 夜雨聆风
夜雨聆风今天不谈复杂编译,直接教你用最快捷的“动态库方案”,让windows10+16G+ 4060(8G) + llama.cpp组合发挥出最大潜能。
一、 极速配置:解压即用
不需要安装 CMake,不需要配置 CUDA 环境,直接下载官方预编译版本。
依赖:安装Visual Studio
llama.cpp 运行时需要调用相关的库才能运行,如果已经安装过了可以跳过。win10对应的2019或更高版本。
各版本列表:https://visualstudio.microsoft.com/zh-hans/vs/older-downloads/
下载地址:https://visualstudio.microsoft.com/zh-hans/vs/older-downloads/#visual-studio-2019-and-other-products
运行下载的安装程序后,Visual Studio Installer 会启动,请严格按照以下配置进行勾选:
MSVC v142 - VS 2019 C++ x64/x86 生成工具(或对应版本的生成工具)
Windows 10/11 SDK
核心工作负荷: 在“工作负荷”选项卡中,必须勾选“使用 C++ 的桌面应用开发”(这是编译 llama.cpp 必须的核心库和环境)。
右侧详细信息(可选): 勾选后,在安装器右侧的“安装详细信息”面板中,建议确认以下组件处于勾选状态:
下载:
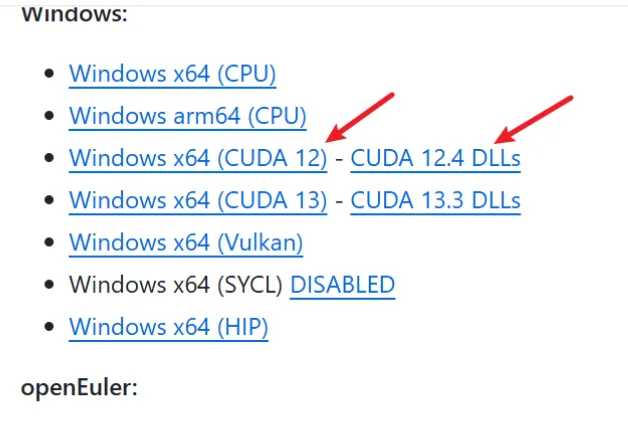
前往 llama.cpp Releases 页面,下载两个文件,注意一定要跟本地的cuda版本一致(4060是12.x)。
llama.cpp windows 压缩包,名字格式:llama-b9518-bin-win-cuda-12.4-x64.zip
llama.cpp 版本对应的显卡加速文件(dll文件),名字格式:cudart-llama-bin-win-cuda-12.4-x64.zip
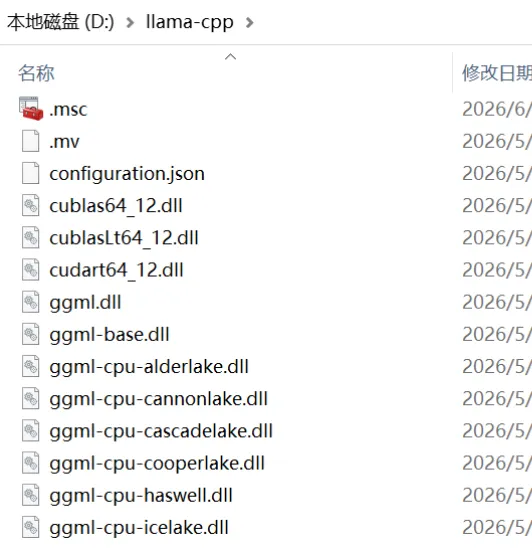
准备: 将下载的2个压缩包都解压到
D:\llama-cpp(或其他任意文件夹,自己取的名字)。
驱动检查: 打开 CMD 输入
nvidia-smi,看到显卡信息,说明环境已就绪。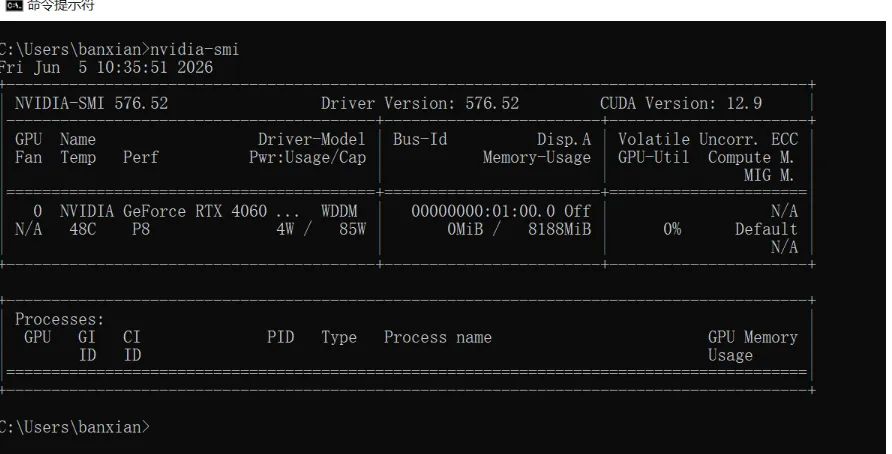
二、 下载模型:认准“黄金组合”
模型文件需寻找 GGUF 格式。对于 8GB 显存的 4060,Q4_K_M 是智力与体积的黄金平衡点。
下载步骤:
打开 Hugging Face 或 https://www.modelscope.ai/ (推荐)。
搜索关键词:
模型名 + GGUF(例如:DeepSeek-R1-Distill-Qwen-7B GGUF)。点击 "Files and versions",选择文件名包含
Q4_K_M的.gguf文件进行下载。推荐清单:
日常通用:
DeepSeek-R1-Distill-Qwen-7B代码辅助:
Qwen2.5-Coder-7B-Instruct能力均衡:
Llama-3.1-8B-Instruct
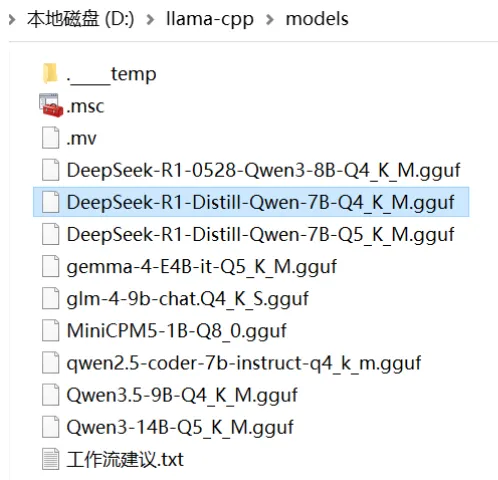
下载后,建议将模型文件放在 D:\llama-cpp\models 目录下。
三、 组合拳:后端算力 + 顶级前端
llama.cpp 是强大的“算力后端”,自带的 Web UI(llama-ui)功能非常初级。推荐使用 Cherry Studio ,解决原生界面体验差的痛点。
解除截断: 将 Cherry Studio“超时时间”设为 0,彻底告别 30 秒被掐断。
优雅展示: 完美支持 DeepSeek 等模型的
<think>标签折叠,思考过程清晰可见。全能外挂: 支持前端联网搜索与识图插件。
四、 实战:一键启动脚本
加载启动本地模型:
进入到llama.cpp的主目录,执行如下命令(可直接复制):
llama-server.exe ^
-m "models\DeepSeek-R1-Distill-Qwen-7B-Q4_K_M.gguf" ^
-ngl 28 ^
-c 8192 ^
--flash-attn on ^
-t 6 ^
--port 8080
说明:因为 7B 模型总共有 28 层(Layer)左右,剩下的十多层需要靠内存和 CPU 去跑。CPU 和内存的带宽远低于 4060 的显存带宽,成为了严重的木桶短板,后面再看怎么优化。
如下,说明启动成功。如遇参数不合法,可以搜索一下最新参数。
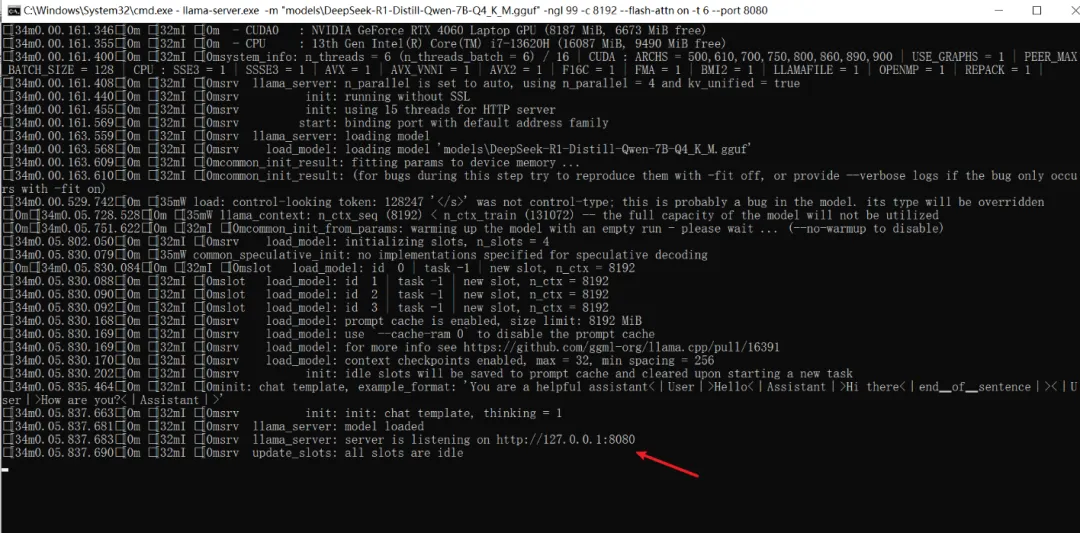
制作一键启动脚本:
将以下代码保存为 run.bat,放在 llama-server.exe 同目录下,点击即用:
@echo off
:: 将模型路径修改为你实际下载的路径
llama-server.exe ^
-m "models\DeepSeek-R1-Distill-Qwen-7B-Q4_K_M.gguf" ^
-ngl 28 ^
-c 8192 ^
--flash-attn on ^
-t 6 ^
--port 8080
pause
参数速查:
-ngl 99:自动将所有模型层卸载到 GPU,速度起飞。-c 8192:设定上下文长度,保证 AI 能记住长对话。--flash-attn on:显存减负 Buff,提升长文本生成速度。-t: 代表threads,即指定程序运行程序时使用的 CPU 线程数。
五、使用模型进行对话
1、使用自带的llama-ui
打开浏览器,输入地址即可:http://127.0.0.1:8080
2、使用 Cherry Studio 客户端(推荐)
功能更加强大,怎么设置连接大模型自行搜索一下。
查看资源占用情况
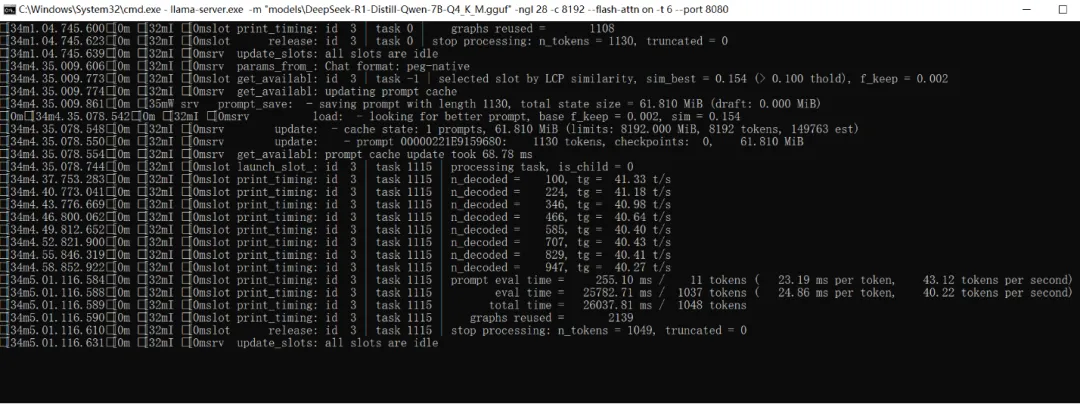
[34m1.04.745.639[0m [32mI [0msrv update_slots: all slots are idle[34m4.35.009.606[0m [32mI [0msrv params_from: Chat format: peg-native[34m4.35.009.773[0m [32mI [0mslot get_availabl: id 3 | task -1 | selected slot by LCP similarity, sim_best = 0.154 (> 0.100 thold), f_keep = 0.002[34m4.35.009.774[0m [32mI [0msrv get_availabl: updating prompt cache[34m4.35.009.861[0m [35mW srv prompt_save: - saving prompt with length 1130, total state size = 61.810 MiB (draft: 0.000 MiB)[0m[34m4.35.078.542[0m [32mI [0msrv load: - looking for better prompt, base f_keep = 0.002, sim = 0.154[34m4.35.078.548[0m [32mI [0msrv update: - cache state: 1 prompts, 61.810 MiB (limits: 8192.000 MiB, 8192 tokens, 149763 est)[34m4.35.078.550[0m [32mI [0msrv update: - prompt 00000221E9159680: 1130 tokens, checkpoints: 0, 61.810 MiB[34m4.35.078.554[0m [32mI [0msrv get_availabl: prompt cache update took 68.78 ms[34m4.35.078.744[0m [32mI [0mslot launch_slot: id 3 | task 1115 | processing task, is_child = 0[34m4.37.753.283[0m [32mI [0mslot print_timing: id 3 | task 1115 | n_decoded = 100, tg = 41.33 t/s[34m4.40.773.041[0m [32mI [0mslot print_timing: id 3 | task 1115 | n_decoded = 224, tg = 41.18 t/s[34m4.43.776.669[0m [32mI [0mslot print_timing: id 3 | task 1115 | n_decoded = 346, tg = 40.98 t/s[34m4.46.800.062[0m [32mI [0mslot print_timing: id 3 | task 1115 | n_decoded = 466, tg = 40.64 t/s[34m4.49.812.652[0m [32mI [0mslot print_timing: id 3 | task 1115 | n_decoded = 585, tg = 40.40 t/s[34m4.52.821.900[0m [32mI [0mslot print_timing: id 3 | task 1115 | n_decoded = 707, tg = 40.43 t/s[34m4.55.846.319[0m [32mI [0mslot print_timing: id 3 | task 1115 | n_decoded = 829, tg = 40.41 t/s[34m4.58.852.922[0m [32mI [0mslot print_timing: id 3 | task 1115 | n_decoded = 947, tg = 40.27 t/s[34m5.01.116.584[0m [32mI [0mslot print_timing: id 3 | task 1115 | prompt eval time = 255.10 ms / 11 tokens ( 23.19 ms per token, 43.12 tokens per second)[34m5.01.116.588[0m [32mI [0mslot print_timing: id 3 | task 1115 | eval time = 25782.71 ms / 1037 tokens ( 24.86 ms per token, 40.22 tokens per second)[34m5.01.116.589[0m [32mI [0mslot print_timing: id 3 | task 1115 | total time = 26037.81 ms / 1048 tokens[34m5.01.116.590[0m [32mI [0mslot print_timing: id 3 | task 1115 | graphs reused = 2139[34m5.01.116.610[0m [32mI [0mslot release: id 3 | task 1115 | stop processing: n_tokens = 1049, truncated = 0[34m5.01.116.631[0m [32mI [0msrv update_slots: all slots are idle
五、 避坑:8GB 显存分配清单
如果出现 "CUDA error: out of memory",请按此表调整:
| 模型类型 | 量化格式 | 显存占用 | 建议 |
|---|---|---|---|
| 7B 通用模型 | Q4_K_M | ~5.5 GB | 极速流畅(30+ t/s) |
| 9B 模型 | Q4_K_M | ~6.5 GB | 可用,适合复杂任务 |
| 14B 模型 | Q3_K_M | ~7.5 GB | 勉强,长文易溢出 |
温馨提示: 若显存报警,将
-c从 8192 降至 4096 即可立竿见影。
写在最后
无需成为工程师,通过简单的脚本组合,RTX 4060 就能从“游戏卡”变身为你的“AI 生产力助手”。
预告: 觉得这还不够?下一篇我们将探讨如何通过参数微调,在 8GB 显存内运行更大模型,彻底榨干 4060 的每一分性能。
跑通的小伙伴,欢迎在评论区分享你的 token/s 速度,看看谁的优化最强!
