 夜雨聆风
夜雨聆风你打开 Midjourney,对着空白输入框发呆:这张图,我脑子里有画面,但我不知道该怎么形容它。这种感觉几乎每个用过 AI 画图工具的人都经历过。你写了一大段提示词,生成出来的图差强人意;你修改措辞,再生成,还是不对。兜兜转转,花了半小时,图还没出来。问题出在哪里?
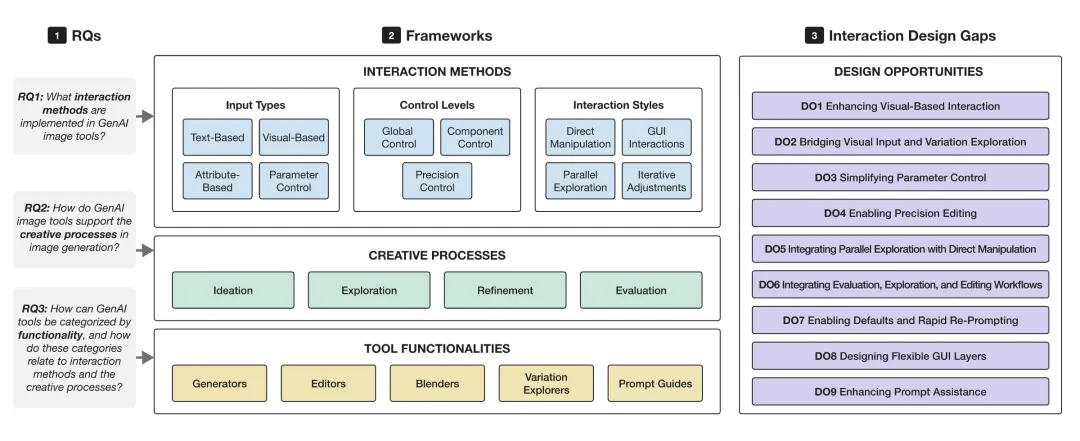
在一篇最新的论文综述中,研究团队系统回顾了 37 款 AI 图像生成工具(28 个学术原型和 9 个商业产品),试图回答一个核心问题:这些工具到底是怎么设计的?它们真的支持创作者的完整工作流程吗?
论文链接:
https://dl.acm.org/doi/full/10.1145/3772318.3790307

Method|拆开 37 款工具,看它们的骨架


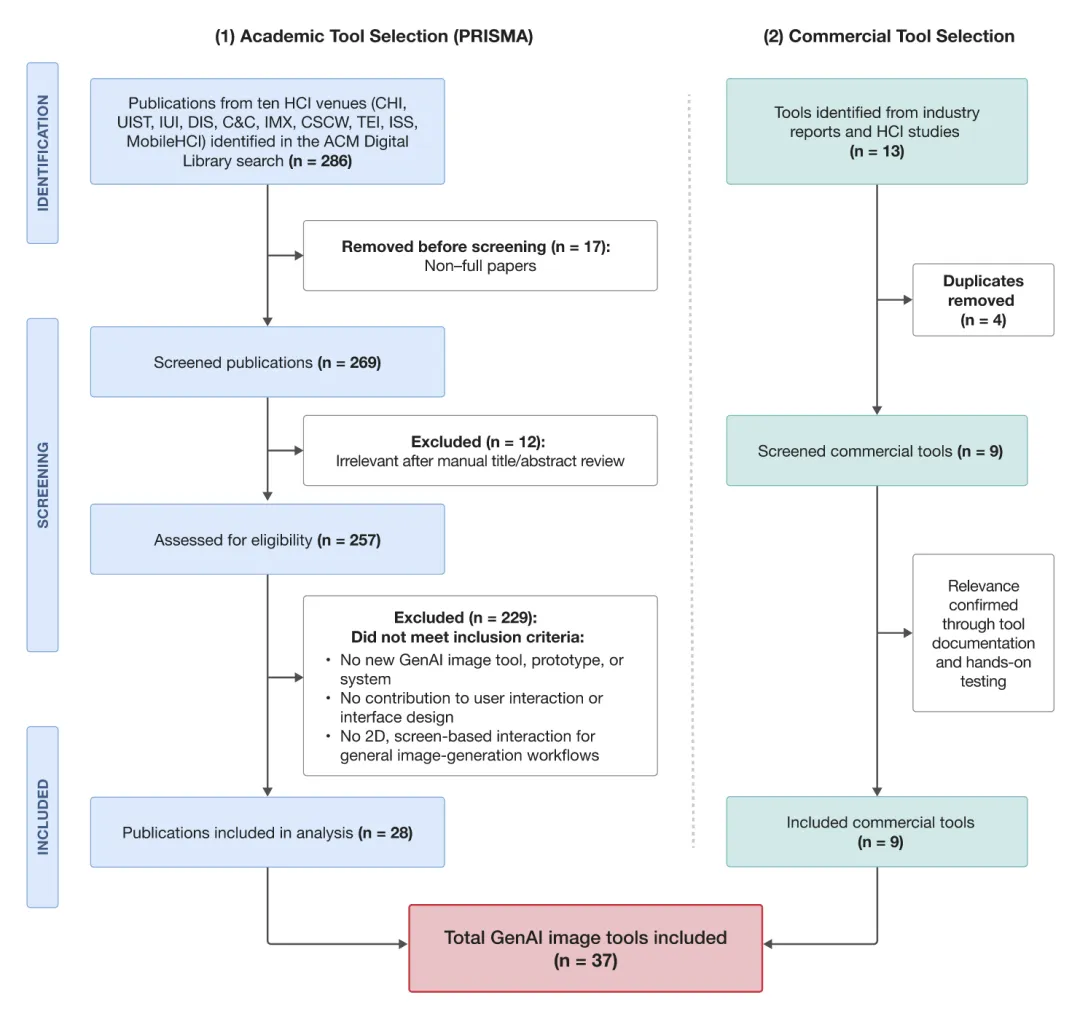
研究团队使用 PRISMA 系统综述框架,从 CHI、UIST、IUI 等十大 HCI 会议中筛选出 28 篇学术论文,并补充了 Midjourney、DALL·E 3、Adobe Firefly 等 9 款主流商业工具。时间范围定在 2022 年至 2025 年 7 月,正好覆盖了文生图技术从"能用"到"好用"的关键演变期。他们建立了三个分析框架,对每款工具进行逐项评分(0-3 分):
- 交互方法:输入类型(文字/视觉/属性/参数)、控制粒度(全局/局部/精细)、交互风格(直接操作/GUI 控件/并行探索/迭代调整)
- 创作流程:构思、探索、精修、评估
- 工具功能:生成器、编辑器、混合器、变体探索器、提示词引导
最终,两名标注者的评分一致性达到 κ = 0.847(接近完全一致),为结果的可靠性提供了保障。


文字提示词至今仍是主流输入方式,而视觉输入和属性控制正在学术系统中逐步兴起——尤其是在需要精细调整的场景下。
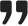

Findings|有好用的,也有缺失的


发现一:文字输入一统天下,但视觉思维者被冷落
37 款工具中,有 28 款对文字输入提供"强支持",但对视觉输入提供强支持的只有 13 款。视觉输入在统计上与"精修"阶段强相关,与"构思"阶段几乎没有关联——这意味着大部分工具只允许你在最后阶段"贴个参考图",而不支持从一开始就用视觉方式表达想法。
发现二:学术工具和商业工具,在走两条路
商业工具(如 Midjourney、DreamStudio)更倾向于暴露参数控制——种子值、采样步数、去噪强度;学术工具则更关注语义属性——风格、色调、构图,让用户用"设计语言"而非"机器语言"表达意图。两种路径各有优劣,但都没有很好地融合。
发现三:构思和探索很强,精修和评估很弱
31/37 款工具对"构思"提供强支持,28/37 款对"探索"提供强支持——也就是说,帮你"想出来"很容易。但到了"精修"阶段,只有 7 款工具有强支持;"评估"阶段更惨,仅有 3 款工具真正帮你比较、判断、选择。
换句话说:AI 画图工具擅长帮你起草,却几乎不帮你收尾。
发现四:直接操控几乎是稀缺品
能让你直接拖动、调整、操作图像元素的工具,在 37 款中只有 1 款(Brickify)达到"强支持"。大多数工具的"直接操作"仅限于用画笔框一个区域、填入文字描述——仍然绕不开文字。

Limitation|清单的边界


研究的覆盖范围限定在 2D 屏幕界面,3D/AR/VR 等空间交互工具被排除在外。商业工具的筛选基于市场份额,可能遗漏一些新兴但小众的产品。此外,评分依赖研究者的主观判断,尽管已有双人校验机制,部分边界案例的分类仍存在争议(比如"属性控制"与"参数控制"的区分)。
学术原型的数量(28 款)相对于整个领域而言也偏少,结论的代表性有待更大规模验证。

Future Work|下一代 AI 画图工具长什么样?


研究团队提出了 9 个设计机会,核心方向集中在三点:让视觉输入贯穿整个创作流程(而不只在精修阶段才出现);让参数控制更直观,普通用户也能调;以及在工具内部打通构思、精修、评估的完整工作流。
这里有一个值得思考的开放问题:
既然专业设计师自称"视觉型思考者,不是语言型思考者",那未来的 AI 创作工具,是应该继续优化提示词体验,还是彻底重新设计一套以视觉为中心的交互范式?答案或许不是非此即彼——但现在的工具,还远远没有给出令人满意的回答。
原论文:Park, H., Eiband, M., Luckow, A., & Sedlmair, M. (2026). Interaction Methods in Generative AI Image Tools: A Review of Trends and Design Opportunities Across HCI and Industry. CHI '26, Barcelona, Spain.

