 夜雨聆风
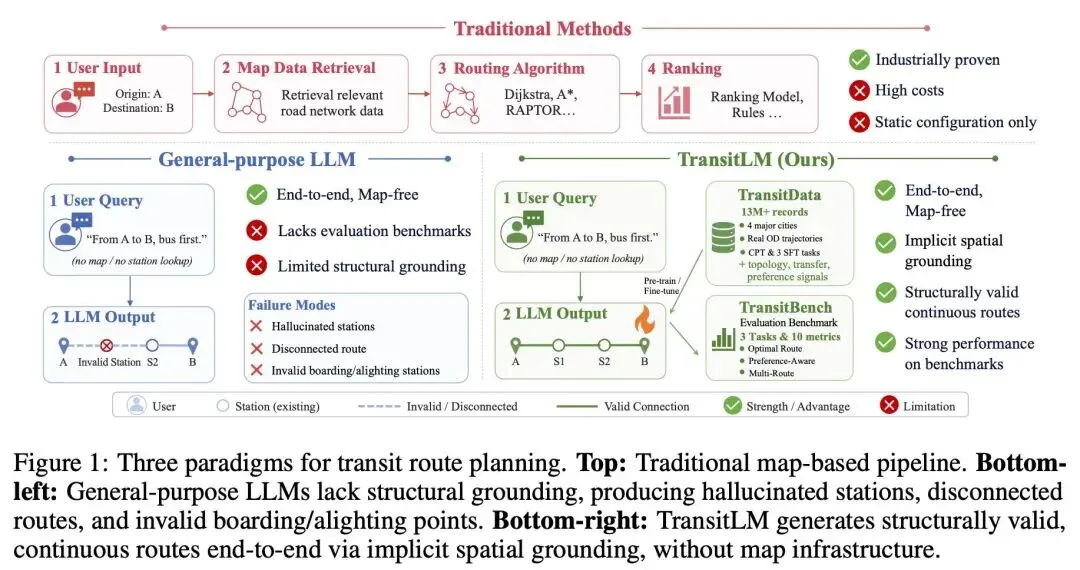
夜雨聆风传统公交规划要分三步:先查路网、再跑Dijkstra等算法、最后排序。高德把这套流水线全塞进一个模型里——你输入起点终点,它直接输出坐几路车、在哪换乘,中间步骤一步到位。更厉害的是,它只靠经纬度就能规划,从不编造不存在的站点。通用大模型做不到的事,一个0.6B的小模型做到了。
📄 导语
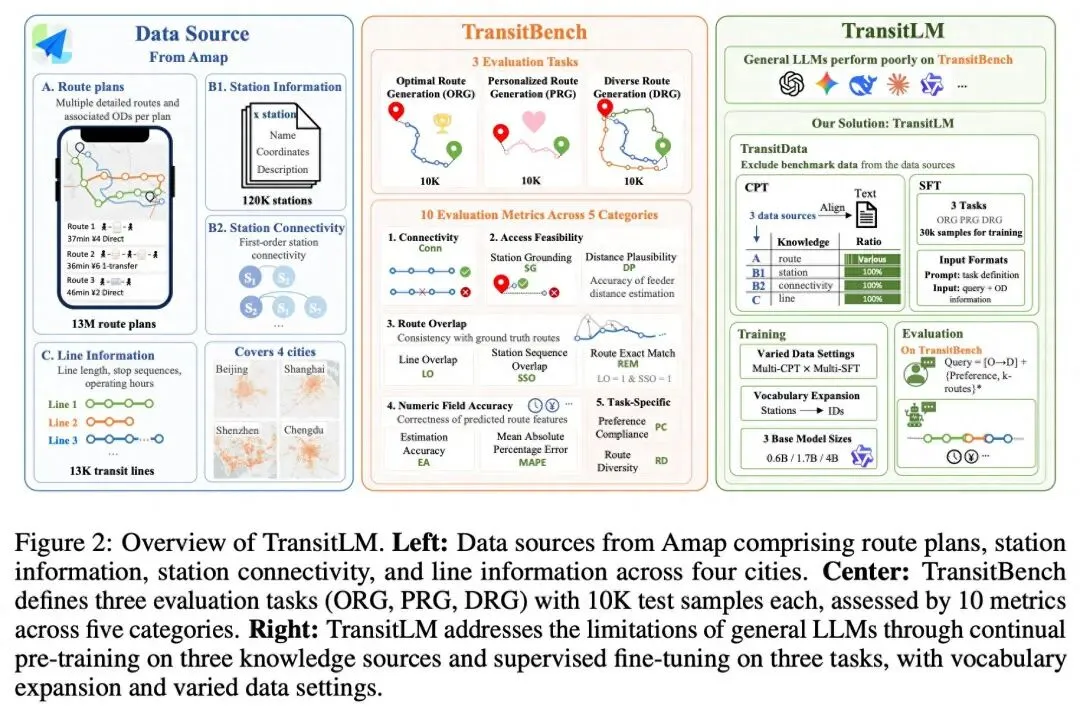
TransitLM 是高德地图研究团队提出的一项开创性工作,它直接挑战了一个长期存在的假设:公交路线规划必须依赖结构化地图和 Dijkstra 等路由算法。通过构建包含 1294 万次真实出行会话、超过 200 亿 token 的大规模数据集,并将 12 万个站点 ID 直接注册为词表 token,该研究首次证明:一个仅有 0.6B 参数的小型领域模型,在完全抛弃地图和外部引擎的情况下,其端到端路线规划能力全面超越 GPT-4、Gemini 等通用大模型。更令人惊叹的是,模型仅凭经纬度坐标就能实现 隐式空间定位——空间拓扑被压缩进了参数中,即便删掉所有地名文本,性能几乎不降。这项工作不仅为公交导航提供了新的技术路径,更对“领域数据 vs 模型参数量”的争论给出了有力回答。以下是基于论文原文的完整解读。
📎 资源链接
📄 论文页面 (arXiv): https://arxiv.org/abs/2605.22355
📑 论文PDF: https://arxiv.org/pdf/2605.22355
🤗 数据集地址: GD-ML/TransitLM
🐱 代码仓库: github.com/HotTricker/TransitLM
🚀 📌 核心亮点
问题挑衅性:传统公交路线规划依赖结构化地图、路网检索和 Dijkstra/RAPTOR 路由引擎。高德这项研究直接问:这套能否全扔掉,让语言模型从历史导航日志里把路线“背”出来?答案是能。
🔑 核心数据 TransitLM:从高德一天的导航日志中抽取 1294 万次真实路线规划会话,覆盖北京、上海、深圳、成都四城,12 万个站点、1.3 万条公交地铁线路,总量超过 200 亿 token。
⚙️ 关键工程决策:把全部 120,845 个站点 ID 注册成词表中的独立 token,一个站点就是一个 token。这直接掐死了模型用字符拼接编出不存在站点的可能。
🧠 最有意思的发现:隐式空间定位。只给经纬度坐标、删掉所有地名文字,通用大模型的站点定位准确率从 72% 崩到 16%,而 TransitLM 几乎不掉点(Route Exact Match 从 71.0% 只降到 70.4%)。模型真的把路网的空间拓扑学进了参数里。
📉 反直觉对比:Gemini-3.1-Pro 在被放水的简化任务下 Route Exact Match 只有 40.2%,而 0.6B 的领域模型在更难的完整站点序列任务上就全面超过了所有六个通用大模型。瓶颈是数据,不是参数量。
一、❓ 问题背景:公交路线规划难在哪?
传统地图 App 查公交的流水线:
用起终点检索周边路网数据
在拓扑图上跑 Dijkstra、A*、RAPTOR 等多准则最短路算法
用排序模型/规则将候选路线排序推给用户
两个绕不开的代价:
依赖结构化地图基础设施
依赖实时调度数据
能不能换个思路? 公交平台每天生成海量路线规划日志,其中隐含了路网知识(上车点、换乘、用户偏好)。路线规划能否直接从这些数据中学出来,跳过地图和路由引擎?
🤖 通用大模型为什么不行?
能背出高频站点和热门线路,但遇到冷门起终点就开始编造不存在的站点、给出断开的路线
根因:现有数据源各管一段,没有完整的“路线结构 + 行为标注”数据集
车辆轨迹数据(T-Drive 等):有 GPS,无站点结构、换乘逻辑
静态网络数据(GTFS、OSM):有拓扑,无用户行为、真实出行轨迹
TransitLM 就是来补这个洞的。
二、📊 数据集:1294 万次真实会话怎么变成训练语料
2.1 数据来源与规模
来自高德导航平台的公交路线规划日志
四个城市:北京、上海、深圳、成都
120,845 个站点,13,666 条公交和地铁线路
从单日导航日志抽出 超过 1290 万次规划会话
所有候选路线由生产路由引擎生成,天然满足连通性和可行性(训练信号高质量)
2.2 两套互补的数据资源
1) 继续预训练(CPT)语料:1390 万条
1294 万条路线规划会话 + 100 万条站点/线路静态描述
每条会话编码为自然语言:查询头(城市、起终点坐标、POI) + 若干候选路线 + 细节
用户实际选中的路线被放在候选列表第一位 → 模型隐式学习用户偏好
静态记录:线路长度、站序、运营时间、连通关系
2) Benchmark SFT 数据
针对三个评测任务各构造 3 万训练 + 1 万测试
来自与 CPT 不重叠的时间段,避免数据泄漏
2.3 📈 数据统计亮点
平均每次会话有 6.32 条候选路线
路线模态均衡:纯公交 33.0%,纯地铁 19.0%,公交+地铁 16.8%,混合(含打车/骑行首尾接驳)30.5%
距离分布广:<5km 短途 22.8%,5–20km 中途 47.4%,>20km 长途 29.7%
CPT 记录平均 2377 个汉字,整个语料 超过 200 亿 token
| 城市 | 会话数 | 站点数 | 线路数 | 路线/会话 | 站数 | 换乘 | 票价(元) |
|---|---|---|---|---|---|---|---|
| 北京 | 4,802,588 | 38,792 | 4,234 | 6.14 | 14.29 | 1.57 | 8.36 |
| 上海 | 3,144,747 | 35,617 | 3,702 | 6.54 | 13.42 | 1.51 | 8.38 |
| 深圳 | 2,877,449 | 14,980 | 2,307 | 6.41 | 12.45 | 1.23 | 7.17 |
| 成都 | 2,120,480 | 31,456 | 3,423 | 6.28 | 13.82 | 1.49 | 6.99 |
三、🔧 最关键的一招:把站点 ID 全做成 token
骨干模型:Qwen3-0.6B / 1.7B / 4B Base
词表扩展:将全部 120,845 个站点 ID 注册为专属 token,一个站点就是一个 token
效果:堵死了字符级拼接造假(无法编出 "bus-899932" 这种不存在站点)
深层意义:模型直接在 token 层面学习站点间的空间和拓扑关系,这是“隐式空间定位”能涌现的前提
⚠️ 代价:词表随地理扩张线性增长。覆盖全中国需约 180 万个站点 token(现十倍多),显存和算力吃不消。
训练配置
CPT 阶段:序列打包到 4096,cosine 学习率,15000 步
SFT 阶段:每个任务微调一个 epoch,loss 只算在 response token 上
额外训练 Joint 模型:用三个任务合并的 SFT 数据一起微调 4B 的 CPT checkpoint
硬件:阿里云 PPU,4B 的 CPT 在 64 张卡上跑约 6 天
四、🎯 三个评测任务(TransitBench)与指标体系
每个任务 1 万条测试样本。
任务一:最优路线生成(ORG)
输入:起终点信息 + 自然语言查询
输出:单条最优路线的结构化 JSON(线路序列、带换乘标记的站点 ID 序列、距离、时间、票价、首尾接驳方式及距离)
标签:排名第一且被用户选中的路线(路由引擎认可 + 真实偏好)
任务二:偏好感知规划(PRG)
输入格式同 ORG,但查询中显式写偏好
四类偏好:地铁优先、公交优先、少换乘、最短时间
模型需解析偏好并在满足约束下给最优解
任务三:多路线生成(DRG)
同一 OD 输入,一次性生成三条不同路线(JSON 数组,每条带路线类型标签)
三条 ground-truth 按优先级组装:用户点击的优先 → 多样化路线(标签不同或线路不重叠)→ 专家打分兜底
📏 评测指标(四个互补维度 + 任务特定)
| 维度 | 指标 | 说明 |
|---|---|---|
| 连通性 | Conn | 预测序列中每对相邻站点是否真正可达(同线或有效换乘),其余指标仅在此条件下计算 |
| 接驳可行性 | SG (站点接地) | 上下车站点是否在起终点的模式特定距离阈值内(步行3km/骑行5km/打车10km) |
| DP (距离合理性) | 预测接驳距离是否物理合理 | |
| 路线重叠 | LO (线路重叠) | IoU 衡量线路匹配 |
| SSO (站点序列重叠) | 站点序列的 IoU | |
| REM (Route Exact Match) | LO=1 且 SSO=1 的样本占比 | |
| 数值准确率 | EA (估计准确率) | 距离/时间/票价在双容差内通过 |
| MAPE | 平均绝对百分比误差(仅在 REM 样本上计算) | |
| 任务特定 | PC (偏好符合度) | PRG 任务 |
| RD (路线多样性) | DRG 任务,需与质量指标一起看 |
五、📉 实验结果:数据比参数更重要
5.1 通用大模型到底有多惨?(放水设置)
为了公平,通用模型只需预测每段的上下车站点(不用生成完整中间站点序列)。即便如此:
| 指标 | GPT-5.4 | DeepSeek-V4 | Gemini-3.1 | Claude-4.6 | Qwen-3.6 | Doubao |
|---|---|---|---|---|---|---|
| 连通性 | 60.5% | 64.9% | 75.5% | 48.1% | 45.0% | 61.6% |
| 站点接地 | 60.5% | 72.0% | 93.9% | 50.7% | 64.2% | 83.9% |
| 距离合理性 | 40.7% | 49.9% | 67.0% | 27.9% | 42.9% | 59.4% |
| 线路重叠 | 0.407 | 0.447 | 0.600 | 0.396 | 0.475 | 0.584 |
| 站点序列重叠 | 0.361 | 0.425 | 0.569 | 0.314 | 0.386 | 0.517 |
| Route Exact Match | 18.4% | 23.7% | 40.2% | 15.4% | 19.8% | 33.6% |
结论:瓶颈是领域知识,不是模型容量。通用大模型没有公交路网的拓扑知识。
5.2 🏆 主结果:领域模型全面碾压(更难的完整站点序列任务)
| 指标 | 0.6B | 1.7B | 4B-25% | 4B | Joint |
|---|---|---|---|---|---|
| 连通性 | 93.5% | 95.0% | 95.9% | 97.0% | 97.9% |
| 站点接地 | 96.3% | 96.6% | 97.7% | 98.5% | 98.9% |
| 距离合理性 | 84.9% | 85.0% | 87.4% | 91.0% | 92.9% |
| 线路重叠 | 0.812 | 0.827 | 0.811 | 0.828 | 0.835 |
| 站点序列重叠 | 0.805 | 0.818 | 0.816 | 0.838 | 0.847 |
| Route Exact Match | 62.1% | 64.1% | 65.6% | 71.0% | 73.7% |
| 估计准确率 | 97.2% | 98.4% | 97.8% | 98.5% | 98.6% |
| MAPE | 2.03% | 1.60% | 1.88% | 1.33% | 1.30% |
最扎心对比:连最小的 0.6B 模型,在更难的设置下都全面超过上面六个被放水的通用大模型。参数量决定论被按在地上。
性能随模型容量单调上升:4B 比 0.6B 在 ORG 上多 8.9 个百分点的 REM。
Joint 模型真实输出示例(如“怎么去故宫”):生成地铁 15 号线换 8 号线的路线,21.4km、1h17min、5 元,步行接驳合理,全部自回归生成,无外部地图匹配。
5.3 📈 数据 scaling:先学语法,再学细节
将 CPT 会话数据砍到 6.25%、12.5%、25%、50%(静态描述和 SFT 不变):
| 指标 | 4B-6.25% | 4B-12.5% | 4B-25% | 4B-50% | 4B-100% |
|---|---|---|---|---|---|
| 连通性 | 94.0% | 95.4% | 95.9% | 96.8% | 97.0% |
| 站点接地 | 93.5% | 96.4% | 97.7% | 97.9% | 98.5% |
| REM | 49.9% | 61.2% | 65.6% | 68.9% | 71.0% |
| MAPE | 3.26% | 2.27% | 1.88% | 1.51% | 1.33% |
学习层级:
连通性在最小数据量下就到 94% → 路网“语法”学得很快
REM 和 MAPE 需要密集数据 → 精确匹配和数值校准要更多数据
模型先学结构语法,再掌握细粒度偏好和距离估计
六、🧠 全文最值钱的发现:隐式空间定位是真的(GPS-only 消融)
把所有自然语言查询删掉,只留起终点的 GPS 经纬度。通用大模型原形毕露:
| 指标 | GPT-5.4 | DeepSeek-V4 | Gemini-3.1 | Claude-4.6 | Qwen-3.6 | Doubao |
|---|---|---|---|---|---|---|
| 连通性 | 78.9% | 80.3% | 81.3% | 64.9% | 65.5% | 73.7% |
| 站点接地 | 14.4% | 16.8% | 79.9% | 15.3% | 11.3% | 24.1% |
| REM | 0.6% | 0.6% | 17.7% | 0.6% | 0.2% | 0.5% |
DeepSeek-V4 站点接地从 72.0% 暴跌到 16.8%
反常:连通性反而升了(如 DeepSeek 64.9% → 80.3%)→ 因为没有地名线索,模型退化成背诵高频站点,把记住的几个大站连起来,但跟你要去的地方毫无关系
结论:通用大模型的“路线规划”靠的是起终点地名的文本语义,不是对坐标的空间理解
再看领域模型,几乎不掉点:
| 指标 | 0.6B | 4B | Joint |
|---|---|---|---|
| 连通性 | 93.5% | 97.2% | 98.0% |
| 站点接地 | 95.9% | 98.3% | 98.8% |
| REM | 61.0% | 70.4% | 72.9% |
4B 模型在 GPS-only 下 REM 70.4%(带文本 71.0%),Joint 模型 72.9%(vs 73.7%)
模型只看一对经纬度,就能把任意坐标解析到合适的上下车站点,无显式坐标→站点查表,无地理数据库。空间拓扑被压进了参数里。
意义:next-token prediction 在密集的“坐标—站点—路线”配对数据上,能逼出内化的空间表征。
七、🔬 CPT 到底贡献了什么?CPT vs SFT-only 对照
控制实验:SFT-only 直接用 base 模型在同等体量会话数据上做监督微调,跳过 CPT。
标准文本输入下:SFT-only 的 REM 居然最高(74.9% vs CPT-100% 的 71.0%)。单看这个会以为 CPT 没用。
但切到 GPS-only:排名整个翻转。
| 从文本到 GPS-only 的退化 | SFT-only | CPT-25% | CPT-100% | Joint |
|---|---|---|---|---|
| REM 变化 | −8.8 | −0.5 | −0.6 | −0.8 |
| 估计准确率变化 | −21.8 | −1.0 | −0.9 | −0.5 |
| MAPE 变化 | +3.61 | +0.36 | +0.42 | +0.22 |
本质区别:
SFT-only:把空间知识和任务输入格式、文本线索缠在一起 → 有地名时表现好(用文本作弊),线索一抽走就垮
CPT:在任务监督之前先逼模型从原始路网数据中建立空间表征 → 独立于 prompt 模板,任务无关、可迁移
工程启示:如果需要一个对各种 prompt 格式鲁棒、对输入扰动稳定的领域模型,不能指望 SFT 一步到位。CPT 给底座表征,SFT 给任务接口,角色不能互换。
八、🤝 一个模型干三件事,没有负迁移
Joint 模型:用三个任务合并的 SFT 数据训练
在所有 benchmark 的每个指标上追平或超过单任务 4B
提升最明显的是 PRG:连通性 +2.1 点,REM +2.2 点
没有任何负迁移 → 三个任务共享同一套底层路网拓扑表征,互补的规划目标互相加强
偏好感知示例(同一 OD 对,加“公交优先”约束):模型将整条路线从地铁切到公交(405 路换 1 路快车),完全避开地铁段。说明它学的是条件化选路,不是无脑给最短路。
⚖️ 与工具增强 LLM 的对比
让通用模型调高德路由 API 取候选再选 → 工具增强后 REM 可达到约 74.0%
但这把任务从“生成”降级为“选择”,且不再是 map-free(依赖外部引擎、实时调度、路况)
TransitLM 不碰任何外部工具,Joint 模型的 LO 0.835 / SSO 0.847 与最好的工具增强模型(0.848/0.834)几乎持平,还是在更难的完整站点序列任务上
等于说 CPT 把一个生产级路由引擎的知识“蒸”进了参数
九、🧐 我的判断:这条路通向哪,又卡在哪
✅ 价值与意义
回答了一个普遍问题:需要严格结构有效性的工程系统,能否用“领域数据 + 继续预训练 + 词表扩展”换成纯生成模型?
TransitLM 给的答案是肯定的,证据链完整(主结果、数据 scaling、GPS-only 消融、CPT vs SFT 对照、联合训练)
没有停在“刷榜”,而是用 GPS-only 拷问“模型到底学到了什么”,落到隐式空间定位这个有意思的现象上
⛔ 硬天花板
词表线性膨胀:120 万 → 全中国约 180 万个站点 token,不是调参能绕过去的。需要词表压缩或层级编码,目前未做。
静态快照:实时拥堵、临时调线、停运、新开站反映不了,唯一更新方式是重训。对需要实时性的场景是妥协。检索增强(推理时注入实时状态)列为未来方向,但未落地。
🔍 数据层面的留心眼
单一平台、单日采样、四个中文城市、全中文文本
路由排序策略可能是高德特有的,是否能迁移到其他拓扑和换乘惯例上?
评测只对着路由引擎输出做结构比较,没有真实出行验证
🏁 总结
作为一个范式验证,它足够干净,也足够有说服力。从一千多万条真实日志里,确实长出了一个 “看不见地图也能换乘” 的模型
期待您的关注,欢迎留言讨论!
#高德地图 #AI黑科技 #大模型 #公交出行 #路径规划 #颠覆性技术 #人工智能 #GPT4 #Gemini #出行必备
