 夜雨聆风
夜雨聆风有一道怪题困扰着每一个做生态AI的工程师:
模型足够强,数据看上去也有,但结果就是跑不起来——要么预测精度稀烂,要么管用的模型换一个站点就彻底失效,要么辛苦训练出来的大模型在实际部署后输出的全是废数。
问题出在哪里?
几乎所有人最后都会给出同一个回答:数据没打通。
这个答案听起来平淡,却是生态AI领域一个深藏在冰山之下的结构性困境。本文想把这块冰山翻出来,彻底讲清楚——多源异构生态数据的融合,为什么是整个AI生态应用链条上最难啃的骨头,又该如何系统性地破解。
一、5万个节点,说着5万种语言
2026年5月,国家生态环境监测"十五五"规划传来一个振奋人心的数字:全国生态环境监测网点位将从现有的3.3万个扩容至5万余个,覆盖降碳、减污、扩绿全领域。天空地海四维立体感知网络正在快速织密。
这是一个巨大的进步。但在这个进步背后,潜藏着一个技术人员不得不面对的现实:这5万个节点,几乎每一类传感器都在说着自己的语言。
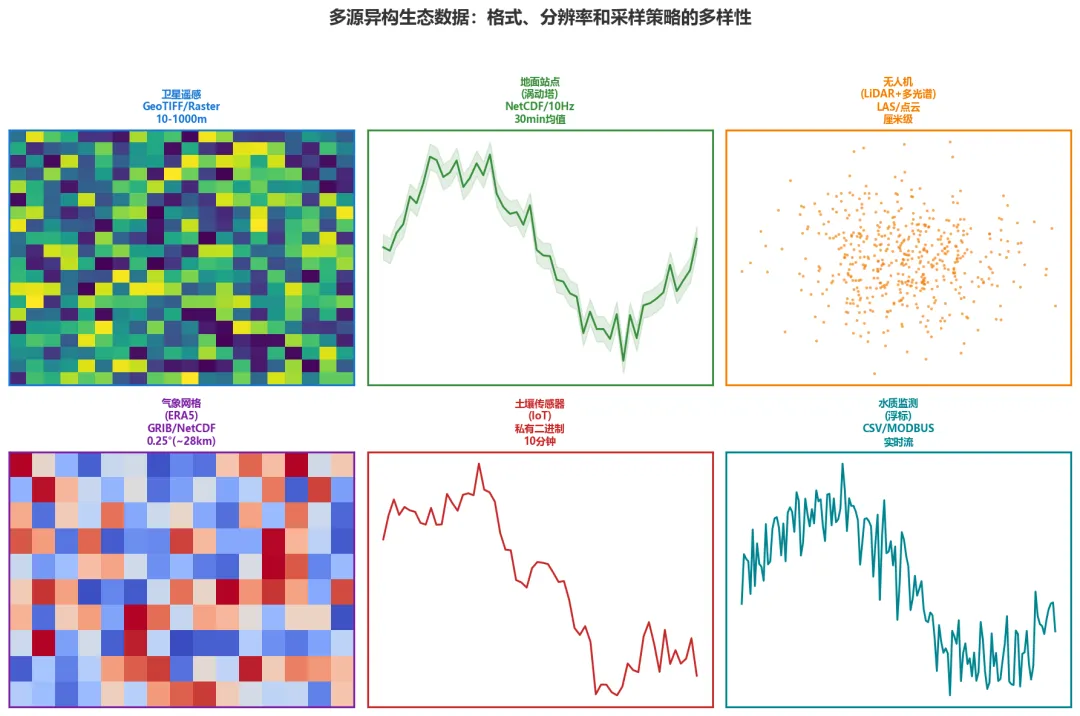
让我们来拆解一下这张网络到底有多"杂":
卫星遥感层(天):Sentinel-2多光谱(13个波段,10-60m分辨率)、Landsat-9热红外(100m)、MODIS时序(250m-1km,每日)、高分系列(0.5-16m)、PRISMA高光谱(239波段,30m)。每颗卫星的轨道周期、辐射校正方式、云覆盖处理方法都不一样。
无人机/航空层(空):消费级无人机的RGB影像、搭载LiDAR的点云数据(每次飞行动辄亿级点)、热成像相机的热红外数据——三者格式、坐标系、时间戳记录方式统统不同。
地面站点层(地):涡动协方差塔(EddyPro软件处理的30分钟均值NetCDF文件)、自动气象站(CSV格式10分钟观测)、土壤传感器阵列(不同厂商的私有格式)、水质监测浮标(MODBUS/TCP协议实时流)。
海洋/水体层(海):声学多普勒流速剖面仪(ADCP二进制文件)、CTD传感器(温盐深链式数据)、浮标阵列(Argo格式NetCDF)。
以FLUXNET2015数据集为例:这是国际涡动协方差研究的黄金标准数据库,由Pastorello等人(2020,Scientific Data)建立,收录了来自全球212个通量站、累计1532个站点-年的长期观测数据。但即便是经过多年标准化整理的FLUXNET,其中仍然混杂着来自不同仪器厂商、不同高度处理方案、不同插补算法的数据——这还是"已经被标准化"的结果。在此之前,原始数据的杂乱程度是这的数倍。
格式异构只是冰山一角。 真正让工程师夜不能寐的,是三类更深层的问题——不解决它们,再强的AI模型在生态数据面前也只能"有力气没处使"。为什么?因为AI的核心能力是"从数据中学习模式"——但如果数据本身在时空维度上就无法对齐、质控标准互不承认、同一个名字指向不同的东西,那AI学到的所有"模式"都可能是虚假的。让我们逐一拆解这三道坎。
二、三类深层难题:格式之下的地狱
难题一:时空分辨率的"像素鸿沟"
不同数据源覆盖着完全不同的时空粒度,而生态过程恰恰是跨尺度耦合的。
一个典型的冲突场景:你想用MODIS时序预测某流域的碳通量动态。MODIS给你250m×250m的像元,每16天一景(考虑云遮挡实际更稀)。但涡动协方差塔给你的是一个"footprint"——这个足迹的形状随风向时刻变化,半径通常在200-2000m之间,采样频率高达10-20 Hz,30分钟汇总一次。
要把这两种数据"对齐",不是一个简单的插值问题。空间上,你需要做footprint建模(常用Kljun et al. 2015的2D参数化方案),计算每半小时内通量塔的"看到范围",再用这个动态足迹去加权卫星像元。时间上,卫星的16天观测代表的是一个"综合状态",而通量塔的30分钟值代表的是瞬时状态——两者在概念层面就不等价。
更麻烦的是,一旦你想做区域尺度推断,就要把数十个站点的点状测量"上推"到面状卫星数据——这个上推过程会引入怎样的系统偏差?在异质性强的景观(如镶嵌型农林交错带)中,偏差往往可以达到20%以上。
数学上,这个问题可以形式化为:
其中 是空间任意位置的瞬时通量, 是时变的footprint权重核, 是研究区域。问题在于: 只有在站点处有直接观测,其他位置都需要模型估算——而这个估算本身又依赖于所有你想融合的数据。这是一个循环依赖的不适定反演问题。
难题二:质量控制标准的"各自为政"
每个传感器体系都有自己的质控体系,但这些体系之间无法直接互认。
涡动协方差数据有一套成熟但繁琐的质控流程:稳态检验(Stationarity test)、湍流条件检验(Integral turbulence characteristics)、摩擦风速阈值过滤(u* filtering,通常 u* < 0.1-0.2 m/s 的夜间数据直接丢弃)、以及插补(各站点缺失率通常高达30-60%)。FLUXNET采用的NEE质量标志(QC flag)分为0/1/2三级,0表示测量值,1/2分别是不同方法的插补值。
遥感数据有另一套:Sentinel-2的SCL(Scene Classification Layer)提供云、云影、雪、水体等12类掩膜;MODIS的MOD13A1里QA位标识了VI的可靠性(0=好数据,3=云覆盖);高分数据的辐射校正精度则取决于获取时的大气参数。
气象站数据更是五花八门:世界气象组织(WMO)有BUFR格式规范,但大量小型自动站根本不遵循;土壤温湿度传感器的输出往往是厂商私有的数字量,需要站点特定的标定曲线才能转换成物理量。
当你把这些数据拼在一起时,你并不知道某一时刻哪条数据是可信的、哪条数据的"缺失"是真缺失还是质控过滤掉了、哪条数据的异常是真实极端事件还是传感器故障。
这不是可以用统计方法一键解决的问题。它需要每种数据类型的领域专家知识、系统性的元数据管理,以及跨数据源的一致性核验机制。
难题三:语义鸿沟——同名不同义
这是最隐蔽、也是最容易踩坑的问题。
"土壤温度"是一个听起来无比直白的物理量。但当你把来自三个不同站点的"土壤温度"数据放在一起时,你可能面对的是:5cm深度的热敏电阻读数 vs. 10cm深度的热电偶读数 vs. 表层0-5cm的平均值。深度、仪器类型、安装方式不同,在干旱事件中这三者的差异可以高达8-15℃。
"生物量"可以是地上生物量、地下生物量,可以是鲜重也可以是干重,可以是NDVI遥感估算值也可以是样地实测值。文献中的"NPP"可能指的是年际累积量、可能是瞬时速率、可能是基于不同呼吸分配假设的净值。
"降水量"看上去最标准,但站点雨量计和格网气候数据集(如ERA5)在小尺度空间中的差异,可以轻易超过30%。
这种语义层面的不一致,会在AI模型训练时悄无声息地引入系统性偏差。模型可能会学到一些"垃圾相关性"——比如把某类传感器的系统误差学成了真实的生态信号——而这种模型的验证精度可能看起来还不错,直到在新站点部署时彻底崩溃。
三、当前主流破解路线:四类技术方案对比
面对上述三重困境,学界和工业界正在推进四条技术路线:
路线A:统一数据模型 + ETL管道
这是最传统的工程路线。核心思路是:先定义一套通用数据模型(Universal Data Model),再通过ETL(Extract-Transform-Load)管道把各来源数据规范化成这套模型。
代表性工作是OGC传感器网络框架(Sensor Web Enablement)中的SOS(Sensor Observation Service)和SensorML规范,以及国内的生态环境数据标准(HJ/T)体系。
优势:一旦完成规范化,下游分析可以无缝调用。劣势:ETL管道的开发和维护成本极高,每接入一种新数据源都需要专门开发适配器;更大的问题是数据中包含的"语义"往往无法用固定Schema完全捕获。
实际表现(R²角度):在格式规整、来源有限的小系统中效果良好;一旦数据源超过20类,维护成本呈指数增长,格式漂移(Schema drift)几乎不可避免。
路线B:联邦学习 + 隐私计算
不把数据物理汇聚,而是让模型在各数据孤岛上"就地训练",只汇聚模型参数。这是数据确权问题日益突出背景下的重要方向。
McMahan等人(2017,AISTATS)提出的FedAvg算法奠定了联邦学习的基础框架。在生态领域,这一方案有天然吸引力——大量观测数据分属不同机构(气象局、生态站、科研院所),彼此之间存在数据共享壁垒。
优势:绕过了数据确权和隐私顾虑。劣势:在高度异构的非独立同分布(Non-IID)数据上,联邦学习的模型收敛速度极慢,且最终精度往往低于集中训练基线10-30%。生态观测数据的分布差异(不同气候带、不同生态系统类型)比典型联邦学习场景更大,使这一差距进一步拉大。
路线C:时空基础模型(Geospatial Foundation Model)
用海量多模态遥感数据预训练一个大型基础模型,让模型自主学习跨传感器的特征对齐。代表性工作包括:
Prithvi-100M(2023,IBM & NASA):基于Sentinel-2和HLS时序数据,采用掩码自编码器预训练,在洪水检测、作物分割等下游任务上表现出强大的少样本迁移能力 SatMAE(2022,Cong et al.):专门针对多时序遥感数据的掩码自编码预训练框架 GeoChat(2024):多模态遥感视觉-语言大模型
优势:一旦预训练完成,下游任务的数据效率极高,有望打破不同传感器之间的特征鸿沟。劣势:①预训练数据仍以光学遥感为主,缺乏与地面传感器(涡动塔、土壤探头)的系统性对齐;②对于需要高精度物理量反演的任务(如精确碳通量),表征学习的物理一致性难以保证;③预训练算力门槛极高,对生态领域的小团队不友好。
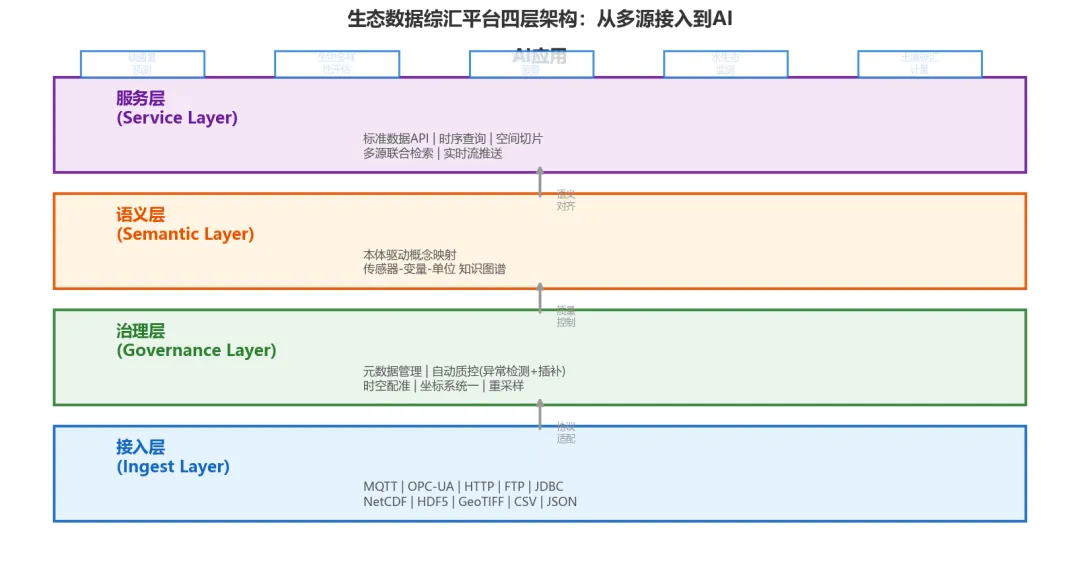
路线D:数据综汇平台——先把"采集-监测-分析-汇交"闭环跑通
这是当前最务实的工程路线。核心思路并不复杂:先建立一个统一的综汇平台,把多源生态数据的采集接入、实时监测、基础分析、数据汇交这几个环节连成闭环,让各类传感器数据能够进入同一个系统进行管理。这听起来简单,但在生态监测领域,能把这件事做扎实并不容易。
当前业界已有团队在交付这类平台的可用版本。以其实际架构为例,典型包含:
台站管理层:管理跨区域、跨生态系统的数十个监测站点,覆盖涡动塔、气象站、声纹采集器、物候相机、水质浮标等多种设备类型,实时展示仪器运行状态(正常/告警) 数据接入与处理层:实时数据流接入,支持原始数据浏览(数据/图表双模式)、涡动协方差数据处理、物候图像计算、数据归档等专项功能 分析工作台:提供多源数据对比分析、交互式查询、主题分析等基础分析工具 数据资产层:报表模板配置、指标管理、数据汇交输出——帮助运维团队把分散的监测数据汇总成标准化报表
优势:解决生态监测最紧迫的实际问题——多站点分散数据的统一管理和呈现,让运维人员不必在多个系统之间来回切换。数据汇交能力也直接服务于项目验收和成果输出的刚需。劣势:目前此类平台在AI驱动的智能分析方面尚处于早期阶段,更多价值体现在"让数据可见、可管、可汇"的工程层面。
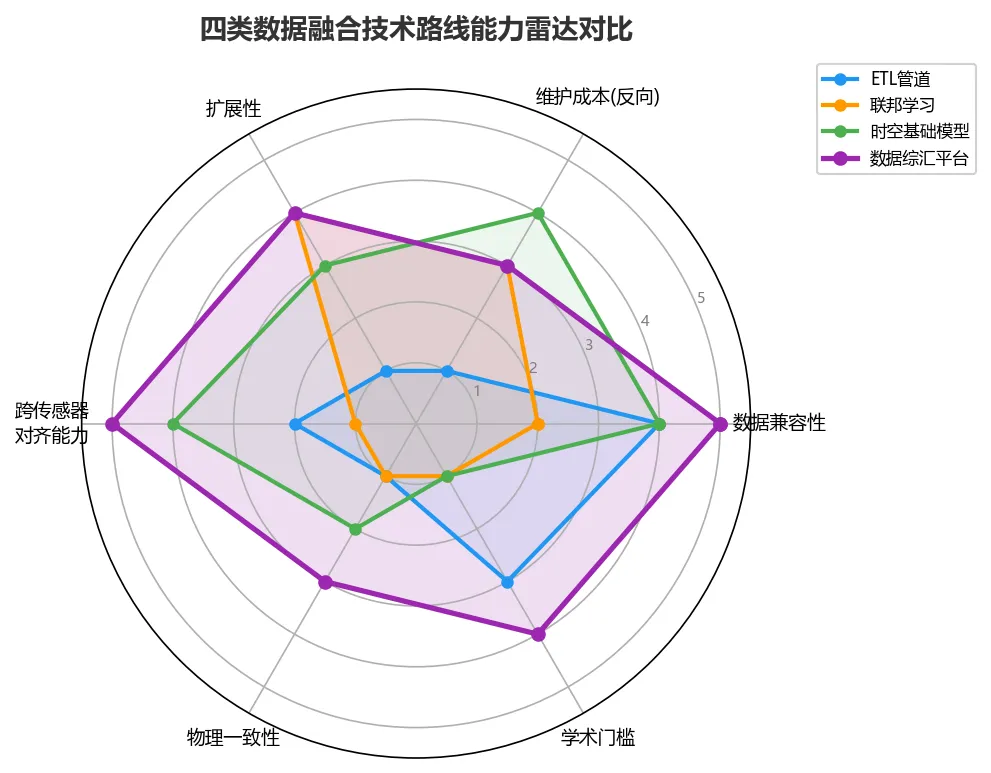
四条路线一字排开,差距在哪里? 路线A-C本质上都属于"上层建筑"——它们假设数据已经在某种程度上有秩序了。路线A假设你能定义通用Schema(但生态数据恰恰拒绝标准化),路线B假设数据孤岛之间有足够好的内部分布(但生态站点的异质性远超联邦学习假设),路线C假设预训练就能自动学完跨传感器对齐(但对需要物理量精度的那类任务显然不够)。路线D的不同在于,它不假设数据已经整齐,而是从最脏最乱的起点开始解决问题。 下面用一个真实场景来展开这个差别。
四、为什么数据综汇平台是务实的第一步
前三条路线为什么都离落地还有距离?让我们用一个真实场景来说明。
场景:你管理着一个跨5个省份的涡动通量监测网络,有30个站点、100+台仪器——包括涡动相关系统、自动气象站、土壤温湿度探针、物候相机、水质传感器等。数据每天都来,但分散在不同系统里:有些存成CSV在本地电脑上,有些通过4G传到FTP,有些还在巡检人员的U盘里。
这就是当前大量生态监测工作的真实状态。而路线D(数据综汇平台)要解决的,就是这桩"能看见但管不起来"的日常难题。
具体来说,一个实际的综汇平台首先解决的是这些基础设施层的问题:
统一站点与设备管理:把所有站点和仪器纳入一个系统,实时状态可视——哪些在线、哪些告警、哪些数据在持续入库,一目了然。不再需要登录5个不同的系统去查不同站点的数据。 数据采集与实时接入:支持涡动、气象、物候、声纹、水质等多种传感器的数据接入,提供实时数据浏览与数据图表智能切换。 数据归档与汇交:自动归档历史数据,按站点和指标生成标准化报表,支持数据汇交输出——这是项目验收和成果管理的刚需。 基础分析工具:多源数据对比分析、涡动协方差数据处理、物候时序计算等——不是高级AI,但能覆盖日常运维中的高频分析需求。
这个定位或许不如"AI数字孪生"性感,但它解决的是真实存在的痛点:让散落在各地的生态监测数据不再沉睡在硬盘里,而是真正进入可管理、可查询、可呈现的状态。而这恰恰是未来更高级AI应用的基础——如果数据都没被管起来,所有关于AI的讨论都停在纸上。
五、生态AI中的数据综汇:三个关键技术细节
细节一:时序对齐中的"边界效应"
多源时序对齐中有一个容易被忽视的问题:不同数据源的时间戳代表的含义不同。
涡动协方差塔的30分钟均值,通常标注的是时间段的结束时刻(例如"09:30"表示09:00-09:30的均值)。ERA5再分析数据的每小时值,标注的是时间段的起始时刻("09:00"表示09:00-10:00的均值)。MODIS的16天合成产品,标注的是合成窗口的第一天。
如果不处理这种时间语义差异,直接用标注时间戳对齐,会引入30分钟到16天不等的系统性时移。在碳通量这种对时间高度敏感的应用中,这种时移会导致日变化模式的错位,进而使模型把"本来没有关系的两件事"学成了相关的。
正确的做法是为每种数据源定义显式的temporal_convention元数据字段,在对齐时按照统一的"区间中点"规则进行重采样。
细节二:空间不确定性的传播
每种数据源都有其内在的空间不确定性:MODIS 500m像元对应地面250000平方米的混合信号;涡动塔的足迹模型本身有±15%的不确定度;GPS授时的地面传感器位置有±3m误差。
当这些数据被融合用于训练AI模型时,这些空间不确定性会线性叠加并向模型预测传播。忽略这种传播,会导致模型在异质性高的区域系统性低估预测不确定度——即模型"过于自信"。
不确定性传播的正确处理方式是采用贝叶斯融合框架:
其中每个似然项 都包含对数据源 的测量不确定性的明确建模。这个框架在Gaussian假设下退化为经典的卡尔曼滤波(时序融合)或最优插值(空间融合),是气象数据同化领域几十年来验证的成熟方法。
细节三:数据"孤岛效应"的组织根源
最后一个常被技术人员忽视的维度:数据孤岛不只是技术问题,更是组织问题。
中国的生态环境监测数据分散在生态环境部(大气/水/土)、自然资源部(遥感/土地)、气象局(气象/气候)、科学院(野外台站)、高校(科研站点)等多个系统,各自有不同的数据归属权和共享机制。
一个纯技术的数据融合方案,如果无法解决数据归属确认、访问授权管理、数据共享协议这些组织层面的问题,最终会发现:管道都建好了,但数据没有人授权来接。
因此,真正有效的数据综汇方案必须同时解决技术层(格式/协议适配)和机制层(权限管理/溯源审计/共享协议)两个问题。
六、AI应用的三个典型"数据瓶颈"案例
上面讨论了三个技术细节。你可能会觉得"这些问题确实存在,但真有那么严重吗?"下面就用三个真实AI应用场景中的翻车案例来回答——每一个案例失败的根因,都可以追溯到前面讨论的技术或组织瓶颈。
案例一:碳通量基础模型的跨站泛化困境
在碳通量大模型的研发中,一个反复出现的问题是:模型在训练集站点上表现优异(R² > 0.85),但在迁移到新站点时性能骤降(R² < 0.50)。
根本原因往往不是模型架构问题,而是不同站点的输入特征分布存在系统性偏移——有的站点缺少部分辅助气象变量(用气候格网数据插补),有的站点的土地覆盖类型与训练集站点差异显著,有的站点的传感器高度不同导致footprint代表性不同。
这些"隐藏的分布差异"如果不在数据层面显式建模和补偿,模型就会把它们当作噪声,训练时忽略,但在测试新站点时被放大成系统误差。解决方案是:在数据综汇层引入站点元数据(高度、下垫面类型、气候带)并进行显式特征归一化,让模型看到的不是"原始测量值",而是"考虑了站点背景差异后的标准化观测"。
案例二:森林防火模型的时序断点问题
AI森林防火预测模型依赖多源实时数据流:卫星热点(MODIS/VIIRS,每日两过境)、气象格网(每小时更新)、闪电定位(近实时)、人为活动指数(日频更新)。
在一次复盘分析中发现:当某一路数据流出现延迟(如气象局接口超时)时,模型没有感知到这种缺失,仍然用"上一时刻的历史缓存值"填补,导致预测结果看起来正常但实际基于了数小时前的过时气象信息——在快速变化的大风低湿天气中,这种4小时的时间延迟足以使火险等级的判断从"中"跳到"极高"。
这个问题需要在数据综汇层引入数据鲜度感知(Data Freshness Awareness)机制:每条进入AI模型的数据必须携带时效性元数据,当某路数据超过时效阈值时,模型收到的不是"填补值",而是"缺失标记+时效超期警告",以便做出相应的不确定性放大处理。
案例三:涡动观测数据的自动质控误杀
涡动协方差观测中有一个已知的问题:降雨期间传感器信号会被雨滴干扰,但雨后的短暂恢复期内,大气湍流结构异常,部分数据虽然能通过简单的物理阈值检验,却实际上代表不了真实的碳通量状态。
传统质控方案会漏掉这段"看起来合格但实际异常"的数据,导致碳汇/碳源的日总量估算出现系统偏低。
更好的方案是在质控层引入降雨事件的上下文感知:当雨量计检测到最近2小时有降水时,对涡动数据的质控阈值做动态收紧,并对雨后6小时内的数据打上特殊标记,让下游模型决定是使用这段数据还是增大其不确定权重。
这些案例说明了一个核心道理:数据问题不是"把数据堆在一起"就能解决的——它需要系统性地在平台层做处理,而不是让每个AI项目各自对付。没有数据层面扎实的基础设施,再精巧的AI模型也只是纸上谈兵。
那么问题来了:既然数据基础设施如此关键,到底谁在做这件事? 下面把视角从"问题"切换到"行动者"——国际上早已有先行者,国内也有团队在交付实际可用的系统。
七、产业格局:谁在做这件事?
国际上,生态数据融合的基础设施建设已有多个先行者:
ICOS(Integrated Carbon Observation System):欧洲碳观测基础设施,覆盖欧洲180+通量站(16个国家),建立了严格的数据质控和标准化流程,数据可通过Carbon Portal统一访问。ICOS的成功经验证明:标准化基础设施可以把单站数据的可用性从约40%提升至85%以上。
NEON(National Ecological Observatory Network):美国国家生态观测网,在全美81个站点部署了统一的传感器体系和数据采集协议,所有数据通过统一API发布。NEON最大的价值不是数据量,而是数据的一致性——研究者不需要为每个站点单独开发数据解析器。
Google Earth Engine(GEE):从另一个角度解决问题——不是规范化地面数据,而是把海量多源遥感数据的访问、处理、融合能力云端化。GEE的成功证明:基础设施层面的能力共享,可以把遥感应用的门槛降低两个数量级。
在中国,这个方向正处于关键的建设窗口期。"十五五"期间,5万个监测点位的数据将以前所未有的速度产生,如果没有高效的数据管理基础设施,海量数据将很快变成运维团队的噩梦——找数据比分析数据花更多时间。
国内已有若干团队在交付可用的数据综汇平台。以雨根科技的"云枢智汇系统"为例:该系统已在实际项目中运行,管理着覆盖北京、新疆、青海、海南、神东等多区域的30余个生态监测站点,涉及涡动协方差、自动气象、物候成像、鸟类声纹、土壤墒情、水质浮标、植物生理、径流观测等多种监测类型。
以下是该系统的真实运行界面(演示账号数据),我们逐一过一下每个核心模块的实际形态:
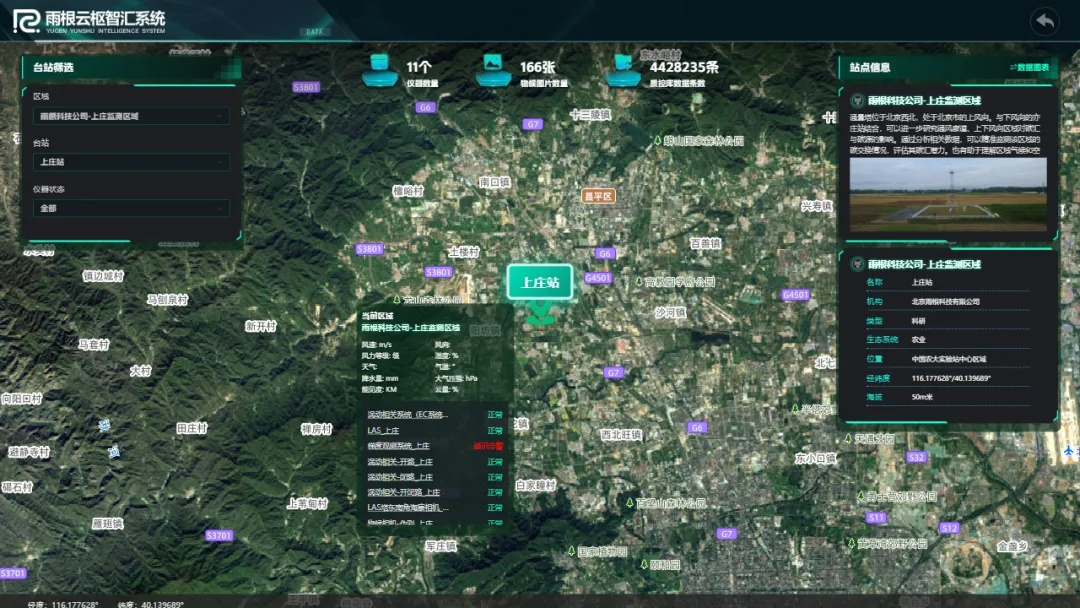
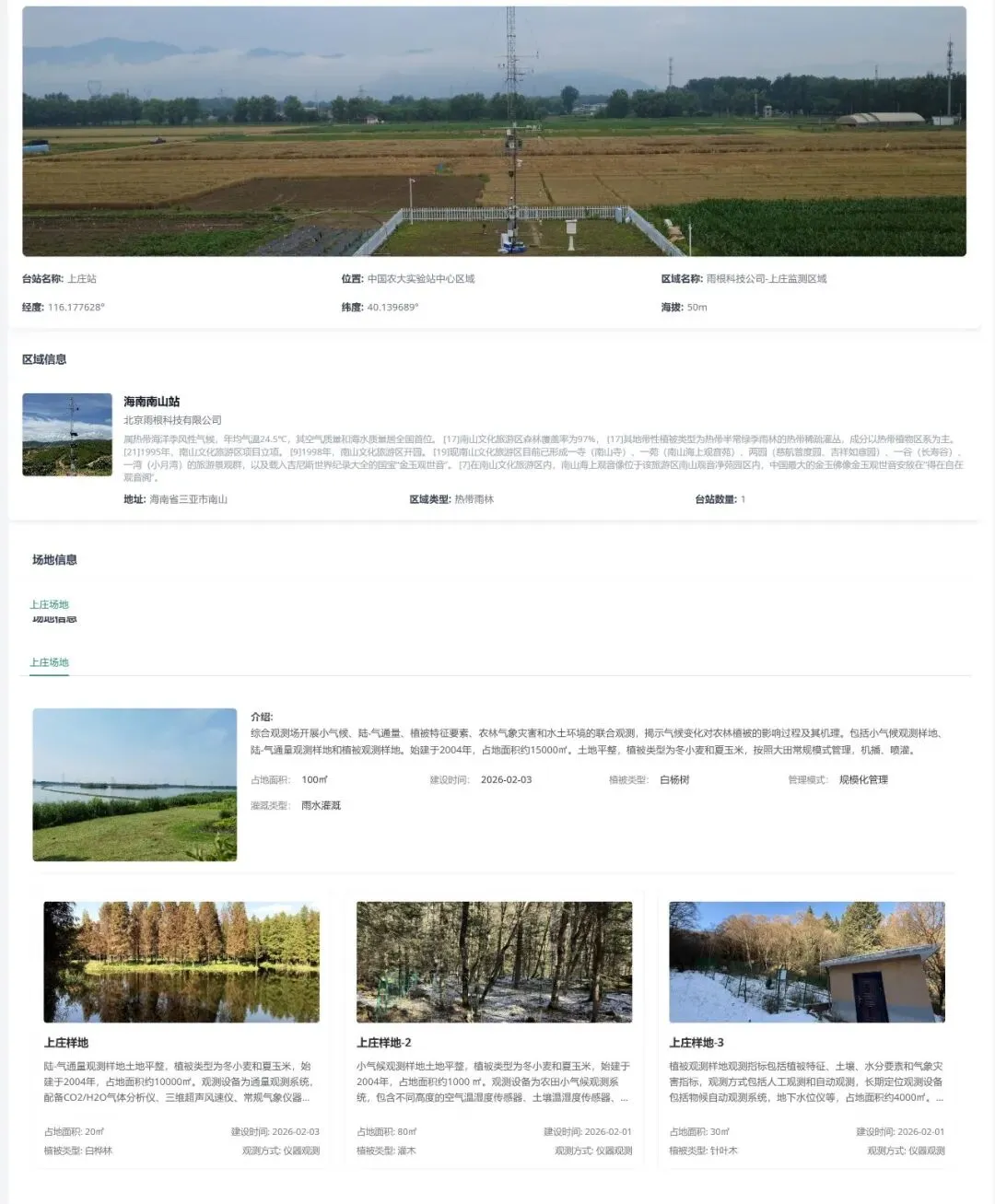
① 数据一张图:一目了然的站点全景
登录后首页即是"数据一张图"大屏。所有站点在卫星底图上标注,左侧可按区域/站点层级筛选,右侧面板展示选中站点的详细信息(坐标、面积、类型等)。首页顶栏直接给出了核心指标:11台仪器在线、166张植被图片已入库、442万+条质控后数据。运维人员不再需要逐个系统翻数据——在这张图上就能判断哪里数据正常、哪里需要派人现场维护。
② 台站管理:跨区域站点与设备统一台账
将所有台站和仪器纳入一个管理系统。从下方截图可以看到,台站类型覆盖森林防火、红树林湿地、土壤观测、鸟类声纹、水质监测、气象、径流小区等广泛场景。
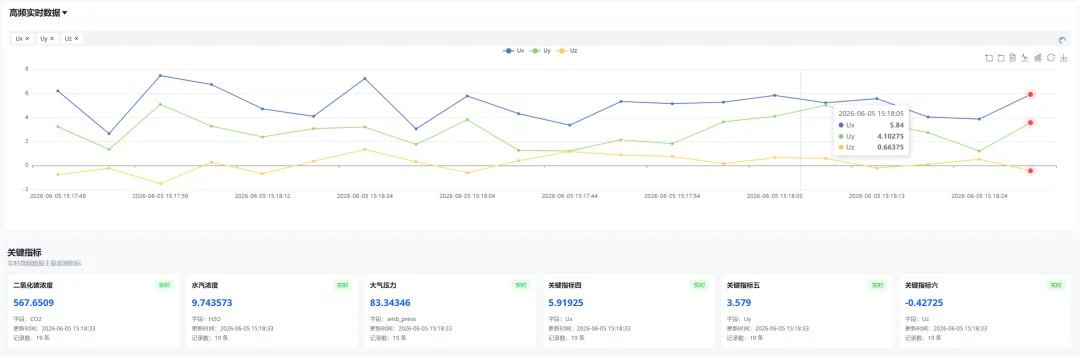
③ 实时数据接入:多源传感器汇聚可视
这是系统的数据入口——涡动、气象、声纹、物候、水质等多种传感器的原始数据在此汇聚。界面左侧为台站/区域选择面板(树状结构),主区域支持数据表格与实时图表双模式切换。选定站点和仪器后即可查看原始观测序列,是数据确认和异常巡检的高频入口。
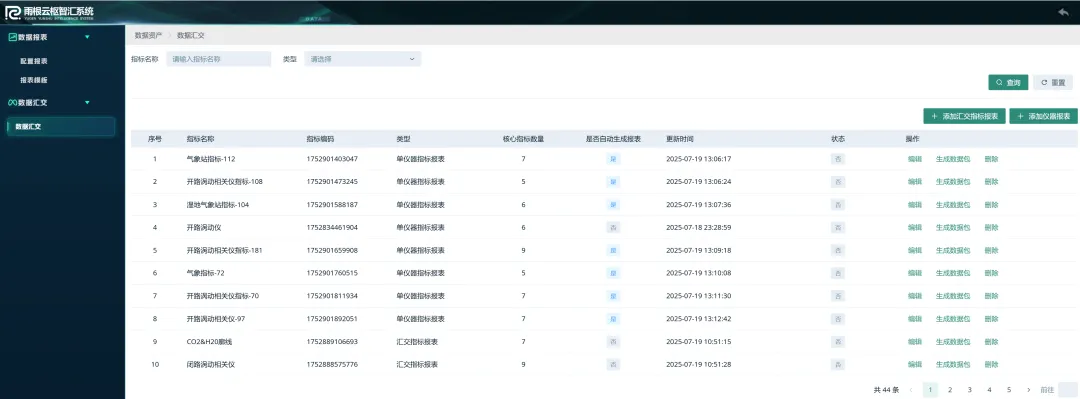
④ 数据资产与汇交输出
对于项目运维团队来说,"能把数据汇成交付要求的格式"往往比"能看图表"更关键。数据资产模块支持按站点和指标配置报表模板,提供标准化数据汇总输出,直接服务于项目结题验收和成果上报的硬需求。从下方界面可以看到,系统按指标分类组织数据(水体、土壤、气象、生物等),支持多维度报告生成。
⑤ 系统入口页:五大模块一目了然
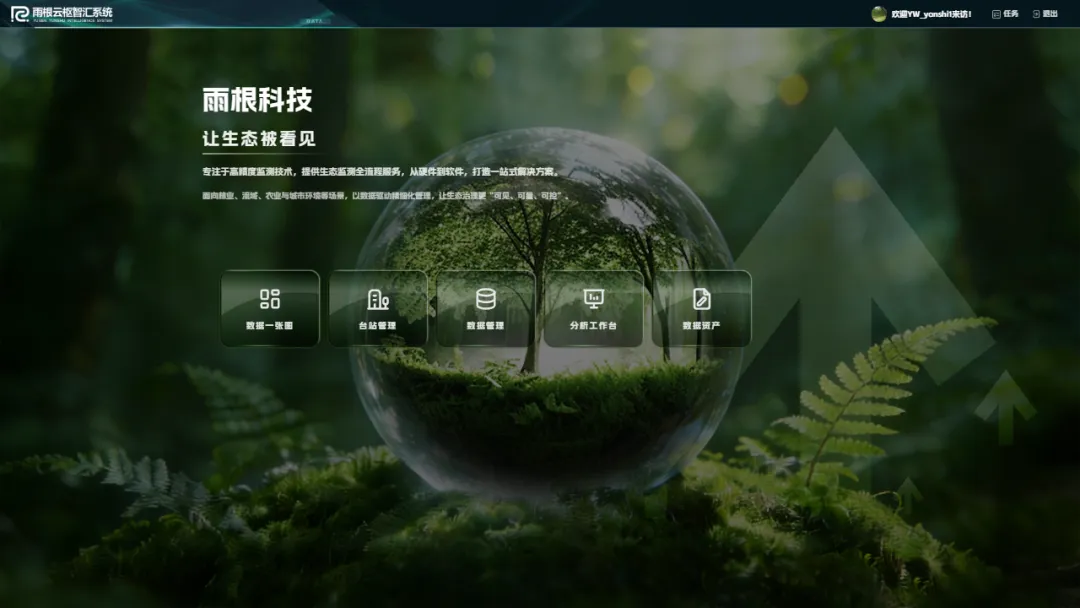
数据一张图、台站管理、数据管理、分析工作台、数据资产——每层对应不同的运维角色。这种清晰的模块划分使得不同岗位的人员可以各取所需,而不用在复杂的菜单树里迷路。
这个系统不是AI大模型,也不是数字孪生——它就是一套让生态监测数据从"散落各处"到"汇聚管理"的基础设施。但从上面这些截图可以看出来:它已经解决了生态监测中最根本的"可见性"问题——站点在哪、设备在不在线、数据有没有进来、质控状态如何——这些都是上层AI应用"有数据可喂"的前提条件。
八、未来图景:从"数据管起来"到"数据用起来"
看了上面的截图,你可能会问:这不就是数据管理工具吗?AI在哪里?
这正是关键所在:AI需要数据,但数据不先管起来,AI连门都进不去。 上面的系统演示清楚地说明了一个事实——当前阶段,数据综汇平台的核心价值是解决"可见→可管→可汇"的问题。11台仪器、442万条质控数据、30+跨区域站点——如果你连这些基础的事务都没做好,谈AI是奢侈的。
当前阶段,数据综汇平台的核心价值是解决"可见→可管→可汇"的问题。拿实际运行的平台来说——30+站点、数十种传感器类型、数百万条质控数据——如果你连这些数据在哪儿、状态怎么样、格式是否统一都搞不清楚,谈AI就是奢侈的。
下一阶段才是"可量"——在数据基础打牢之后,可以逐步引入:
跨站点的数据一致性分析 基于历史模式的异常自动检测 多源数据的预对齐和特征工程自动化
再下一步才是"可控"——让AI模型在可靠的数据底座上发挥作用:精准碳通量预测、智能森林火险预警、生态状况的自动化诊断。
这不是一蹴而就的事。ICOS和NEON花了十年时间建基础设施,GEE也是迭代了数年才达到今天的规模。务实的态度是:先把数据管起来这件事做扎实,再谈AI怎么用。

结语:先把数据管起来,再谈AI
回到文章开头那个困扰工程师的怪题。
AI模型从来不是生态应用落地的主要瓶颈——真正卡脖子的,是原始数据散落各处、未被有效管理和组织的状态。在生态AI能跑出令人信服的结果之前,首先要有人去做"把数据管起来"这件费力但未必讨好的工程工作。
这个定位很朴素,但也很真实。一个能覆盖30+站点、对接涡动/气象/声纹/物候/水质/土壤等十余种传感器的综汇平台,它的价值不在于做了多么炫酷的AI,而在于让这些数据不再沉睡——可看见、可管理、可汇交、可追溯。做好了这些,AI模型才有真正的用武之地。
"十五五"期间,当5万个监测节点开始同时产生数据,把数据管好的能力,将决定中国生态AI的起跑线在哪里。
你在生态数据管理方面遇到过哪些令人头疼的实际问题?欢迎在评论区分享,我们一起讨论。
参考资料:
Pastorello et al., "The FLUXNET2015 dataset and the ONEFlux processing pipeline for eddy covariance data," Scientific Data, 7(1), 225, 2020. McMahan et al., "Communication-efficient learning of deep networks from decentralized data," AISTATS, 2017. Jakubik et al., "Foundation Models for Generalist Geospatial Intelligence (Prithvi-100M)," arXiv, 2023. Kljun et al., "A simple two-dimensional parameterisation for Flux Footprint Prediction (FFP)," Geoscientific Model Development, 8(11), 2015. 国家生态环境监测"十五五"规划媒体说明,新华社,2026年4月27日. 《我国生态环境监测体系持续向数字化智能化转型》,中国政府网,2026年5月6日.
