 夜雨聆风
夜雨聆风📄 上传一份几十页的 PDF,它能自动识别标题结构,3 分钟生成带书签目录的版本。支持扫描版 PDF(OCR)、Word 文档,还能插队优先处理、批量操作、实时看进度……
一、这个项目解决什么问题?
工作中经常遇到这样的场景:
下载了一份 200 页的 PDF 技术手册,没有目录,找内容翻到手酸
扫描版的 PDF(图片形式)连文字都选不中,更别指望有书签了
Word 转 PDF 后,原来的标题结构全丢了,变成一个"平面"文档
要给几十份文档批量加书签,手动操作太耗时
PDF 书签生成器就是为了解决这些痛点而生。你只需上传文件,剩下的交给它:
✅ 自动提取标题结构,生成多级书签
✅ 扫描版 PDF 用 OCR 识别文字后再提取标题
✅ Word 文档提取 Heading 样式,映射到对应页码
✅ 支持批量处理、插队优先、实时进度追踪
二、技术架构一览
项目采用前后端分离架构,整体轻量但功能完整:
┌─────────────┐ ┌─────────────┐ ┌─────────────┐
│ Vue 3 │◄────►│ FastAPI │◄────►│ SQLite │
│ Element Plus│ │ Huey队列 │ │ (数据+队列) │
│ Vite │ │ PaddleOCR │ │ │
└─────────────┘ └─────────────┘ └─────────────┘| 前端 | ||
| 后端 | ||
| 数据库 | ||
| 任务队列 | ||
| PDF 处理 | ||
| OCR 识别 | ||
| Word 解析 |
三、核心功能详解
1. 智能标题提取(5 层策略)
不只是简单按字体大小判断,系统用了 5 种策略 组合拳识别标题:
| 模式匹配 | ||
| 绝对字号 | ||
| 相对字号 | ||
| 字体名检测 | ||
| 短粗行 |
2. 扫描版 PDF 也能识别
遇到扫描版(图片型)PDF?开启 OCR 模式:
用 PaddleOCR 逐页识别文字
识别出的文字送回标题提取流程 自动生成书签后写入原 PDF
⚠️ OCR 模式较慢(CPU 下约 25-30 秒/页),适合偶尔使用,或搭配 GPU 加速。
3. 任务队列 + 插队机制
上传文件后自动生成书签,但如果队列里有多个任务怎么办?
普通排队:默认优先级,按顺序处理
插队优先: urgent 任务可设置
priority=0,直接跳到队首批量操作:同时选中多个文件,一键批量生成
实时进度:每 2 秒更新进度条 + 当前阶段文字
4. 终端式实时日志
点击任务"详情",打开侧边抽屉,能看到终端风格的实时日志:
14:32:01 开始解析 PDF 结构
14:32:03 提取到 23 个标题候选
14:32:04 正在生成书签...
14:32:05 书签写入完成,输出文件: api_bookmarked.pdf处理过程一目了然,出问题也能快速定位。
5. 孤儿任务自动清理
服务重启时,如果刚好有任务在运行,这些任务会被标记为"处理中"但永远不会完成。
系统启动时自动扫描:
发现"僵尸任务"(处理中但超过 5 分钟没更新) 自动标记为"失败"并记录原因 避免用户看到"卡死"的任务
6. 书签预览 + PDF 在线预览
生成完成后:
书签树预览:弹窗查看层级结构,带页码,确认没问题再下载
在线预览:直接在浏览器里打开 PDF,不用下载到本地
下载:一键下载带书签的 PDF,文件名自动加
_bookmarked后缀
四、界面截图(文字描述版)
首页 简洁的欢迎页,两个大按钮:"上传文档"和"查看文件",下方三个特性卡片介绍核心能力。
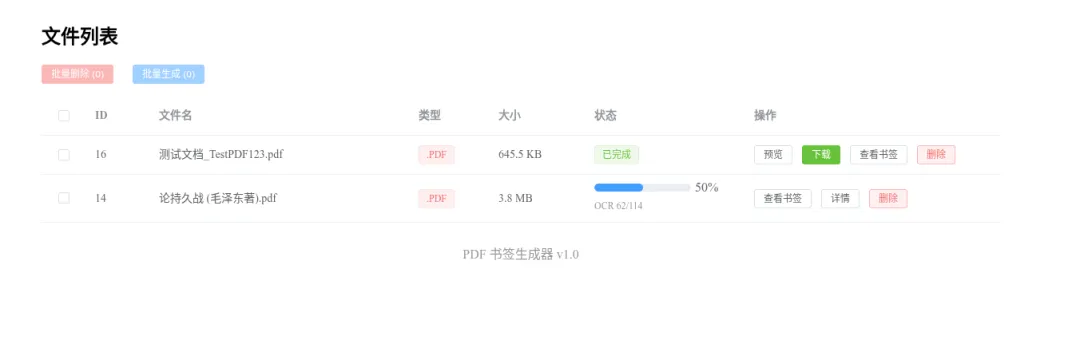
文件列表页
表格展示所有文件:ID、文件名、类型、大小、状态 每行前面有复选框,支持批量删除/批量生成 处理中的任务显示实时进度条,点击可展开详情抽屉 操作列根据状态动态显示按钮:生成书签 / 插队 / 预览 / 下载 / 查看书签 / 删除
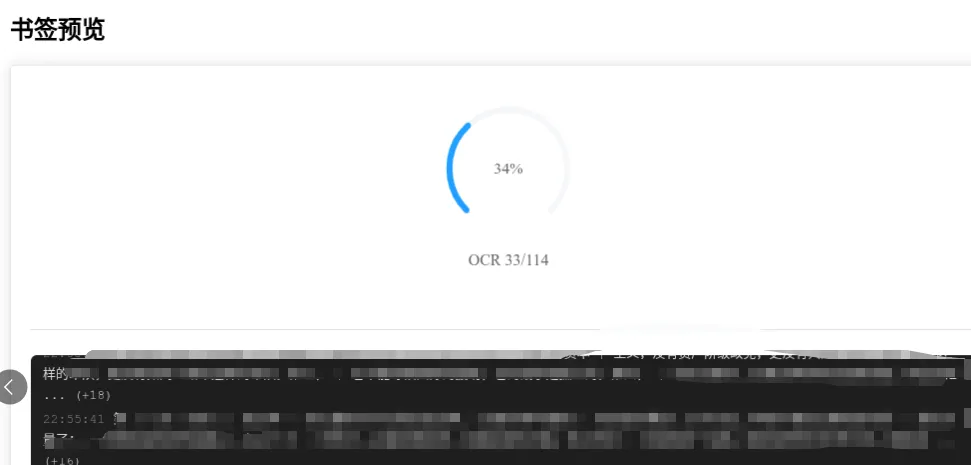
处理详情抽屉
顶部圆形进度仪表盘 下方黑色背景的终端日志区,实时滚动
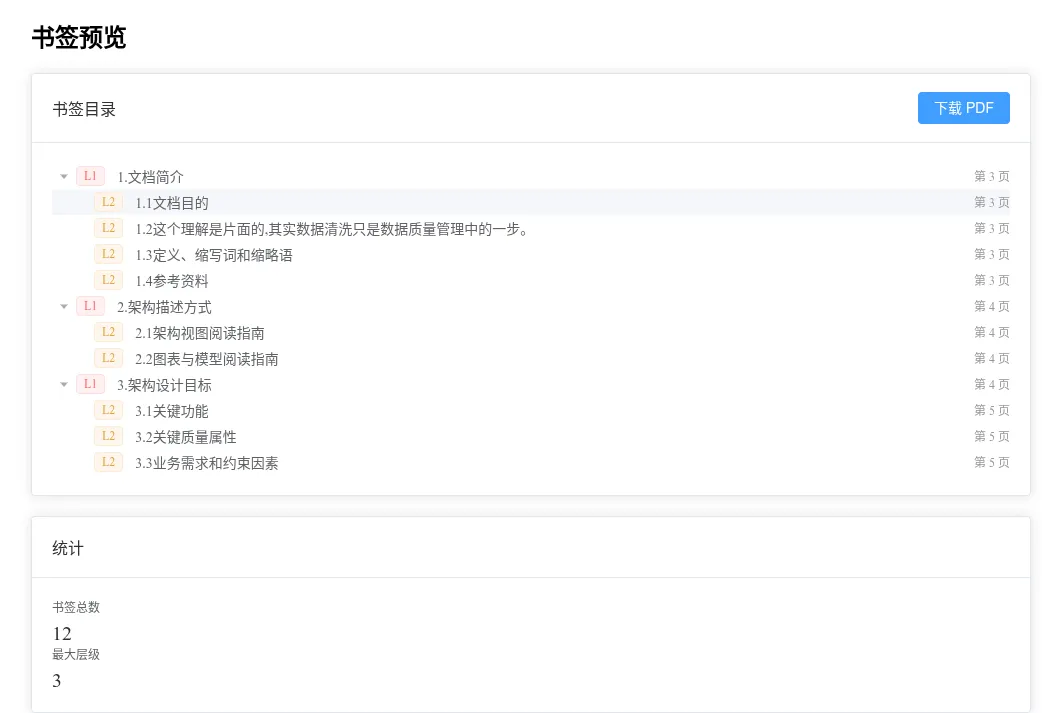
书签预览页
左侧树形结构展示多级书签(L1-L4 不同颜色标签) 右侧统计卡片:书签总数、最大层级深度 底部下载按钮
五、快速开始
方式一:开发模式(前后端分离)
# 1. 克隆项目
git clone https://gitee.com/michah/pdf-bookmark-generator
cd pdf-bookmark-generator
# 2. 启动后端(自动检查依赖、虚拟环境)
python start.py
# 3. 另开一个终端,启动前端
cd frontend
npm install
npm run dev
# 4. 浏览器访问 http://localhost:3000方式二:生产模式(前后端一体)
# 一键启动(自动构建前端 + 启动后端)
python start.py
# 浏览器访问 http://localhost:8000方式三:Docker(可选)
项目结构清晰,很容易打包成 Docker 镜像,适合部署到服务器。
六、项目亮点总结
threading.Lock,多页 OCR 不丢日志 | |
七、适合谁用?
📚 学生/研究者:论文、电子书、手册加目录
💼 职场人:合同、标书、技术文档整理
🏢 企业:批量处理内部文档,统一书签规范
💻 开发者:学习 FastAPI + Vue3 + 任务队列的完整项目案例
八、源码地址
⭐ 觉得有用的话,欢迎 Star 支持!
Gitee: https://gitee.com/michah/pdf-bookmark-generator技术栈标签:#Python#FastAPI#Vue3#ElementPlus#PDF处理#OCR#PaddleOCR#任务队列
感谢阅读!如果这个项目帮到了你,欢迎转发给有需要的朋友 👋
