 夜雨聆风
夜雨聆风一、论文信息
今天的大语言模型已经不只是聊天工具,它会写代码、解数学题,也开始进入学习、办公和决策场景。我们常说某个模型更强,但这个判断往往来自有限次数的测试,换一组采样结果,排名就可能发生变化。论文关注的正是这个看似基础却影响很大的问题:怎样更可靠地评价一个大语言模型。
本篇推文解读的文章来自 International Conference on Learning Representations,简称 ICLR。它是机器学习与人工智能领域最具影响力的国际会议之一,长期聚焦表征学习、深度学习及相关前沿问题,在全球学界与工业界都有很高关注度。在 2026 年发布的第七版中国计算机学会推荐国际学术会议和期刊目录中,ICLR 已被列入 CCF-A 类会议。
中文题目:别再用Pass@k:一种用于大语言模型评估的贝叶斯框架
英文题目:Don't Pass@k: A Bayesian Framework for Large Language Model Evaluation
作者:Mohsen Hariri,Amirhossein Samandar,Michael Hinczewski,Vipin Chaudhary
来源:OpenReview
二、背景及贡献
大语言模型(Large Language Models)的评测常用Pass@k来描述推理能力。它关注模型在次采样中是否至少有一次答对。这个指标直观,但在数学推理这类样本少且推理成本高的任务中容易造成排序不稳定。一个模型可能因为某几次随机采样而排到前面,也可能因为种子或解码策略变化而掉队。更重要的是,Pass@k本身并不直接告诉我们两个模型之间的差距是能力差异,还是有限采样下的噪声。
论文的核心转向是把大模型评测视为统计推断(statistical inference)问题,而不是只计算一次分数。作者提出贝叶斯评估框架(Bayesian evaluation framework)Bayes@N,用后验均值(posterior mean)表示模型的潜在成功概率,并同时给出可信区间(credible interval)。这样,排行榜不再只是一个点估计,而是带有不确定性的比较结果。
论文贡献可以概括为三点。
统一的贝叶斯框架(Bayesian framework):把每道题的输出建模为类别变量(categorical outcome),再用狄利克雷先验(Dirichlet prior)得到闭式的后验均值和不确定性。二元正确性只是特例,部分正确、格式错误、拒答、置信度等级等都可以纳入同一框架。
带可信区间的评测协议(interval-aware protocol):报告后验均值与可信区间,当两个模型的区间重叠时不宣布胜负。该规则减少了由微小差距造成的榜单波动,也允许评测者把额外采样分配给仍然不确定的模型对。
仿真和真实基准的验证:在带已知真值的偏置硬币模拟中,以及AIME'24,AIME'25,HMMT'25,BrUMO'25四个数学推理基准上,Bayes@N比Pass@k及其变体更快接近参考排序。
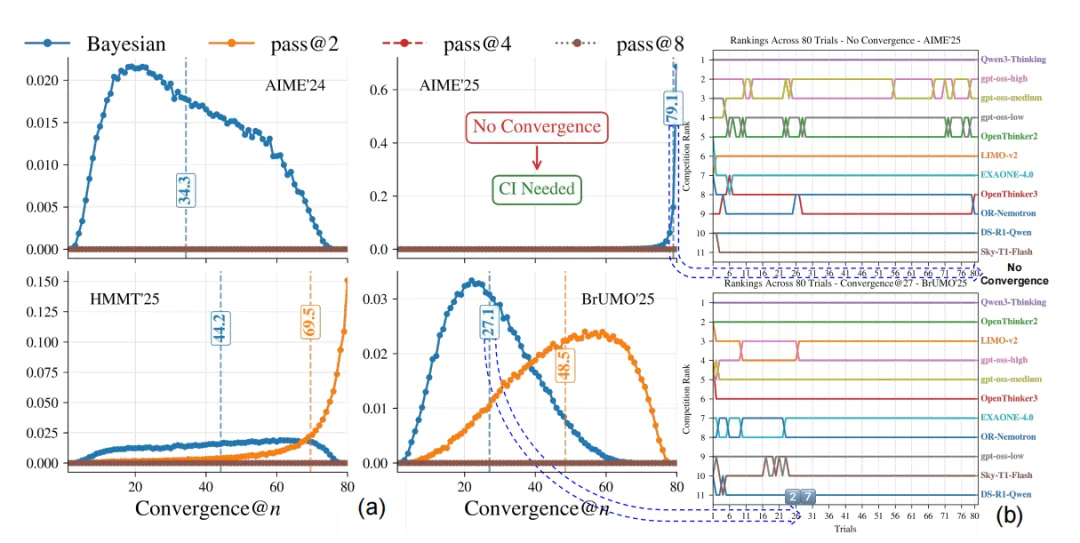
三、主要结论
第一,均匀先验下的Bayes@N与平均正确率(avg@N)在排序上等价,但Bayes@N额外给出了可信区间。这解释了平均多次运行通常比Pass@k更稳定,同时也说明仅有平均分仍然不足以判断差异是否显著。
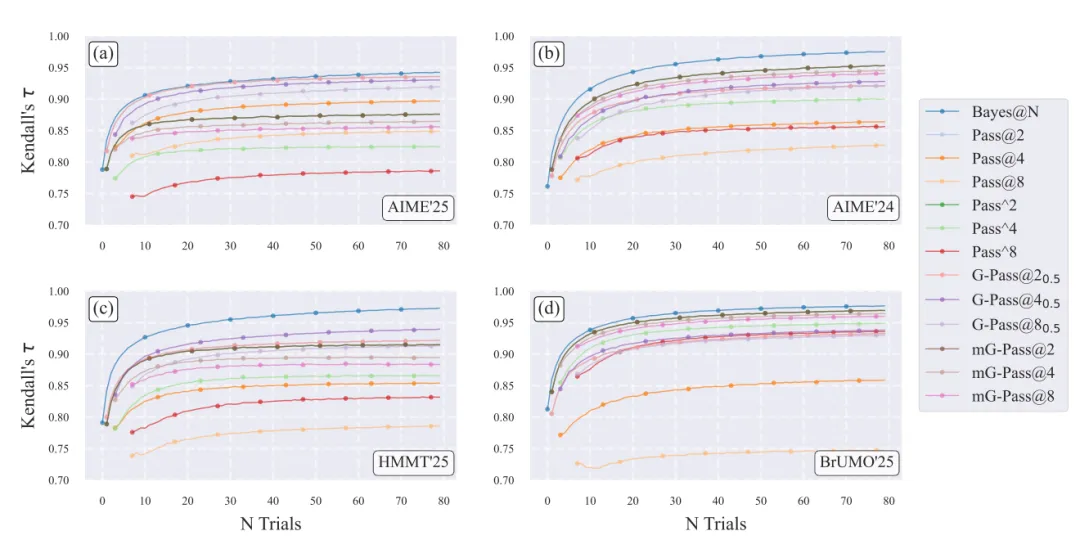
第二,Bayes@N在小样本下更快达到稳定排序。四个真实数学基准中,Bayes@N在附近已经达到Kendall's 。除AIME'25外,其余任务在附近接近。AIME'25在时仍约为,说明该任务下仍需要更多采样或区间化排序。
第三,可信区间会显著改变排行榜解释。原文第8页表2显示,Qwen3-30B-A3B-Thinking-2507和Qwen3-4B-Thinking-2507在四个数据集上稳定处于前两位,其中30B模型在95%可信区间下仍能与其他模型区分。中间模型的相对顺序则会随数据集和区间规则发生变化。
第四,类别化评测可以把正确性、格式、置信度、输出长度和验证器信号放在同一统计框架中。文章表明,Qwen3-30B-A3B-Thinking在多种类别化评分规则下均排名第一,但中间模型会随规则变化而重排。
原文第10页表3如下。
四、模型构建与公式细节
论文首先定义评测结果矩阵。假设有道题,每道题独立采样次,结果矩阵为。元素表示第道题第次采样的评分类别。若,类别表示错误,类别表示正确。若,则可以表示部分正确、格式合规、置信度等级等更细的评分。
对第道题,模型落入第类的潜在概率记为,向量为。给定权重向量,总体性能定义为
贝叶斯部分采用多项分布(Multinomial distribution)似然和狄利克雷先验(Dirichlet prior)。计数为
若有历史评测矩阵,其试验次数为,则先验计数为
后验参数为
于是有
后验均值与方差的闭式公式为
若比较两个模型,分别得到与,则差异的标准化量为
排序置信度为
当时,对应约的排序置信度。作者据此提出一个直接规则:若可信区间重叠,就不宣布某个模型优于另一个模型。
均匀先验下,Bayes@N与加权平均分满足
由于对所有模型相同,且,所以Bayes@N与avg@N的排序完全一致。不同之处在于Bayes@N同时给出了。复杂度方面,算法只需统计每题各类别计数并代入公式,总时间复杂度为
Algorithm 1如下。

五、实验与数据模拟
论文围绕评估协议本身做对照、仿真和敏感性分析。
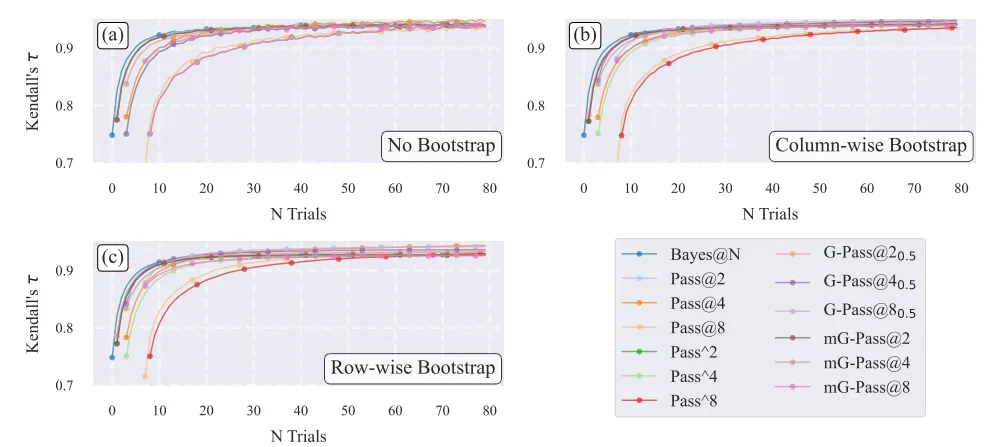
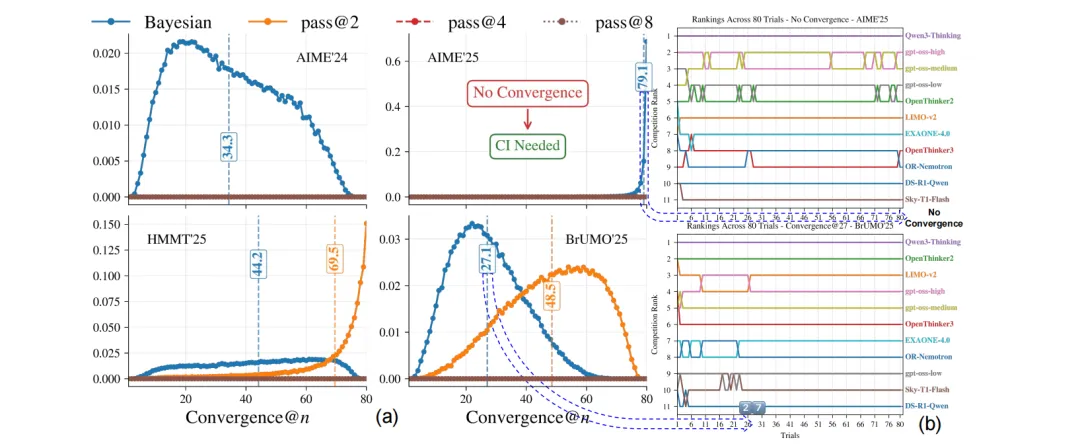
偏置硬币模拟:作者构造11组模拟模型,每组有30个已知成功概率,并设置一个真实并列情况。Bayes@N与Pass@2、Pass@4、Pass@8、Pass^k、G-Pass@k和mG-Pass@k比较。结果显示Bayes@N更快达到真实排序,见下图。
真实数学基准的收敛分析:在AIME'24,AIME'25,HMMT'25,BrUMO'25上,Bayes@N的Kendall's 在各个下通常高于Pass@k系列。HMMT'25与BrUMO'25中,Bayes@N平均约在44.2次和27.1次试验收敛,而表现最好的Pass@k约需69.5次和48.5次。见下图。
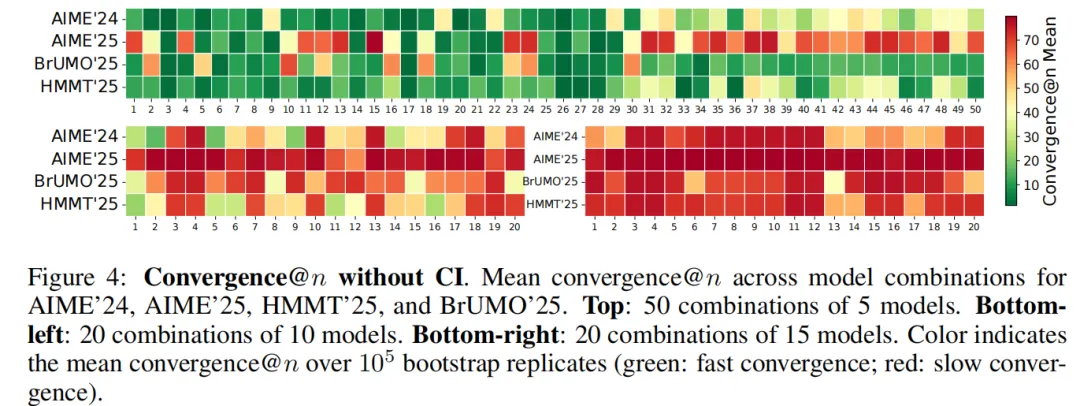
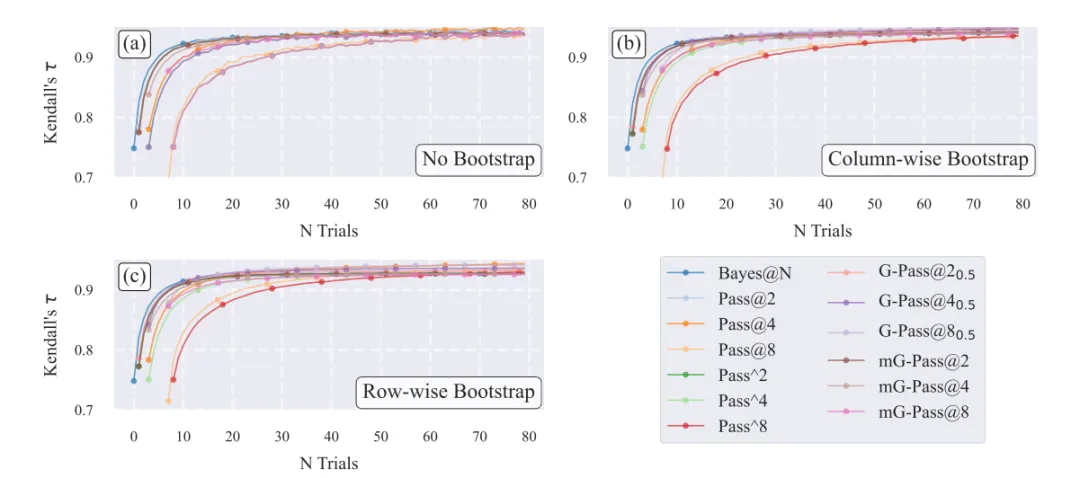
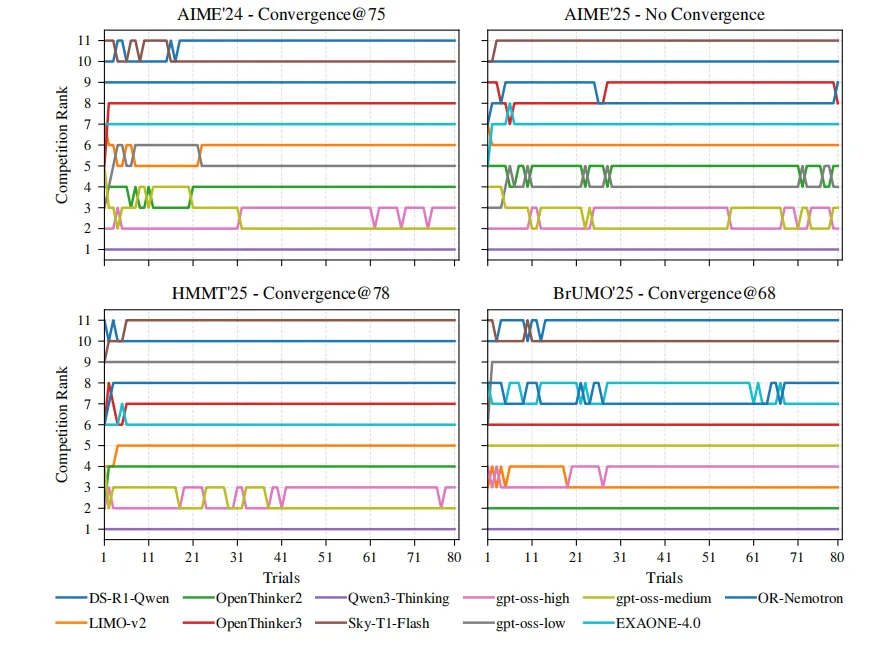
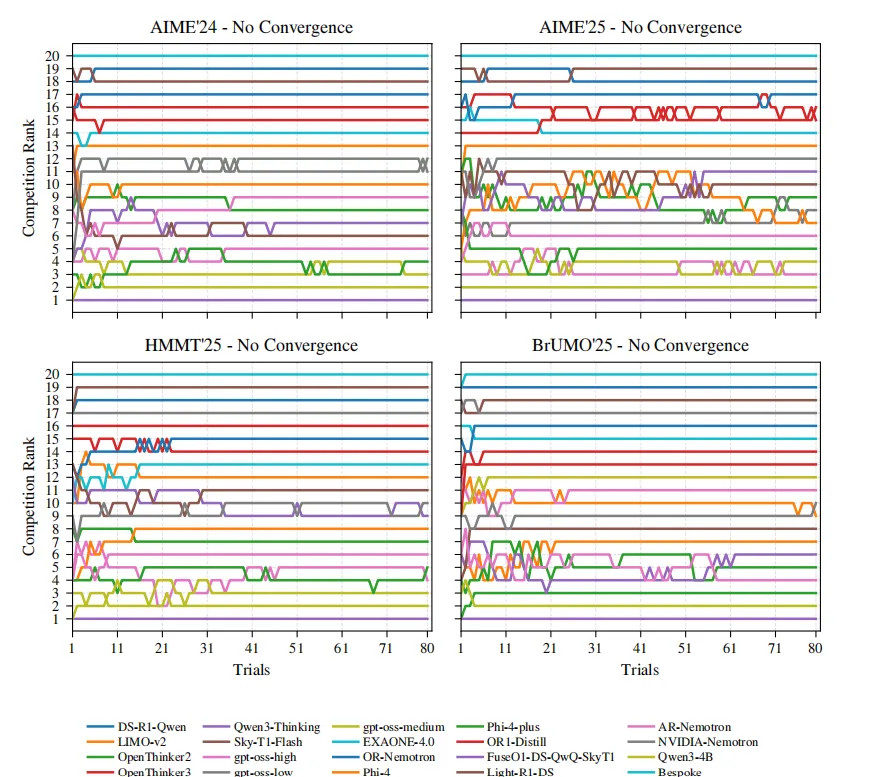
模型数量敏感性:当模型数从11扩展到20时,所有数据集在最坏bootstrap轨迹中都出现未收敛。说明待比较模型越多,单纯点估计排行榜越不稳定。见下图所示。
先验信息的作用:附录C用更新模型与原模型的相关性模拟非均匀先验。小的先验样本数能提升小时的排序质量,但或可能让旧信息压过新数据,从而损害排序。
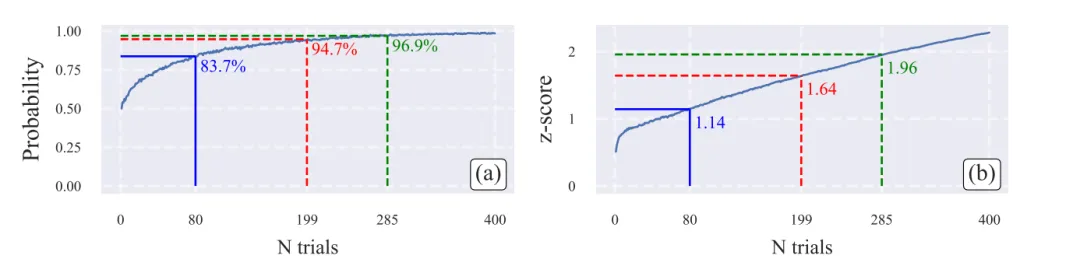
可区分性与样本量:在两个真实成功率接近的模拟模型中,时正确排序概率只有83.7%。若要达到约95%的排序置信度,需要约次试验。若达到约97.5%,需要约次试验。见下图。
计算成本:真实实验覆盖20个模型、4个任务、每题80次采样与每个基准30题,总计192000次推理,消耗7445.2 GPU小时,生成约2.96B tokens。
六、我们的思考
我们认为,这篇文章可能对统计学和大模型评测的结合有直接启发。第一,Bayes@N可能可以发展成序贯实验设计(sequential design):先对所有模型少量采样,再把预算分配给可信区间重叠的模型对,而不是平均增加采样次数。这样可以在同等算力下提高排行榜的判别力。
第二,可能未来可以引入层级贝叶斯模型(hierarchical Bayesian model)。不同任务、不同年份的基准、同一模型的不同版本之间通常相关。层级模型可以用部分池化(partial pooling)共享信息,同时避免某个旧基准的先验过强。文章附录C已经提示先验有收益,也提示先验需要敏感性分析。
第三,排行榜评估本质上是多重比较(multiple comparisons)。若有20个模型,就不仅是比较第一名和第二名,而是同时比较大量模型对。可以报告后验优越概率矩阵,并把错误发现率(false discovery rate)控制思想引入模型榜单发布。
本篇推文的封面、图片、表格来自论文原文:Don't Pass@k: A Bayesian Framework for Large Language Model Evaluation
公众号介绍
公众号“前沿统计学”致力于AI、统计学、数据科学的研究和学习。我们提供顶级期刊/会议深度解读、前沿数据分析方法实战与建模、AI工具使用指南、以及相关方向的升学/申请经验分享等服务,欢迎关注公众号交流合作。
