 夜雨聆风
夜雨聆风先说明一下,这个想法不是我原创,它主要结合了两个大佬三分享:
一个来源于Skill "Context-engineer" is you need! (qq.com)
另一个是杨堃老师的我如何从ClaudeCode丝滑切换到Codex
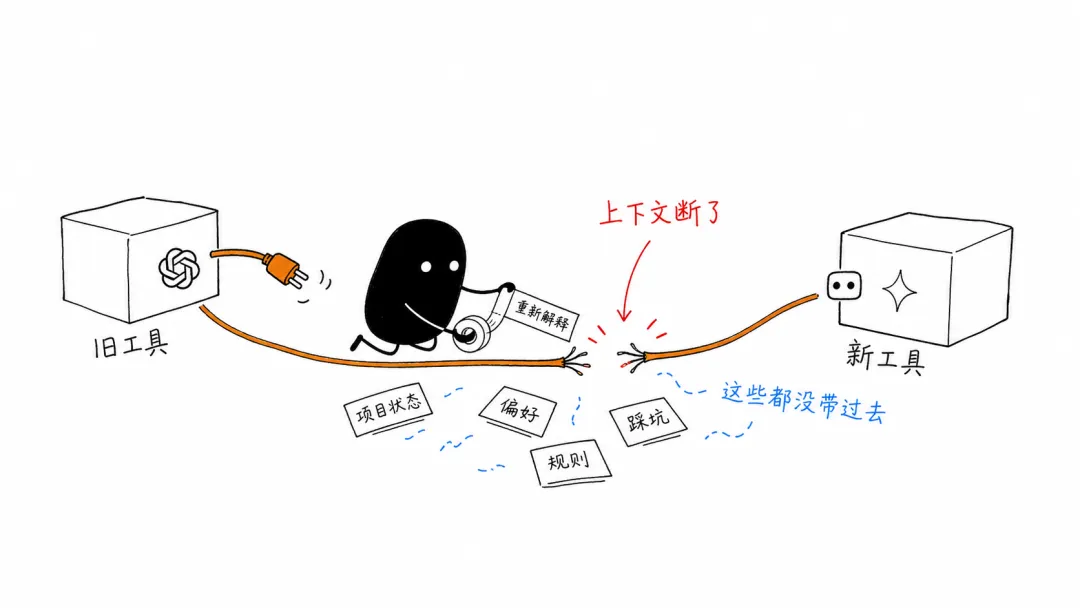
换 AI 工具的时候,最麻烦的不是安装。
也不是第一条命令能不能跑通。
真正麻烦的是:上下文会断。
新工具不知道我是谁,不知道项目做到哪一步,不知道哪些内容已经讨论过,也不知道哪些坑之前踩过。
于是每换一个工具,我都要重新解释一次自己。
这件事很烦。
所以这次结合两位的想法搭了一套memory 系统,管理有生命周期的上下文。
它的作用是什么
它解决的不是“如何多建几个文件夹”。
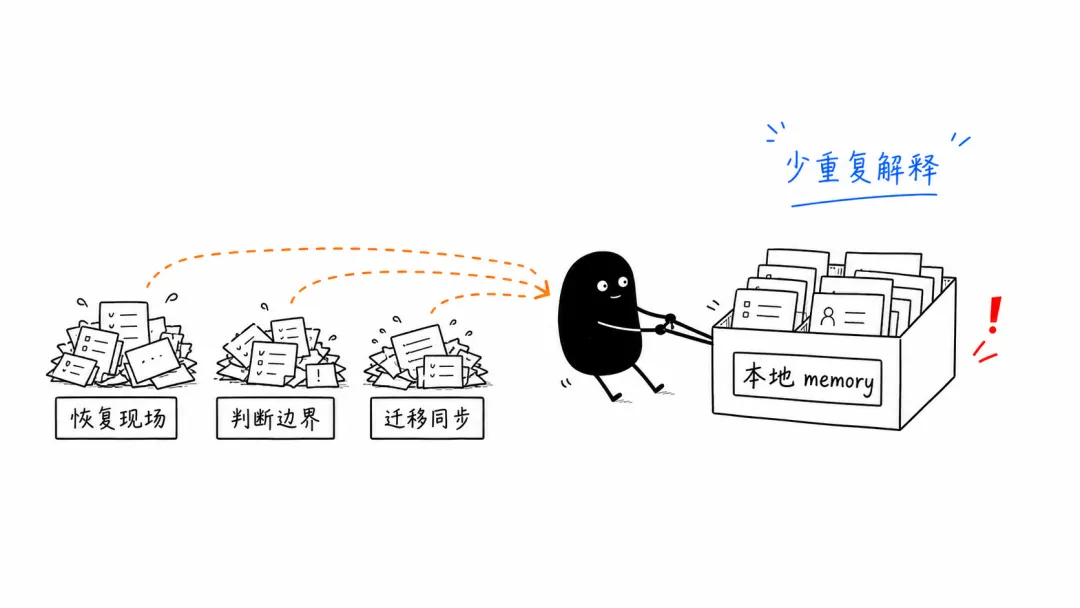
它想省下来的,是 AI 长期协作里那些反复出现、单次不大、累积起来很烦的成本。
第一个成本,是恢复现场。
同一个会话里,AI可能记得很好。但换线程、换工具,或者隔几天再回来,项目背景、当前进度、关键限制往往要重新补一遍。
第二个成本,是判断边界。
全局偏好、项目规则、草稿、决策如果都混在一个入口里,AI 可能拿到了信息,却不一定知道这条信息该不该用于当前项目。
第三个成本,是迁移和同步。
Claude Code 有自己的入口,Codex 有自己的入口,Cursor 又有自己的习惯。如果长期记忆主要写在某个工具的配置里,换工具时就要判断哪些规则要复制、哪些规则不该复制,以及以后两边怎么同步。
这套系统的核心,沿用了那篇文章里的判断:把“记忆”从工具里拿出来,变成用户自己掌控的一套本地资产。
工具只是来读它。
不是工具拥有记忆,而是记忆接待工具。
怎么搭
先让Agent安装context-engineer上下文skills,再让他结合memory解耦思路,建立memory系统,修改Agent执行的逻辑。
最后形成的是一个组合结构。
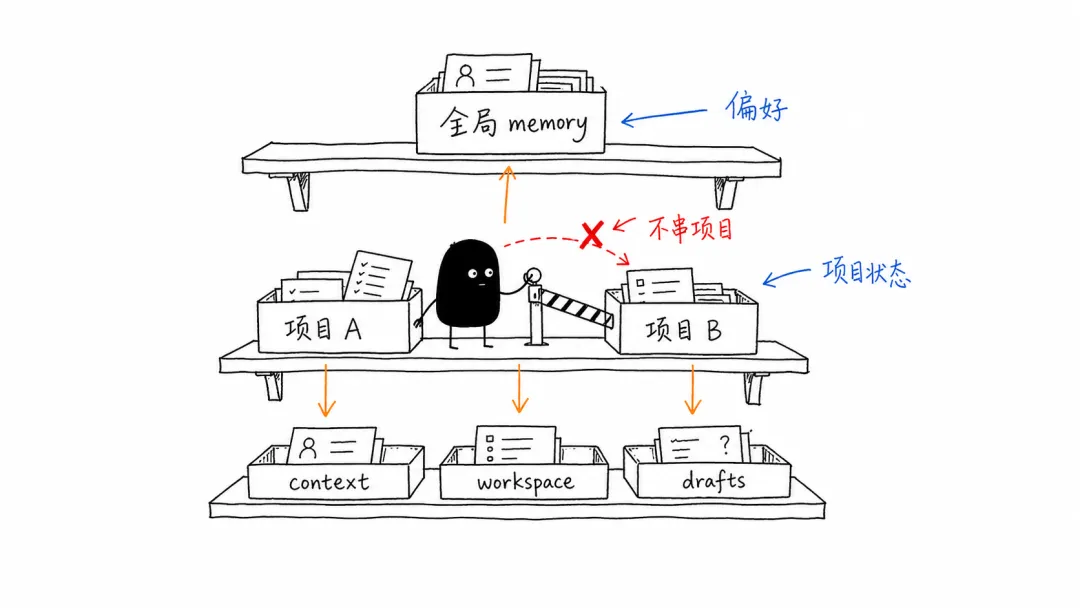
第一层:全局个人 memory。
它只放跨项目都适用的东西,比如我是谁、我喜欢什么协作方式、写作风格、常用资料路径、有哪些项目。
第二层:每个项目自己的 project-memory。
它记录这个项目的目标、状态、决策和工作记录。
第三层:每个项目自己的三层context。这个部分主要借鉴`context-engineer` 的思路。
context/ 已确认的稳定知识
workspace/ 正在推进的事项
drafts/ 草稿和待确认材料
这三个目录每个项目都有一套,彼此独立。
简单说就是:
全局 memory 负责认识我,项目 memory 负责认识项目,三层 context 负责判断信息成熟度。
这样拆完以后,AI 进入一个项目时,至少有了明确的查找路径。
它先读全局入口,知道怎么跟我协作。
再读项目入口,知道这个项目是什么。
然后根据任务去找事实、进展或草稿。
不保证它一下变聪明,但至少不会上来就到处翻。
最后说点过程中的问题
AI表面理解到位,但深层需求没有对齐
我给出想法后,AI看起来很快理解并完成了整合,但在持续追问后才发现,实际理解和我的预期并不一致。
这里有两方面原因:一是我自己的边界和需求没有完全说清楚;二是AI对整体方向把握较好,但对关键细节、边界条件和落地状态的把控不足。
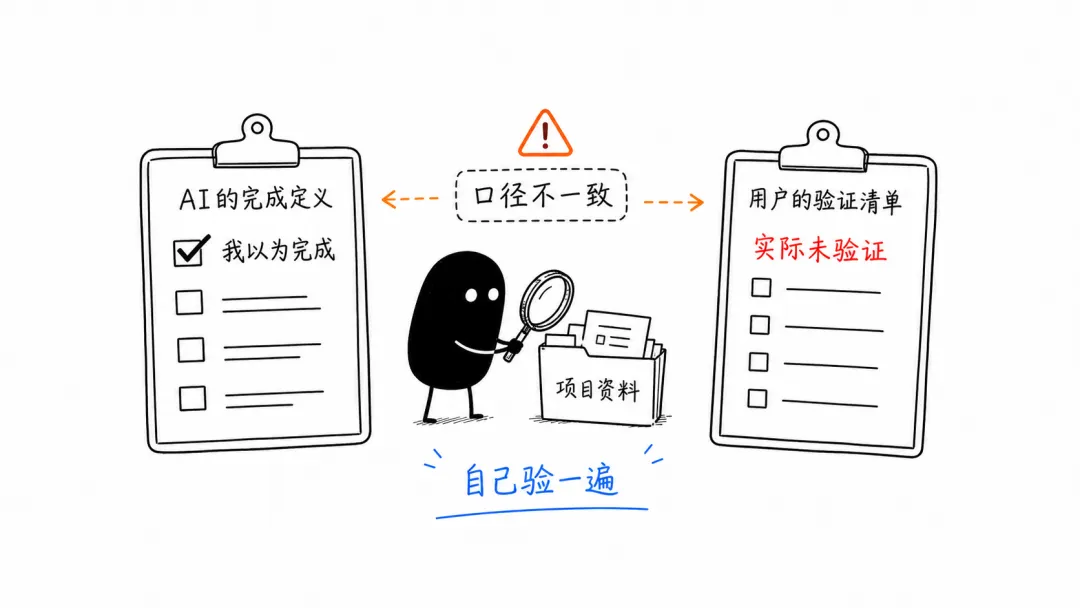
“完成”的口径不一致,导致结果不可靠
后来我进入每个项目逐一确认,才发现很多项目并没有真正安装成功相关skills和记忆索引,有些只是半成品,有些项目甚至没有被识别出来。
问题在于我和AI对“项目”的定义不同:我认为 Codex 里的一个项目就是我的项目,而AI可能按另一套方式识别。
结果是,AI表面上回复“都安装好了”,但实际并没有完成。这让我必须自己进行验证,才能检查出结果是否符合预期。
容易放大价值,焦虑满天飞
后来我让AI把记忆系统搭建的过程写个总结,AI会倾向于把这件事的价值、意义和影响拔高。
但这套系统是今天才搭起来的,实际效果和价值我还没有真正感受到。
提前总结出很大的价值、夸大成果,让我想其他人的内容是不是也这样,悄悄制造了一波焦虑。
虽然价值不肯定,但是我认为思路是很好的,虽然我自己搭不出这套系统,但感谢大佬们的无私分享和Agent工具能力。
