 夜雨聆风
夜雨聆风本周,全球最权威的 AI 评测平台 Arena(原 LMArena)悄然上线了一个全新的榜单——Agent Arena。跟以往的 Chatbot Arena 不同,这次不看模型聊天多顺溜,而是直接拉出来干真活:写代码、搭应用、分析文档、操作命令行。

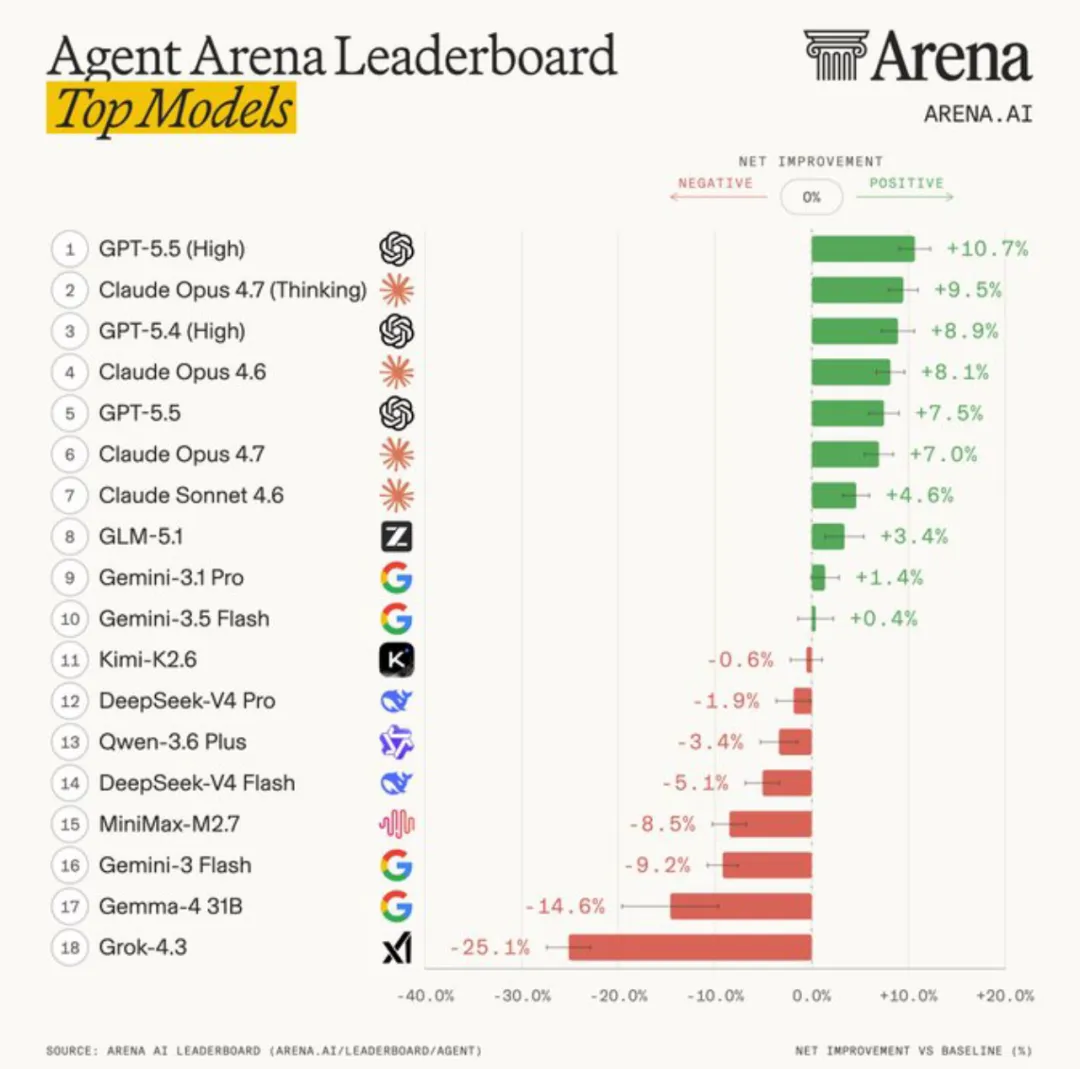
结果一出来,GPT-5.5 High 拿下第一,Claude Opus 4.7 Thinking 屈居第二,GPT-5.4 High 排在第三。
但真正有意思的,藏在这三个数字背后。
{ 370,000 次真实任务,18 个模型的正面对决 }
先说说这个榜单是怎么来的。
Arena 没有用传统的学术基准测试(那些早被各家厂商刷烂了),而是让用户在平台上用 Agent Mode 执行真实任务——建网页、写脚本、分析 PDF——然后用五个维度打分:
确认成功率:用户最终有没有点"任务完成"。
好评 vs 差评比:用户是夸还是骂。
可操控性:模型听不听话,会不会自作主张跑偏。
命令恢复:执行失败后能不能快速自救。
工具幻觉:会不会编造根本不存在的工具。
这五个维度合在一起,就是一个模型的"智能体商"。数据量相当扎实——371,792 次会话,覆盖 18 个主流模型。
说实话,这种评测方式比实验室跑分靠谱太多了。你在 SWE-bench 上刷到 90%,真扔到生产环境里用户可能五分钟就弃坑。真实任务里的坑——依赖冲突、权限问题、用户模糊的需求——只有拉到实战里才能暴露。
{ GPT-5.5 High 凭什么赢?}
GPT-5.5 High 的净改进率是 10.66%,比第二名的 9.47% 高出 1.19 个百分点。听起来不多,但看五个细分维度就有意思了。
它在四个维度上都是第一:好评率领先 Claude 将近 3 个点,可操控性领先 3 个点,命令恢复能力也更胜一筹(17.73% vs 16.69%)。唯一输给 Claude 的是"确认成功率"(7.06% vs 7.95%)——Claude 用户更容易觉得"这事干成了"。
这里有个有意思的细节。GPT-5.5 High 在命令恢复上这么强,很可能得益于它极简的输出风格。之前有实测表明,GPT-5.5 在相同任务上比 Claude Opus 4.7 少生成 72% 的 Token。输出越精炼,越不容易在长会话里把自己绕进去,出错回退也更少。
而 Claude 用户更容易"确认成功",可能跟它更愿意写文档和注释有关。你让 Claude 写段代码,它不光给代码,还附带一段解释和用法说明,用户体验更完整。
两种路线,两种优势。
{ Claude 的"偏科"和 GPT 的"全能" }
如果把 Agent Arena 的结果和 Arena 其他榜单放在一起看,格局就清晰了。
在传统的 Text 排行榜上,Claude Opus 4.6/4.7 Thinking 包揽前三,GPT 只能排到第六第七。WebDev 榜单也是 Claude 的天下。但在 Agent 榜单上,GPT 完成了逆袭。
这说明什么?Chatbot 时代的强项(文笔、推理、长文本理解)不完全等于 Agent 时代的能力。Agent 需要的是工具编排、错误恢复、指令遵循——这些恰好是 GPT-5.5 重点优化的方向。
还有一个不能忽略的因素:长上下文检索。实测数据显示,在 512K 到 100 万 Token 范围内,GPT-5.5 的检索准确率 74%,而 Claude Opus 4.7 只有 32.2%。差距大到 41.8 个百分点。Agent 任务经常要在超长上下文中来回横跳——打开十几个文件、执行几十步操作——长上下文能力几乎决定了你能走多远。
{ 中国模型的表现:有亮点,也有硬伤 }
18 个模型中,中国模型占据了 6 席,但整体排名不算靠前。
GLM 5.1(智谱)排在第 8,净改进率 3.38%,是中国模型里最高的。Kimi K2.6(月之暗面)排第 11。DeepSeek V4 Pro 排第 12,但有一个扎眼的数据——工具幻觉率 5.48%,是头部模型的 3 倍多。在 Agent 场景里编造不存在的工具,基本等于原地熄火。
不过 DeepSeek V4 Flash 虽然排第 14,却在一个维度上拿了第一:可操控性得分 15.29%,所有 18 个模型里最高。说明它在"听话"这件事上做得不错,短板在其他地方。
Minimax M2.7 排第 15,但好评率 15.73% 相当亮眼。Qwen 3.6 Plus(阿里)排第 13。
总的来说,中国模型在 Agent 能力上跟顶级的 GPT/Claude 还有明显差距,但追赶的势头在。从去年年底到现在,半年时间从"不配上桌"到"能进前 10",速度已经够快了。
{ 2026,Agent 元年是真的来了 }
Agent Arena 的上线,本身就是一个信号。
Arena 从最早的纯 Chatbot 竞技场,扩展到 12 个垂直榜单——代码、视觉、搜索、视频、文档、WebDev,再到今天的 Agent 专项评测。这不是简单的品类扩张,而是评测范式的升级:从"哪个模型聊得好"到"哪个模型能干成事"。
整个行业也在往这个方向狂奔。OpenAI 把"自主智能体"作为 GPT-5.5 的核心卖点;Anthropic 把 agentic coding 写进 Opus 4.7 发布主题;Google Gemini 3 也在强化工具使用和多步推理。Agent 已经从概念变成了主战场。
对于普通用户来说,这意味着你能用的 AI 不再只是"帮你写邮件"的秘书,而是一个真正能独立完成复杂任务的助手。Agent Arena 的作用,就是帮你在眼花缭乱的模型列表里,找到那个真能干活、不掉链子的。
榜单会持续更新。今天 GPT 领先,明天可能就是 Claude 反超,后天说不定哪个中国模型杀进前三。
这才是评测该有的样子——拉到真实任务里见真章。
#AI #AgentArena #GPT5.5 #ClaudeOpus4.7 #智能体 #AI评测 #Arena #大模型 #DeepSeek #GLM
{ 感谢阅读 }
如果本文对您有帮助,欢迎 “点赞“,点“推荐”
