 夜雨聆风
夜雨聆风本文记录了我从最初的编译失败,到在无数依赖地狱中挣扎,最终找到本地AI最佳工作流的完整历程。这不是一个工具评测,而是一篇关于“如何驯服一个强大的开源引擎”的生存指南。
序章:本地AI的诱惑与现实的残酷

当本地大模型(LLMs)的性能被展示出来时,我像所有技术爱好者一样,被其“数据私密性”和“无限潜力”所吸引。我的目标是:在我的 RTX 4060 笔记本上,构建一个既高效又完全私有的AI工作站。
然而,现实很快给我泼了一盆冷水。从一开始的“极客范”出发,我发现本地AI的门槛,远比想象中高得多。
阶段一:底层引擎的“冰冷”与阻碍(Step 0 & 1)
我从最底层的性能基石——llama.cpp 开始。理论上,这是最纯粹、最轻量、最可控的选择。
第一次打击:环境不兼容的噩梦。

我的第一次尝试是灾难性的。版本不一致、本地显卡驱动与编译环境不匹配、VS Studio 等必备工具缺失……在命令行里反复输入参数,得到的只是冰冷的编译错误。GPU加速的梦想,在最基础的配置阶段就破灭了。
即使最终成功编译,我发现 llama.cpp 本身提供的 llama-ui 客户端,也只是一个基础的聊天框。它解决了“能不能运行”的问题,但彻底忽略了“能不能高效使用”的问题。它没有记忆、没有高级的 Prompt 管理,更像是一个工业级的计算器,而不是一个生产力工具。
战术调整:我意识到,在环境配置上耗费时间是不可持续的。 我决定放弃从源码编译的硬仗,转而使用预编译的动态连接库(Dynamic Libraries)版本,以最快的速度跳过编译环节,将精力集中在“如何使用它”上。
结论:性能是极致的,但体验是割裂的。 我需要一个“翻译官”,一个能把底层性能转化为高级交互的界面。
阶段二:依赖地狱的陷阱(Step 2)

被界面困扰后,我转向了寻找一个“集成”方案。我选择了 WebOpen,一个声称能提供全功能Web界面的解决方案。
然而,这让我撞上了开源软件最残酷的现实:依赖地狱。
open-webui 基于 Python,而我的系统环境是 Python 3.13。而它却需要一个特定版本的 Python 3.11。我陷入了版本冲突的噩梦,每安装一个依赖,就伴随着另一组冲突的报错。我花费了数小时,不是在配置 AI,而是在和 Python 的包管理器搏斗。
我最终放弃了。 我意识到,试图在“零配置”的前提下,用“模块化”的方式去解决问题,本身就是一种悖论。
阶段三:从“万能药”到“完美搭档”(Step 3 & 4)
在彻底放弃“自己搭建全栈”的绝望状态下,我转向了市场上的主流桌面应用——LM Studio。
LM Studio 的魅力: 它是一个完美的“降维打击”。它将复杂的 Python 环境、CUDA 依赖、GGUF 模型格式、服务器配置,全部打包成一个 .exe。我只需要点几下鼠标,就能从搜索模型到启动本地 API。它解决了我的第一大痛点:环境配置的痛苦。
我本以为,LM Studio 就是我的“桌面救赎”。
但,真正的挑战才刚刚开始。
阶段四:性能的陷阱与崩溃(Step 5)
我将 LM Studio 作为我的主力,享受了它带来的流畅体验。但随着我开始进行严肃的工作——比如长篇代码生成、复杂的多轮对话、跨文档的上下文理解时,问题浮现了:
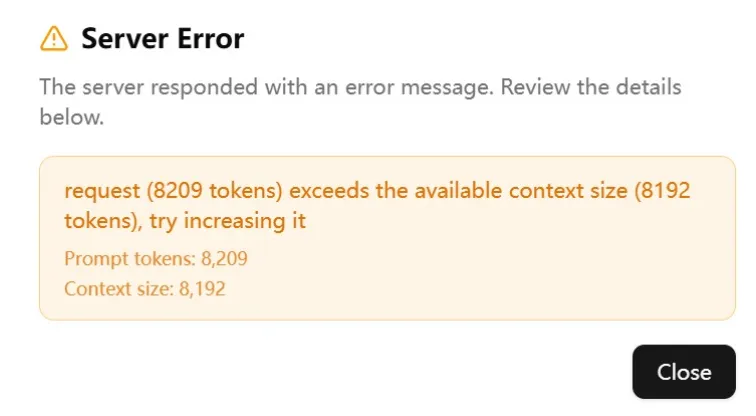
多轮对话崩溃(Context Drift):在长对话后,模型开始出现上下文漂移,忘记早期的指令和关键信息。
词语无限重复(Repetition Loops):模型陷入循环,重复生成某些词汇或短语,导致生成结果无法使用。
乱码与输出不稳定:在某些参数配置下,输出的 token 出现了明显的乱码或格式错误。
我意识到,LM Studio 提供了极好的 “使用体验”,但它在 “底层的参数可控性” 和 “稳定性” 上,存在着封装带来的妥协。它把所有复杂性都隐藏起来了,但也因此隐藏了问题的根源。
这让我完成了认知上的升华:真正的“救赎”,不是一个万能的封装,而是一个能让我理解并控制底层逻辑的系统。
阶段五:最终的哲学与实践(Step 6)
我终于回到了最开始的哲学思考:我需要一个性能极致的后端,搭配一个高级且稳定的前端。
我决定放弃“一站式”的诱惑,选择 llama.cpp 作为性能的基石,然后使用像 Cherry Studio 这样专注于提供顶级用户体验的第三方客户端作为“适配层”。
这个组合的意义在于:
性能:我获得了
llama.cpp级别的原生速度和最低开销。体验:我获得了
Cherry Studio提供的精美 UI、高级对话管理和流畅的交互。控制:我保留了对核心参数(如上下文长度、温度、Top P 等)的细致调整能力。
这才是真正的“桌面救赎”:不是一个软件,而是一个由高性能引擎和顶级前端构成的“工作流”。
1、llama.cpp作为推理引擎
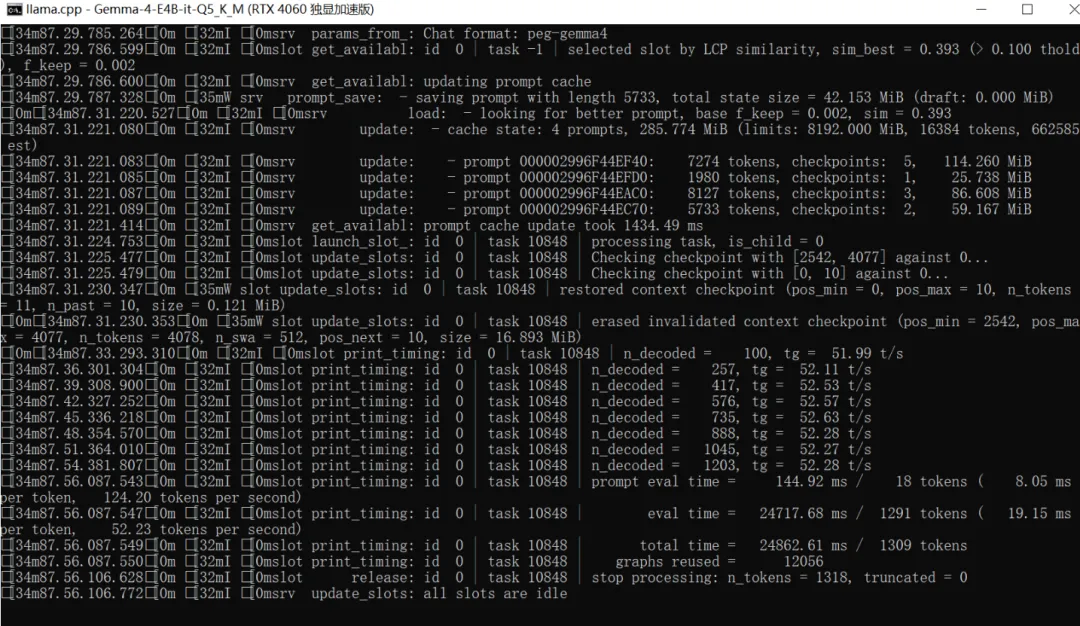
2、Cherry Studio 交互界面
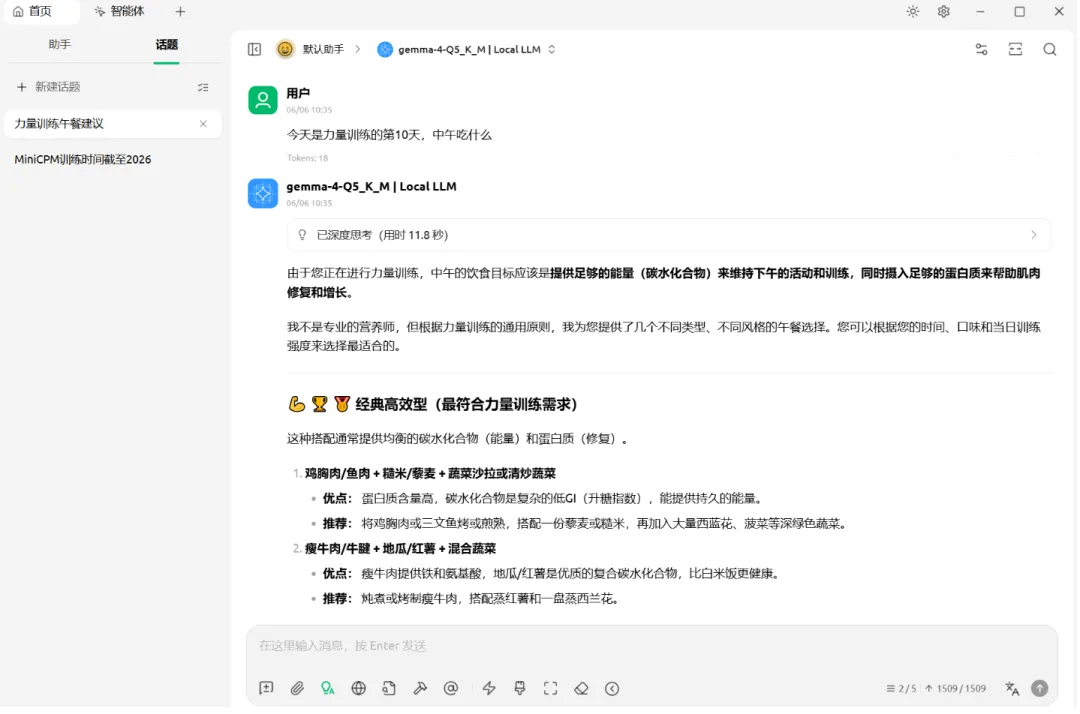
💡 给所有挣扎在配置中的你:我的六个生存指南
我的四十八小时,教会了我本地AI的六个核心真理。如果你正在经历我的痛苦,请参考以下指南:
1. 告别“一键式”的幻想
不要被“开箱即用”的宣传所迷惑。如果你的目标是生产力、追求效率,那么你需要理解工具的底层逻辑。性能和体验的平衡,往往需要你亲手去调整。
2. 优先解决“基础环境”问题 (Step 0)
在追求 UI 之前,先确保你的编译环境是健康的。如果 llama.cpp 连最基本的 GPU 加速都做不到,那么所有上层的 UI 都是空中楼阁。先跑起来,再优化。
3. 谨慎选择“依赖型”方案 (Step 2)
对于复杂的 Web 或 Python 依赖方案,请务必在开始前做好环境隔离(如使用 Conda 或 venv)。如果项目依赖太重,它会成为你最大的时间黑洞。
4. 了解工具的“本质” (LM Studio vs. Cherry Studio)
LM Studio:适合“快速尝鲜者”和“小白用户”。它抽象掉了所有复杂性,帮你走完第一步。
专业客户端:适合“专业工作者”和“深度使用者”。它用优秀的 UI 来承载底层引擎的全部潜力,它在“优化体验”上比“抽象配置”更进一步。
5. 驯服模型的“病症” (Step 5)
当模型出现“重复循环”、“上下文漂移”时,不要直接抱怨软件。去检查:
上下文窗口:你是否超出了模型的最大上下文长度?
参数:尝试调整
temperature(温度) 和repetition_penalty(重复惩罚)。这两个参数是解决重复问题的关键。
6. 本地模型选型原则:Q4_K_M 是你的“甜点”
在消费级显卡上,Q4_K_M 是兼顾质量与速度的最佳平衡点。它能让你在不爆显存的前提下,获得最流畅的体验。
结语:
本地AI的旅程,是一场从“代码层面的完美主义”到“应用层面的实用主义”的转变。它教会我,最好的工具,不是那个最复杂的,而是那个能让你最快、最稳定、最舒适地将技术转化为生产力的那个组合。
最终,我找到了我的答案:一个稳定的引擎 + 一个优秀的界面 + 对参数的理解。
