 夜雨聆风
夜雨聆风扯个故事:某AI Infra新人,985硕士毕业,算法推导能力极强,Transformer论文倒背如流。入职第一个月,接手一个7B模型的训练任务。他写好了训练脚本,在8卡A100集群上启动训练。三天后,训练任务OOM崩溃,浪费了数十万算力成本。排查后发现,他的Python脚本存在内存泄漏,多进程数据加载配置错误导致CPU成为瓶颈,而nvidia-smi的报错信号他一直没有注意到。
算法思维在AI Infra的战场上,远不如工程素养来得实在。
AI Infra工程师与算法工程师的“地基”截然不同——前者需要的是工程化的Python、面向硬件的模型理解、系统级的性能思维。本文着眼于一套“够用主义”的基础知识清单,希望能够帮到跨行业者以较少时间补齐最关键的短板,直达后续的CUDA、分布式训练和推理优化。当然,这只是笔者尝试,也是一厢情愿:)
全文共分四个板块:Python工程能力、Transformer硬件视角、Linux性能思维、环境搭建实战。
主要内容:
- 1. Python工程能力:从“能跑”到“能上生产”
1.1. 内存管理与性能剖析(核心痛点) 1.2. 多进程与异步IO(数据加载瓶颈) 1.3. 装饰器与上下文管理器(资源管理艺术) 1.4. 类型注解与工程化(协作与维护) 1.5. Python“够用清单”速查表 - 2. Transformer原理:不只是调API,要懂硬件意识
2.1. 从RNN到Transformer:Attention的硬件红利 2.2. Attention机制的硬件视角(核心中的核心) 2.3. 主流模型架构变体与Infra影响 2.4. 从模型结构到算力估算(成本意识) 2.5. 数学“够用清单” - 3. Linux系统与性能思维:从“会用”到“会看”
3.1. 必备命令行:不只是ls和cd 3.2. GPU生态命令行(AI Infra专属) 3.3. 性能分析三板斧:CPU、内存、IO瓶颈定位 3.4. 文件系统与存储:大模型时代的隐形瓶颈 - 4. 环境搭建:实操第一步
4.1. 推荐的基础环境配置 4.2. 最小可行性验证:从零跑通LLaMA-2-7B推理 - 5. 地基篇的终点与下一站入口
5.1. 本文核心技能检验清单 5.2. 参考文献
1. Python工程能力:从“能跑”到“能上生产”
AI Infra工程师的Python,不是用来做实验的原型代码,而是要在万卡集群上24×7不间断运行的生产系统。万不万卡,额,其实不是每个同学都有机会摸到万卡的,可以全当该“万”是虚词:)
1.1. 内存管理与性能剖析(核心痛点)
在长周期训练任务中,Python内存泄漏比算法Bug更难排查——日志只显示“Killed”,没有堆栈,难以复现和归因。根本原因往往不是模型本身,而是未被释放的中间对象、全局缓存膨胀,或C扩展的引用计数异常。
定位工具链: Python标准库内置的tracemalloc是排查内存泄漏最基础也最强大的工具。在服务启动时插入:
1 2 3 4 5 6 7 8 9 10 import tracemalloctracemalloc.start(25) # 保存25帧调用栈# 执行若干轮模型推理后,获取快照并对比current = tracemalloc.take_snapshot()if 'prev_snapshot' in globals(): top_stats = current.compare_to(prev_snapshot, 'lineno') for stat in top_stats[:5]: print(stat) # 输出内存增量最高的5处代码行prev_snapshot = current tracemalloc可以精确定位到内存增长最快的是哪一行代码、哪个文件,配合objgraph可视化对象引用关系,生成PDF图谱识别“可疑增长类型”。memory_profiler则提供逐行火焰图分析,精确到一行代码的内存占用。
在AI训练场景中,最典型的内存泄漏问题包括:全局缓存中长期持有model.state_dict()引用、注册的钩子隐式捕获模型实例、日志模块对模型参数的引用意外升级为强引用等。一个经验判断标准是:如果nvidia-smi显示GPU利用率和显存长期不匹配,尤其训练过程中显存持续增长而利用率下降,大概率存在内存泄漏。
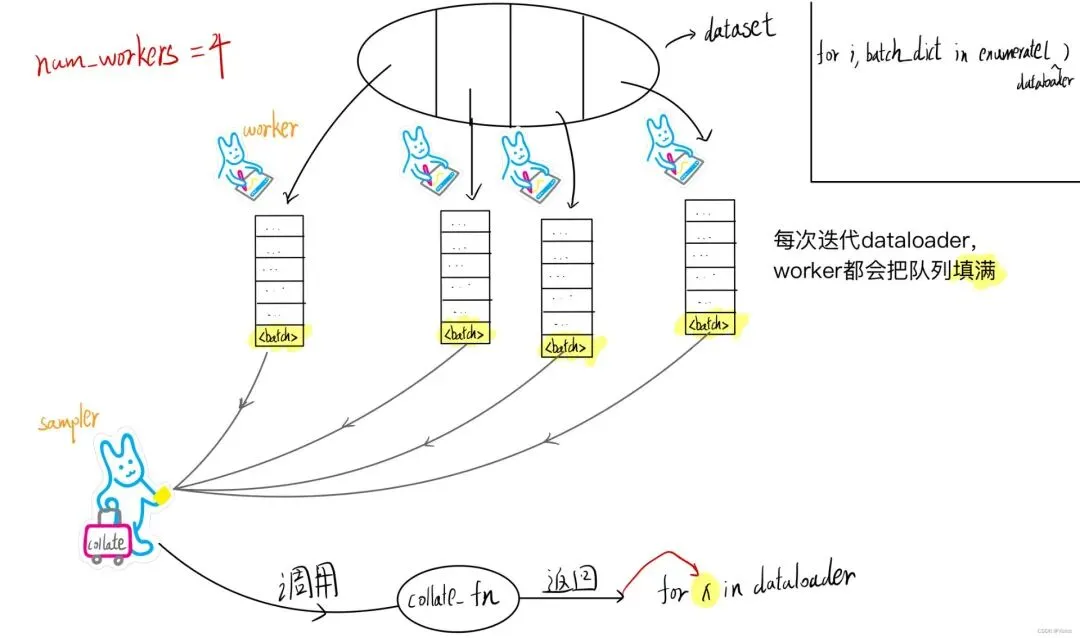
1.2. 多进程与异步IO(数据加载瓶颈)
为什么AI训练必须用多进程而非多线程加载数据?答案只有一个字:GIL。Python的全局解释器锁使得多线程无法真正利用多核CPU并行处理数据。
PyTorch的DataLoader中,num_workers=0意味着在主进程中同步加载数据,训练必须等待数据准备好才能继续。将num_workers设置为大于0时,数据加载和训练可以重叠执行,大幅隐藏磁盘IO和预处理的延迟。
最佳实践:num_workers应设置为CPU物理核心数,或按经验设为4×GPU数量,需要根据工作负载和训练数据的位置反复调优。同时开启pin_memory=True,将数据固定在内存的不可交换区域,加速Host到GPU的数据拷贝。在GPU利用率长期低于70%时,应优先检查是否数据加载已成为瓶颈。
异步编程在AI Infra中同样有重要应用。例如,日志收集系统的异步写入、监控指标的异步上报。核心原则是:在异步函数内部,永远不要使用阻塞式同步调用——应该使用对应的aio版本库(如aiohttp、aiofiles),或通过loop.run_in_executor将阻塞任务卸载到线程池。
1.3. 装饰器与上下文管理器(资源管理艺术)
在AI Infra场景中,资源的生命期管理极其重要。下面是一个生产级的训练耗时统计装饰器:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 import timeimport torchfrom functools import wrapsdef training_metrics(func): @wraps(func) def wrapper(*args, **kwargs): torch.cuda.reset_peak_memory_stats() start = time.perf_counter() result = func(*args, **kwargs) elapsed = time.perf_counter() - start peak_memory = torch.cuda.max_memory_allocated() / 1024**3 print(f"{func.__name__}: {elapsed:.2f}s, peak_mem={peak_memory:.2f}GB") return result return wrapper 上下文管理器在推理引擎中尤其常见。例如,Hugging Face Transformers库的Llama类实现了上下文管理器协议,使得模型显存能够在with语句退出时自动释放。torch.no_grad()则是每位AI Infra工程师每天都在使用的上下文管理器——禁用梯度计算可显著降低内存占用,加速推理。
1.4. 类型注解与工程化(协作与维护)
在大规模AI Infra工程中,数百行甚至数千行的训练脚本必须可读可维护。类型注解是这背后的基础设施。TypedDict描述配置字典的结构、dataclass减少样板代码、mypy在CI环节进行静态类型检查——这些都极大降低了多人协作时的隐性Bug。
1.5. Python“够用清单”速查表
2. Transformer原理:不只是调API,要懂硬件意识
AI Infra工程师不需要手推Attention公式的数学细节,但必须知道:为什么FlashAttention能快7倍?为什么GQA能省显存?

2.1. 从RNN到Transformer:Attention的硬件红利
RNN的串行计算特性使其天然不适合GPU并行加速——每个时间步的计算依赖上一个时间步的输出,无法被有效地分解为并行计算。
Transformer的革命性贡献在于,Attention机制的计算几乎完全是矩阵乘法,而矩阵乘法正是GPU设计之初就专门优化的核心任务。将整个序列的上下文一次性“喂”给Attention,所有Token对之间的计算可以被批次化为巨大的矩阵乘法和Softmax操作,在现代GPU上获得极高的并行吞吐量。
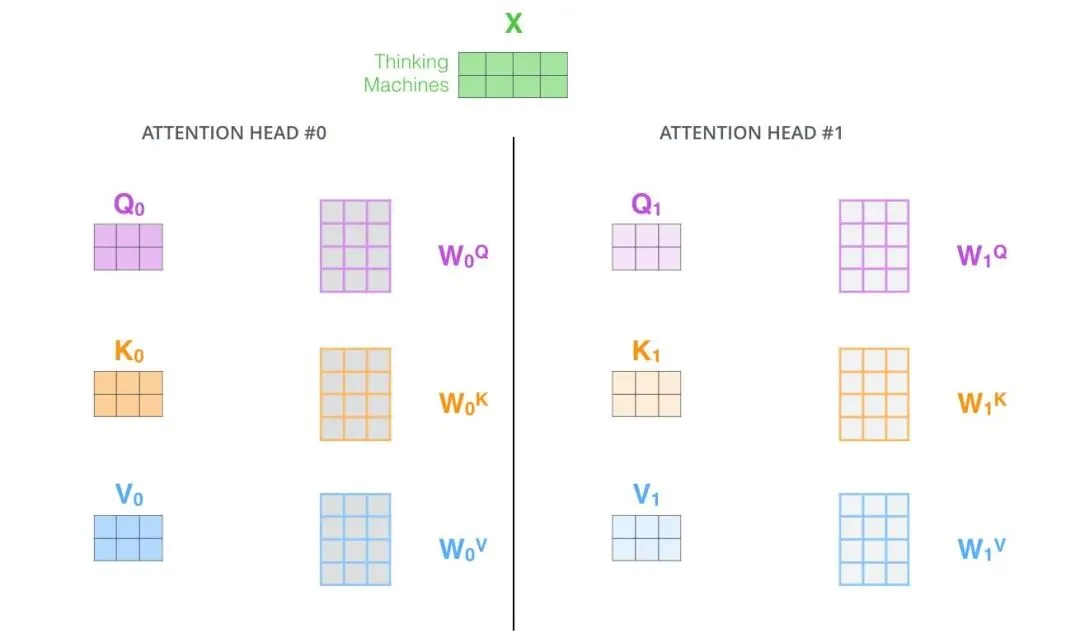
2.2. Attention机制的硬件视角(核心中的核心)
Attention的平方复杂度O(N²)的核心:标准Attention的计算公式为 Attention(Q,K,V) = softmax(QK^T/√d_k) * V。中间矩阵 QK^T 的维度是 [batch, seq_len, seq_len]——序列长度N加倍,矩阵大小变为4倍。这一复杂度直接决定了模型在更长上下文下的算力和显存双重重压。
KV Cache的显存占用推导:推理过程中,模型逐个生成Token。为了不必为每个新Token重新计算整个序列的Key和Value,推理引擎会缓存已经计算过的K和V矩阵。其显存占用量可通过以下公式计算:KV_Cache_Size = 2 × batch_size × seq_len × num_layers × hidden_size / num_heads × (num_kv_heads) × dtype_bytes
实测数据:以LLaMA-2-7B为例,FP16精度下仅模型权重就占用约14 GB显存。在推理场景中,当batch=1、seq_len=2048时,KV Cache额外需要约1-2 GB显存。序列长度每增加一倍,KV Cache对显存的消耗也将成倍增长。
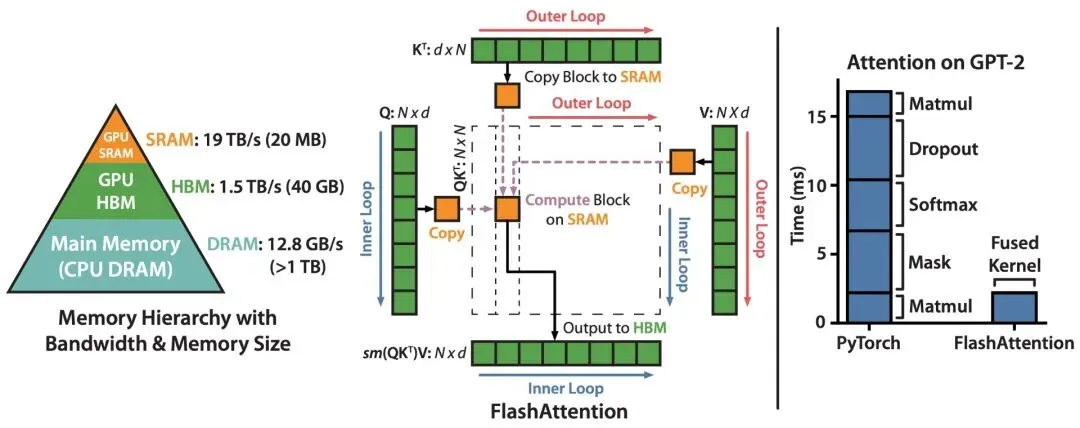
FlashAttention为什么快:标准Attention将N×N的注意力矩阵完整存储在慢速HBM(高带宽显存)中,造成了巨大的读写开销。FlashAttention的核心洞察是:现代GPU的限制因素不是计算速度,而是在HBM(带宽~1.5-2.0 TB/s)和片上SRAM(容量约192 KB/流式多处理器,但带宽~19 TB/s)之间移动数据所需的时间。通过Tiling将计算切分成适合SRAM的块,配合Softmax的增量计算,FlashAttention在前向传播中可将HBM读写从N²降低到O(N),在GPT-2上实现了7.6倍的速度提升。
2.3. 主流模型架构变体与Infra影响
AI Infra工程师不仅要知道模型的数学形式,更要预判其内存访问模式。
GQA由Ainslie等人于2023年提出,核心思想是将查询头进行分组,每组共享一组KV缓存——既保留了MQA的推理效率,又尽可能逼近MHA的质量。理解GQA对于估算大模型推理时的KV Cache显存至关重要。
2.4. 从模型结构到算力估算(成本意识)
几个必备公式:
1)参数量→推理显存占用:FP16精度下,参数量(亿) × 2 = 显存(GB)。量化到INT8时,参数直接减半。
2)FLOPs估算:
训练 ≈ 6 × 参数量 × Token数推理 ≈ 2 × 参数量 × Token数
2.5. 数学“够用清单”
AI Infra工程师不需要在数学上与算法工程师直接竞争。但以下概念是阅读系统设计文档、理解显存占用公式和性能瓶颈分析的核心工具。
数学是工具,不是目的。AI Infra工程师遇到公式的目标是“读懂结论”,而非“从头推导”。
3. Linux系统与性能思维:从“会用”到“会看”
AI Infra工程师的工位,常年挂着一个htop终端。不懂Linux性能分析的Infra工程师,就像不懂仪表的飞行员。
3.1. 必备命令行:不只是ls和cd
Brendan Gregg在其著名演讲中整理了完整的Linux性能工具观图,覆盖从应用到硬件各层级的观测手段。
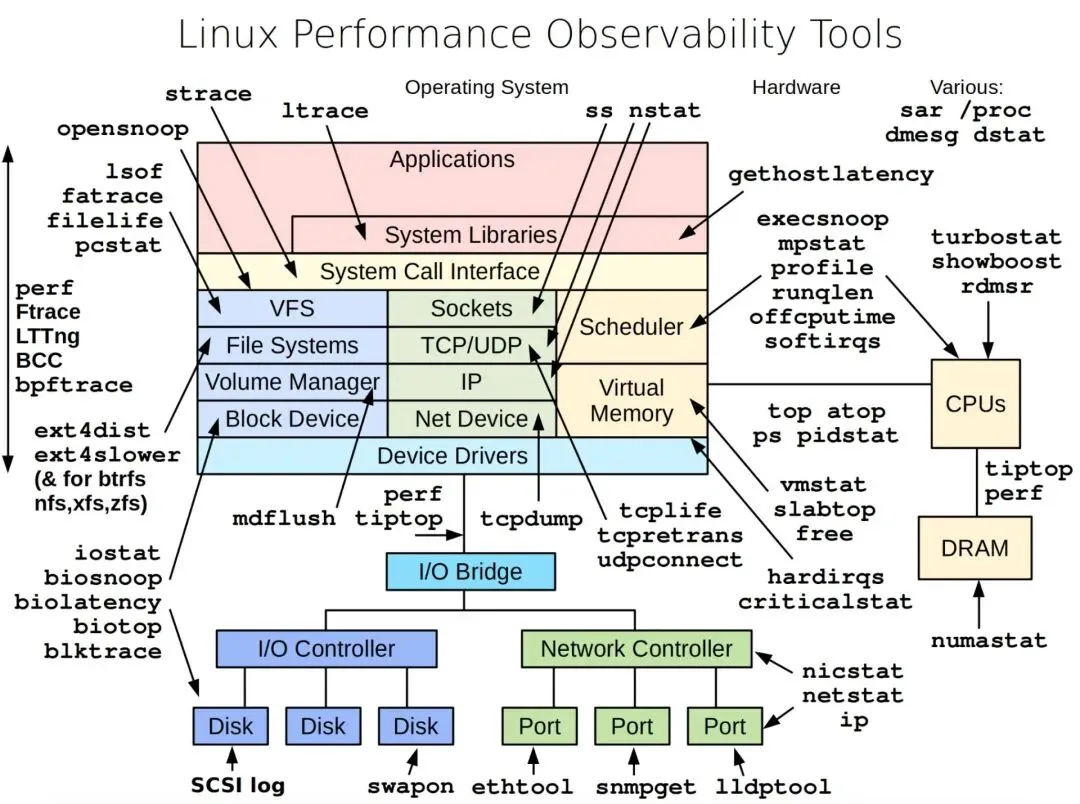
核心命令速览(按维度分类) :
pstop/htop、kill、nice | ||
free -hvmstat、/proc/meminfo | ||
df -hdu -sh、iostat、iotop | ||
ssnetstat、iftop、ping/traceroute | ||
findxargs、grep、awk、sed组合 |
3.2. GPU生态命令行(AI Infra专属)
以下命令应当成为每一位AI Infra工程师的日常基础:
nvidia-smi: 默认面板查看所有GPU的显存占用、利用率、温度、功耗和运行进程。nvidia-smi pmon -c 1可查看每个进程对GPU的具体使用情况。nvidia-smi -i 0 --query-gpu=index,utilization.gpu,memory.used --format=csv: 输出结构化CSV,便于集成进监控脚本。nvidia-smi dmon -s u,m,p -c 300: 每秒采样一次利用率和显存,持续300秒,生成日志用于离线分析。nvidia-smi topo -m: 查看GPU拓扑,识别NUMA节点间的连接关系,对于Tensor Parallel等分布式并行策略的配置至关重要——两组GPU跨PCIe连接还是通过NVLink互联,通信带宽差异可达数倍。
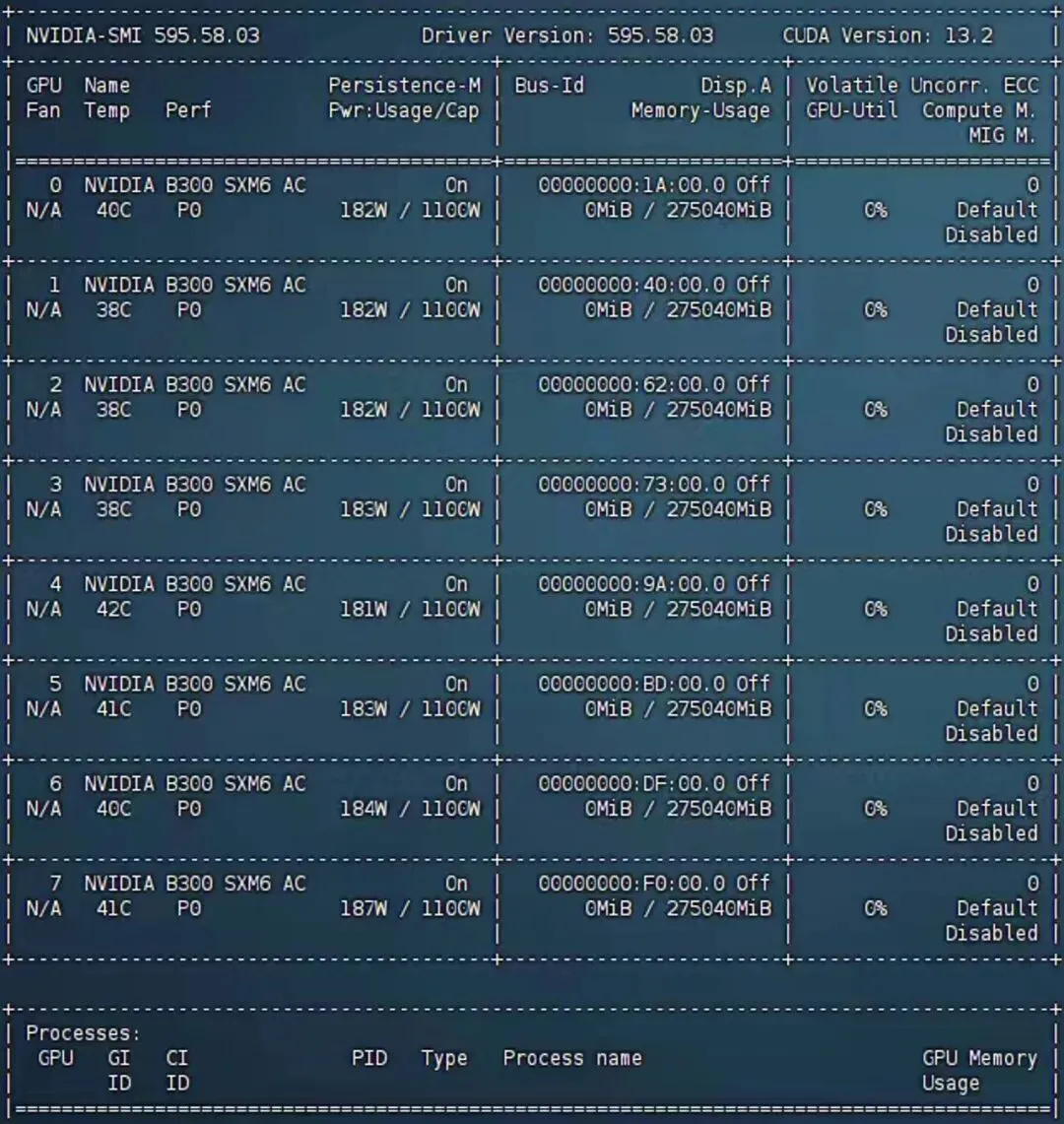
在容器环境中一个常见的陷阱:容器内通过nvidia-smi -i 0看到的GPU 0,可能对应宿主机的GPU 1。多卡服务器上极易误判,部署多实例推理时需格外注意。
3.3. 性能分析三板斧:CPU、内存、IO瓶颈定位
Netflix性能团队发布的一篇著名博客总结了一套在60秒内完成系统健康检查的流程。核心命令如下:
uptime | ||
dmesg \| tail | ||
vmstat 1 | ||
mpstat -P ALL 1 | ||
pidstat 1 | ||
iostat -xz 1 | ||
free -m | ||
sar -n DEV 1 | ||
top |
Netflix团队特别强调:重点关注错误(errors)和饱和度(saturation)指标,因为它们最容易被解释,也往往是性能问题的直接根源。饱和度表现为请求队列的长度(等待CPU调度的进程数)或等待时间(磁盘I/O的await)。
在AI训练场景中,如果GPU利用率长期低于70%,应优先检查是否为数据加载瓶颈——用htop观察CPU核心负载、用iostat检查磁盘I/O等待。反之,如果CPU利用率过高、GPU闲置,则说明预处理代码可能过于复杂,需要优化或迁移到GPU侧执行。
3.4. 文件系统与存储:大模型时代的隐形瓶颈
大模型训练中,海量小文件的随机读取往往是意想不到的性能杀手。训练数据集常包含数百万个小图片或文本片段,随机读取模式下磁盘I/O的%util可能瞬间被占满。
优化策略:
将小文件合并为大文件(如TAR、WebDataset格式),利用顺序读的特性大幅提升吞吐。 利用 tmpfs内存文件系统存储热数据,适用于频繁读取的小规模索引文件。在生产环境中,Lustre和BeeGFS等高性能并行文件系统专门为AI训练设计,而JuiceFS等云原生解决方案则以更轻量的方式提供类似能力。
4. 环境搭建:实操第一步
理论说得再好,不如亲手跑起来一个模型。
4.1. 推荐的基础环境配置
- 操作系统: Ubuntu 22.04 LTS / 24.04 LTS
- Python版本: 3.10+(推荐3.10,稳定性最佳)
- CUDA版本: 11.8或12.1。确认驱动兼容性后选择即可,驱动版本可通过
nvidia-smi查看 - PyTorch安装: 访问
pytorch.org,根据CUDA版本选择对应的pip install`命令
推荐使用NVIDIA NGC容器来简化环境配置,只需安装NVIDIA驱动和nvidia-docker即可,无需单独安装CUDA和cuDNN。
4.2. 最小可行性验证:从零跑通LLaMA-2-7B推理
目标:1小时内,在自己的机器上(哪怕是单卡游戏GPU)加载并运行一个7B模型,完成一次文本生成。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 # 导入依赖from transformers import AutoModelForCausalLM, AutoTokenizerimport torchmodel_name = "meta-llama/Llama-2-7b-chat-hf"tokenizer = AutoTokenizer.from_pretrained(model_name)model = AutoModelForCausalLM.from_pretrained( model_name, torch_dtype=torch.float16, # 使用半精度节省显存 device_map="auto" # 自动分配设备(GPU/CPU))inputs = tokenizer("Hello, how are you?", return_tensors="pt").to("cuda")outputs = model.generate(**inputs, max_new_tokens=50)print(tokenizer.decode(outputs[0], skip_special_tokens=True)) 执行watch -n 1 nvidia-smi观察显存变化——生成结束时显存是否完全释放?批量推理时显存占用是否线性增长?这些都是理解推理引擎内部内存管理的第一步。
5. 地基篇的终点与下一站入口
5.1. 本文核心技能检验清单
能够用 tracemalloc定位并修复训练脚本中的内存泄漏能够解释 num_workers对训练吞吐的影响原理能够手写一个 @training_metrics装饰器能够计算LLaMA-2-7B在推理时KV Cache的显存占用 能够说明GQA与MHA在KV Cache上的本质区别 能够通过 nvidia-smi topo -m判断GPU间的通信拓扑能够在60秒内用Linux命令定位高CPU/高IO进程 能够独立估算训练一个7B模型的大致算力成本
5.2. 参考文献
Python AI服务OOM崩溃不断?:4步精准定位内存泄漏源头(附可落地的eBPF+tracemalloc实战脚本) https://blog.csdn.net/InstrGap/article/details/158754519Python AI应用内存泄漏检测工具(GitHub Star 2.4k+,已被Meta、OpenAI内部团队验证) https://blog.csdn.net/FastCompile/article/details/159401977【性能查看】用 nvidia-smi监控 GPU 使用率:从一次性查看到工程级日志实践https://blog.csdn.net/Rabbit_QL/article/details/156713927nvidia-smi Deep Dive for GPU Sever Operators https://gigagpu.com/nvidia-smi-deep-dive-gpu-server/#processesLinux Performance Analysis in 60,000 Milliseconds https://netflixtechblog.com/linux-performance-analysis-in-60-000-milliseconds-accc10403c55htop Explained Visually https://codeahoy.com/2017/01/20/hhtop-explained-visually/PyTorch官方性能调优指南 https://docs.pytorch.org/tutorials/recipes/tuning_guide.htmlThe Illustrated Transformer https://jalammar.github.io/illustrated-transformer/FlashAttention 论文 https://arxiv.org/abs/2205.14135Hugging Face Transformers https://huggingface.co/docs/transformers
