 夜雨聆风
夜雨聆风AI 编程工具用着爽,账单也爽。
所以有了省token的各种项目
但是一旦涉及省成本,通常意味着妥协了什么
调查下来,大部分方案在丢信息换节省
信息丢了,就可能犯错,犯错意味着返工,反而增加token消耗
不过也有不丢信息照样省的路子。
每一轮对话的 token 消耗其实分六层:
第一层:系统提示。 每轮必传,2000-5000 tokens。这一层几乎没人注意,但它是所有轮次的底座。
第二层:MCP 工具定义。 装了十几个 MCP 服务器的话,所有工具的完整 Schema 每轮都要加载。实测下来,未优化时可以吃掉 150K tokens——上下文窗口才 200K,光工具定义占 3/4。
第三层:探索代码库。 AI 接到任务后的第一件事是 Grep、Glob、Read 一路翻下去。一个中型项目,完整探索一遍几千到几万 tokens。
第四层:AI 的回复。 模型一边推理一边输出,很多时候推理过程比答案本身还长。有用量审计发现,超过一半的钱花在"没有工具调用的对话轮次"上——说白了就是废话太多,过度思考。
第五层:工具返回结果。 AI 执行完命令后拿回来的输出——git diff、test log、grep 结果。一个 git diff 动辄几千 tokens,一轮测试跑完的 log 可能上万。这一层是单轮里最大的消耗源之一,但经常和对话历史混在一起被忽略。
第六层:历史对话。 每一轮都把之前所有对话重新传一遍。聊了 20 轮之后,光历史就能占掉大半上下文窗口。
搞清这六层,省 token 的思路就自然出来了。砍哪一层、怎么砍,决定了方案的本质。
所有方案可以分成两大阵营:砍信息和靠缓存。

砍信息:用损失换节省
这一阵营覆盖了绝大多数方案。核心逻辑都是一样的:减少传给模型的信息量。
砍第三层——少读:别让 AI 翻箱倒柜
Repomix(⭐26K)最直觉:会话开始前把代码库打包成结构化摘要。AI 读摘要拿全局视野,不用逐文件翻。
Codesight(⭐1.1K)更进一步——用 AST 分析代码结构,生成带语义的索引。告诉 AI 每个模块干什么、谁依赖谁。探索阶段声称 7-12x 压缩,加上按需读取综合 91x。
Code Graph(⭐18K)最巧妙:先分析代码依赖图,只喂和当前任务相关的子集。改了一个函数,只送调用链上下游。实测压缩 38x 到 528x。
代价:静态分析会漏动态生成的代码。Codesight 的 benchmark 显示部分项目的路由检测准确率在 88-100% 之间。索引需要随代码更新维护,否则读到的是过期信息。
砍第四层——少说:管住 AI 的嘴
Caveman(⭐69K+)是目前最火的方案。在系统提示里加一条规则,要求模型回复极简(输出token你输入贵很多)。
原来:"The reason your React component is re-rendering is that you're creating a new object reference on every render..."(69 tokens)
Caveman 后:"New object ref. Wrap in useMemo."(19 tokens)
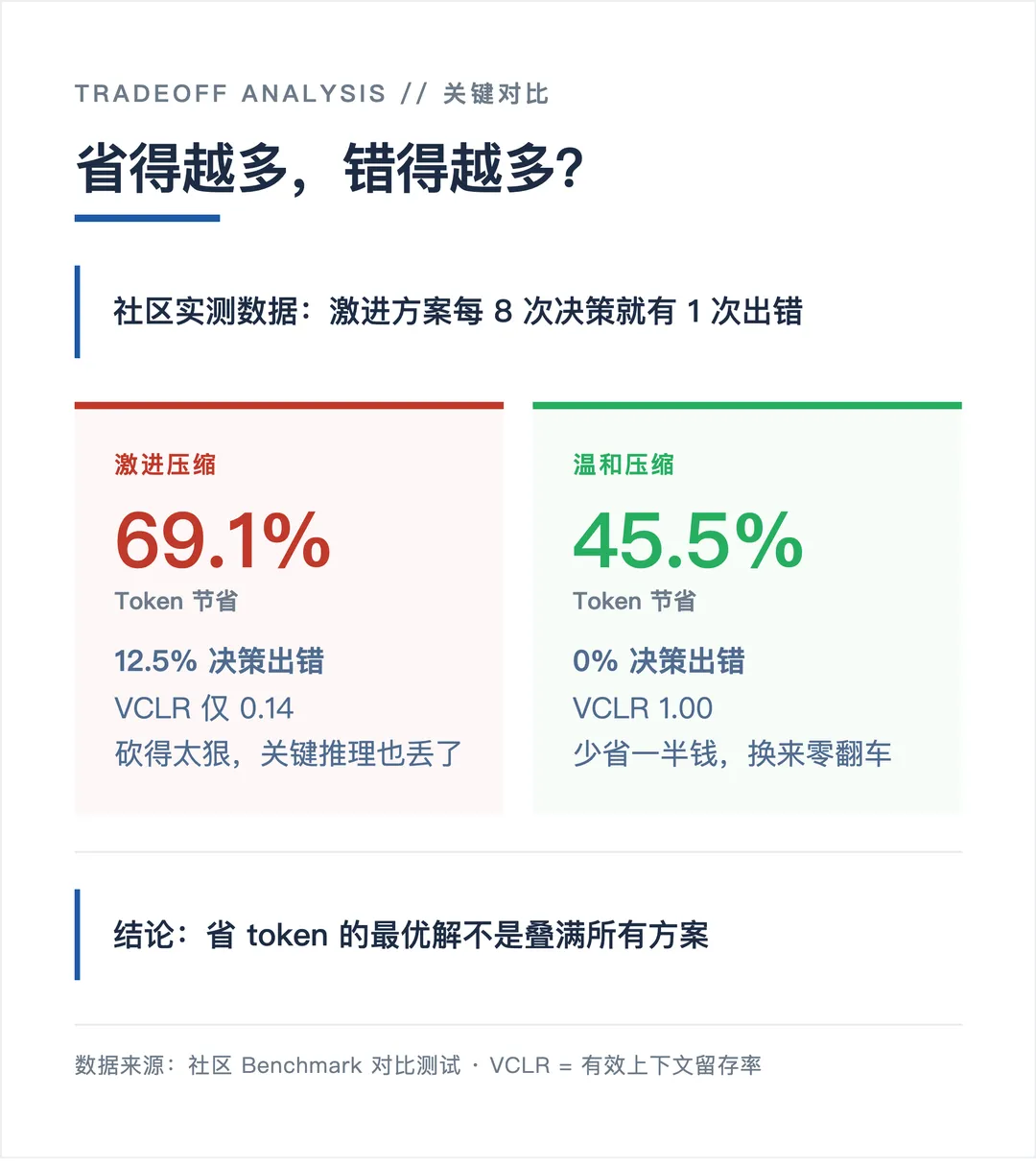
输出缩减约 65%(README 10 个 prompt 实测平均)。但 越激进的压缩,出错风险越高——有社区测试发现压缩后 AI 漏掉了关键的推理步骤。
OmniRoute(⭐5.8K)在网关层用免费模型做压缩,官方声称综合省 78-95%(基于两层压缩率的数学推算)。但免费模型压缩质量不稳定,关键时刻漏一句推理就废了。
核心矛盾:废话和关键推理挤在同一句话里,砍的时候分不开。
砍第二层——少加载:MCP 工具定义是隐藏大户
装了十几个 MCP 服务器,每次会话 AI 都要加载所有工具的完整 Schema。
解决方案:Claude Code 的 Tool Search 功能默认延迟加载 MCP 工具——只在 AI 主动调用时才加载完整定义。装了大量 MCP 的项目,这一步就能释放大量上下文空间。
mcp2cli(⭐2.2K)把 N 个 MCP 统一成一个 CLI 入口,省 96-99%。代价:AI 看不到完整工具描述,复杂参数传递受限。
砍第五层——截断工具输出
git diff 动辄几千 tokens,测试跑完的 log 上万。这些内容对决策有用,但 AI 往往只需要其中几行。
OmniRoute 的网关层压缩覆盖了这部分,在转发之前先截断。综合省 78-95%。代价和上面一样:免费模型截断质量不稳定,可能把关键报错信息也砍掉。
砍第六层——压缩历史
/compact 用 LLM 总结会话历史,压缩 80-90%。代价是丢早期细节。社区经验:主动 compact,别等快爆了才做。180K 再 compact,总结质量打折。
靠缓存:不丢信息照样省
上面所有方案都在丢信息。但有一个完全不同的思路:信息一个字不丢,照样把成本降下来。
DeepSeek-Reasonix(⭐18.5K)就是这个思路的代表。它不做任何压缩,而是把上下文分成三层:不可变前缀(系统提示 + 工具定义)、只追加日志(对话历史)、临时草稿区。
核心操作:保证前缀层永远不变。每次请求,前缀一模一样地传上去。大模型 的 Prompt Cache 一看"这个前缀我见过",直接命中缓存,不用重新处理。
结果:Cache 命中率最高达到 99.82%(项目方公布的真实用户单日数据)。信息零损失。
这个思路的本质:与其砍内容,不如让重复传输变便宜。 不是少读、不是少说,是让"读同样的东西"不再按原价收费。
Reasonix 是独立 Agent 框架,不能直接装在 Claude Code 里。
不是越省越好
两个阵营,两种哲学。
砍信息阵营的逻辑链:少传 → 省钱 → 但可能丢关键信息。砍得越狠,丢得越多。
靠缓存阵营的逻辑链:不砍 → 靠缓存机制降价 → 信息零损失。天花板是缓存命中率,取决于你的前缀有多稳定。
高性价比组合:优先靠缓存(固定前缀、别频繁切模型),再砍隐藏浪费(MCP 懒加载 + 主动 compact),最后适度砍探索成本(项目索引 + 依赖图)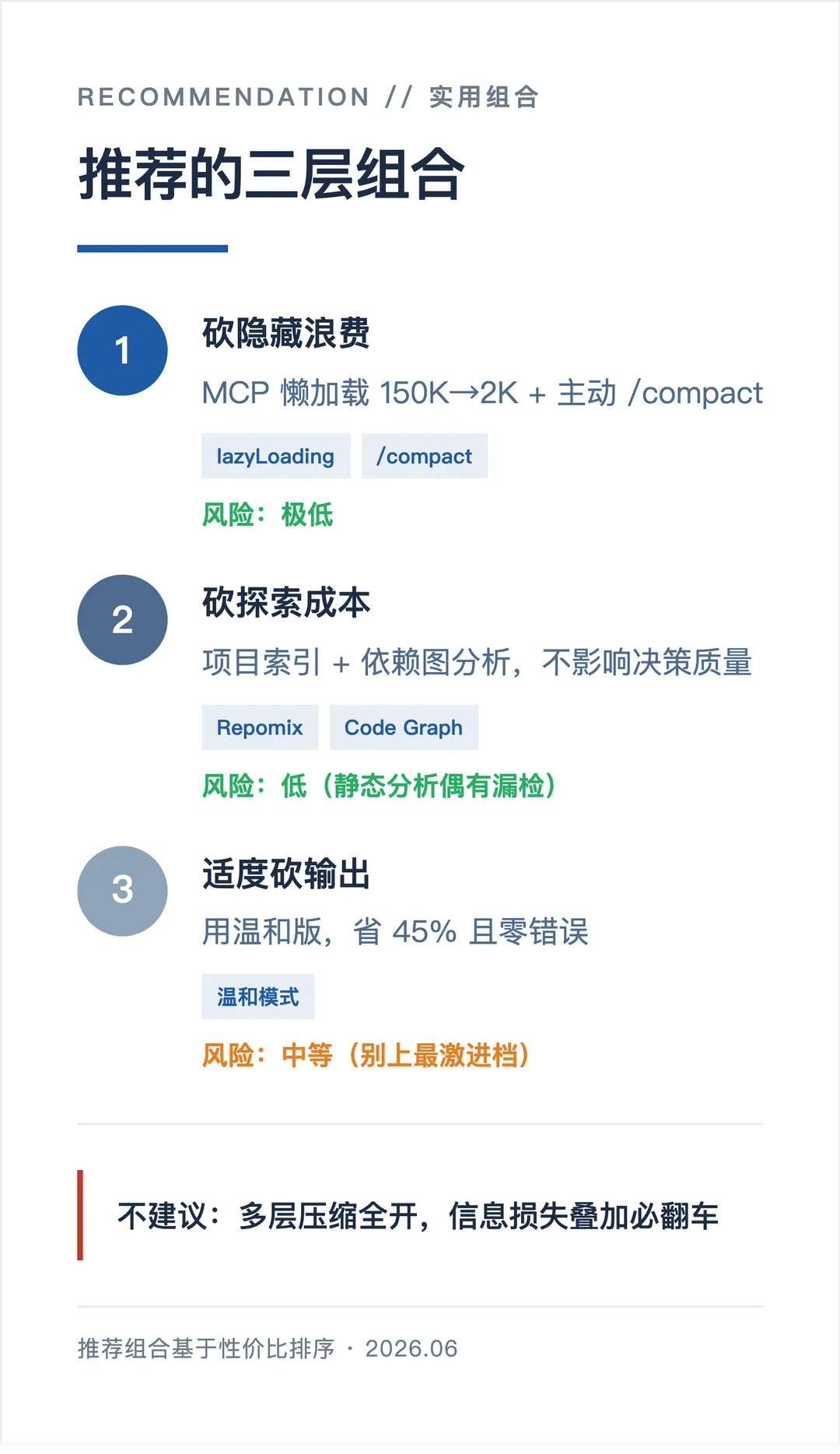
不建议:多层压缩全开。理论上省 90%+,但信息损失叠加,复杂任务几乎必然出问题。
关键项目:
- • Caveman (69K+): github.com/JuliusBrussee/caveman
- • Repomix (26K): github.com/yamadashy/repomix
- • DeepSeek-Reasonix (18.5K): github.com/esengine/DeepSeek-Reasonix
- • Code Graph (18K): github.com/tirth8205/code-review-graph
- • OmniRoute (5.8K): github.com/diegosouzapw/OmniRoute
- • mcp2cli (2.2K): github.com/knowsuchagency/mcp2cli
- • Codesight (1.1K): github.com/Houseofmvps/codesight
你在用哪个省 token 方案?踩过什么坑?评论区聊聊 👇
觉得有用,点个推荐让朋友也能看到。
