 夜雨聆风
夜雨聆风
AI Agent & LLM
早上好,六月的技术圈继续热闹,来看看昨天有什么值得关注的动态。
重点动态
vLLM-2080Ti-Definitive: 双 2080Ti 跑 27B 模型
有人在双 RTX 2080 Ti 上把 27B/31B 模型跑到了 100+ tok/s,还支持 262K 上下文,老卡的生命力比想象中强。
2080Ti 单卡 11GB 显存,两张 NVLink 桥接后 22GB,常规思路只能跑 7B 级别。作者通过精细调校 vLLM 运行时,把显存利用压到极限,27B 模型单请求解码超过 100 tok/s。262K 原生上下文支持更是很多新卡配置都未必做到的长度。
对手上还有老卡的工程师来说,这份配置直接省了一笔硬件升级费。和下面那条 RTX 3060 跑 35B 的指南一起看,"老硬件跑大模型"已经形成了自己的小社区。
📎 相关链接
vLLM-2080Ti-Definitive
https://github.com/weicj/vLLM-2080Ti-Definitive
SoulX-Transcriber: 端到端多说话人语音转录
联合建模"谁说的、什么时候说的、说了什么"三个任务,用端到端方式替代传统的分步流水线。
多说话人转录的传统做法是 VAD 切段加说话人聚类再跑 ASR,每一步的误差往前传播,最终结果经常错得离谱。SoulX 把这三个任务塞进同一个模型里联合优化,从原理上减少了级联误差。
GitHub 上标注支持 ASR、说话人分离和说话人日记三个任务,Python 实现降低了上手门槛。做会议记录、访谈整理这类场景的团队值得关注。
📎 相关链接
SoulX-Transcriber
https://github.com/Soul-AILab/SoulX-Transcriber
episodiq: Agent 轨迹的结构化日志
Agent 跑完之后的日志到底怎么看?episodiq 给出了一个方案,生成人类可读的结构化日志,还能做轨迹检索。
生产环境里 Agent 的 debug 一直是老大难。原始日志太冗长,摘要又丢失关键细节。episodiq 同时解决了两个问题,日志写得既经济又完整,还能按结构快速检索到出问题的环节。项目强调"economical",说明作者有意识地在控制日志体积,不是一股脑全记下来。
📎 相关链接
episodiq
https://github.com/slavaZim/episodiq
edge-lm: 边缘设备专用的 Tiny LLM
TheStageAI 放出一套面向边缘部署的小模型,从模型层而非推理框架层切入,让 LLM 在 IoT 和移动端跑得更顺畅。
边缘 AI 的热度持续走高,但大部分工作集中在推理框架优化,模型本身的针对性设计反而少。edge-lm 从模型结构层面做了裁剪,目标是让小参数量模型在资源受限的设备上保持可用性。Python 实现,实验门槛不高,不过真正落地还得看具体硬件适配。

📎 相关链接
edge-lm
https://github.com/TheStageAI/edge-lm
data2prompt: 把数据科学项目塞进 LLM 上下文
你有个数据科学项目想让 LLM 帮忙看,但文件太多塞不进上下文窗口,这个 CLI 工具就是干这个的。
智能筛选代码、数据描述和配置文件,打包成 LLM 能消化的格式。能上 HN 首页说明这个需求击中了不少人的痛点,毕竟谁没试过把整个项目丢给 Claude 然后被告知"太长了"。
📎 相关链接
data2prompt
https://github.com/arianmokhtariha/data2prompt
aiforge: 一键同步多工具 AI 编程配置
Copilot、Claude Code、Cursor 各有各的配置文件格式,aiforge 用一条命令把它们统一起来。
TypeScript 实现,能把一个 Git 仓库里的 AI 编程配置同步到多个工具。同时用两三个 AI 编程工具的 developer 应该深有体会,维护分散的配置文件纯属浪费时间。
📎 相关链接
aiforge
https://github.com/flanliulf/aiforge
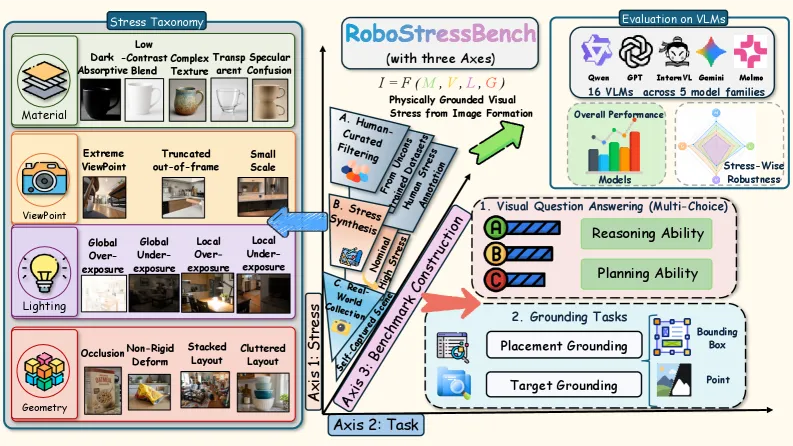
RoboStressBench: VLM 在真实物理场景的鲁棒性评测
现有 VLM 评测用干净图片,跟真实机器人部署环境差了十万八千里,这个基准专门模拟物理场景中的视觉压力。
光照变化、遮挡、材质反射,这些才是机器人部署时真正遇到的问题。论文来自 arXiv,对做具身 AI 的团队来说,比标准 benchmark 更有参考价值。
📎 相关链接
RoboStressBench
https://arxiv.org/abs/2606.00828
RTX 3060 跑 Qwen3.6-35B 指南
又一份老显卡压榨教程,这次的主角是 RTX 3060 和 35B 参数的 Qwen3.6。
跟上面 2080Ti 那条一起看,"用消费级老卡跑大模型"这个赛道比想象中活跃。这类指南最值钱的部分是具体的量化配置和踩坑记录,泛泛的推理框架介绍谁都能写。

📎 相关链接
rtx3060-qwen3.6-35b-guide
https://github.com/castlen3/rtx3060-qwen3.6-35b-guide
HN 热议: 别把求职帖当获客渠道
一位带着妻子和猫的移民求职者在 HN 发帖找工作,收到的是 AI 创业者的产品推销邮件,社区炸了。
发帖人说自己需要一份工作来付房租养家,结果等来的不是 offer 而是"我做的 LLM 工具可以帮你编排 Agent 工作流"。HN 社区几乎一边倒地认为这种行为既不尊重人也不体面。做 AI 产品的团队,获客要有底线。
📎 相关链接
Please don't spam people looking for employment
https://news.ycombinator.com/item?id=48370330
下午见。
