夜雨聆风
夜雨聆风你有没有遇到过这种抓狂的情况?跟ChatGPT聊了一下午的项目需求,明天打开新对话,它却问你"请问您从事什么行业";让Claude帮你改代码改了三小时,重启会话后它把之前的逻辑全忘了...这种AI的"金鱼记忆"真的让人崩溃。
其实从去年开始,我就一直在找能让AI拥有长期记忆的解决方案。试过自己搭向量数据库,也用过几款记忆插件,但总觉得差点意思——要么配置复杂得要命,要么就是简单的文本匹配,完全不懂什么叫"记忆"。直到我挖到了Supermemory这个项目,GitHub上已经飙到20.9k Star,才算是真正找到了组织。
这帮家伙搞了个啥呢?简单来说,就是给AI装了一个真正的"海马体"。它不是那种傻乎乎把所有聊天记录塞进向量库就完事的方案,而是真的会理解、整理、遗忘和联想。比如说你跟AI说"我明天要去面试",这种临时信息它会自动标记过期时间;但如果你说"我是做前端开发的",这种核心标签会被永久保存在用户画像里。更牛的是,如果你后来改口说"我转做后端了",它还会自动更新记忆,解决新旧信息的矛盾。
先试试在线版,5分钟上手
如果你跟我一样是个急性子,想先尝尝鲜,那直接去 https://app.supermemory.ai 注册个账号就行。整个流程跟注册个普通网站没区别,谷歌账号一键登录,连验证邮箱都省了。
进来之后第一件事,建议先把Chrome扩展装上。这个扩展简直是信息采集的神器——看到有价值的网页,右上角一点就存进你的"第二大脑";刷Twitter看到好线程,右键直接导入;甚至还能自动抓取你跟ChatGPT的对话(这个太实用了,以前想保存AI对话还得手动复制粘贴)。
安装扩展也很简单:
去Chrome Web Store搜"Supermemory"(或者直接点官网的Download按钮) 装好后点扩展图标登录 看到想保存的页面,点"Add to Memory"就完事
存进去的东西会自动做向量化处理,你不用管什么分块策略、嵌入模型这些技术细节。存就完事了。
程序员专属:给你的IDE装上记忆
但Supermemory最让我惊艳的是它对开发者的友好程度。他们做了几个IDE插件,特别是Claude Code那个,简直是生产力核弹。
安装方法如下(以Claude Code为例):
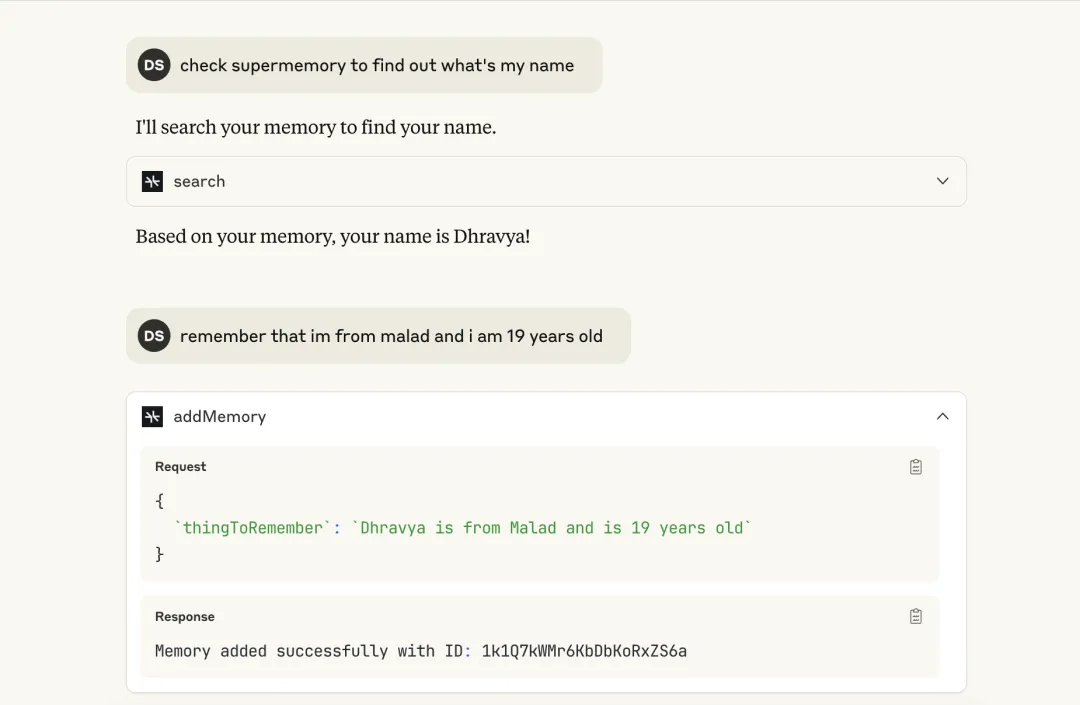
# 在Claude Code里直接运行claude mcp add supermemory然后按照提示输入你的API Key(在Supermemory后台的Settings里生成)。装完之后,你在Claude Code里写代码时,它就能自动读取你之前的项目背景、技术偏好、甚至是以前解决过的类似Bug。比如你可以直接问:"上次我处理过类似的WebSocket连接问题,当时是怎么解决的?"——它真的能给你翻出来,还能结合当前代码上下文给出建议。
他们还给OpenCode、OpenClaw都做了类似的记忆层,配置方法大同小异,基本上就是一条命令的事。
自己动手,丰衣足食:本地部署指南
当然,如果你跟我一样有点数据洁癖,或者公司要求必须私有化部署,那Supermemory也完全支持自托管。毕竟MIT协议开源,随便折腾。
部署需要准备的环境:
Node.js 18+ 和 Bun(对,他们用Bun,速度确实快) Cloudflare账号(用到了D1数据库、Vectorize向量库和Workers) Git
具体步骤:
第一步,克隆仓库
git clone https://github.com/supermemoryai/supermemory.gitcd supermemory第二步,安装依赖
bun install第三步,配置环境变量项目根目录有个.env.example,复制一份改成.env。主要需要填的是:
CLOUDFLARE_API_TOKEN:去Cloudflare控制台生成,需要D1、Vectorize和Workers的权限NEXTAUTH_SECRET:随便找个随机字符串生成器搞一串NEXTAUTH_URL:如果你本地开发就填http://localhost:3000
第四步,初始化数据库
bun run db:migrate第五步,启动开发服务器
bun run dev然后访问localhost:3000就能看到界面了。生产环境部署的话,他们推荐用Cloudflare Pages,因为整个技术栈都是基于Cloudflare生态的(Drizzle ORM + Cloudflare D1 + Vectorize),部署起来比传统的AWS方案省心不少。
对了,项目结构是Turborepo管理的,分成了apps/web(主应用)、apps/extension(浏览器扩展)、和apps/cf-ai-backend(AI后端)。如果你只想改前端界面,盯着apps/web目录折腾就行。
一些使用心得
用了大概三个月,说几个我觉得特别香的点。
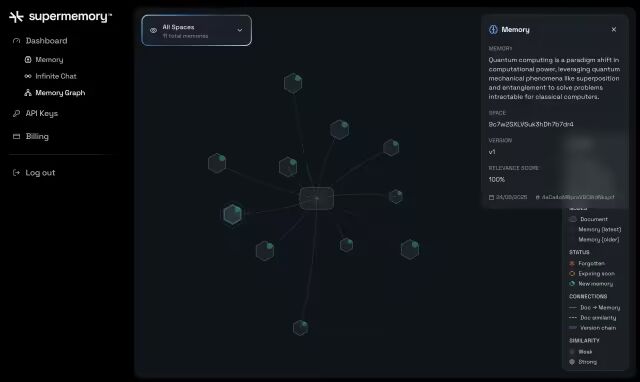
智能遗忘这个功能——听着有点反直觉,但真的很有必要。我之前用Notion存了几千条笔记,其实大部分都过时了,但我懒得删,结果搜索的时候老是被过期信息干扰。Supermemory会自动判断哪些信息是临时的(比如"下午三点开会"),哪些是永久的(比如你的技术栈偏好),临时信息过了有效期就不会在搜索结果里出现了。
混合搜索——它把传统的关键词搜索和向量语义搜索结合了。你可以直接搜"上次看的那个关于React性能优化的文章",不用记得具体标题,甚至不用记得是在哪看到的,它都能给你扒拉出来。
多模态支持——PDF、图片(能OCR识别文字)、视频(能提取字幕),甚至代码文件(带AST分析的代码分块),全能处理。我把自己这几年攒的技术书籍和博客草稿全扔进去了,现在找知识点快得很。
不过也有几个小坑提醒一下。目前他们的免费版有存储限制,如果存大量PDF可能会提示空间不足;另外虽然支持中文,但有时候对中文的语义理解还是不如英文精准,这个得等后续优化。
总之,如果你也受够了AI的健忘症,或者想给自己建个真正的"第二大脑",Supermemory绝对值得折腾一下。20.9k Star不是白来的,而且刚拿了300万美元融资,开发节奏很快,新功能迭代特别勤快。
开源地址:https://github.com/supermemoryai/supermemory
专注分享 GitHub知识,分享AI 资讯和AI搞米经验,分享AI Agent使用经验。

想领取完整版OpenClaw资料的小伙伴,点赞+在看,扫码加我VX,备注“github"。