 夜雨聆风
夜雨聆风Datawhale干货
作者: 北大 OpenDCAI 团队
合成数据,已经正式成为大模型训练的核心口粮。
所有 AI 团队都在被同一个难题卡住: 公开优质数据越来越贵,垂直领域数据拿不到,能真正用来训练的高质量样本,永远不够用。 想做大模型、做行业适配、训练小模型,都必须找到稳定、可靠的新数据来源。
于是,让 AI 自己造数据,成了全行业的共同选择。 OpenAI 公开披露训练过程使用合成数据;Claude Opus 4.6 也纳入了 Anthropic 自研生成数据;英伟达更是在 2026 年两大技术大会上,将 “AI 工厂 + 虚拟世界合成数据” 列为核心战略。
问题也随之变得更尖锐:数据能生成,不代表数据有用。不少 AI 生成的合成数据,看起来格式工整、表达流畅、逻辑通顺,可真正用于训练后,模型效果可能不升反降。 Nature 研究早已警示过模型坍塌:如果模型反复训练自身生成的数据,长尾信息会逐步丢失,最终导致能力退化。
所以现在行业最需要回答的问题是:
不同 LLM、Agent、Workflow 产出的合成数据,到底谁真的能让模型变强?
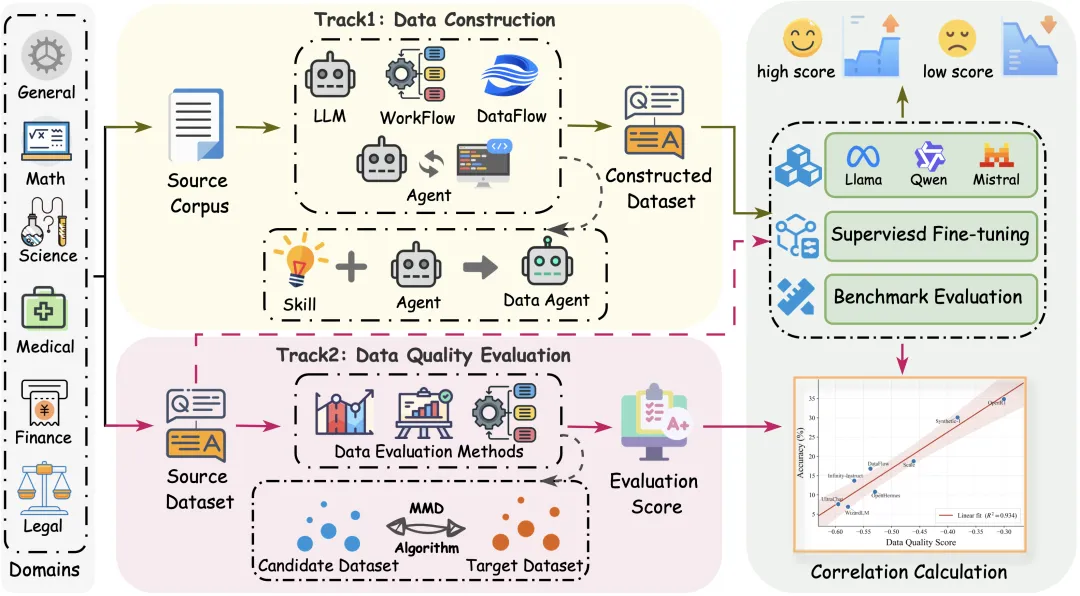
北大 OpenDCAI 团队最新开源的 DataPrep‑Bench,正是为解决这一问题而生。
它面向大模型数据准备全链路,实现从数据合成→筛选→最终模型训练效果的端到端完整评测,给 AI 造数建立一套可量化、可对比的硬核标准。给 AI 数据准备,量身定制了一套真正靠谱的 “高考标准”。
项目主页:https://datapreparationbench.github.io/开源仓库:https://github.com/haolpku/Data-Preparation-Bench论文:https://datapreparationbench.github.io/assets/DataPrep-Bench.pdf
一、评测成绩:没有全能状元,只有单科第一
DataPrep‑Bench 的这场AI 数据高考,最终成绩拆成两份成绩单:
第一份是造数据成绩单:量化不同 LLM、Agent、工作流生成的数据,对下游模型微调的真实增益;
第二份是考前估分榜:验证各类数据质量指标,能否提前预判数据的训练价值。
Track1:造数据成绩单,谁的数据训完更强?
如果把 DataPrep-Bench 的 Data Construction 评测看成是“AI 数据工厂高考”,这场考试里:
考场:不同底座模型,包括 Qwen2.5-7B 和 Llama-3.1-8B
科目:不同领域,包括 Math、General、Finance、Law、Medical、Science
考生:各种造数据方法,包括 DataFlow 工作流、直接让大模型生成、ReAct-style Agent、Data-Construction-Skill
成绩单:不是人工主观打分,而是用这些合成数据微调底座模型后,在下游 benchmark 上的真实分数
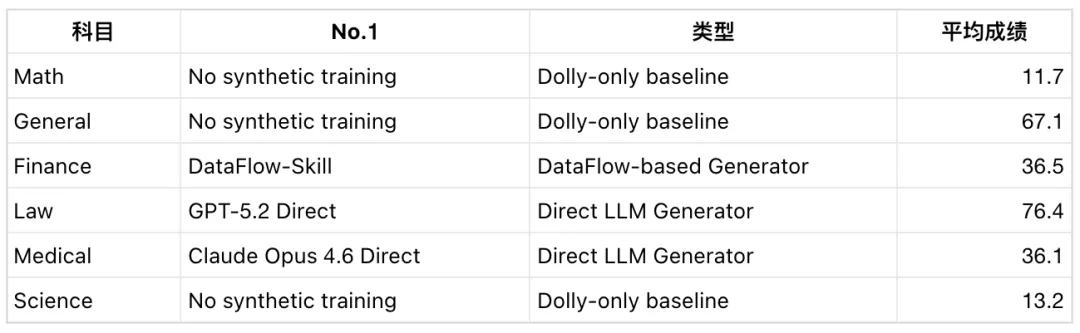
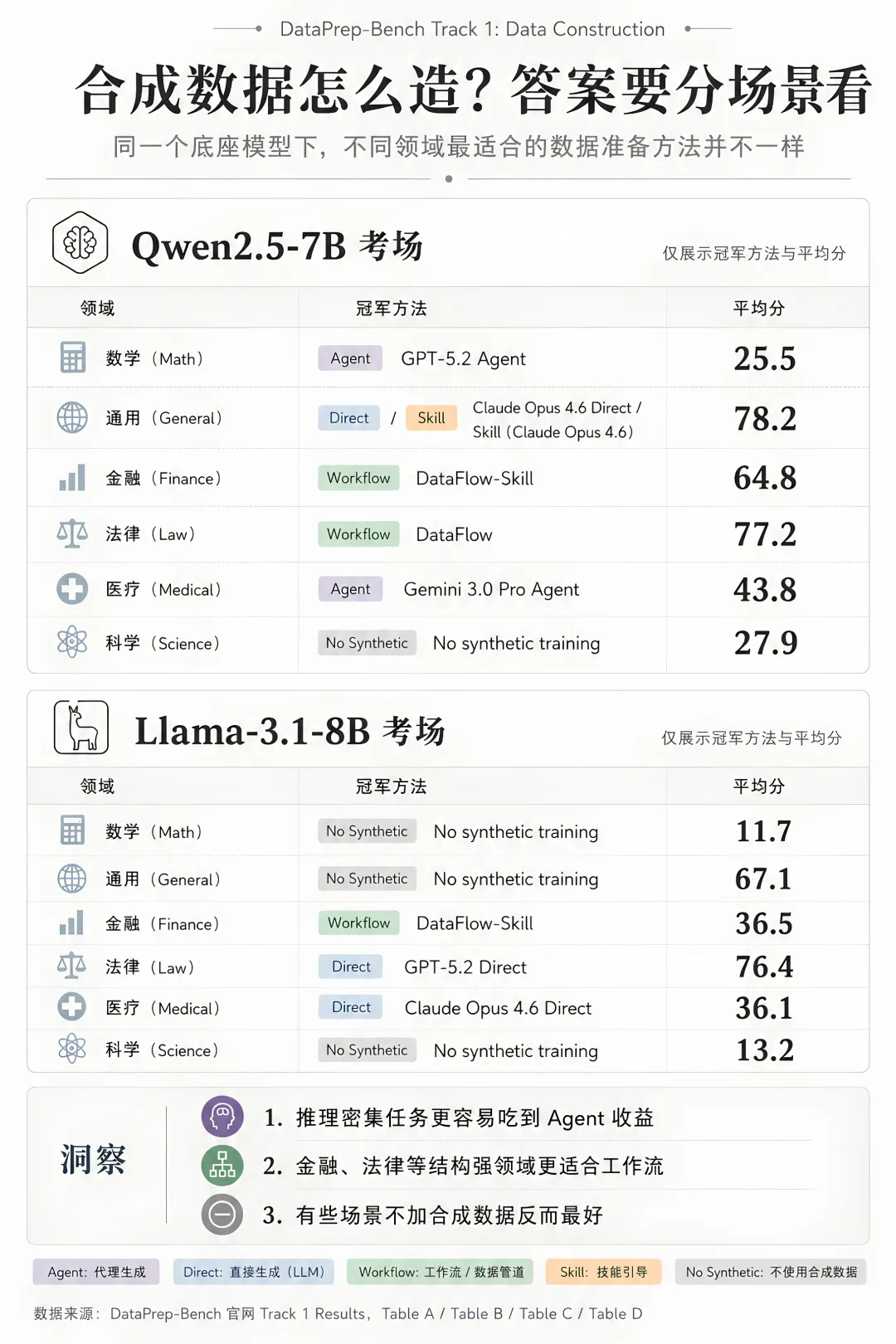
DataPrep-Bench 将每种造数据方法产出的 SFT 数据与 Dolly-15k 混合,然后训练 Qwen2.5-7B,再去对应领域 benchmark 上考试。结果很有意思:没有任何一个方法通吃所有科目。Agent 数学强,DataFlow 法律稳,金融看 DataFlow-Skill。
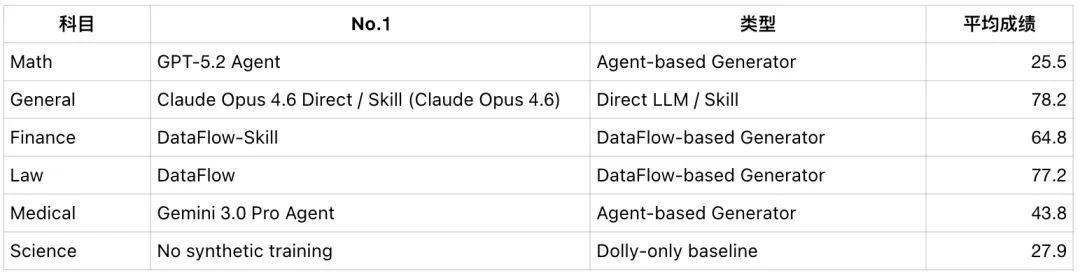
再看 Llama-3.1-8B 上的评测结果:金融、法律、医学都能从合成数据中受益,但最优路径并不一样;Finance 是 DataFlow-Skill,Law 是 GPT-5.2 Direct,Medical 是 Claude Opus 4.6 Direct。而 Math、General、Science 三个场景里,不加合成数据反而最好。
综合两个评测结果来看,使用不同模型,每个场景最适合的数据准备路径是不同的。Agent 适合推理密集型科目,但并不稳定;DataFlow 工作流适合结构强、规则强的领域;强模型直接生成不是落后方案,在不少场景里仍然是非常强的 baseline;而 Science 这样的反例提醒我们,合成数据可能帮模型,也可能伤模型。
详细评测结果可查看:https://datapreparationbench.github.io/
Track2:训练前估分榜,判断数据值不值得训?
Data Quality Evaluation 通过给候选 SFT 数据集打分,再看这个分数和真实下游训练效果的相关性,在训练前判断一批数据值不值得训。
结果显示,DAS( Data Assessment Score 数据评估分数) 是最稳定的整体质量信号,在 Math、Medical、Science、General Text 上都与下游收益保持较强相关,尤其 Math 达到 +0.86,Medical 达到 +0.77。
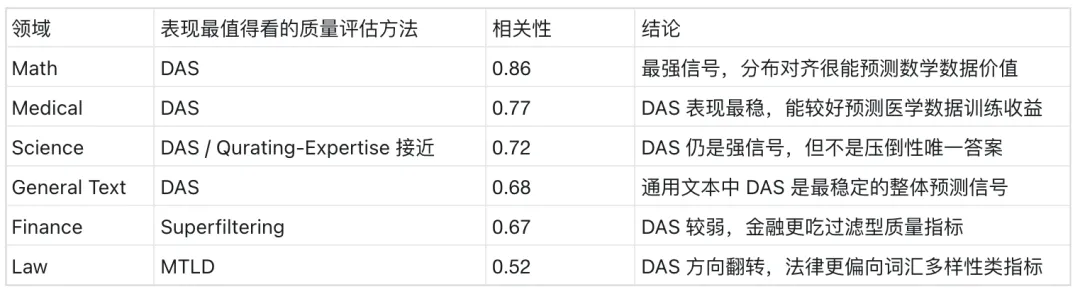
但 DAS 也不是万能指标:Finance 上 DAS 相关性较弱,Superfiltering 更有效;Law 上 DAS 甚至出现方向翻转,MTLD 这类多样性指标表现更好。这说明数据质量评估和造数据一样,也不存在一个跨领域通吃的方法,仍然需要按任务场景选择合适的评估信号。
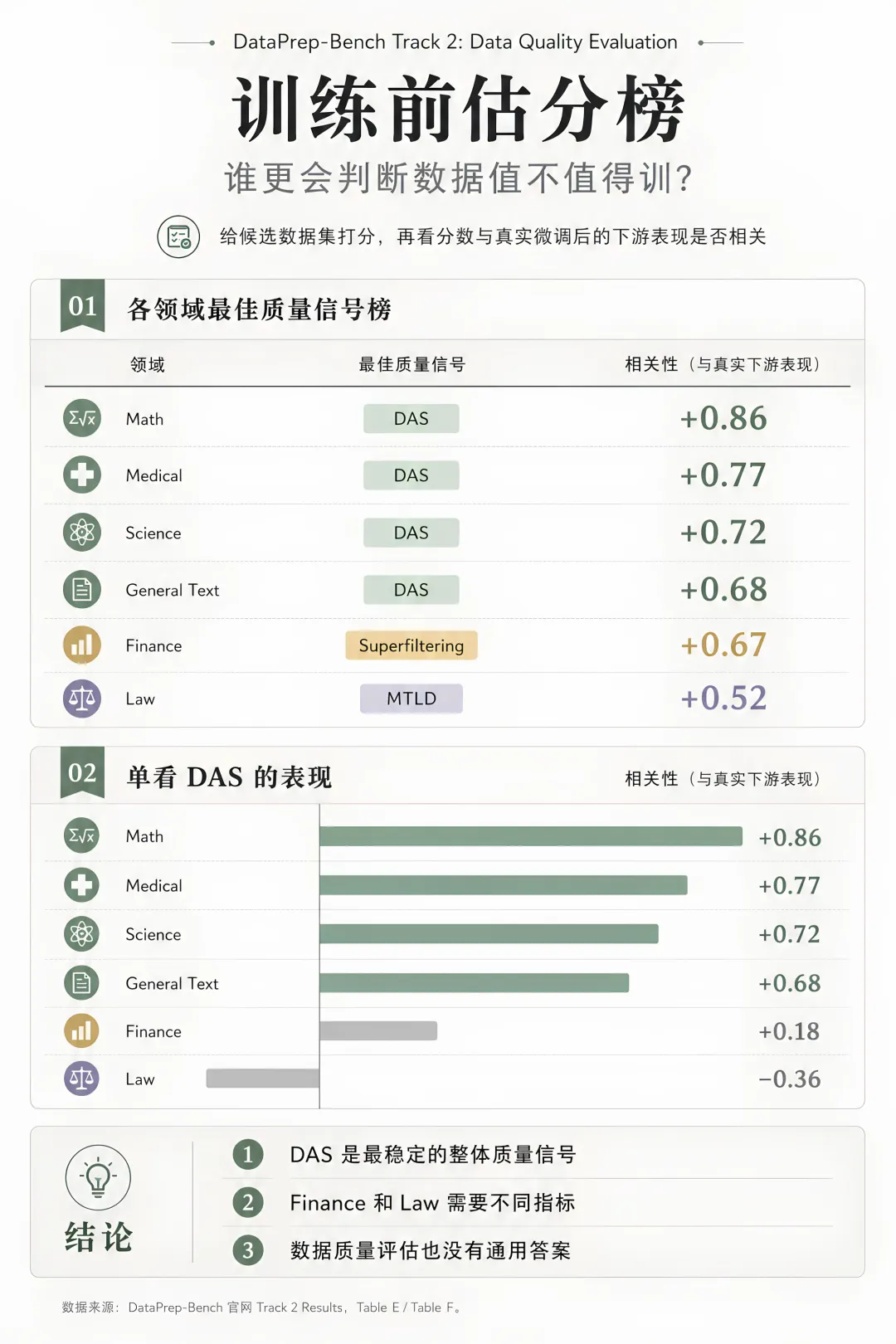
详细评测结果可查看:https://datapreparationbench.github.io/
这也是 DataPrep-Bench 的核心意义:它把“造数据、选数据”这件原本靠感觉、靠样例展示、靠经验判断的工作,变成了一场有考生、有科目、有考场、有成绩单的系统考试。
二、DataPrep-Bench:给 LLM 的“数据准备高考卷”
看完两份成绩单,我们再回到 DataPrep‑Bench 的底层设计。 为了让评测更全面、结果更精准,同时给真实业务落地提供参考,它在任务划分、方法对比、结果验证上,做了一套非常贴合行业现状的精巧设计。
为什么要设置两场 “考试”(Track)?
产出数据和判断数据好不好用,本就是两项完全不同的核心能力: 前者考验 AI 的数据生产能力,后者考验 AI 的数据判断力。
因此 DataPrep‑Bench 采用双赛道设计,既能容纳大模型直接生成、智能体构造、DataFlow 工作流、质量打分器等各类方案,也把评测范围从单一模型,扩展到完整的数据准备系统。 这也更贴合当下行业真实场景:合成数据的生产与筛选,本就是同步进行的。
造数据课代表:Skill
Data‑Construction‑Skill,是「数据合成赛道」里的标杆方案,专门解决长文档自动生成 SFT 训练数据的难题。
它给智能体的造数过程定下了一套清晰规则:明确样本类型、字段结构、内容覆盖范围与质量校验标准,摆脱了传统 Agent 只靠单次 Prompt、稳定性不可控的问题。
技术实现上,它围绕 Markdown 文档搭建了完整工具链:包含文档清单构建、文本切分、未处理片段查询、数据合并、覆盖度检查、格式校验等模块。 最终生成的数据分为三类:知识问答、流程推理、场景案例应用,分别对应知识记忆、逻辑推理、落地应用三大能力。
简单来说,Skill 专门解决 Agent 造数的不稳定痛点: 长文本任务里常见的漏生成、重复、格式错乱、过度依赖原文等问题,全部通过前置规则规避。 既保留了智能体灵活规划的优势,又能输出可直接用于训练的高质量数据。
估分课代表:DAS
Data Assessment Score(DAS)是「训练前估分赛道」的核心标杆,核心作用是:在正式训练前,提前预判一批数据到底值不值得训。
它的核心逻辑很直白:候选数据和目标领域的真实数据越贴近,训练后带来的提升就越大。
项目通过 distflow 工具包实现完整链路: 先加载开源数据集,统一格式;再通过主流模型计算文本特征;最后用 MMD 分布距离,衡量候选数据与目标领域数据的相似度。
DAS 把分布距离换算成数据质量分:距离越小,代表数据价值越高。 最大的实用价值是零训练成本预判—— 不用跑完整训练,就能快速给海量候选数据排序、筛选,大幅节省算力与时间成本。
统一考试规则:一场绝对公平的 AI 数据高考
对合成数据评测而言,统一实验协议,就像定下一套公平的高考考试规则,至关重要。
行业里很常见的问题是:不同团队用不一样的输入素材、不一样的筛选标准、不一样的训练成本,得出各自自洽的结论,结果根本没法横向对比。
而 DataPrep‑Bench 用标准化协议,彻底规避了这些变量干扰:
在数据生成赛道:统一原始素材、底座模型、训练参数与下游评测基准,让所有造数方法在完全相同的条件下同台比拼;
在数据估分赛道:固定候选训练数据集与真实训练效果基准,直接对比各类评估指标的预判准确度。
数据生态:从造数据、用数据到评数据,一套闭环打通
DataPrep‑Bench 是北大 OpenDCAI 最新开源的项目,但它解决的不只是一个单点问题 ——如何科学判断一套数据准备方法到底有没有用。
在真实的大模型研发链路里,评测只是其中一环。
数据要先被生产,再被筛选,最后在训练里被高效使用。
只有把生产 → 评测 → 训练三者打通,Data-Centric AI 才能从零散工具,真正变成系统化能力。
沿着这条核心主线,北大 OpenDCAI 已经搭建起一套完整生态:
DataFlow:负责把原始材料变成可训练的数据;
DataPrep‑Bench:负责检验数据与方法的真实收益;
DataFlex:负责在训练阶段做数据选择、混合与加权。
三者各司其职,环环相扣。
3.1 DataFlow:AI 数据工厂的基础设施
DataFlow 是整个链路里的数据生产底座。它把生成、评估、过滤、精炼等步骤封装成可复用、可复现的工作流,能从 PDF、纯文本、低质量问答里稳定产出模型可用的高质量数据。
在本次 DataPrep‑Bench 的数据生成赛道里,DataFlow 也是核心参赛方案之一,尤其在金融、法律这类规则性强的领域,展现出极强的稳定性。
3.2 DataFlex:让训练里的数据 “活起来”
如果说 DataPrep‑Bench 是考前评测,DataFlex 就是考场内的动态调度。 它基于 LLaMA‑Factory 构建,专注动态样本选择、数据混合、样本加权,让数据不再是一成不变的静态输入,而是可优化、可调度的核心资源。
它关注的不是 “数据好不好”,而是 “数据怎么用才更猛”。
这些项目共同指向一个清晰趋势:AI 的下一代竞争,核心是数据体系之争。 谁能把数据生产、评估、使用做到系统化、自动化,谁就能占据下一代 AI 的核心壁垒。
DataPrep‑Bench 的真正价值也正在于此: 它把 “谁更会造数据、谁更会判断数据”,从凭经验、凭感觉,变成了可复现、可对比、可验证的科学问题。从此,AI 数据准备,终于有了属于自己的 “高考标准”。
关于作者梁昊北京大学大数据科学研究中心博士,曾获北京大学校长奖学金,第一作者发表10+篇CCF-A论文/期刊。主导 Data-Centric AI 系列开源项目设计开发,项目累计获得近万 GitHub Star,其中 DataFlow 项目荣获 ICML SeePhy 比赛冠军,智源 LIC 挑战赛冠军。同时带领团队负责 Camel,LLaMAFactory 项目的数据模块设计开发,分别获得16k+和65k+ stars。北京大学 DCAI 团队专注于大模型数据系统研究与 Data-Centric AI 基础设施建设,开源 DataFlow、DataFlex、One-Eval、OpenWorldLib 等多个项目。开源项目:DataFlow (4k+ Stars) :一站式 LLM 训练数据准备系统 https://github.com/OpenDCAI/DataFlow 🌟DataFlow-Skills: https://github.com/OpenDCAI/DataFlow-SkillsDataFlex:LLM 动态数据训练框架 https://github.com/OpenDCAI/DataFlex 🌟DataMind:Agentic 范式的推理时数据检索框架 https://github.com/OpenDCAI/DataMind 🌟One-Eval:基于 Agent 的自动化大型语言模型评估框架 https://github.com/OpenDCAI/One-Eval 🌟OpenWorldLib:统一世界模型的通用推理与交互框架 https://github.com/OpenDCAI/OpenWorldLib 🌟更多开源项目可查看 https://github.com/OpenDCAI

