 夜雨聆风
夜雨聆风身份证、银行卡、发票、快递单、车牌,这些东西以前大多要人自己看、自己抄。
现在放到 App 里,很多时候拍一张图就够了。图片上传以后,里面的姓名、号码、金额、地址会被识别出来,有的出现在页面上,有的进入后面的业务流程。
用户这边的动作通常没几步:
打开相机
↓
拍一张图
↓
等几秒
↓
文字出来了
写到代码里,可能也会被压成一个很短的调用:
recognizeImage(image)
或者:
uploadAndRecognize(file)
但图片里的字,不是 App 自己“看懂”的。
App 拿到的首先是一张图片。图片对机器来说是一堆像素点,哪里是背景,哪里是文字,哪些笔画连在一起算一个字,哪一串字又该合成一句话,都要经过识别服务处理。
这一篇就从拍下一张图开始,看 OCR 大概怎么把一张图片变成可读的文字。
一、图片刚进来时,只是一堆像素
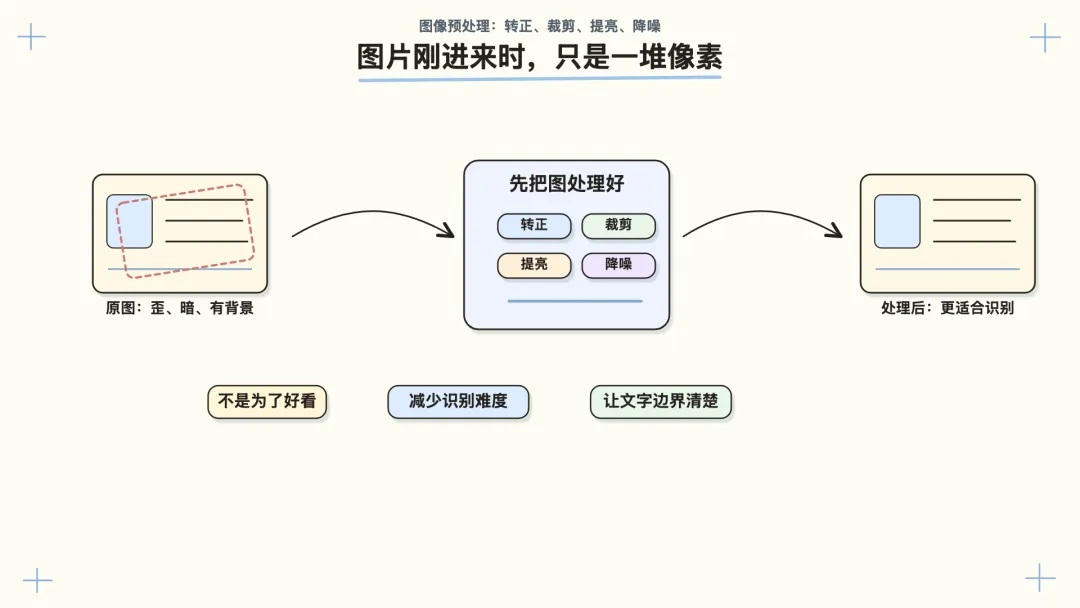
人看一张身份证,会很自然地分出照片、姓名、号码、地址。
机器刚拿到图片时没有这些概念。
它看到的是一张二维图,每个位置上有颜色和亮度。白底、黑字、阴影、手指、桌面、证件边框,在图片里都只是像素。
所以 OCR 拿到图片后,通常会先把图片处理到更适合识别,再进入读字环节。
比如:
把图片转正
裁掉多余背景
调整亮度和对比度
减少噪点
修正倾斜
找到可能有文字的区域
一张身份证如果斜着拍,号码区域就会跟着斜;一张发票如果有反光,某些字会发白;一张快递单如果背景太乱,文字边界就不好分。
人眼能靠经验补出来,机器不一定能补。
所以很多 App 会在拍摄时给一个框,提醒用户把证件、银行卡或发票放到指定区域。这个框不是只为了好看,它是在帮后面的 OCR 少踩坑。
有些处理发生在 App 本地,有些发生在服务端或 OCR 服务里。
移动端可能负责相机预览、边框提示、图片压缩、方向修正;OCR 服务则会做更细的图像预处理。分工不固定,但目的差不多,都是让后面的识别拿到一张更清楚的图。
二、先找出哪里有文字
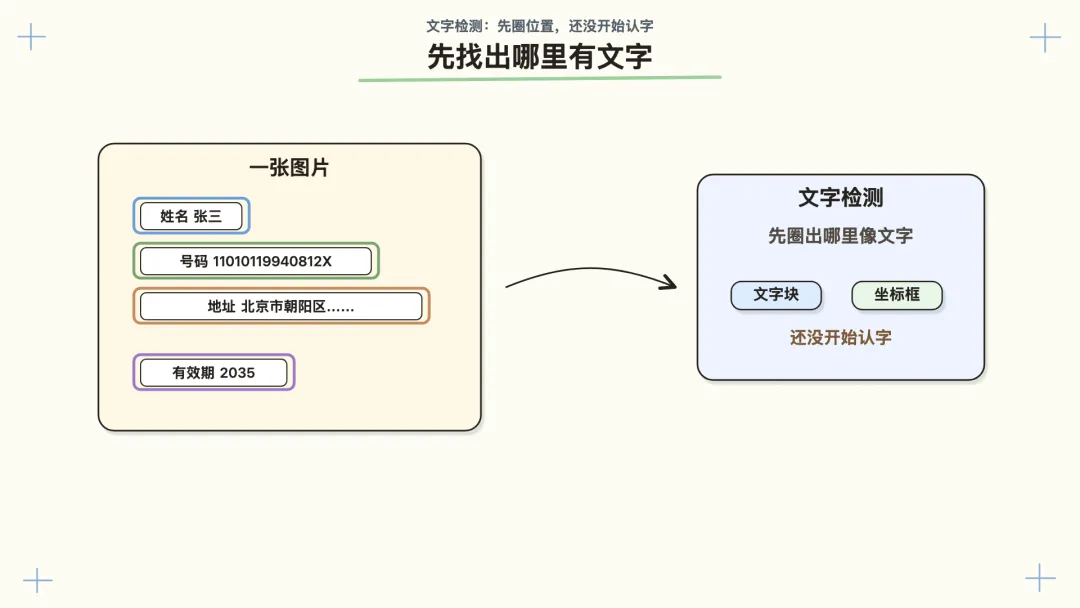
图片处理完以后,OCR 服务要先找到文字在哪里。
这一步叫文字检测。
它先不管“这是什么字”,只在图片上圈出“这里可能有一段文字”。
比如一张发票里,可能会被圈出这些区域:
发票号码所在区域
开票日期所在区域
购买方名称所在区域
金额所在区域
一张身份证里,可能会圈出:
姓名区域
性别区域
民族区域
出生日期区域
住址区域
公民身份号码区域
普通文档、截图、海报也类似。OCR 服务会先在整张图里找文字块,再把每一块送去识别。
这一步听起来简单,线上经常出问题。
文字可能是横着的,也可能是竖着的;可能很小,也可能很大;可能在白底上,也可能压在图片背景上;有些车牌、票据、广告图里,字体还会变形。
如果文字区域没找准,后面识别就会跟着错。
比如身份证号码只框到一半,后面再强的识别模型也只能看到一半;发票金额旁边的线条被框进来,也可能干扰识别。
所以 OCR 的前半段,很大一部分工作是在回答一个问题:
这张图里,哪里像文字?
三、再把文字区域读成字符
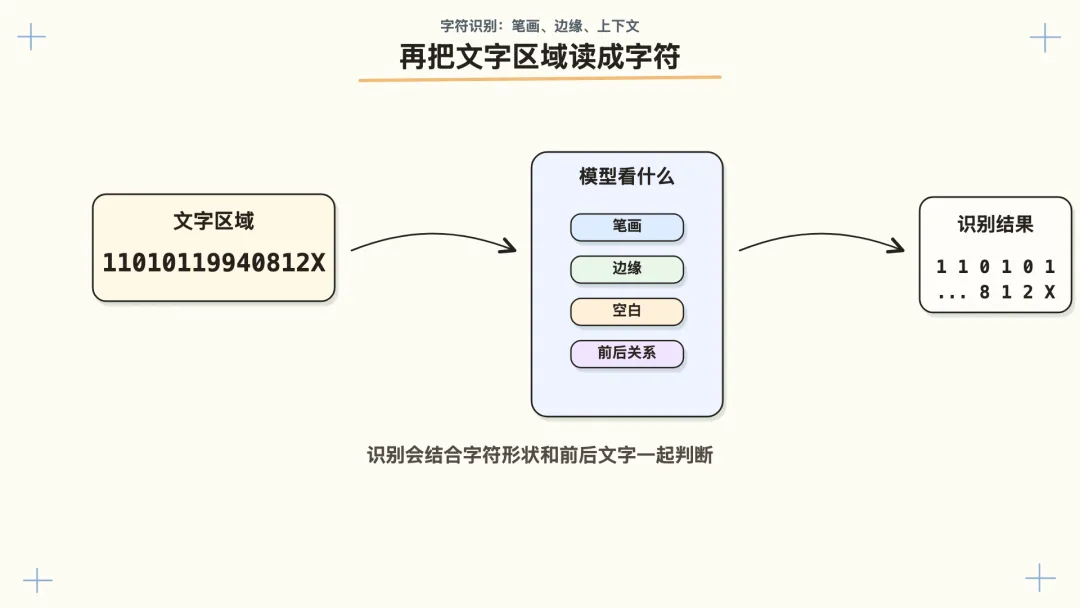
找到了文字区域,下一步才是文字识别。
这一步要回答的问题是:
这块图里的笔画,分别是什么字?
早一点的 OCR 会更依赖规则和模板,比如把字符切开,看每个字符的形状,再和已有模板比对。现在常见的 OCR 服务,多数会使用深度学习模型。
模型会从图片里提取特征。
比如一段数字:
11010119940812X
对人来说,它就是一串身份证号。对模型来说,先看到的是笔画、边缘、空白、字符之间的间距。模型会根据训练过的大量样本,判断这些形状接近 1、0、9,还是别的字符。
识别中文时会更复杂。
中文字符数量多,笔画差异细,有些字长得很像;图片里还会出现不同字体、手写字、印刷字、模糊字、压缩后的字。模型要把这些图像特征转成文字结果。
很多时候,它不是一个字一个字孤立判断。
一行文字会被当成一个序列来识别。模型既看单个字符的形状,也会看前后字符的关系。
比如:
北京市朝阳区
如果某个字拍得模糊,模型可能会结合前后文字,判断它是否符合地址里的常见写法。
这也是为什么普通文字识别、身份证识别、银行卡识别、发票识别的效果会不一样。
不同场景里的文字格式不同。身份证号码有固定长度,银行卡号大多是数字,发票有固定栏位,车牌有固定规则。OCR 服务知道当前识别场景时,就能利用这些规则减少误判。
四、文字出来以后,还要知道它属于哪里
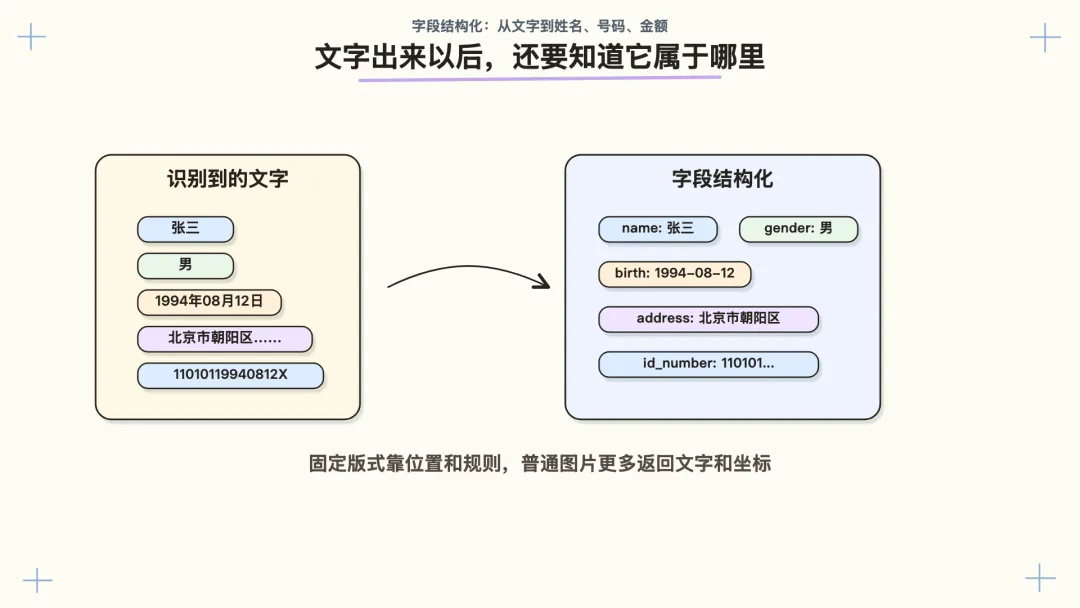
只把字读出来,还不够。
一张身份证上可能识别出:
张三
男
汉
1994年08月12日
北京市朝阳区……
11010119940812****
这些都是文字,但业务想知道的是:
name: 张三
gender: 男
nation: 汉
birth_date: 1994-08-12
address: 北京市朝阳区……
id_number: 11010119940812****
这一步可以叫结构化。
结构化会在认字之后,把识别到的文字放到对应字段里。
固定版式的图片会好处理一些。
身份证、银行卡、发票、车牌都有比较稳定的格式。OCR 服务可以根据文字位置、字段名称、格式规则来判断哪个是姓名、哪个是号码、哪个是金额。
比如发票里,“¥”后面的数字很可能是金额;身份证里 18 位数字很可能是身份证号;银行卡上连续的一串数字,很可能是卡号。
普通图片就难一些。
如果是一张聊天截图、路边招牌、合同照片,里面的文字不一定有固定位置。OCR 服务可能只能先返回文字内容和坐标:
text: 北京市朝阳区……
box: x=120, y=430, width=500, height=48
后面要不要把它当地址、标题、备注或正文,就要看业务场景。
所以 OCR 结果常见有两种。
一种是纯文字结果:
识别到了哪些字
这些字在图里的什么位置
另一种是结构化结果:
这个字段是姓名
这个字段是号码
这个字段是金额
前者更通用,后者更适合身份证、发票、银行卡这类明确场景。
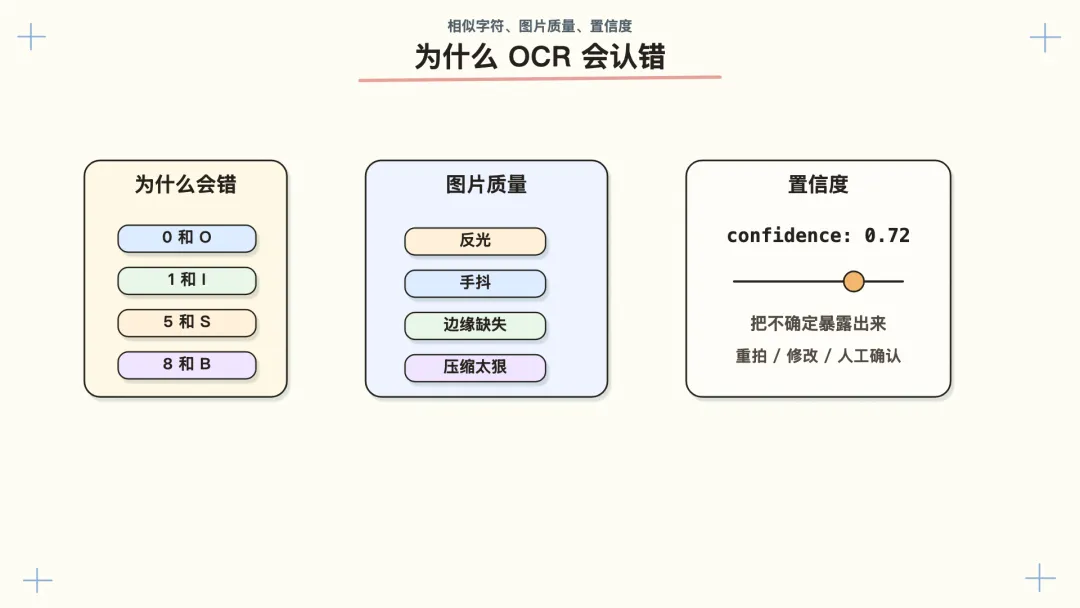
五、为什么 OCR 会认错
OCR 看起来像“读图识字”,实际要做很多次判断。
判断就会有不确定。
最常见的是字符相似。
0 和 O
1 和 I
5 和 S
8 和 B
这些字符在人眼里都可能看错,机器也一样。
还有一些错误来自图片质量。
比如:
反光把一段文字盖住
图片压缩后边缘发糊
拍摄时手抖
证件边缘没拍全
背景和文字颜色太接近
有些错误来自版式。
发票、合同、快递单上有很多线条、印章、表格边框。OCR 服务如果把线条当成笔画,或者把上下两行文字混在一起,结果就会乱。
还有一些错误来自语义。
模型可能识别出了一个“看起来合理”的字符,但放到当前字段里不合理。比如身份证号里多了一个汉字,银行卡号里出现了字母,金额字段里多了一个奇怪符号。
所以很多 OCR 服务会返回置信度。
field: id_number
value: 11010119940812****
confidence: 0.72
这个数值大概表示服务对这次识别有多有把握。
置信度高,不代表一定正确;置信度低,通常说明图片质量、字符形状或字段判断里有不确定。App 可能会提示重新拍,或者让用户手动确认。
六、App、OCR 服务和业务系统各做什么
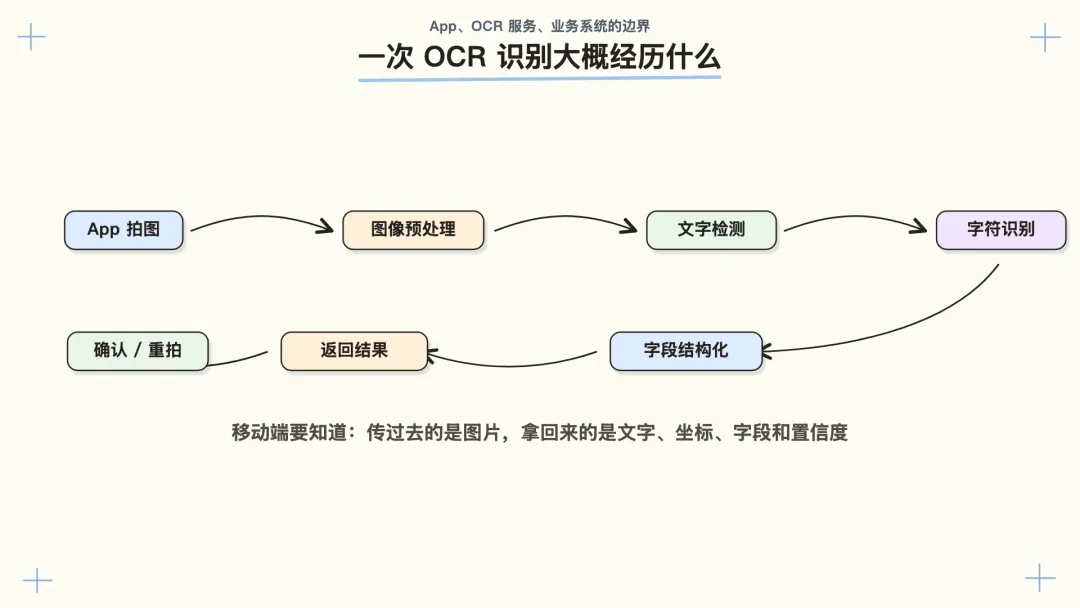
把原理放回 App 场景里,链路大概会变成这样:
App 拍照
↓
裁剪、转正、压缩图片
↓
上传图片
↓
OCR 服务做图像预处理
↓
检测文字区域
↓
识别文字内容
↓
按场景提取字段
↓
返回文字、坐标、字段和置信度
App 这边主要负责让用户拍到一张能识别的图。
比如相机引导、边框提示、图片压缩、失败重拍、识别结果展示。识别结果回来以后,App 还要把它展示成用户能看懂、能修改的样子。
OCR 服务负责图片识别。
它看图片、找文字、读文字、提字段。App 调用的可能是云厂商能力,也可能是公司内部封装过的一层服务。移动端不一定直接面对这些细节,但要知道自己传过去的是图片,拿回来的可能是文字、坐标、字段、置信度。
业务系统负责最后的判断。
身份证号格式对不对,发票是不是已经用过,银行卡能不能绑定,地址能不能配送,这些不是 OCR 原理本身能解决的事。OCR 只能把图里的信息尽量提出来,后面的校验要回到业务规则。
这也是 OCR 和业务系统的边界:OCR 负责“认出来”,业务系统负责“能不能用”。
七、再看那次图片识别
回到最开始那张图。
用户拍下身份证、发票或快递单以后,文字不会一下子从图片里跳出来。中间大概经历了这些事:
图片进入识别服务
↓
先把图处理得更清楚
↓
找到文字区域
↓
把文字区域读成字符
↓
结合场景提取字段
↓
返回识别结果和置信度
↓
App 展示结果
↓
用户确认或修改
先粗略看,OCR 有三步:
找字在哪里
↓
读出是什么字
↓
判断这些字属于什么字段
移动端写到这里,理解重点已经从“调哪个接口”往前多走了一步:自己传给识别服务的图片,会在里面经历什么。
图片太糊,文字检测会受影响;边缘没拍全,字段可能缺失;场景没传对,结构化结果可能不准;置信度低,页面就该给用户一次确认或重拍的机会。
拍一张图,然后识别出文字,看起来只是少打了几行字。
跨过去看,里面有图像处理、文字检测、字符识别、字段结构化,也有移动端和识别服务之间的配合。
