 夜雨聆风
夜雨聆风蜡笔大新的 AI 生存手册 · AI Coding 工作流
我用 AI Coding 两个月后,发现真正难的不是写代码

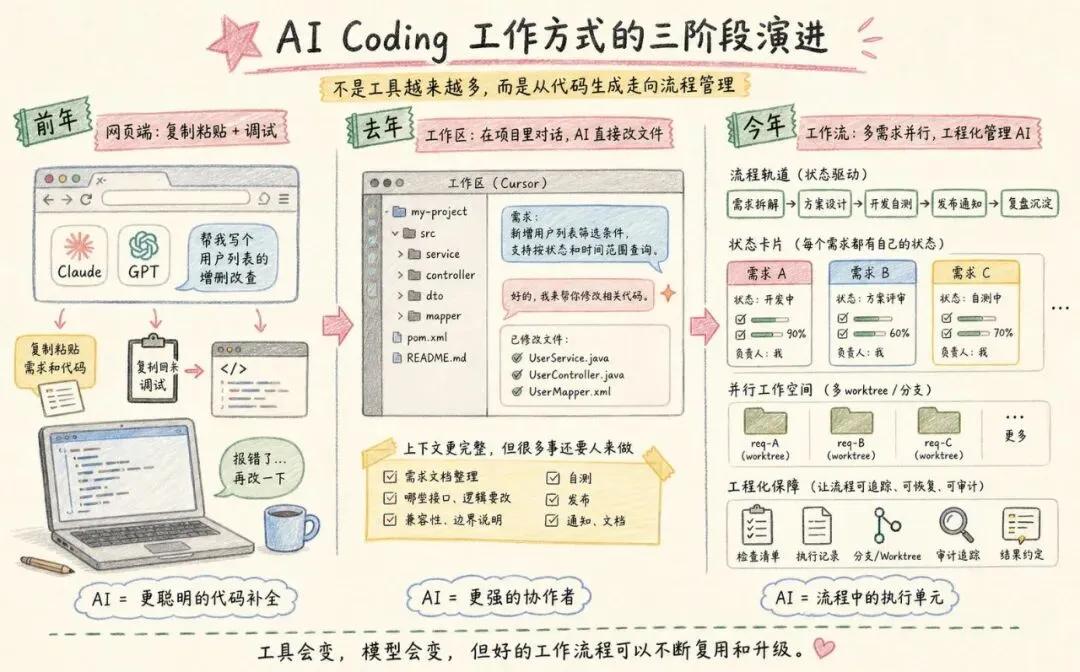
我最早用 AI 写代码的时候,其实很原始。
大概是前年那会儿,就是打开网页端,复制一段代码,再复制一段需求,丢给 Claude 或者 GPT。
它帮我写一段增删改查。
我再复制回来,跑一下,改一下报错。
那个阶段,我对 AI Coding 的理解很简单:
它就是一个更聪明的代码补全工具。
能省一点写样板代码的时间。
后来到了去年,我开始比较重度地用 Cursor。
工作方式确实变了。
不用再一段一段复制代码,而是直接打开工作空间,在项目里对话。
AI 能看到更多上下文,也能直接修改文件。
这比网页端舒服很多。
但用了一年以后,我发现一个问题:
AI 变强了,但整个开发流程,还是靠人拽着往前走。
需求文档要我整理。
上下文要我补充。
哪些接口要改,哪些逻辑不能动,哪里要兼容老数据,还是要我一遍遍说清楚。
代码写完以后,自测、发布、通知、文档,也还是要我一步一步盯着。
直到今年 4 月以后,需求节奏变快,这个问题变得更明显。
我才慢慢意识到:
AI Coding 真正卡住我的,不是代码生成,而是整个需求到发布的流程。
01|真正消耗人的,不只是写代码
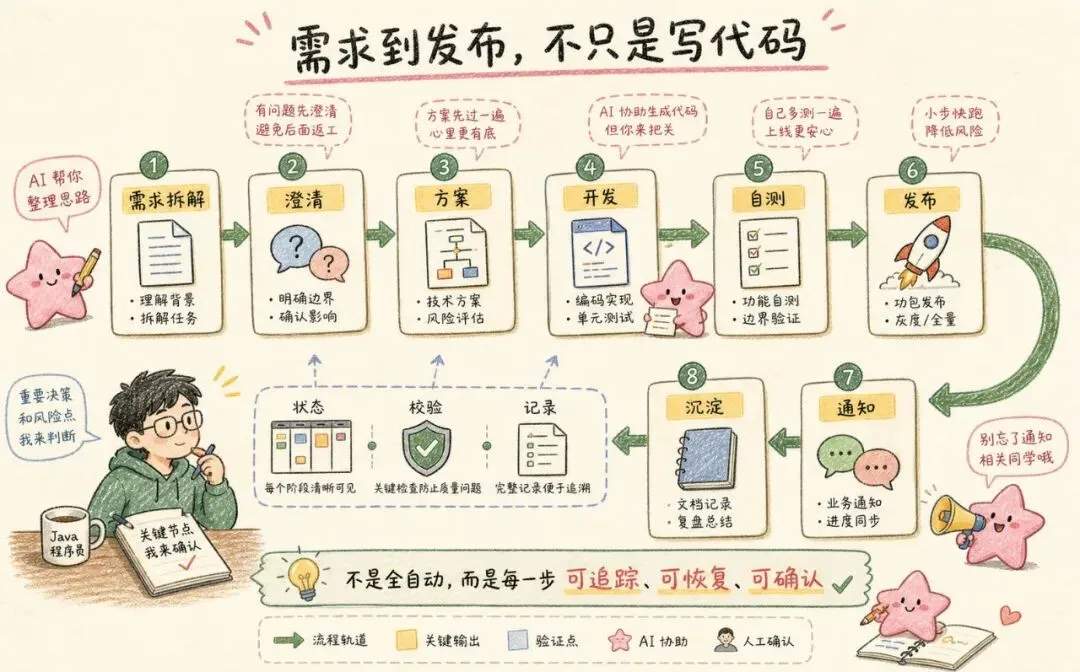
一个需求从开始到上线,里面有很多不起眼的环节。
需求要拆清楚。
影响范围要确认。
技术方案要落下来。
代码改完要自测。
发布步骤要跟上。
飞书通知要发。
文档和记录要补。
中间状态还不能丢。
这些事情单独看都不难。
但叠在一起,就很容易乱。
尤其是多个需求并行的时候,人的脑子会一直在切换上下文。
一个需求还在澄清。
一个需求已经开始写方案。
另一个需求又到了自测和发布。
如果只是打开 Cursor,让 AI 帮我改某一段代码,当然有用。
但它解决的是局部问题。
真正消耗人的地方,往往不是“这一段代码怎么写”,而是:
这个需求从哪里来,现在走到哪一步,下一步要交付什么,哪些信息不能丢。
所以我后来觉得,如果只是让 AI 帮我写代码,上限其实不高。
真正需要改造的,是工作流。
02|一开始我也想得太简单
中间有过一个小插曲。
我试过用 OpenClaw 加一堆子 Agent,让不同角色用不同提示词约束。
想法听起来挺美好:
让它自动读取飞书需求文档,自动拆解,自动写代码,最好一路跑到交付。
但实际试下来,并不理想。
任务经常跑到一半卡住。
上下文会丢。
某个子 Agent 理解错了,后面就一路偏。
有时候看起来它一直在执行,但你不知道它执行到了哪一步,也不知道它为什么停住。
那段时间我挺受挫的。
因为我原来以为,给 AI 多分几个角色,再写清楚提示词,就能把流程自动化起来。
后来发现没那么简单。
提示词可以约束表达。
但一个稳定的工程流程,不能只靠提示词撑起来。
03|我开始重新理解 AI 工作流
后来我看了一些文章和工具。
比如 OpenAI 的 harness 思路,也看过 OpenSpec、Superpowers、gstack 这类工具。
它们给我的启发,不是某个工具多神。
而是背后有一个共同点:
AI 不能只是孤零零地跑在聊天框里。
它需要被放进一套可以追踪、可以恢复、可以校验的流程里。
换句话说,AI Coding 不只是“让模型写代码”。
它更像是把一次开发过程拆成很多个可控节点。
每个节点知道自己要输入什么。
知道自己要产出什么。
知道完成后进入哪个状态。
失败了,也知道卡在哪里。
这件事听起来有点工程味。
但对后端程序员来说,其实并不陌生。
我们平时做业务系统,也是这样。
状态要落库。
流程要有状态机。
结果要有约定。
脚本要能校验。
关键节点要有 hook。
执行过程最好留下记录,方便回放和排查。
我后来才意识到:
AI 工作流落地,本质上不是写更多 Prompt,而是把 AI 当成流程里的执行单元,再用工程系统把它管起来。
04|我给自己搭了一个很小的版本
后来我开始在自己的工作里慢慢试。
这不是一天搭好的。
中间改了很多次,也废掉过不少想法。
差不多两个月下来,才慢慢有了一个能跑起来的小版本。
现在它大概能做这些事:
从飞书需求文档里拆解需求。
把关键信息落到本地流程。
推进需求澄清。
生成技术方案。
辅助开发和自测。
衔接发布、通知和文档记录。
这里我先不展开具体实现。
一方面是因为细节太多,一篇文章讲不完。
另一方面,我也不想把它写成工具教程。
我更想先讲清楚一个思路:
普通程序员用 AI Coding,不要只盯着某个工具会不会写代码,而要看自己的开发流程里,哪些地方一直在重复消耗。
比如需求拆解。
比如上下文整理。
比如方案确认。
比如自测清单。
比如发布记录。
比如每次都要重新写一遍的通知和文档。
这些地方不一定难。
但很耗注意力。
AI 真正适合帮我们做的,可能就是把这些重复消耗降下来。
05|多个需求并行时,最怕的是续不上
还有一个变化,是我以前没怎么想过的。
当你只有一个需求时,很多事情靠脑子记一记,还能撑住。
但多个需求同时跑起来以后,问题就变了。
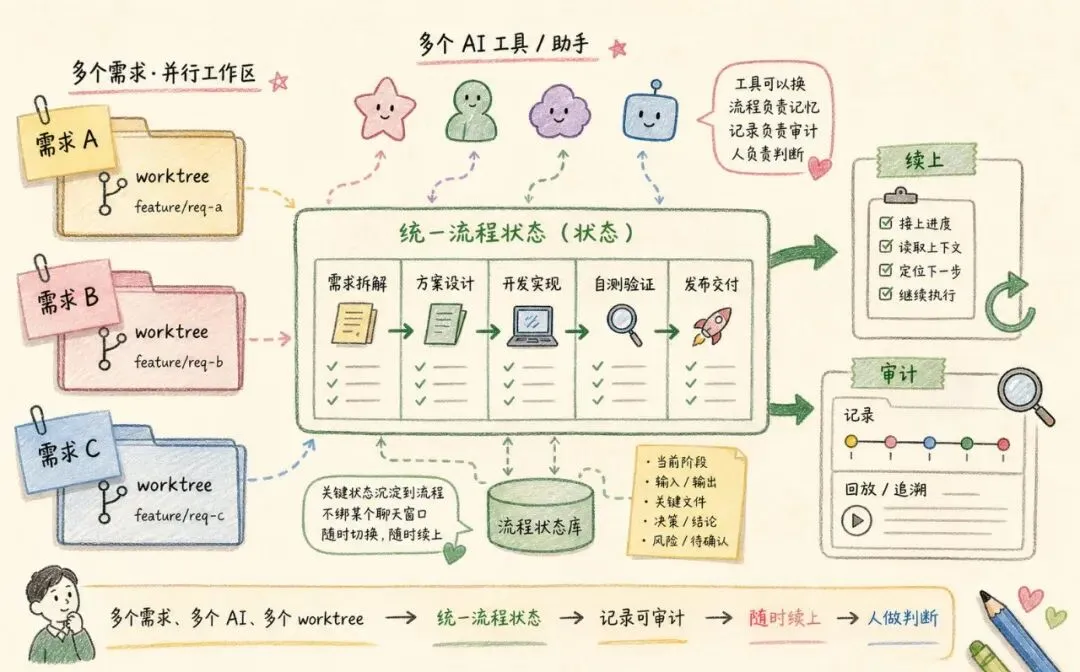
一个需求在 A 分支。
一个需求在 B worktree。
一个需求用 Cursor 改了一半。
另一个需求可能又想让 Codex 或 Claude Code 接着处理。
这时候真正麻烦的,不是“能不能再开一个 AI”。
而是:
多个需求、多个 AI、多个 worktree,怎么并行,又怎么随时续上。
如果每个 AI 都只活在自己的聊天窗口里,很快就会乱。
你不知道它改了什么。
不知道它为什么这么改。
不知道它跑过哪些检查。
也不知道换一个工具以后,对方能不能接上前面的上下文。
所以我后来给自己定了一个原则:
不要把上下文只放在聊天里。
要把关键状态、关键产出、关键证据,尽量落到流程里。
比如一个需求现在走到哪一步。
当前 worktree 对应哪个需求。
这一步的输入是什么。
产出是什么。
哪些地方需要人确认。
哪些检查已经跑过。
哪些结论只是 AI 的建议,不能当成最终事实。
这些信息一旦沉淀下来,就不再绑定某一个聊天窗口。
今天用 Cursor。
明天换 Codex。
后天让 Claude Code 帮忙 Review。
只要它们能读到同一套流程状态和产出约定,就有机会接着往下做。
这也是我现在觉得“兼容不同 Agent 工具”很重要的地方。
不是去赌某一个工具永远最好用。
而是把自己的工作流做成一个相对稳定的底座。
工具只是执行者。
流程负责记忆。
记录负责审计。
人负责判断。
这样多个需求并行时,才不至于每次切回来都要重新想:
我上次做到哪了?
这个 AI 到底改了什么?
这一步能不能继续?
我觉得这是 AI Coding 进入真实工作后,绕不开的一步。
06|普通程序员可以先从流程开始
如果你现在也想用 AI Coding,我不太建议一上来就追 Agent、MCP、自动化平台。
这些东西当然有价值。
但如果流程本身没想清楚,很容易越折腾越乱。
可以先问几个简单的问题:
一个需求从开始到上线,中间到底有哪些步骤?
哪些步骤每次都要重复做?
哪些信息经常丢?
哪些地方最容易靠脑子硬记?
哪些产出其实可以固定格式?
哪些节点必须人来确认,不能完全交给 AI?
先把这些问题想清楚,再去选工具。
这比一开始就问“Cursor、Codex、Claude Code 哪个更强”更有用。
因为工具会变。
模型也会变。
但你的工作流程一旦沉淀下来,是可以不断复用和升级的。
这也是我现在对 AI Coding 最大的变化。
以前我关心的是:
这段代码能不能让 AI 写?
现在我更关心的是:
这次开发过程,能不能沉淀成下一次可复用的流程?
写在最后
这篇先不展开具体实现。
比如怎么拆飞书需求文档,怎么设计流程状态,怎么约定每个节点的产出,怎么做自测和发布衔接,后面我会慢慢写。
我自己也还在迭代。
很多地方谈不上成熟。
只能说,我已经从“复制代码让 AI 写”,慢慢走到了“用流程把 AI 管起来”。
对普通程序员来说,这可能是一个更现实的开始。
不要一上来就追求全自动。
先让 AI 进入你的真实工作流程。
先帮你少做一点重复劳动。
先把一次需求拆解、一次方案确认、一次自测、一次复盘沉淀下来。
这些东西看起来不炫。
但它们会慢慢变成自己的工作资产。
后面我会继续写这套 AI Coding 工作流的拆解过程。
如果你也在试着把 AI 用进真实开发里,可以先关注一下。
我们一起慢慢把这件事讲清楚。
记录一个普通 Java 程序员,如何在 AI 时代寻找职业、副业和收入的第二曲线。
不装专家,不贩卖焦虑,只分享真实、可执行的尝试。
