步往往比换模型更值钱。
这东西怎么变成钱
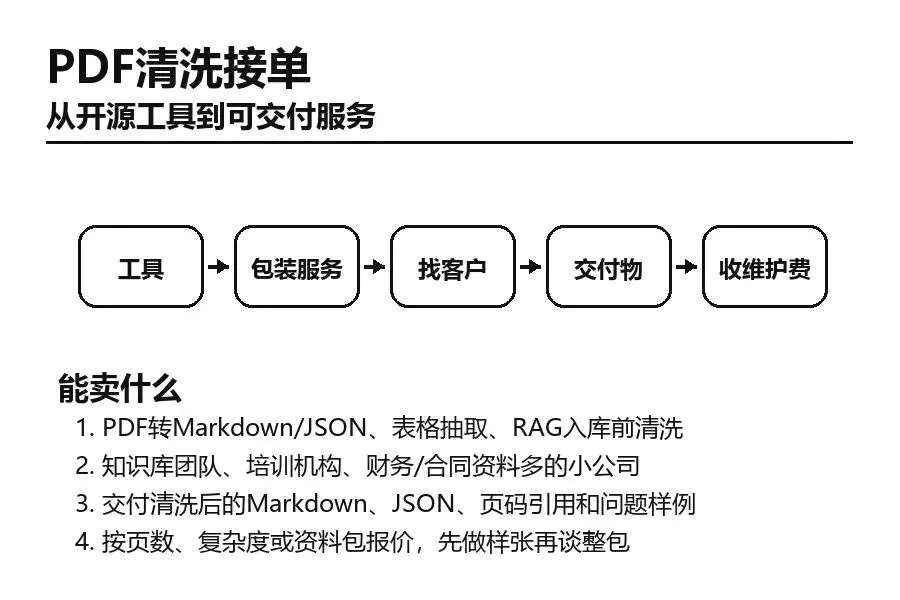
别把它只当成一个GitHub项目。更现实的玩法,是把它包装成一项小服务:PDF转Markdown/JSON、表格抽取、RAG入库前清洗。客户不一定关心底层技术叫什么,他们更关心资料能不能处理、流程能不能少人干、结果能不能交付。
适合找的客户是:知识库团队、培训机构、财务/合同资料多的小公司。这些客户通常不缺想法,缺的是有人帮他们把工具跑起来、把流程接好、把结果整理成能用的东西。
交付时不要只说“我帮你部署好了”。要交付得更具体:交付清洗后的Markdown、JSON、页码引用和问题样例。有文档、有样例、有验收口径,客户才知道钱花到哪里了。
报价上不要一开始就卖梦想,先按小包做:按页数、复杂度或资料包报价,先做样张再谈整包。先做一个能验收的小闭环,再谈长期维护,反而更容易成交。
别吹过头
这类AI开源工具能帮人省时间,但不能保证客户立刻赚钱。公众号里可以讲变现路径,但不要写成暴富承诺。真正有吸引力的说法,是告诉读者:这个项目能包装成什么服务,第一单怎么交付,哪里最容易翻车。

项目名:opendataloader-project/opendataloader-pdf
