 夜雨聆风
夜雨聆风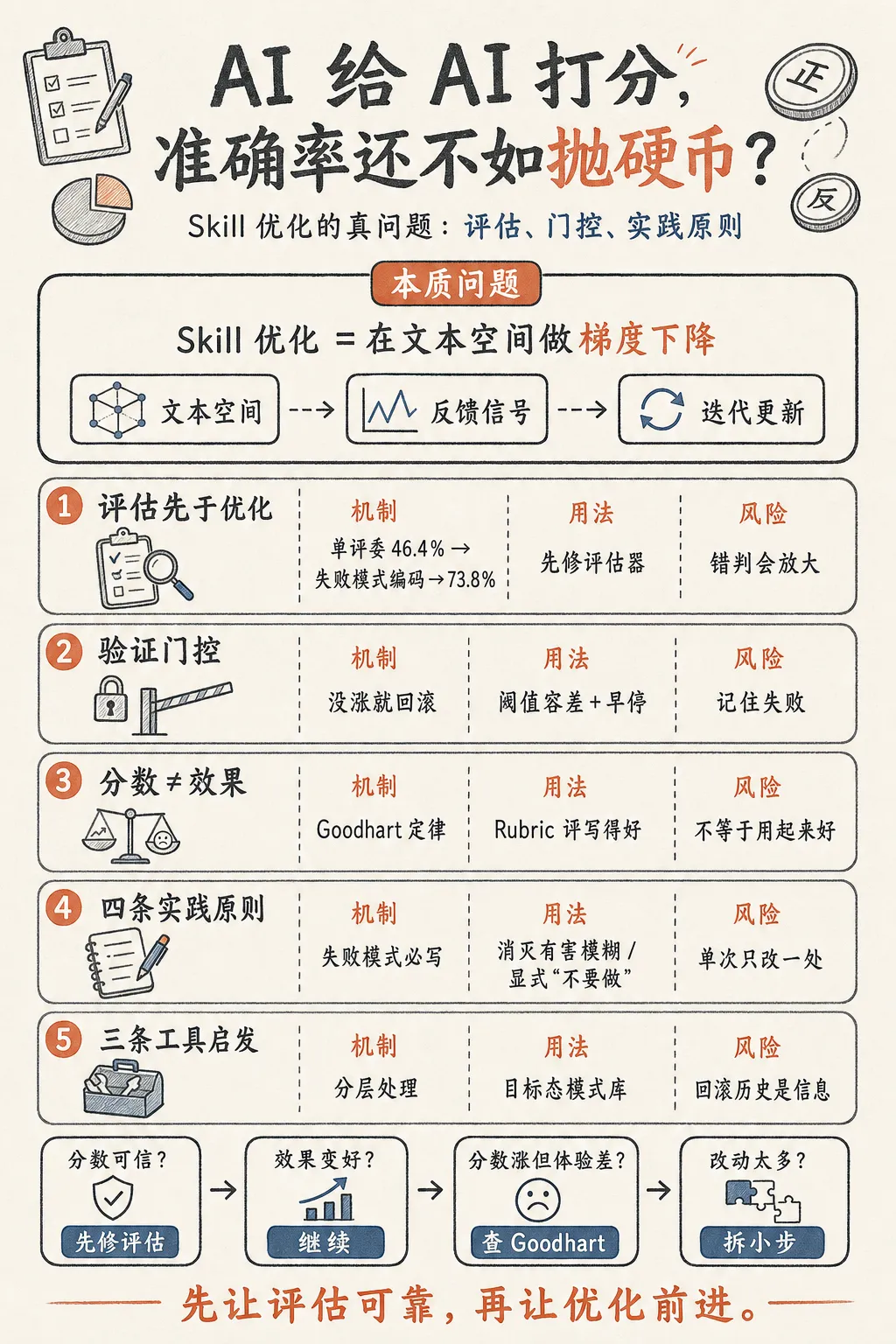
最近我在研究 skill 怎么系统性地变好这个问题。不是靠灵感改几句话碰运气,而是有没有一套工程化的流程,能让 skill 的质量稳定提升。
这个问题引我读了几个东西:社区里开源的达尔文 skill 优化器(自动评分、提改进方案、改完再评、分数没涨就回滚),微软研究院 5 月 22 日发的两篇论文 SkillLens 和 SkillOpt,以及另一个社区项目 Skills-Optimization-Pro 和一篇关于元级自改进的论文 Bilevel Autoresearch。再加上我自己做 skill 评测工具时积累的一些体感。读完之后有些收获想分享,也有些地方我觉得需要打问号。
Skill 优化的本质问题
从第一性原理出发,skill 优化是什么?
把外衣扒掉,它是一个 在文本空间做梯度下降 的问题。你有一个目标函数(skill 的实际效果),有一个可调参数(skill 文档的文字内容),需要找到让目标函数值最大化的参数配置。
但文本空间不像数值空间那样连续可微,所以你没法算梯度。替代方案是:让一个 AI 评估当前状态,让另一个 AI 提出改进方向,改完再评,评完决定接受还是回滚。

这个框架成立的前提有三个:评估足够准确、优化方向不随机漂移、有机制防止退化。达尔文和微软论文各自在这三个前提上做了工作,但也各自暴露了盲区。
评估先于优化:单评委准确率只有 46.4%
SkillLens 论文给了一个让我印象深刻的数字:让单个 AI 按评分标准给 skill 打分,准确率只有 46.4%。比抛硬币好不了多少。
这里解释一下 Rubric 这个词。它来自教育评估领域,就是一张预先定义好的评分量表,列出各维度(比如指令明确性、失败模式覆盖)、每个维度的分值区间、以及什么样的表现对应什么分数。作用是让不同评委打分时有统一锚点。
回到那个 46.4%。这个数字揭示了一个根本性问题:如果你的度量工具本身不可靠,所有基于它的优化都是在噪声上做梯度下降。方向都是随机的,改了也不知道是变好还是变差。
SkillLens 发现把准确率拉上去的关键手段是 失败模式编码。当 Rubric 里加入了 agent 在执行时遇到异常情况该怎么办的判断维度后,准确率从 46.4% 升到了 73.8%。这是一个显著的提升,虽然离完美还远(每 4 次还错 1 次),但至少让评估从基本不可用变成了勉强可参考。
另一个提升评估可靠性的手段是 多评委共识。多个独立的 AI 用同一套 Rubric 分别打分,取共识结果。这降低了随机噪声,但要注意:它没有解决系统性偏差。如果 Rubric 本身有问题,10 个评委也会一致地给出错误判断。
我从这里带走的核心认知是:评估必须独立于优化。 写 skill 的 AI 和评分的 AI 必须分开,多个评委之间不能复用上下文。这其实是在文本优化领域重新发明了双盲实验。
验证门控是唯一可靠的质量保障
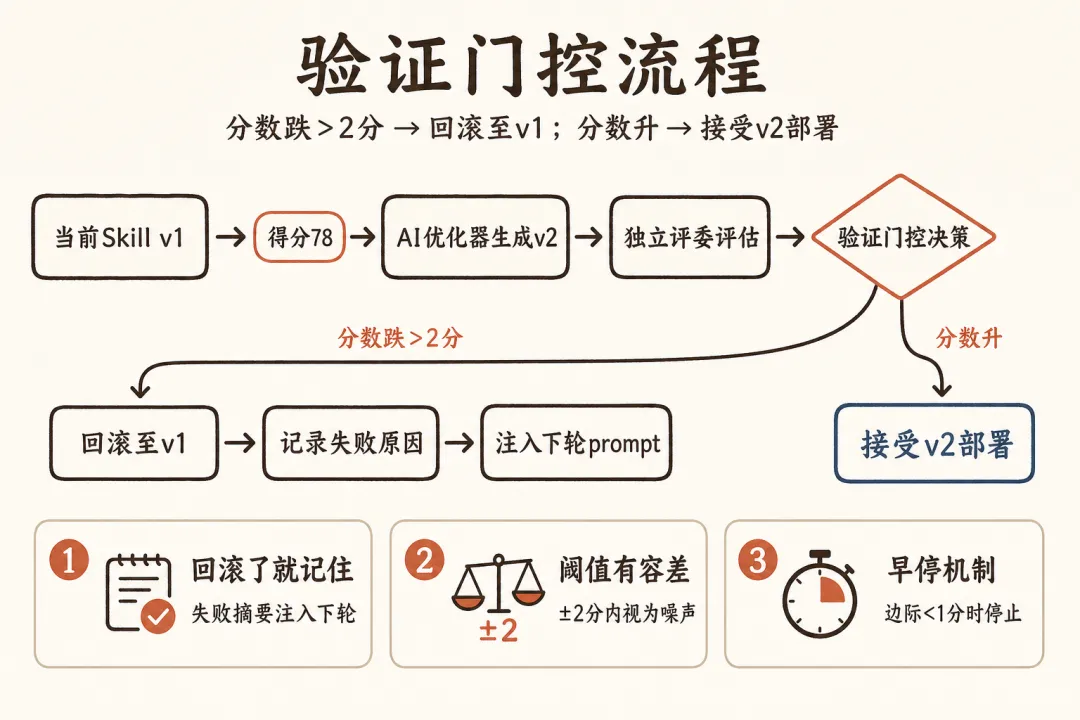
达尔文优化器有一个设计让我觉得抓住了要害:分数没涨,自动回滚。
SkillOpt 论文里也有类似机制:验证不通过就拒绝写入。表述不同,原理完全一样。在没有确凿证据证明改进有效之前,保持现状。
为什么这很重要?因为 LLM 提出的改进方案有很大概率是中性甚至负面的。它很擅长给出看起来合理的修改建议,但这些建议是否真的让 skill 变好了,只有通过独立评估才能知道。没有验证门控,你会不断接受看起来像改进但实际是随机漂移的改动,skill 越改越长、越改越碎,但没有变好。
但验证门控本身也有两个需要注意的设计细节。
第一个是 回滚了就记住。SkillOpt 不只是回滚,还把被拒绝的改动摘要喂给下一轮优化,告诉它这条路走过了不通。这样做的好处是避免系统反复尝试同一个无效方向,让每一轮回滚都产生信息价值,而不只是浪费一次迭代。
第二个是 回滚阈值应该有容差。SkillLens 已经证明 AI 评委在 ±1-2 分范围内的判断不可靠,这个区间的波动可能是噪声不是真实变化。所以回滚条件不应该是"分数没涨就回滚",而是"跌了 2 分以上才回滚"。否则你会把本来有效的改动因为评分噪声误杀掉。
在这个基础上,我认为还需要一个 早停机制。当边际收益递减(比如单轮涨幅小于 1 分),继续优化大概率是在往 skill 里塞冗余内容来讨好评分标准,而不是真正改善效果。你要有勇气在还能涨一点的时候停下来。
分数不等于效果
这是我最想强调的一点,也是读这些材料时始终保持的一个警觉。
达尔文优化器宣称跑了 40 次优化平均涨 13.5 分,2.0 版本全部进入 90+。这些数字很漂亮,但需要追问:涨的是什么的分数?
答案是:AI 评委按 Rubric 打的分。
那 Rubric 分数高就等于 skill 好用吗?不一定。SkillLens 对这个问题给了一个更精确的拆分:skill 质量其实有两个独立维度,一个是 文本本身是否清晰完整,另一个是 agent 拿着它执行任务时表现是否更好。前者可以叫"写得好",后者可以叫"用起来好"。Rubric 评的是前者,但用户真正关心的是后者。而这两者之间的相关性,没有想象中那么高。
我自己做评测工具时也碰到了同样的问题。最后不得不在报告里写明:这个工具评的是文档工程质量,不是运行时性能。真正要验证 skill 是否变好了,得拿优化前后的版本分别跑同一组真实任务,对比结果。没有这一步,所有评分都只是参考。
还有一个容易踩的坑:同一套评分标准对不同类型的 skill 可能产生误判。 有些 skill 是给 agent 补能力的(比如教它用一个它不知道的 API),有些 skill 是编码用户偏好的(比如规定输出格式和风格)。前者需要高密度的领域知识,后者重点在流程一致性。如果你用同一把尺子量这两种 skill,第二种会在"领域知识密度"这个维度上天然低分,但这不代表它写得差。
这是 Goodhart's Law 的一个变体。翻译成白话就是:当度量标准本身成为优化目标时,它就不再是好的度量标准。
所以我的看法是:Rubric 评估适合做 快速筛选,类似 unit test,帮你快速排除明显不好的改动。但最终验证必须回到 真实任务执行,类似 integration test,看优化后的 skill 在实际场景中的成功率和用户满意度是否提升。
另外,0 回滚这个指标也需要警惕。如果回滚阈值设得足够宽松,任何改动都能通过验证。0 回滚可能说明算法精准,也可能说明标准太松。没有对照实验,你分不清是哪种。
对构建 Skill 的四条实践原则(以及对做优化工具的三条启发)
以上是认知层面的收获。落到实操,经过批判性过滤后我觉得有几条原则是确实成立的。
先说写 skill 的人应该关心的:
第一,写 skill 时必须包含失败模式和边界条件。
这是 SkillLens 论文中最扎实的发现。大多数 skill 只写了 happy path,但 LLM 执行时最容易出错的恰恰是边界情况。具体做法:为每个关键步骤写出"如果 X 发生就做 Y,否则做 Z"的明确分支。不要让 agent 在遇到意外时自己猜该怎么办。
第二,消灭有害模糊,但保留有价值的抽象。
建议、可以考虑、视情况而定,这些词对人类读者是礼貌的缓冲,对 LLM 是决策噪声源。Skill 是给机器执行的指令,不是给人看的建议书。该给确定性指令的地方,必须给确定性指令。
但这条规则有一个重要的边界:当正确答案依赖运行时上下文时,不确定不是逃避,是参数化。
比如写"根据当前 agent 环境查找配置路径",表面上看是模糊的,但它其实是一条明确指令(查找),只是目标值是动态的。如果你写死 ~/.cursor/settings.json,skill 换个环境就废了。
所以更精确的规则是:区分 决策逃避型模糊 和 环境适配型抽象。前者是 skill 作者自己也不确定该怎么做,这该消灭;后者是正确答案依赖运行时探测,这该保留甚至鼓励。判断标准:这个不确定是作者的懒,还是问题本身的特性?
这里还有一个容易忽略的对称面:堆砌硬性规则也不等于清晰。 很多人写 skill 时一口气列了十几条 MUST、NEVER、ALWAYS,但不解释为什么。这看起来很确定,实际上很脆弱。LLM 理解了原因后,能在没见过的场景里自己做正确推断;但如果只给了死板规则没给原因,一旦遇到规则没覆盖的情况,它就会乱来。所以该确定的是行为指令,该解释的是背后原因,两者缺一不可。
第三,设置显式的 不要做什么 章节。
这比 要做什么 更重要。LLM 的默认行为空间极大,不加约束它会探索到你不想要的区域。一个 skill 如果只说了该做什么,没说不该做什么,agent 迟早会给你惊喜。
但加内容也有代价。每多写一句话,就多占一分 agent 的注意力。冗余不是无害的,它会稀释真正关键的指令的权重。所以写 不要做什么 的同时也要问自己:我写的每一条,删掉后 agent 真的会做错吗?如果答案是不会,那这条就不该存在。
第四,单次只改一个维度。
这是控制变量法的直接应用。如果一次改了三个地方,分数涨了,你不知道是哪个改动起了作用;分数跌了,你也不知道该回滚哪个。每次只动一处,归因清晰,迭代才有方向感。
这里有一个来自 Bilevel Autoresearch 的补充观察:LLM 在自主选择优化方向时存在 确定性偏见,它总是先尝试同一类改法。就像一个人拿着锤子看什么都像钉子。所以不仅要每次只改一处,还要有意识地避免连续几轮都改同一个方向。如果发现自己(或工具)连续三轮都在加 fallback 表、加异常处理,停下来问一句:是不是该换个角度了?
最后,有一个比内容质量更前置的问题:你的 skill 能被找到吗?
我自己做评测时发现,很多 skill 内容写得不错,但根本没机会发挥作用,因为它的 description 写得太保守,agent 压根不会触发它。这不是质量问题,是生死问题。一个永远不被触发的 skill 等于不存在。
而且 agent 在选择是否调用 skill 时有一个系统性偏向:宁可不触发,也不轻易触发。 这意味着 description 不能只是精确描述功能,还得主动覆盖用户可能的各种说法,包括口语、缩写、同义词。宁可被多触发几次(用户说了不相关的话也被激活,大不了跑一下发现不对再退出),也不能漏触发(用户明明需要你,但 agent 没想起来调用你)。所以在花精力打磨 skill 内容之前,先花同样的精力打磨 description 里的触发词。
再说做 skill 优化工具的人应该关心的:
第一,简单问题不需要重炮。 Skills-Optimization-Pro 用三级路由机制,格式问题(比如 frontmatter 缺失)直接快速修,不跑完整评估流程。不是所有 skill 问题都值得启动全量优化,分层处理能省掉大量不必要的 token 消耗。
第二,给优化一个目标态,不只是"分数涨了就行"。 Skills-Optimization-Pro 维护了一套设计模式库(比如 Tool Wrapper、Pipeline、Reviewer 等典型 skill 架构),优化方向不只是让评分提高,而是让 skill 向某个正确的架构模式靠拢。与其让 AI 在无限空间里自由探索,不如给它一组参照物,告诉它好的 skill 长什么样。
第三,回滚历史是信息,不只是垃圾。 前面提到 SkillOpt 把被拒改动注入下一轮 prompt。更一般地说,每次失败的优化尝试都在告诉你这条路不通,如果你的工具能记住并利用这些失败,收敛速度会比从零开始快很多。
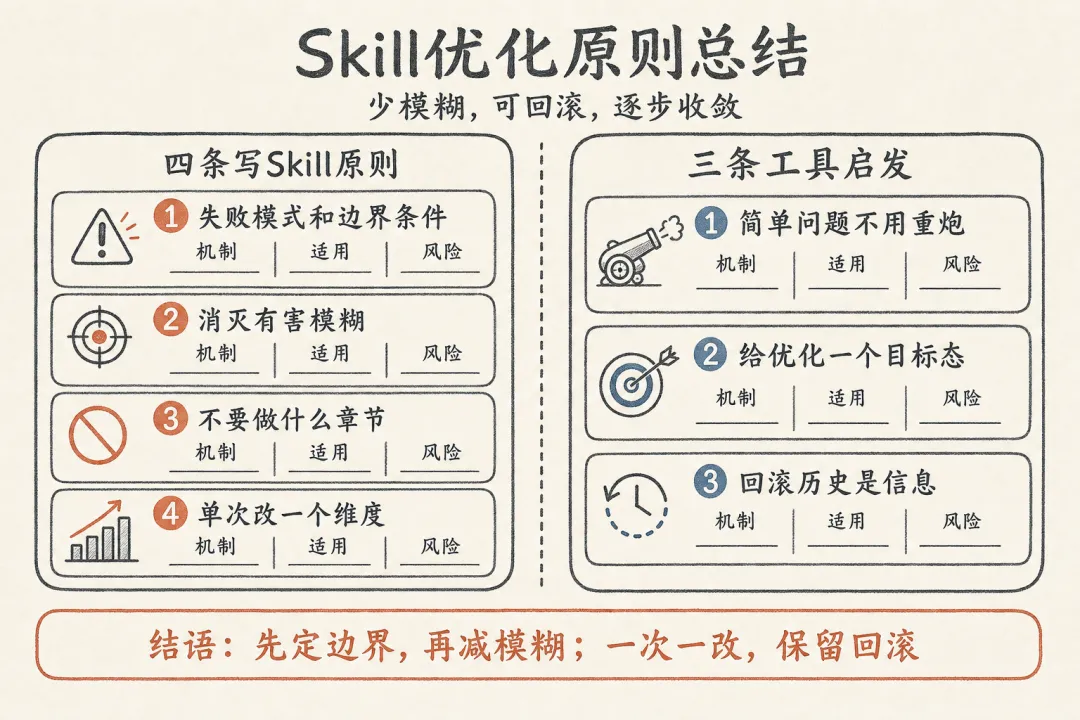

最值得从这些材料中带走的不是具体的评分维度或多评委机制,而是背后的思维方式:让独立的观察者用明确的标准审判你的工作,并且只在有证据证明改进有效时才接受改动。 这个原则不仅适用于 skill 优化,适用于任何需要持续迭代的工作。
