 夜雨聆风
夜雨聆风如果一家公司今年给团队加一条 AI 目标:代码里有多少由 AI 生成,或者每个月 AI 工具用量要跑到多少,听起来很像在推动效率升级。
但这个目标也很容易把人带偏。
一个人为了完成 AI 产出比例,可以让 AI 写出更多代码;为了证明自己“高强度使用 AI”,也可以让它去跑一些很复杂、很耗 token、但对真实业务没什么意义的任务。表面上,AI 使用量上去了,代码产出也多了。可项目是不是真的变好了,客户是不是更容易用了,系统是不是更稳定了,反而不一定有人说得清。
所以 Uber 给 AI 工具设 1500 美元上限这件事,最值得看的不只是“AI 花钱了”。
更重要的是,AI 从聊天工具变成执行工具以后,公司不能再只看“用了多少 AI”,而要重新问一遍:哪些任务适合 AI 做,哪些地方必须人来协调,什么时候该让 AI 停下,最后按什么标准验收。
1500 美元
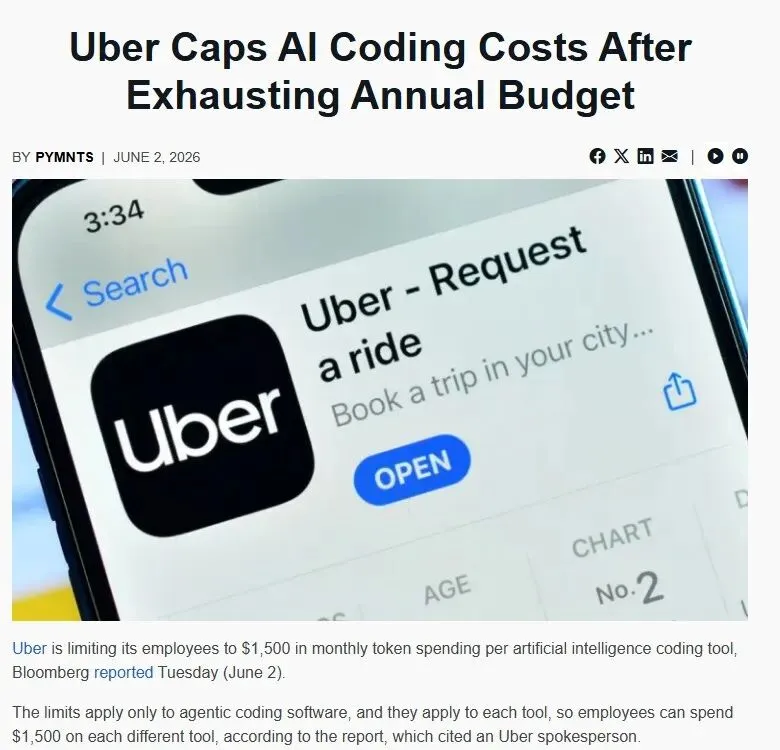
据 TechCrunch 和 PYMNTS 引用 Bloomberg 报道,Uber 最近给部分 AI 编程工具设置了月度支出上限:每名员工、每个 agentic coding tool 每月 1500 美元。报道提到的工具包括 Claude Code、Cursor 这类能连续执行编程任务的工具,员工可以通过内部 dashboard 追踪用量,在一些情况下也可以申请超过标准上限。
媒体报道里还有一个背景:Uber 到今年 4 月已经用完了全年 AI 预算。这个边界要说清楚,它不是 Uber 官方白皮书,也不是行业标准,只能作为一个强数字信号。
但这个数字之所以有意思,是因为它把 AI 工具从“随便试试”的状态,推到了“每个任务都要算账”的状态。
以前很多团队讨论 AI,重点放在采购上:买哪个工具,开多少账号,用 Claude 还是 Cursor,要不要给每个员工配高级模型。
可当 AI 真的进入工作流,账就不只在订阅费里。
它还藏在每一次反复试错、上下文读取、工具调用、中间结果生成、人工等待和人工验收里。你以为只是让 AI 多跑一轮,其实是在让项目多承受一轮成本和不确定性。
用量不是产出
有些 AI 考核容易走到一个误区:把“AI 参与了多少”当成“工作效率提高了多少”。
比如看代码里有多少由 AI 生成,或者看某个员工用了多少 AI 工具额度。这些指标不是完全没有意义,它们可以帮助公司知道大家有没有真的接触新工具,也可以帮助团队发现哪些流程开始被 AI 改写。
但它们更适合做观察指标,不适合直接变成绩效指标。
一旦它变成绩效,人就会很自然地优化这个数字,而不一定优化真实结果。
你要求 AI 生成代码占比,员工就可能把本来可以复用的简单逻辑重新生成一遍;你鼓励大家尽量多用 AI,团队就可能把一堆不值得自动化的任务也丢给 agent;你只看 token 消耗,就会有人去跑一些看起来很复杂、很耗额度、但并不解决业务问题的东西。
这不是员工坏,而是指标设计会改变人的动作。
AI 本来是用来减少无效劳动的,如果考核方式设计错了,它也可能制造新的无效劳动。
这也是为什么 Uber 这个上限不该只被理解成“限额”。它更像在提醒一件事:AI 使用需要可视化,但可视化以后,不能只盯着用量本身。
真正要看的,是这些用量有没有换来更快的交付、更少的返工、更清楚的验收,还是只换来一堆更漂亮的使用曲线。
项目不是一段代码
AI 最容易让人产生错觉的地方,是它能把一个局部问题处理得很快。
你让它改一个页面,它可能马上给出一版前端 UI。你让它补一个查询,它能写出 SQL。你让它搭一个后台接口,它也能生成代码。看起来,每个点都在被解决。
可一个产品不是这些点的简单相加。
真实项目里,前端 UI 不是孤立的,它要服从产品设计、用户路径和不同状态下的展示。数据库也不是随便加字段,它会影响权限、查询性能、历史数据和后续维护。一个看起来很小的接口修改,可能会让另一个页面的筛选条件失效;一个为了当前需求临时补的字段,可能会让后面的统计口径变乱。
这就是 AI 当前阶段很容易卡住的地方:它擅长处理局部任务,但复杂项目的难点往往在协调。
产品目标、用户体验、数据结构、权限边界、前后端状态、异常处理、业务优先级,这些东西彼此咬在一起。AI 如果只看当前窗口里的任务,很容易把这边修好,那边又弄出新问题。
这不是说 AI 不能做复杂项目,而是说复杂项目不能只靠“让 AI 继续跑”来推进。
越大的项目,越需要人来做几件事:定义目标,拆清模块,决定优先级,确认接口边界,检查副作用,最后判断这件事是不是可交付。
如果这些协调动作没有人负责,AI 生成得越多,后面要收拾的东西可能也越多。
多跑几轮不等于更好
一篇 2026 年 4 月提交到 arXiv 的论文研究了 agentic coding tasks 的 token 消耗。它研究的是编程任务,不能直接套到所有 AI 工具上,也不能拿来解释 Uber 个案原因。但里面有一个机制很适合普通人理解:当 AI agent 开始执行复杂任务时,token 消耗会明显波动,同一个任务不同运行之间的消耗可能差出很大倍数;更高 token 用量,也不稳定等于更高准确率。
这句话放到小团队工作里,就是:AI 多试几轮,不一定就更接近好结果。
有时多跑几轮确实能把方案磨顺。但更多时候,如果任务目标、限制条件和验收标准一开始没有说清,AI 会沿着一个模糊方向越跑越远。它可以生成更多页面、更多代码、更多文案、更多解释,但这些东西未必能合成一个更好的产品。
这也是 token 消耗和人工成本同时变高的原因。
AI 在跑,人在等;AI 生成,人在筛;AI 改完一个模块,人还要检查另一个模块有没有被牵连。最后成本不只是额度花掉了,还有人的注意力被持续占用。
很多团队一开始想让 AI 降低时间成本,结果变成另一种陪跑:人不断告诉它哪里不对,它不断给出新的版本,人再继续判断。
如果这件事本身价值很高,这种陪跑可能值得。比如一个复杂客户方案、一个核心产品原型、一次重要数据分析,AI 可以帮人更快探索空间。
但如果任务价值很低,或者任务本身还没想清楚,反复让 AI 跑就是在把不清楚的问题外包给计算资源。它不一定帮你想清楚,反而可能让你误以为“东西已经很多了”。
先保持辅助

所以对很多中小公司,尤其是主业并不是输出 AI 工具的公司来说,当前更现实的策略,不是急着追求“AI 全自动创造任务价值”。
更稳的做法,是先保持 AI 辅助。
让 AI 做第一稿、做备选方案、做资料归纳、做局部代码、做流程草图、做重复内容整理。人负责目标、判断、协调和验收。等行业工具更成熟、团队自己的流程也更清楚,再逐步把某些环节自动化得更深。
这不是保守,而是把人工和 AI 的度控制住。
AI 看起来越来越像一个万能按钮,但工作里真正难的往往不是按下按钮,而是知道什么时候不该按,什么时候按一次就够了,什么时候必须停下来让人判断。
如果一个团队现在就把“AI 产出比例”当成最终目标,很容易出现两种偏差。
一种是为了让 AI 参与更多,牺牲了产品整体协调。页面、接口、数据库、权限、查询、异常处理都有人让 AI 改过,但没有人真正负责把它们合成一个稳定产品。
另一种是为了让 AI 用量更高,制造了很多看似高级、实际无用的任务。额度消耗了,token 跑满了,报告也能写得很漂亮,但真实业务没有因此变简单。
这两种偏差,本质上都是把 AI 从辅助工具,误当成了绩效本身。
算的是任务价值
小团队需要的不是一张“多用 AI 表”,而是一张“AI 任务预算表”。
这张表不用很复杂,它只要先把几个问题说清楚:这个任务值不值得交给 AI,AI 在里面扮演什么角色,最多允许它试几轮,什么情况下停止,最后由谁验收。
可以先这样写:
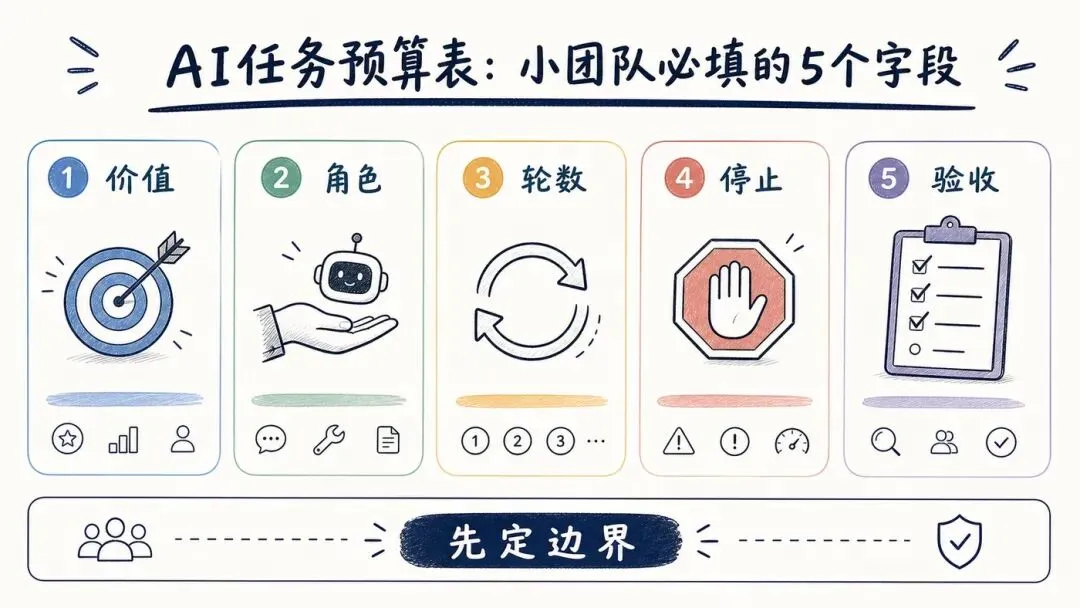
这张表真正要管的,不是 AI 有多强,而是人有没有先把任务说清楚。
当 AI 还是辅助工具时,最重要的不是让它多做,而是让它做在合适的位置。让它补速度,不让它替代判断;让它做局部生成,不让它独自承担整体协调;让它参与试错,不让它无限试错。
Uber 的 1500 美元上限是一个大公司的数字。普通人和小团队不需要照抄这个额度。
但这个新闻提醒了一件更近的事:当 AI 开始进入真实任务,成本、时间、效果和责任都会一起进入。
下次你准备把一件事交给 AI 前,可以先不急着打开工具。先问一句:
这件事是让 AI 辅助我,还是我正在把一个没想清楚的问题丢给 AI?
如果答案是后者,先停一下。
因为当前阶段,真正值钱的不是把 AI 用满,而是把人和 AI 的边界用清楚。
以上,既然看到这里了,如果觉得不错,随手点个赞、在看、转发三连吧,如果想第一时间收到推送,也可以给我个星标~谢谢你看我的文章,我们,下次再见。
参考资料
- TechCrunch: Uber caps employee AI spending after blowing through budget in 4 months
- PYMNTS: Uber Caps AI Coding Costs After Exhausting Annual Budget
- Simon Willison: Archive for Wednesday, 3rd June 2026
- arXiv: How Do AI Agents Spend Your Money? Analyzing and Predicting Token Consumption in Agentic Coding Tasks
